
지난번 강의에서는 pandas의 기초를 배웠다.
데이터 프렘임에서 우리가 원하는 값들을 추가하고 삭제하고, 뽑아내고
오늘부터 서울시 CCTV현황에 대해 본격적으로 배운다.
01. Analysis Seoul CCTV
2) CCTV 데이터 훑어보기
- 현재 CCTV_Seoul 데이터프레임의 상태확인.
CCTV_Seoul.head()
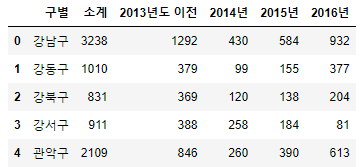
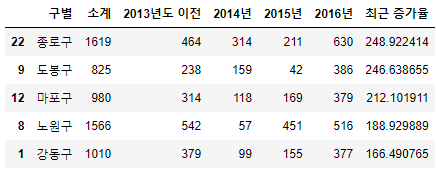
- CCTV_Seoul에 "최근 증가율"컬럼을 추가.
CCTV_Seoul["최근 증가율"] = ( (CCTV_Seoul["2016년"]+CCTV_Seoul["2015년"]+CCTV_Seoul["2014년"]) / CCTV_Seoul["2013년도 이전"] * 100 )
3) 인구현황 데이터 훑어보기
- 인구현황 확인
pop_Seoul.head()
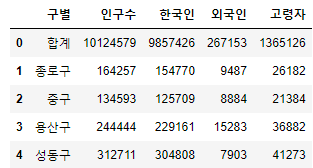
- 인덱스0번 삭제(drop()사용)
#0번째 인덱스 가로행(axis=0) 삭제 후 본문저장 pop_Seoul.drop([0], axis=0, inplace=True)
-외국인비율, 고령자비율 컬럼 추가
pop_Seoul["외국인 비율"]=pop_Seoul["외국인"] / pop_Seoul["인구수"] * 100 pop_Seoul["고령자 비율"]=pop_Seoul["고령자"] / pop_Seoul["인구수"] * 100 pop_Seoul.head()
pandas에서 DataFrame 병합하는 방법
- pd.concat()
- pd.merge()
- pd.join()
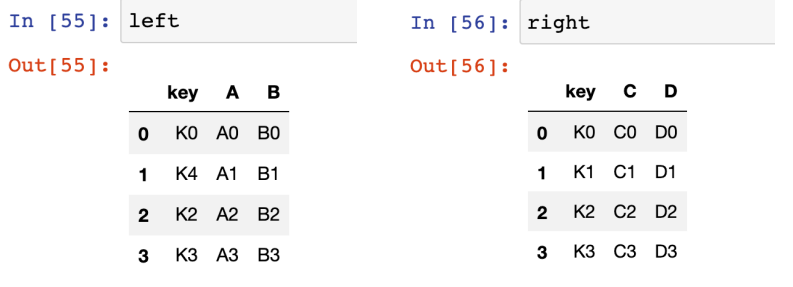
- left, right라는 데이터프레임을 만들어 보자
left
#딕셔너리 안의 리스트 형태
#열로 값이 들어감
left = pd.DataFrame(
{
"key" : ["K0","K4","K2","K3"],
"A" : ["A0","A1","A2","A3"],
"B" : ["B0","B1","B2","B3"]
}
)right
#리스트 안의 딕셔너리 형태
#행으로 값이 들어감
right = pd.DataFrame(
[
{"key":"K0", "C":"C0", "D":"D0"},
{"key":"K1", "C":"C1", "D":"D1"},
{"key":"K2", "C":"C2", "D":"D2"},
{"key":"K3", "C":"C3", "D":"D3"},
]
)
pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 "키"값 이라고 합니다.
- 기준이 되는 키값은 두 데이터 프렘임에 모두 포함되어 있어야 한다.
