D&A 운영진 스터디
1.[D&A 운영진 딥러닝 스터디] 1주차 1차시

파이썬이 이용할 수 있는 모듈의 버전은 1개뿐이다.하지만, 여러 버전을 이용해야 할 필요성이 존재한다.이러한 경우에는 가상환경을 활용하면 된다.독립된 작업 공간으로, 각 공간 별로 모듈의 버전 다르게 설치 가능하다.가상 환경 실습(파이썬) - 윈도우사칙연산 수행 가능s
2.[D&A 운영진 딥러닝 스터디] 1주차 2차시
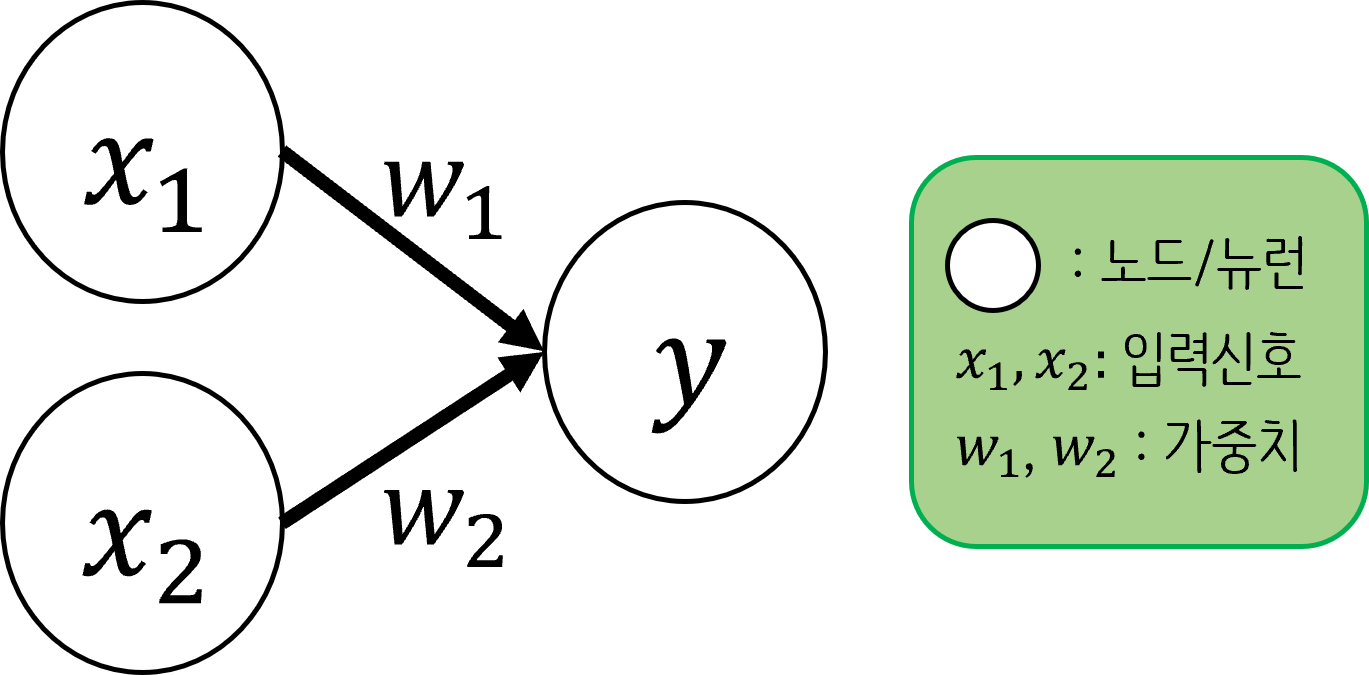
다수의 신호를 입력 받아 하나의 신호를 출력하는 것신호가 흐른다/안 흐른다(1/0)으로 나뉜다.인간의 뇌에 있는 뉴런(neuron)을 본떠 만듦(신호 전달)linear classifier 수행$$y = \\left{ \\begin{matrix} 0& w_1x_1+w_2
3.[D&A 운영진 딥러닝 스터디] 2주차 1차시

올바른 순서대로 학습을 진행최초 입력값으로부터 각 층마다 존재하는 가중치와 연산하고 활성화 함수를 통과하는 과정을 순서대로 이어나가 최종 layer까지 계산한 후 실제 label과 오차를 계산하는 것반대 방향으로 학습을 진행순전파에서 계산한 오차를 기반으로 기울기를 사
4.[D&A 운영진 딥러닝 스터디] 2주차 2차시
출처: https://www.cs.cmu.edu/~bapoczos/Classes/ML10715_2015Fall/slides/ManifoldLearning.pdf고차원 데이터를 저차원 데이터로 차원을 축소하여 표현하는 것sample을 모두 error없이 가져가는
5.[D&A 운영진 딥러닝 스터디] 3주차 1차시
