요약 : 파이썬100문 day2, 벡터연산 개념정리, 리스트를 활용한 벡터연산(차원확장)
벡터 개념 정리
vector-vector operations
- hadamard product : 원소끼리의 곱. 벡터값으로 나옴
x1,y1,z1=1,2,3
x2,y2,z2=3,4,5
x3,y3,z3=x1+x2,y1+y2,z1+z2
x4,y4,z4=x1-x2,y1-y2,z1-z2
x5,y5,z5=x1*x2,y1*y2,z1*z2
# ㄴhadamard product 원소끼리의 곱
# cf)dot product는 원소끼리의 곱의 합. 스칼라로 나옴scalar-vector operations
- 스칼라 : 숫자 하나, 벡터는 화살표=숫자뭉치
- 중요한 것 : print해보기, shape뽑아보기!!!!!
- numpy의 broadcasting기법은 서로 다른 차원끼리의 연산을 가능하게 해줌. 여기서 shape이 더더욱 중요함
a=10
x1,y1,z1=1,2,3
x2,y2,z2=a*x1,a*y1,a*z1
x3,y3,z3=a+x1,a+y1,a+z1
x4,y4,z4=a-x1,a-y1,a-z1vector norm
-feature개수는 이론적으로 무한대. 2개만 쓰는 경우는 잘 없음. 3~4개까지 씀. 일단 2차원에서 feature space를 먼저 이해해보면 이와 같음.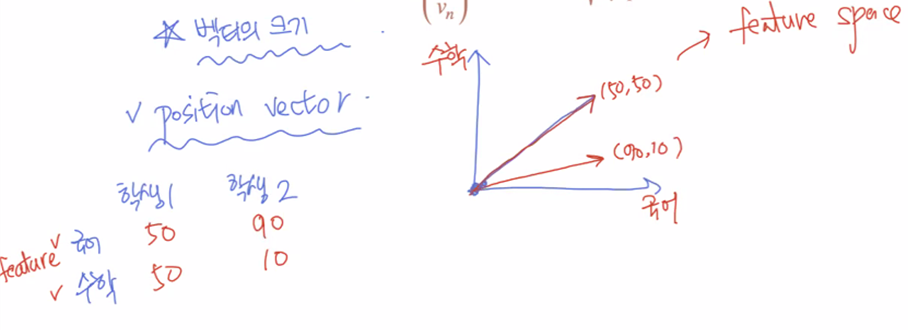
x,y,z=1,2,3
norm=(x**2+y**2+z**2)**0.5making unit vectors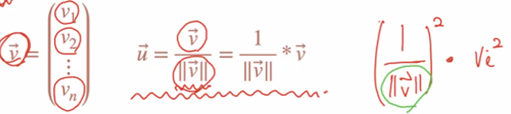
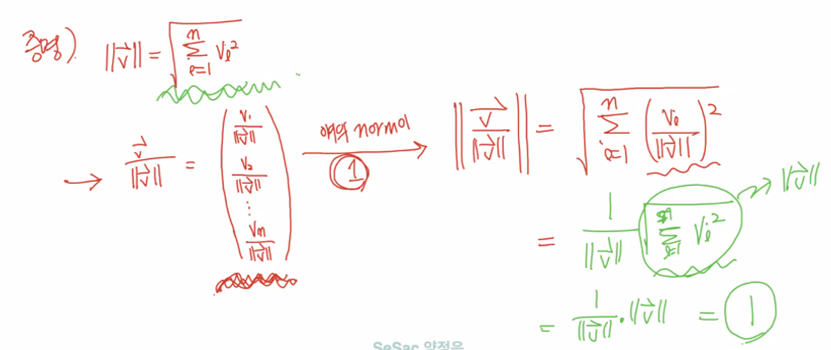
x,y,z=x/norm,y/norm,z/norm
norm=(x**2+y**2+z**2)**0.5dot product "내적"
- 앞에서 본 hadamard product는 원소끼리 곱한 거고, 결과값 벡터로 나옴
- dot product는 원소끼리 곱한 것을 시그마로 다 더해준 거라서 결과값 스칼라로 나옴
- dot product 식
- vi*ui의 시그마 값
- cos세타 x v벡터놈 x u벡터놈 -> cosine similarity
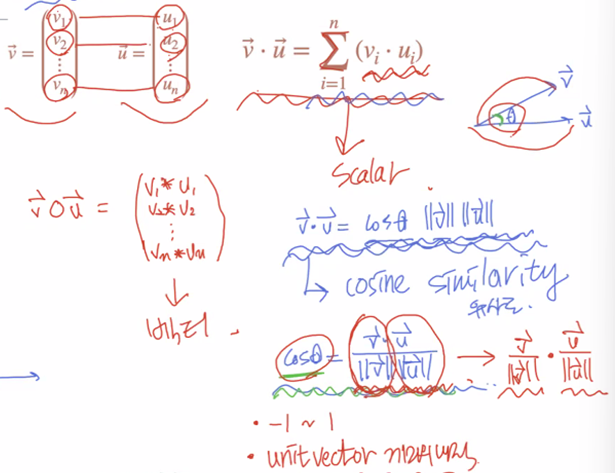
- 내적식으로 cos similarity(cosine 유사도)가 도출됨.