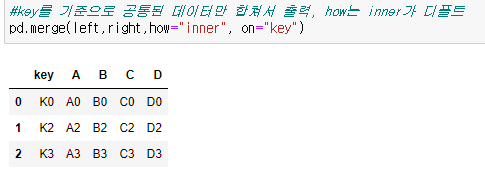


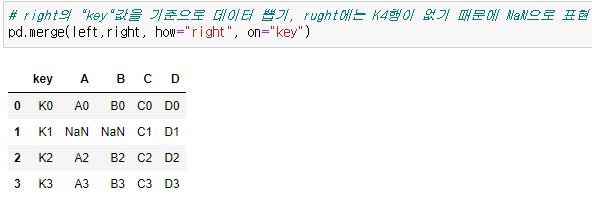
4) 두 데이터 합치기
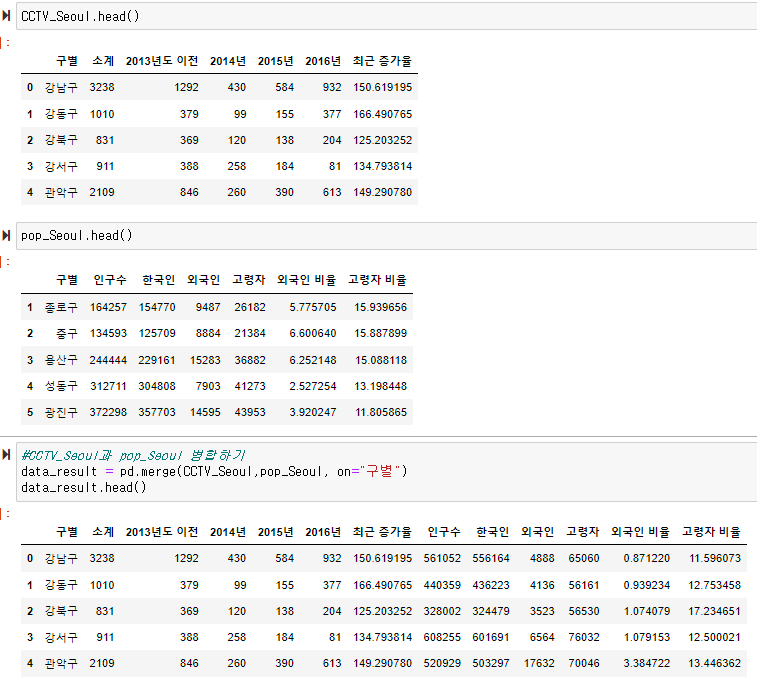
년도 별 CCTV현황은 이후 사용되지 않을것이기 때문에 가독성을 위해 삭제

그래프 표현을 편하게 하기 위해 "구별" 컬럼을 키 로 설정하기
- set_index() : 선택한 컬럼을 데이터프레임의 인덱스로 지정
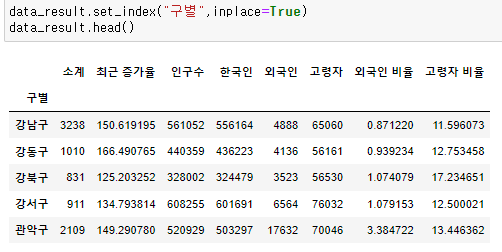
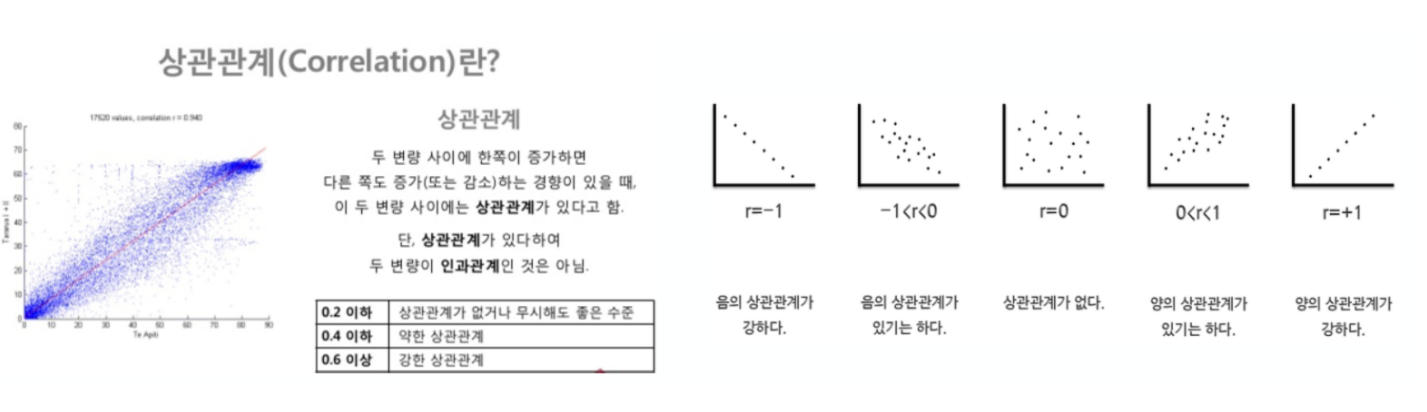
- 상관관계 란?