컴퓨터 비전 문제는 이미지를 구성하는 픽셀 값을 input으로 사용일반적으로 input의 변수가 독립적이지만 이미지의 픽셀 값은 서로 독립이 아니다.MLP의 경우 이미지의 2차원 픽셀 값을 vector로 flatten하여 input으로 사용flatten 시, 가까운 위
6.[D&A 운영진 딥러닝 스터디] 3주차 2차시
이미지 분류 모델을 측정하기 위한 데이터로 가장 많이 사용하는 데이터셋2만 개 이상의 클래스와 약 1400만장의 이미지로 구성ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회에서 사용Yann LeCun 교수가
7.[D&A 운영진 딥러닝 스터디] 4주차 1차시
Text 데이터를 분석하고 모델링하는 분야NLU + NLG자연어 이해(NLU; Natural Language Understanding): 자연어를 이해하는 영역자연어 생성(NLG; Natural Language Generation): 자연어를 생성하는 영역NLP 과정T
8.[D&A 운영진 딥러닝 스터디] 4주차 2차시
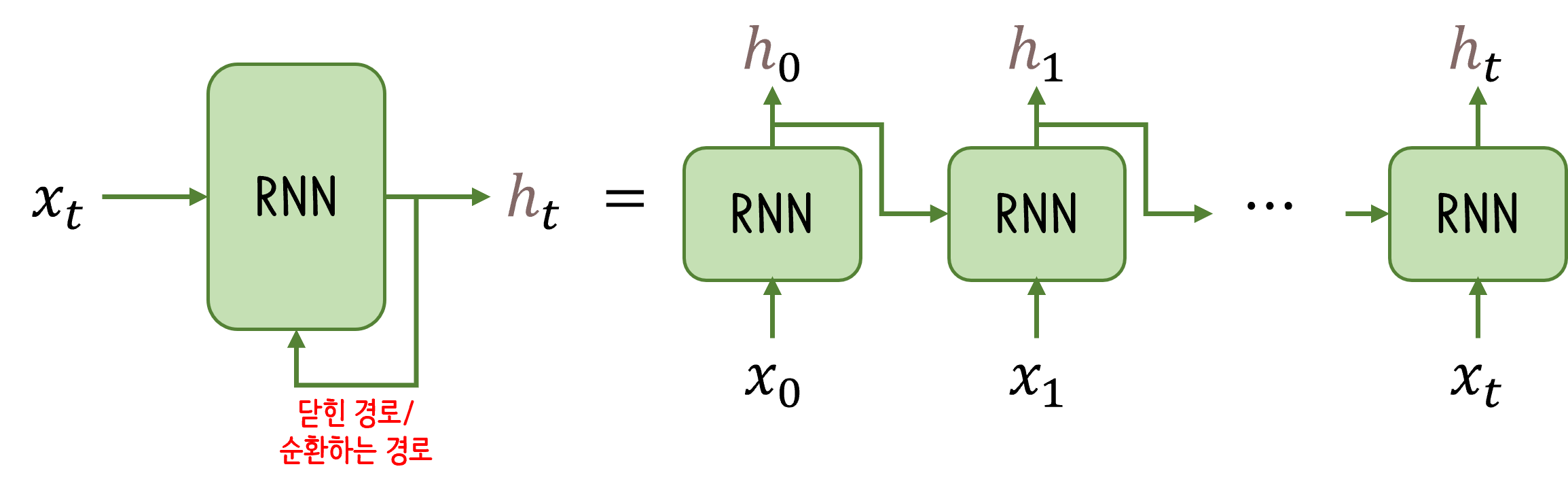
연속된 데이터의 정보 처리단어가 나올 확률은 이전 단어나 주변 단어에 따라 결정(연속적 관계)언어적 약속 ex) 먹고 싶습니다 요소 앞에는 먹을 것이 오며 단어에 받침이 있을 경우에는 이가 조사로 붙어야 함.Probability Language Model: 문장이 나타
9.[D&A 운영진 딥러닝 스터디] 5주차 1차시
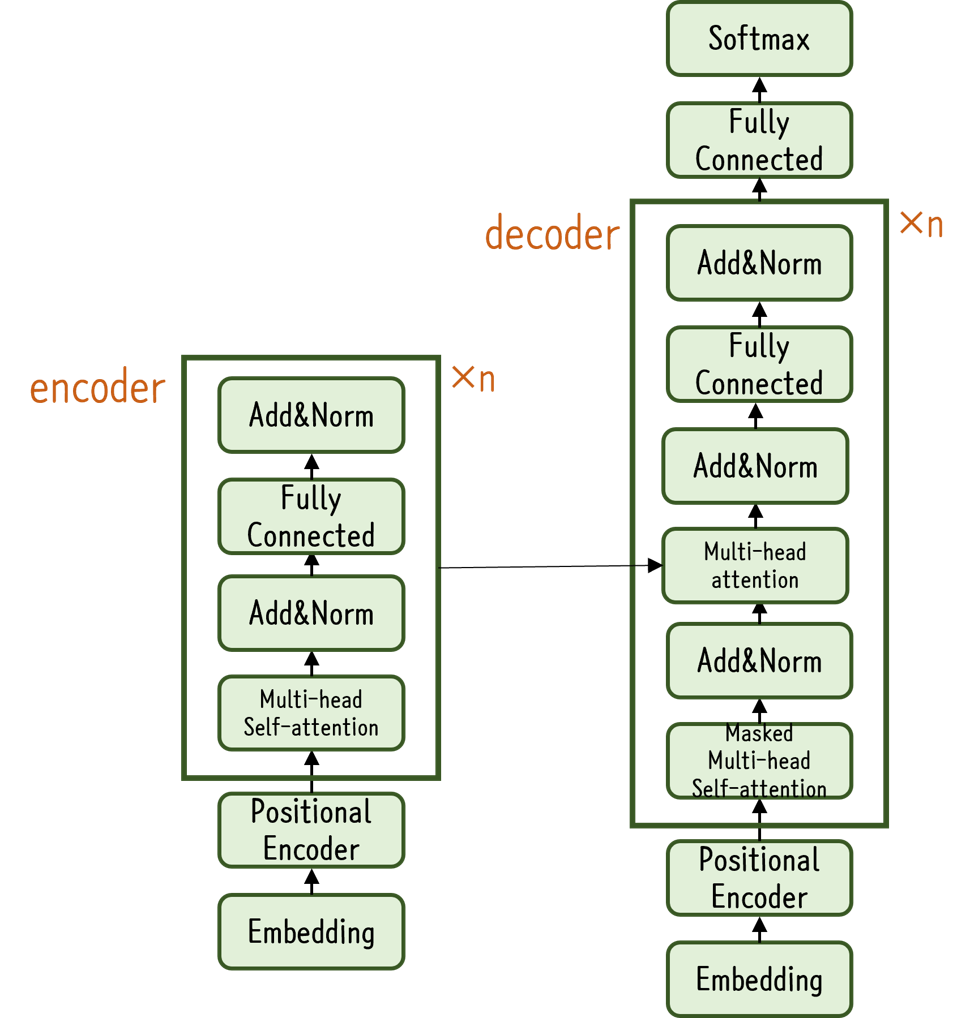
