파이썬이 이용할 수 있는 모듈의 버전은 1개뿐이다.
하지만, 여러 버전을 이용해야 할 필요성이 존재한다. ex) tensorflow 1.0 vs 2.0
이러한 경우에는 가상환경을 활용하면 된다.
가상환경
독립된 작업 공간으로, 각 공간 별로 모듈의 버전 다르게 설치 가능하다.
- 가상 환경 실습(파이썬) - 윈도우
pip install virtualenv # virtualenv 설치
virtualenv [가상환경 이름] # 가상환경 생성
virtualenv [가상환경 이름] -- python=3.6 # 파이썬 버전 지정
call [가상환경 이름]/scripts/activate # 가상환경 실행
deactivate # 가상환경 종료- 가상 환경 실습(파이썬) - 리눅스
virtualenv [가상환경 이름] # 가상환경 생성
virtualenv [가상환경 이름] -- python=3.6 # 파이썬 버전 지정
source [가상환경 이름]/bin/activate # 가상환경 실행
deactivate # 가상환경 종료- 가상 환경 실습(아나콘다) - 윈도우
conda create [가상환경 이름] # 가상환경 생성
conda create [가상환경 이름] pandas torch # 가상환경에 패키지 설치
conda create [가상환경 이름] python=3.6 # 파이썬 버전 지정
activate [가상환경 이름] # 가상환경 실행
deactivate # 가상환경 종료- 가상 환경 실습(아나콘다) - 리눅스
conda create [가상환경 이름] # 가상환경 생성
conda create [가상환경 이름] pandas torch # 가상환경에 패키지 설치
conda create [가상환경 이름] python=3.6 # 파이썬 버전 지정
source activate [가상환경 이름] # 가상환경 실행
source deactivate # 가상환경 종료Docker
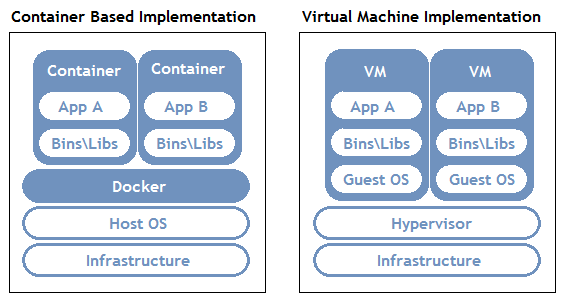 출처 : Docker Container Aqua (aquasec.com)
출처 : Docker Container Aqua (aquasec.com)
모듈 별로 다른 버전이 아니라 각 프로그래밍 버전 및 개발 환경 자체를 독립적인 공간으로 활용해 관리할 수 있는 컨테이너 오픈소스 가상화 플랫폼
- 각 컨테이너 내 프로그램, DB, 서버 등으로 다양하게 구성 가능
- 각 컨테이너를 독립적으로 활용 가능
GPU
딥러닝의 경우 각 레이어의 노드 수가 증가할수록, 깊이가 깊어질수록 파라미터 수는 급격히 증가한다.
이렇게 많은 수의 파라미터를 이용해 설계할 때는 CPU보다 GPU가 훨씬 계산 속도가 빠르다.
- CPU는 고차원적인 일을 수행할 수 있는 능력을 보유하고 있지만 너무 많은 수의 파라미터 값을 계산하기에는 속도가 느림.
- CPU는 코어 수가 10개 미만인 것에 비해 GPU는 수 백개에서 수 천개를 갖는다.
- 따라서 단순한 병렬적인 계산에 적합한 GPU 사용하는 것이 좋다.