- 상관계수
- corr()
- correlation의 약자
- 상관계수가 0.2이상인 데이터를 비교하는 것이 의미가 있다
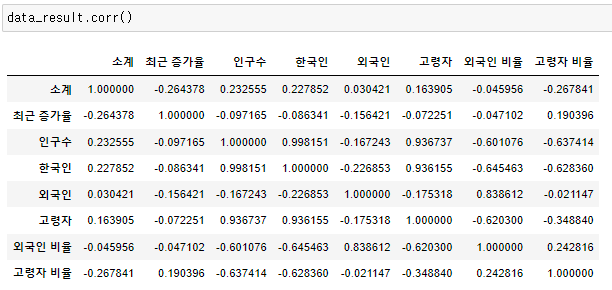
- 인구수와 CCTV갯수는 0.23255의 상관계수로 유의미 한 상관관계를 가진다.
- 하지만 상관관계가 강하지는 못 하다(0.2)
- corr()을 사용할 때는 문자열이 있으면 안된다.
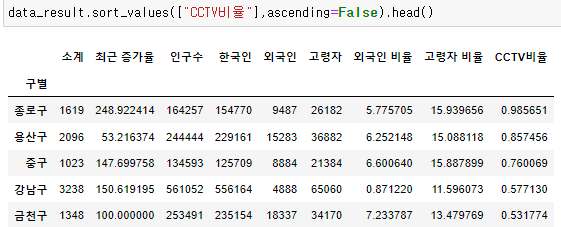
- 상관관계가 유의미하다는것을 알았으니 인구수 대비 CCTV비율에 관한 컬럼을 추가해 보자

- 내림차순으로 정렬 후 알수 있는 건 종로구, 용산구가 인구 대비 CCTV수가 많다는 것이다.
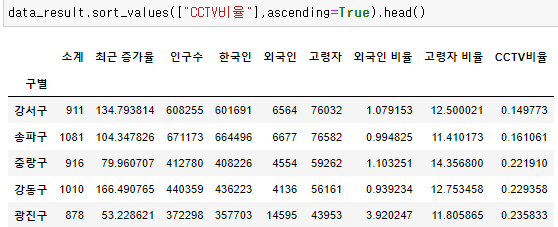
- 반대로 오름차순으로 정렬하면 알수 있는 건 강서구, 송파구가 인구대비 CCTV수가 적다는 것이다.
matplotlib 기초
matplotlib을 사용하기 전에 항상 셋팅을 해줘야 하는것이 있다.
1. 한글깨짐
2. 마이너스 부호 깨짐
3. jupyter notebook안에서 그려지는 그래프 확인

matplotlib 그래프 기본 형태
- plt.figure(figsize=(10,6)) 그래프를 그릴 바탕의 사이즈
- plt.plot(x,y) x축, y축 설정
- x축과 y축의 수는 동일해야 한다. 1:1대응으로 값이 나와야 하기 때문이다.
- plt.show() 설정한 그래프 그리기
예제1. 삼각함수 그리기
-
np.arange(a,b,s) : a부터 b까지 s간격으로
-
np.sin(value) : value값으로 sin그래프 그리기
-
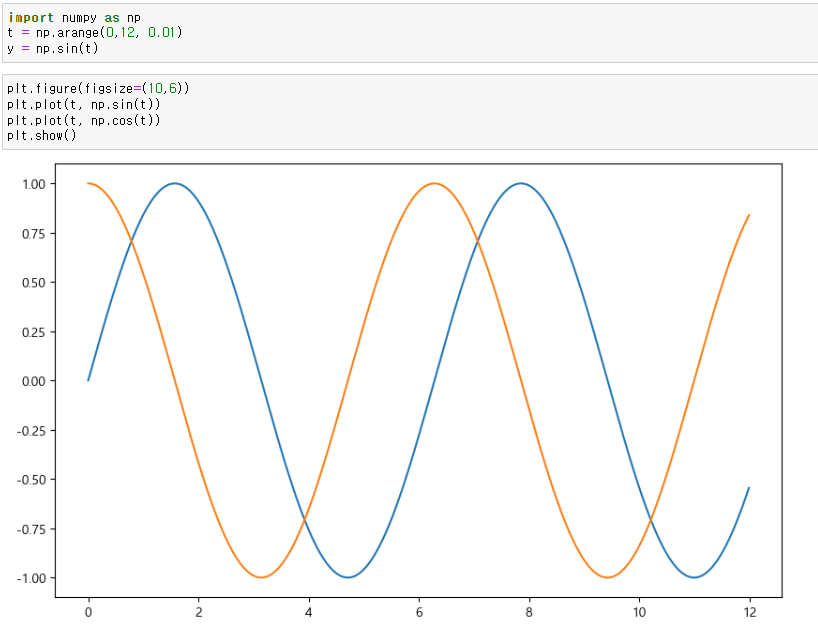
- 추가적으로 그래프를 더 구체적으로 커스터마이징을 할 수 있다.