-cos세타=단위벡터끼리의 내적 -> 단위벡터가 정규화 역할을 한다는 것이 설명되는 것. 단위벡터는 각 벡터의 영향에 상관없이, 각 벡터 사이의 세타값을 통해서 유사도를 도출함.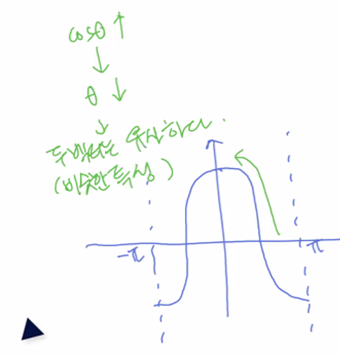
x1,y1,z1=1,2,3
x2,y2,z2=3,4,5
dot_prod=x1*x2+y1*y2+z1*z2euclidean distance
x1,y1,z1=1,2,3
x2,y2,z2=3,4,5
e_distance=(x1-x2)**2+(y1-y2)**2+(z1-z2)**2
e_distance**=0.5MSE(Mean Squared Error)
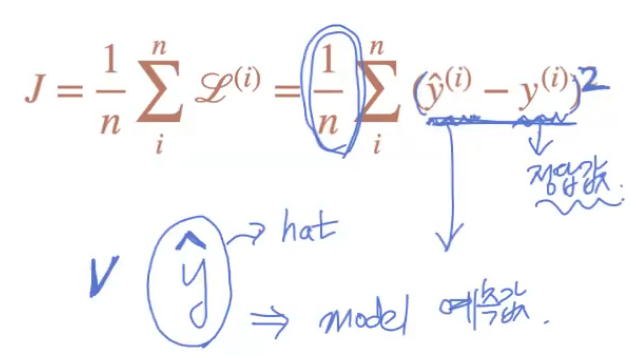
- squared error, mean squared error
- ^ = hat, y^(y hat) : 모델의 예측값(이렇게 분류될 것이다~하는 예측)
- 모델의 성능을 평가하는 여러 지표 중 하나
- error를 제곱해서 다 더해서 평균 냈기 때문에 'mean squared error'
pred1, pred2, pred3 = 10, 20, 30
y1, y2, y3 = 10, 25, 40
n_data=3
s_error1 = (pred1 - y1)**2
s_error2 = (pred2 - y2)**2
s_error3 = (pred3 - y3)**2
print(s_error1, s_error2, s_error3) #squared error
mse=(s_error1 + s_error2 + s_error3)/n_data
print(mse)리스트 활용
mean subtraction(2), standardization(2)
- 리스트를 활용하기 때문에 차원 확장된 것!
-변수명 만들때는 단수형 복수형 지켜서 만들어주는게 좋음
-len함수 쓰면 좋은게, 데이터 수정될때마다 고칠 필요가 없기때문
scores=[10,20,30] #단수형 복수형 지켜서 만들어주는게 좋음
n_student=len(scores) #len함수 쓰면 좋은게, 데이터 수정될때마다 고칠 필요가 없기때문
mean=(scores[0]+scores[1]+scores[2])/n_student
print("score mean: ", mean)
#--------------------------------------------------------
#mean subtraction2
scores[0]-=mean
scores[1]-=mean
scores[2]-=mean
mean=(scores[0]+scores[1]+scores[2])/n_student
print("score mean: ", mean)
#분산과 표준편차2
square_of_mean=mean**2
mean_of_square=(scores[0]**2+scores[1]**2+scores[2]**2)/n_student
variance=mean_of_square-square_of_mean
std=variance**0.5
print("score standard deviation: ",std)
#standardization2
scores[0]=(scores[0]-mean)/std
scores[1]=(scores[1]-mean)/std
scores[2]=(scores[2]-mean)/std
square_of_mean=mean**2
mean_of_square=(scores[0]**2+scores[1]**2+scores[2]**2)/n_student
variance=mean_of_square-square_of_mean
std=variance**0.5
print("score mean: ", mean)
print("score standard deviation: ",std)list 기본문법
- 리스트생성
v1=list() 혹은 v1=[] - 리스트요소 추가
v1.append() - for loop으로 list의 원소에 접근하기
scores=[10,20,30]
#method.1
for score in scores:
print(score)
#method.2 인덱스[]로 접근하기 중요!