GPU를 설치한 후, 파이썬에서 인식할 수 있도록 하기 위해 CUDA 사용
CUDA
GPU에서 병렬처리를 수행하는 알고리즘을 각종 프로그래밍 언어에 사용할 수 있도록 해주는 GPGPU기술
CuDNN(nvidia CUDA Deep Neural Network Library)
딥러닝 모델을 위한 GPU 가속화 라이브러리의 기초 요소와 같은 일반적인 루틴을 빠르게 이행할 수 있도록 해주는 라이브러리
데이터 표현 단위

torch.tensor()을 이용해 데이터 정의
Scalar
상수(하나의 값을 표현할 때 1개의 수치로 표현)
scalar1 = torch.tensor([1])
scalar2 = torch.tensor([3])- 사칙연산 수행 가능
scalar1 + scalar2 # 덧셈
scalar1 - scalar2 # 뺄셈
scalar1 * scalar2 # 곱셈
scalar1 / scalar2 # 나눗셈- 메소드를 사용하여 사칙연산 수행 가능
torch.add(scalar1, scalar2) # 덧셈
torch.sub(scalar1, scalar2) # 뺄셈
torch.mul(scalar1, scalar2) # 곱셈
torch.div(scalar1, scalar2) # 나눗셈Vector
하나의 값을 표현할 때 2개 이상의 수치로 표현
vector1 = torch.tensor([1,2,3])
vector2 = torch.tensor([4,5,6])- scalar와 동일하게 연산기호와 메소드를 사용하여 사칙연산 수행 가능(element-wise)
- 벡터 내적 연산 가능
torch.dot(vector1, vector2) # torch.dot()은 벡터 내적 계산만 가능
torch.matmul(vector1, vector2)Matrix
2개 이상의 벡터 값을 통합해 구성된 값
matrix1 = torch.tensor([[1,2],[3,4]])
matrix2 = torch.tensor([[5,6],[7,8]])- vector와 동일하게 사칙연산 수행 가능(element-wise)
- 행렬곱 연산 가능
torch.matmul(matrix1, matrix2)
torch.mm(matrix1, matrix2) # torch.mm()은 행렬에서만 수행 가능Tensor
2차원 이상의 배열
tensor1 = torch.tensor([[[1,2],[3,4]],[[5,6],[7,8]]])
tensor2 = torch.tensor([[[9,10],[11,12]],[[13,14],[15,16]]])- matrix와 동일하게 사칙연산 수행 가능(element-wise)
- 텐서곱 연산 가능 (동일 차원 행렬 간 행렬곱)
torch.matmul(tensor1, tensor2)- LongTensor: 원소로 정수(integer) 사용할 때 사용
- FloatTensor: 계산을 위한 원소에 사용, 원소가 실수(float)
- ByteTensor: True/False 사용 시 사용
Tensor Manipulation
pytorch에서는 tensor을 다루는 방법이 numpy와 유사
- 2D Tensor (Typical Simple Setting)
- (batchsize, dimension)
- 3D Tensor (Typical Computer Vision)
- (batch size, width, height)
- 여러 장의 이미지(width*height)
- 3D Tensor (Typical Natural Language Processing)
- (batch size, length, dimension)
- batch size 개수 만큼 문단 존재
Dimension&Shape
t = torch.tensor([[1,2,3], [4,5,6],
[7,8,9],[10,11,12]])
t.dim() # tensor의 차원 수 반환
t.shape # tensor의 형상 반환
t.size() # shape와 같은 기능Broadcasting
사칙연산 시에는 shape이 일치해야 하는데, 그렇지 않더라도 자동적으로 shape을 맞춰 계산하는 것
ex1)
m1 = torch.tensor([[1,2]])
m2 = torch.tensor([3]) # [3] -> [[3,3]]
m1+m2ex2)
m1 = torch.tensor([[1,2]]) # [[1,2]] -> [[1,2],[1,2]]
m2 = torch.tensor([[3],[4]]) # [[3],[4]] -> [[3,3],[4,4]]
m1+m2mean
mean은 LongTensor에는 잘 수행하지 못하므로 FloatTensor 활용
t = torch.FloatTensor([[1,2],[3,4]])
t.mean() # 원소 전체의 평균
t.mean(dim=0) # 각 dimension 0(행)을 고정하고 나머지의 평균
t.mean(dim=1) # 각 dimension 1(열)을 고정하고 나머지의 평균
t.mean(dim=-1) # 마지막 dimension을 고정하고 나머지의 평균sum
t = torch.tensor([[1,2],[3,4]])
t.sum()
t.sum(dim=0)
t.sum(dim=1)
t.sum(dim=-1)max/argmax
t = torch.tensor([[1,2],[3,4]])
t.max()
t.max(dim=0)
t.max(dim=1)
t.max(dim=-1) # dim을 주면 argmax도 같이 내보내준다.
t.argmax() # max인 값의 위치(index)view
형상(shape) 바꿔줌, np.reshape()과 같은 역할 수행
t = torch.tensor([[[0,1,2],[3,4,5]],
[[6,7,8],[9,10,11]]])
t.view([-1,3]) # -1을 인자로 줄 시, 나머지에 맞춰 shape 바꿔줌
# (2,2,3) -> (4,3) # 원소들의 곱이 동일하면 view 사용 가능Squeeze
1차원으로 바꿔줌
t = torch.tensor([[0],[1],[2]])
t.squeeze() # (3,1) -> (3,)Unsqueeze
squeeze를 반대로 수행함
t = torch.tensor([0,1,2])
t.unsqueeze(0) # dim=0, dimension 0에 1 입력해 view 수행 # (3,) -> (1,3)
t.unsqueeze(1) # dim=1, dimension 1에 1 입력해 view 수행 # (3,) -> (3,1)Type Casting
tensor type 변환
lt = torch.LongTensor([1,2,3,4])
lt.float() # FloatTensor로 변환bt = torch.ByteTensor([True, False, False, True])
bt.long() # LongTensor로 변환
bt.float() # FloatTensor로 변환Concatenate
x = torch.tensor([[1,2],[3,4]])
y = torch.tensor([[5,6],[7,8]])
torch.cat([x,y], dim=0) # dim 0이 늘어남
torch.cat([x,y], dim=1) # dim 1이 늘어남Stacking
concatenate 편리하게 이용
x = torch.tensor([1,4])
y = torch.tensor([2,5])
z = torch.tensor([3,6])
torch.stack([x,y,z]) # dim=0, dimension 0(행)으로 쌓는다.