- 격자무늬 추가
- 그래프 제목 추가
- x,y축 제목 추가
- 주황색, 파란색 선 데이터 의미 구분(범례)
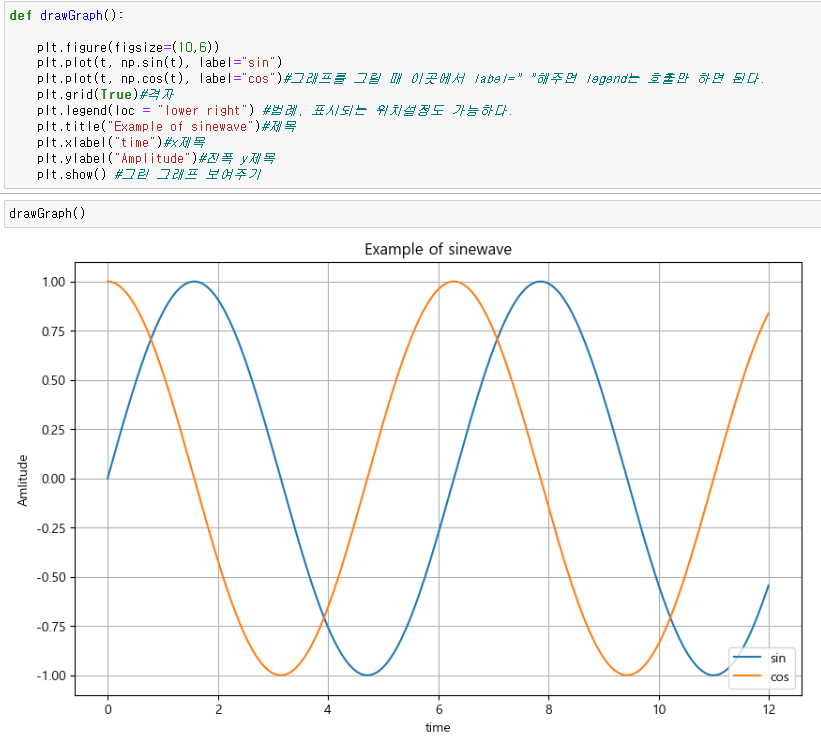
예제2. 그래프 커스터마이징
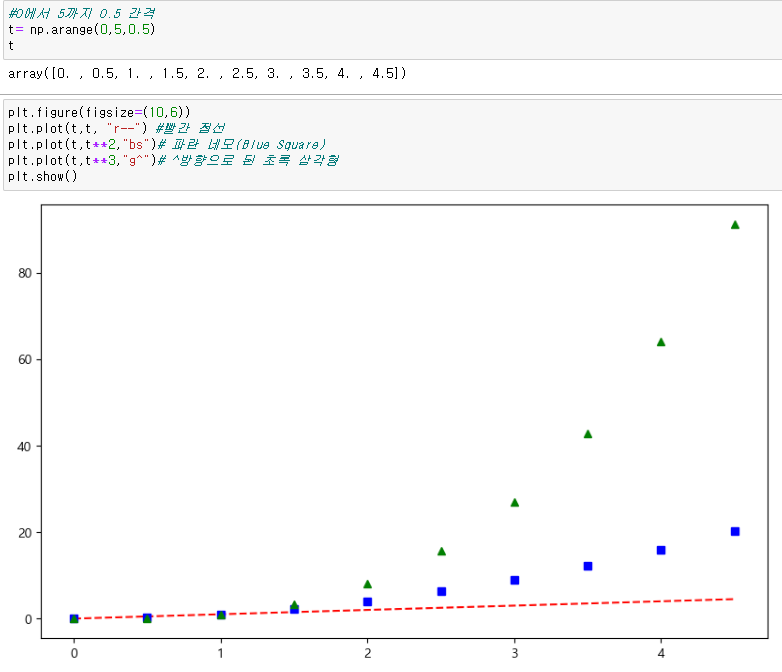
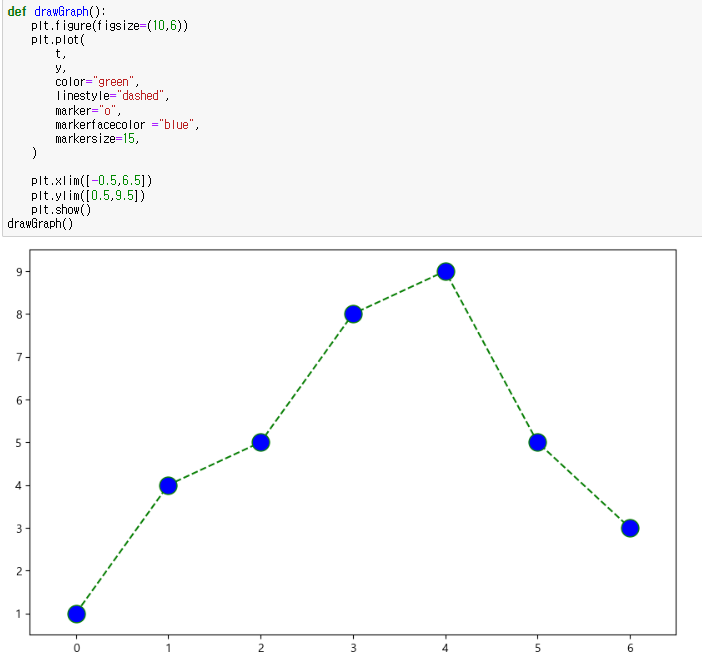
예제3. scatter plot
예제4. Pandas에서 plot그리기