NLP 연구 분야의 큰 흐름 중 하나는 Attention Mechanism의 활용Encoder-Decoder 형식 보유Encoder가 특정 벡터로 정보를 저장하면 Decoder는 해당 정보를 이용해 Output 생성RNN 계열 모듈을 사용하지 않고 여러 개의 Atten
10.[D&A 운영진 딥러닝 스터디] 5주차 2차시
Generator와 Discriminator가 서로 대립적(Adversarial)으로 학습해가며 점차 성능 개선Generator는 데이터 생성Discriminator을 최대한 속이려고 노력Discriminator는 만들어진 데이터 평가진짜와 가짜 데이터를 구분하려고 노
11.[D&A 운영진 git 스터디] git, github
소스코드 버전 관리를 위한 오픈소스 소프트웨어기능버전 관리: 기능을 추가, 삭제, 수정 이력을 저장해뒀다가 자유롭게 버전 이동협력: 여러 개발자가 한 폴더 안에 모든 파일 모아두고 분업소스코드 공유git 원격 저장소 중 하나git으로 원격전송된 내역들이 저장되는 공간을
12.[D&A 운영진 ML 스터디] 1주차 1차시
데이터에서부터 학습하도록 컴퓨터를 프로그래밍하는 과학어떤 작업 $T$에 대한 컴퓨터 프로그램의 성능을 $P$로 측정했을 때 경험 $E$로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 $T$와 성능 측정 $P$에 대해 경험 $E$로 학습한 것학습하는 데 사용하는
13.[D&A 운영진 ML 스터디] 1주차 2차시