torch.stack([x,y,z], dim=1) # dim=1, dimension 1(열)으로 쌓는다.concatenate으로 같은 결과 도출하려면 아래 코드 실행해야 함.
torch.cat([x.unsqueeze(0), y.unsqueeze(0), z.unsqueeze(0)], dim=0)
torch.cat([x.unsqueeze(1), y.unsqueeze(1), z.unsqueeze(1)], dim=1)Ones/Zeros
x = torch.tensor([[0,1,2],[2,1,0]])
torch.ones_like(x) # 똑같은 shape로 영행렬 만듦
# device를 통일해서 수행해야 error 안나기 때문에 사용
torch.zeros_like(x)In-place Operation
x = torch.tensor([[1,2],[3,4]])
x.mul(2) # 실행결과가 변수에 저장되지 않는다.
x.mul_(2) # _ 추가 시, 메모리에 새로 선언하지 않고 정답값에 바로 넣음Autograd
파이토치를 이용해 코드를 작성할 때, 오차역전파법을 이용해 파라미터를 업데이트하는 방법은 Autograd방식으로 쉽게 구현할 수 있도록 설정
if torch.cuda.is_available(): # GPU를 이용해 계산할 수 있는지 파악(True, False 반환)
DEVICE = torch.device('cuda') # cuda 장비 사용
else:
DEVICE = torch.device('cpu') # cpu 장비 사용
BATCH_SIZE = 64 # 파라미터를 업데이트할 때 한번에 계산되는 데이터 개수
# BATCH_SIZE 만큼 데이터를 이용해 output 계산하고 이에 대한 오차 계산
# 오차 평균해 역전파법 적용하고 파라미터 업데이트
INPUT_SIZE = 1000 # Input의 크기(데이터 1개의 크기)이자 입력층의 노드 수
# Input Size 크기를 갖는 데이터 Batch_Size개 이용
HIDDEN_SIZE = 100 # 다수의 파라미터를 이용해 계산한 결과에 한번 더 계산되는 파라미터 수, 은닉층 노드 수
OUTPUT_SIZE = 10 # 최종으로 출력되는 값의 벡터 크기
# 비교하고자 하는 레이블의 크기와 동일하게 설정(원핫인코딩 이용하기 때문)torch.randn: 평균이 0, 표준편차가 1인 정규분포에서 샘플링한 값
x: input, y: output, w1: 가중치1, w2: 가중치2
x = torch.randn(BATCH_SIZE, INPUT_SIZE, # 크기가 input_size인 데이터 batch_size개 생성
device = DEVICE, # 위에서 정의한 도구(CUDA/CPU) 사용
dtype = torch.float, # 데이터 형식 실수로 설정
requires_grad = False) # 학습(파라미터 업데이트)이 필요없으므로 gradient 계산 필요 없음
y = torch.randn(BATCH_SIZE, OUTPUT_SIZE, # 크기가 output_size인 데이터 batch_size개 생성
device = DEVICE,
dtype = torch.float,
requires_grad = False) # 학습(파라미터 업데이트)이 필요없으므로 gradient 계산 필요 없음
w1 = torch.randn(INPUT_SIZE, HIDDEN_SIZE, # x와 행렬곱을 통해 (hidden_size, batch_size)를 만들어야 하므로 다음과 같은 형상
device = DEVICE,
dtype = torch.float,
requires_grad = True) # 학습(파라미터 업데이트)이 필요하므로 gradient 계산 필요
w2 = torch.randn(HIDDEN_SIZE, OUTPUT_SIZE, # 은닉층 (hidden_size, batch_size)와 행렬곱을 통해 output(output_size, batch_size)를 만들어야 하므로 다음과 같은 형상
device = DEVICE,
dtype = torch.float,
requires_grad = True) # 학습(파라미터 업데이트)이 필요하므로 gradient 계산 필요
learning_rate = 1e-6 # 학습률(gradient에 따른 학습 정도) 결정
for t in range(1, 501): # 500번 학습(epochs=500)
y_pred = x.mm(w1).clamp(min=0).mm(w2) # torch.mm()을 사용해 가중치와 행렬곱 적용 후, clamp(min=0)로 활성화 함수 적용(ReLU와 같은 역할)
loss = (y_pred - y).pow(2).sum() # 오차 계산
if t % 100 == 0: # 100번째 반복마다
print(f"Iteration: {t}\t Loss: {loss.item()}") # 반복 횟수 및 오차 표시
loss.backward() # 오차역전파법 수행
with torch.no_grad(): # gradient 계산 결과 이용해 파라미터 업데이트할 때는 gradient값 고정
w1 -= learning_rate * w1.grad # 가중치 업데이트
w2 -= learning_rate * w2.grad # 가중치 업데이트
w1.grad.zero_() # gradient를 통해 파라미터 업데이트 했으므로 다시 학습을 위해 graident 0으로 초기화
w2.grad.zero_()참고
모두를 위한 딥러닝 시즌2 Lab 1-1, 1-2
파이썬 딥러닝 파이토치 (이경택, 방성수, 안상준)