- matplotlib을 가져와서 사용
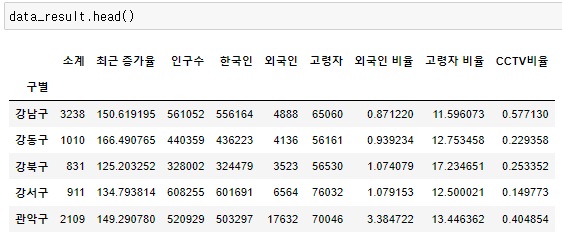
- 현재 데이터 프레임
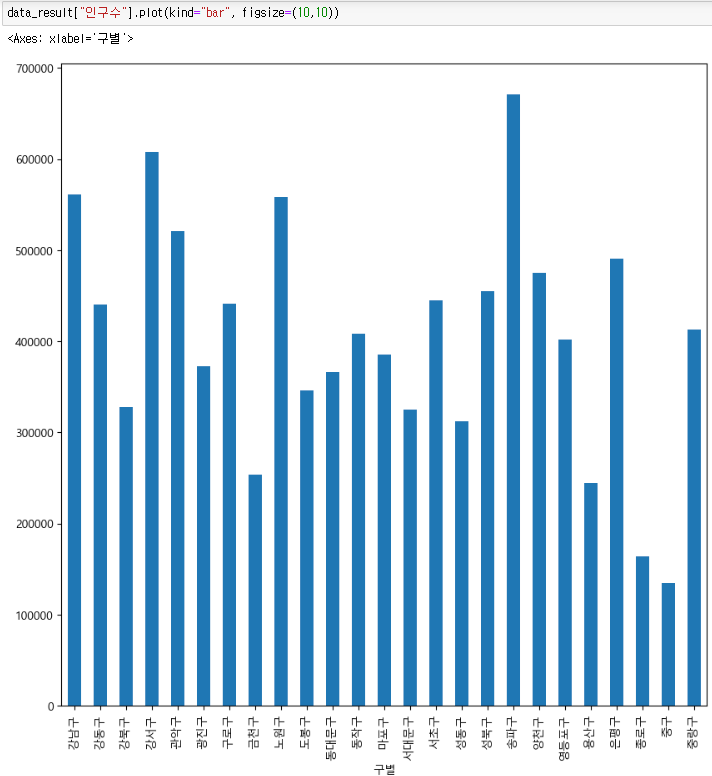
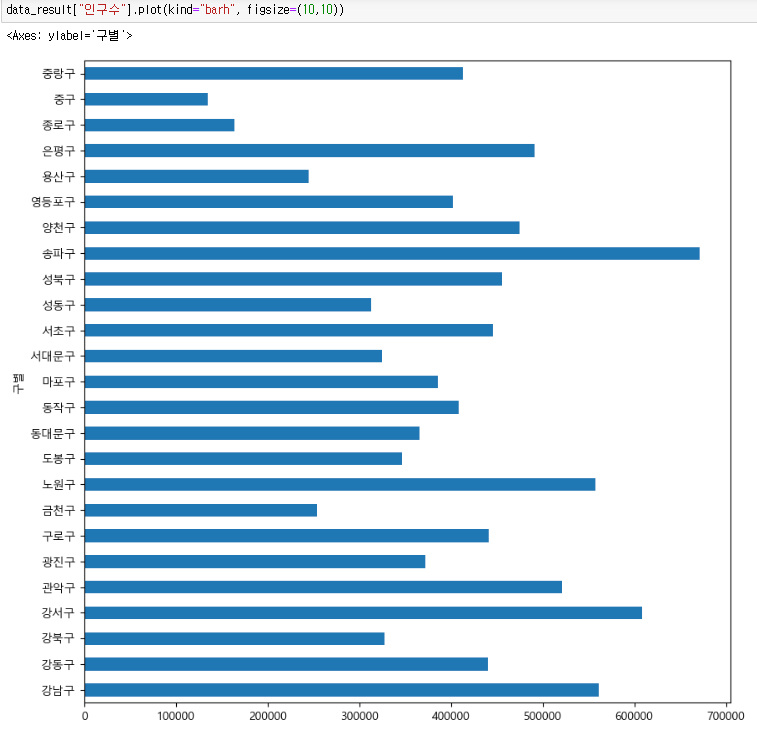
- key별 "인구수"컬럼을 가지고 bar형태의 그래프 10,10사이즈에 그리기
- barh = horizontal bar형태
5) 데이터 시각화