데이터 처리 컴포넌트들이 연속되어 있는 것머신러닝은 데이터를 조작, 변환할 일이 많아 파이프라인 사용보통 컴포넌트들은 비동기적으로 작동각 컴포넌트는 많은 데이터를 추출해 처리하고 결과를 다른 데이터 저장소로 보냄그 후 다른 컴포넌트가 그 데이터를 추출해 자신의 출력을
14.[D&A 운영진 ML 스터디] 2주차 1차시
정확도(Accuracy): 정확한 예측을 한 비율불균형한 데이터셋을 다룰 때 객관적이지 않음데이터셋에서 라벨이 A인 데이터가 90%, 라벨이 B인 데이터가 10%일 때, 모두 그냥 A로만 예측해도 정확도는 90%가 나옴오차 행렬(Confusion Matrix)오차 행렬
15.[D&A 운영진 ML 스터디] 2주차 2차시
모델이 어떻게 작동하는지 알면 적절한 모델, 올바른 알고리즘, 하이퍼파라미터 탐색, 디버깅, 에러 예측이 효율적으로 가능선형 회귀 - 두 가지 방법으로 훈련 가능train set에 가장 잘 맞는 파라미터를 해석적으로 구함경사 하강법 이용$\\hat y = \\theta
16.[D&A 운영진 ML 스터디] 3주차 1차시
두 클래스를 선형으로 분류선 1개로 클래스를 잘 분류해야 함이때 결정 경계가 샘플에 너무 가까우면 좋지 않음.멀어야 혹시나 관측하지 못한 데이터를 잘 예측할 수 있음$\\therefore$ 폭이 가장 넓은 도로를 찾는 것이 목표$\\Rarr$ Large Margin C
17.[D&A 운영진 ML 스터디] 3주차 2차시
export_graphviz 함수를 통해 그래프를 iris_tree.dot 파일로 출력해 시각화sample: 얼마나 많은 훈련 데이터가 해당 노드의 조건을 만족하는 수value: 각 클래스별 해당 노드의 조건을 만족하는 수gini: 불순도(impurity) 측정한 노드