for score_idx in range(len(scores)):
print(scores[score_idx])- for loop로 list의 원소 수정하기
scores2=[10,20,30,40,50]
for score_idx in range(len(scores2)):
scores2[score_idx]+=10- 두 개의 list에 인덱스를 활용해서 접근하기
list1=[10,20,30]
list2=[100,200,300]
for idx in range(len(list1)):
print(list1[idx],list2[idx])ㄴ인덱스 활용하는 것이 중요한 부분임!
- 초기화된 변수 활용해서 for loop로 리스트에 있는 원소값 더하기
-원소값 곱할거면 초기화시킬때 1로 지정해야함
score_sum=0
for score in scores:
score_sum+=score- Iteration(반복)횟수 구하기
-별 의미 없을 때 언더스코어 처리. _대신 i넣어도 같은 값 나옴
numbers=[1,4,5,6,4,2,1]
iter_cnt=0
for _ in numbers:
iter_cnt+=1- 1부터 100까지의 합
num_sum=0
for i in range(101):
num_sum+=i- 1부터 100까지 list만들기
numbers=list()
for i in range(1,101):
numbers.append(i)- 100개의 0 가진 list
numbers=list()
for i in range(100):
numbers.append(0)- 1부터 n까지의 숫자 합 구하는 공식
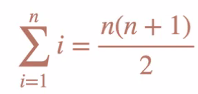
리스트를 활용한 여러 계산
평균구하기
scores=[10,20,30]
#method.1
score_sum=0
n_student=0
for score in scores:
score_sum+=score
n_student+=1
score_mean=score_sum/n_student
print("score mean: ",score_mean)
#method.2
score_sum=0
for score_idx in range(len(scores)):
score_sum+=scores[score_idx]
score_mean=score_sum/len(scores)
print("score mean :",score_mean)mean subtraction
#method1
scores_ms=list()
for score in scores:
scores_ms.append(score-score_mean)
print(scores_ms)
#method2
for score_idx in range(len(scores)):
scores[score_idx]-=score_mean
print(scores)Hadamard Product
- 벡터의 원소끼리의 곱
- cf) dot product는 원소끼리의 곱의 합. 스칼라로 나옴
#method.1
v1,v2=[1,2,3],[3,4,5]
v3=[v1[0]*v2[0],v1[1]*v2[1],v1[2]*v2[2]]
print(v3)
#method.2
v1,v2=[1,2,3],[3,4,5]
v3=[0,0,0]
v3[0]=v1[0]*v2[0]
v3[1]=v1[1]*v2[1]
v3[2]=v1[2]*v2[2]
print(v3)
#method.3 - append기능을 이용한 hadamard
v1,v2=[1,2,3],[3,4,5]
v3=list()
v3.append(v1[0]*v2[0])
v3.append(v1[1]*v2[1])
v3.append(v1[2]*v2[2])
print(v3)vector norm
v1=[1,2,3]
#method1
norm=(v1[0]**2+v1[1]**2+v1[2]**2)**0.5
print(norm)
#method2
norm=0
norm+=v1[0]**2
norm+=v1[1]**2
norm+=v1[2]**2
norm**=0.5
print(norm)unit vector
v1=[1,2,3]
norm=(v1[0]**2+v1[1]**2+v1[2]**2)**0.5
print(norm)
v1=[v1[0]/norm,v1[1]/norm,v1[2]/norm]
norm=(v1[0]**2+v1[1]**2+v1[2]**2)**0.5
print(norm)dot product
v1,v2=[1,2,3],[3,4,5]
#method1
dot_prod=v1[0]*v2[0]+v1[1]*v2[1]+v1[2]*v2[2]
print(dot_prod)
#method2
dot_prod=0
dot_prod+=v1[0]*v2[0]
dot_prod+=v1[1]*v2[1]
dot_prod+=v1[2]*v2[2]
print(dot_prod)euclidean distance
e_distance=0
e_distance+=(v1[0]-v2[0])**2
e_distance+=(v1[1]-v2[1])**2
e_distance+=(v1[2]-v2[2])**2
e_distance**=0.5
print(e_distance)MSE(mean squared error)
predictions=[10,20,30]
labels=[10,25,40]
n_data=len(predictions)
mse=0
mse+=(predictions[0]-labels[0])**2
mse+=(predictions[1]-labels[1])**2
mse+=(predictions[2]-labels[2])**2
mse/=n_data
print(mse)
안녕하세요를레히