- matplotlib사용 전 세팅
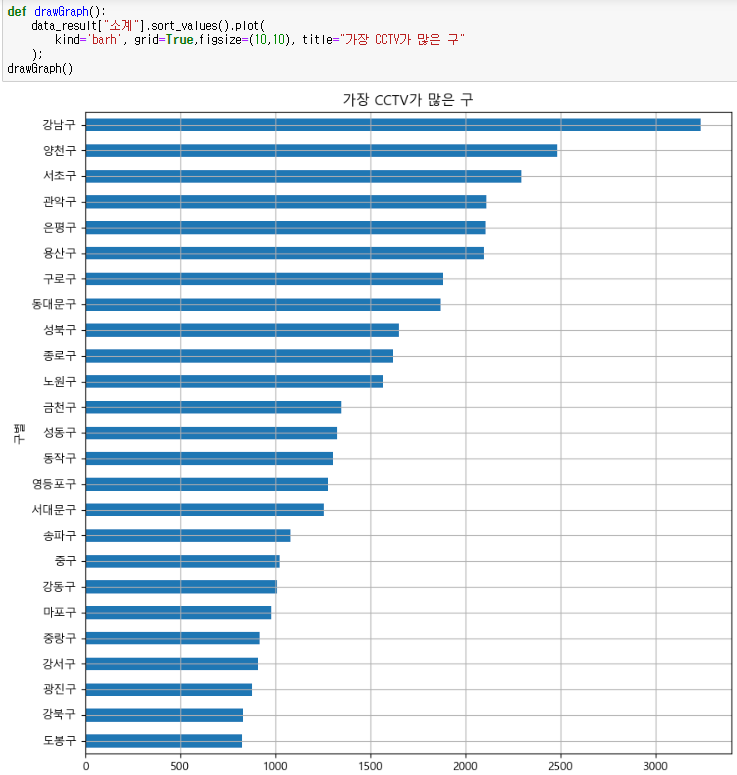
- 소계컬럼 오름차순 정렬시켜 그래프 그리시
- 강남구가 CCTV가 가장 많다
- 도봉구가 CCTV가 가장 적다.
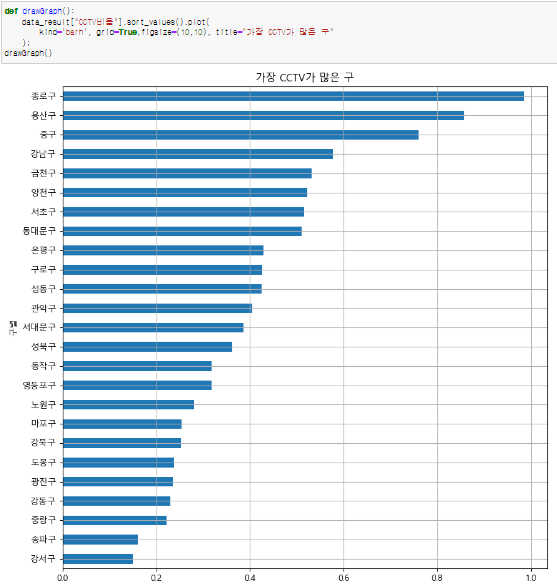
- "CCTV비율"컬럼 오름차순 정렬
- 인구대비 CCTV가 많은 지역은 종로구이다.
- 인구대비 CCTV가 적은 지역은 강서구이다.
6) 데이터 경향 표시
- 인구수와 소계 컬럼으로 scatter plot그리기
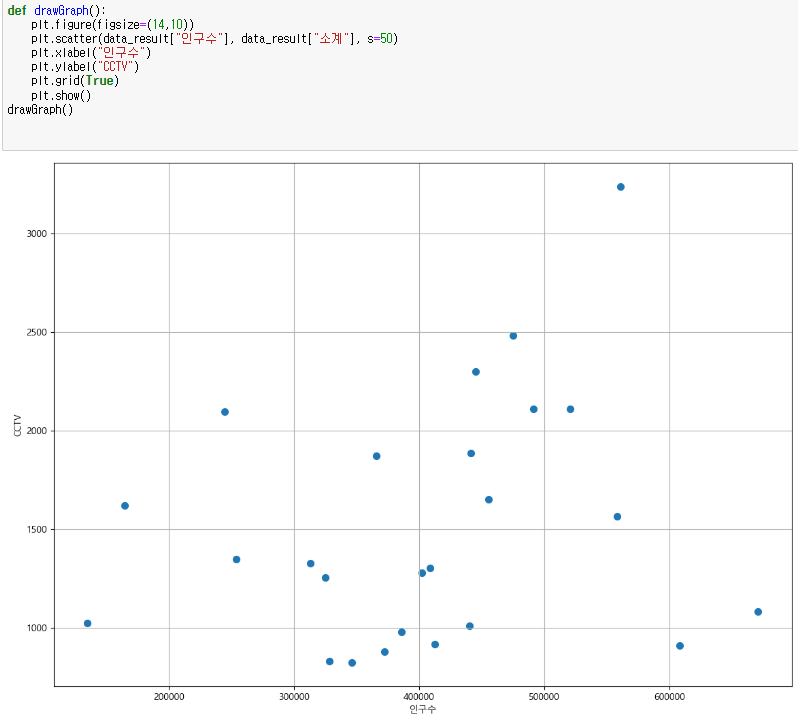
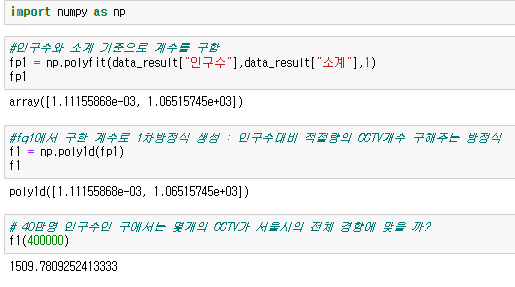
numpy를 이용한 1차직선 만들기
- np.polyfit() : 직선을 구성하기 위한 계수를 계산(기울기, y절편...)
- np.poly1d() : polyfit으로 찾은 계수를 이용해 파이썬에서 사용할 수 있는 함수로 만들어 주는 함수
- 경향성 구하기
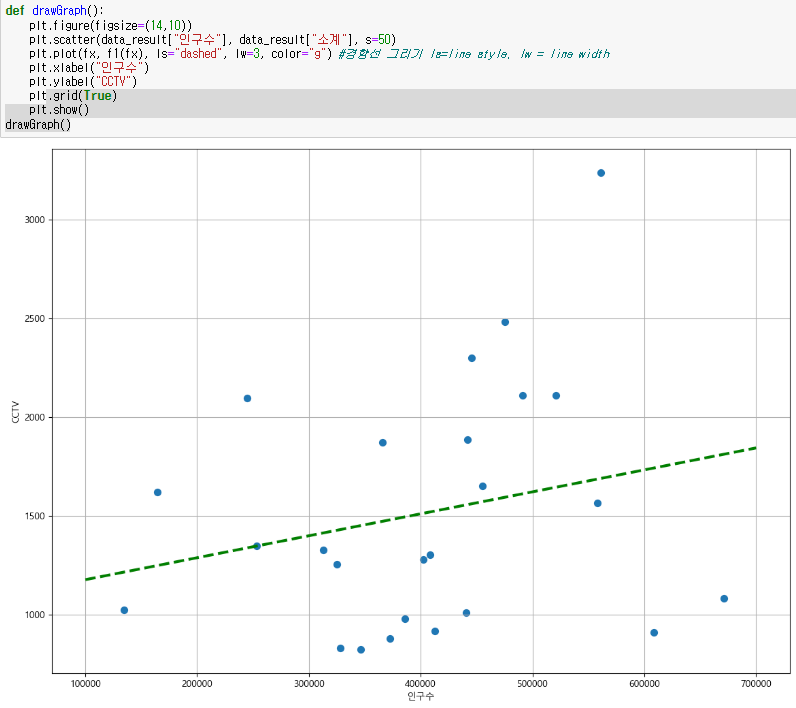
- linspace(a, b, n): a부터 b까지 n개의 동간격 데이터 생성

- 경향선이 추가된 그래프 그리기
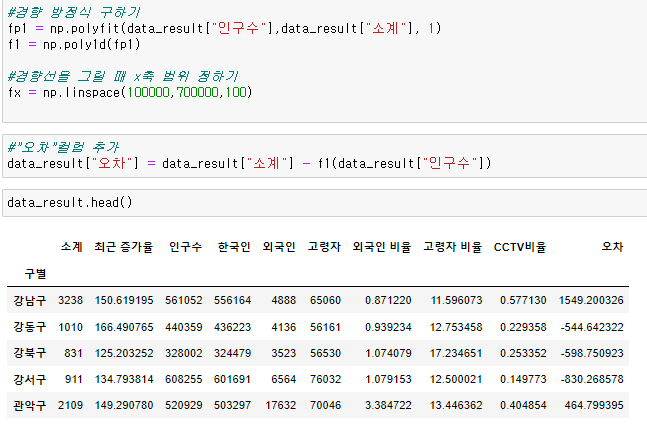
7) 강조하고 싶은 데이터를 시각화 하기
경향과의 오차 만들기
- 경향은 f1함수에 해당 인구를 입력
- f1(data_result["인구수"])
- 오차 는 현재 소계에서 경향을 빼면 된다.
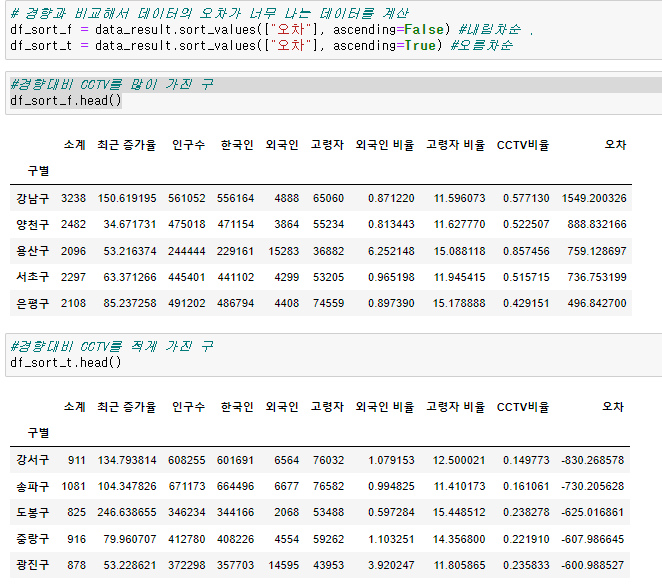
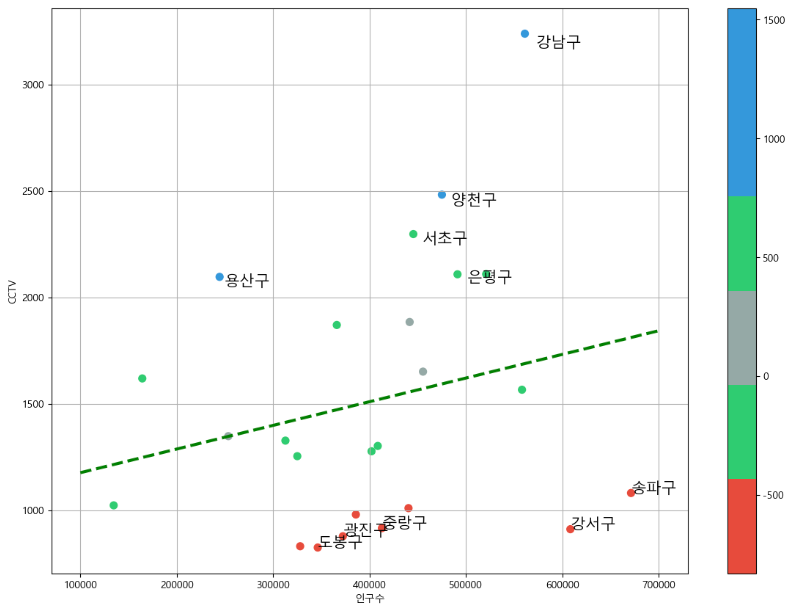
- color bar 사용자 정의

- 상위 5개 하위 5개 글자 출력하기 [plot.text(x좌표, y좌표, 출력될 글씨)]

- 최종결과
- 최종결과 .csv파일로 저장



취업공부