요약 : 표준화계산, 파이썬100문 day3, 차원 계속 확장중, 여러가지 min max 계산, 벡터연산, min-max normalization
- mean subtraction과 standardization을 반복하는 것은 차원을 계속 확장되고 있기 때문임. 저번에는 스칼라 하나(하나의 값)이었다면 이번에는 리스트로 작업 중. 차원이 더 확장되면 복수개의 리스트->행렬 등으로 계속 심화됨.
- 내적 기호가 o임.
- mean subtraction과 standardization은 별개임. mean subtraction은 사분면에서 zero-centered하는 역할이고 standardization은 표준화...(둘다 표준화 방법)
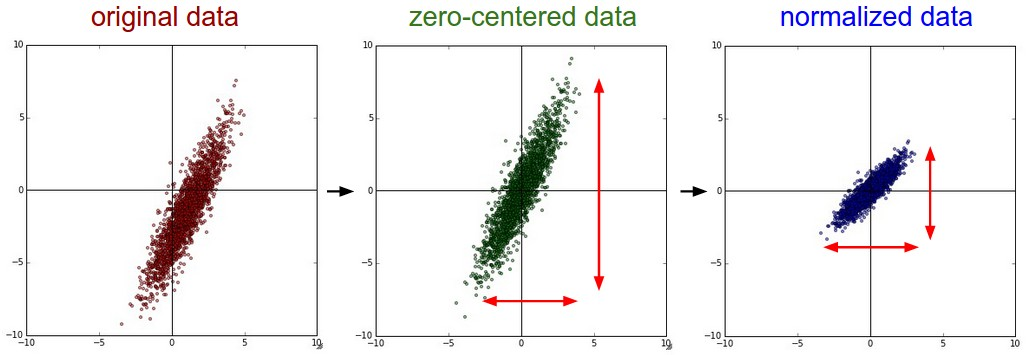
Common data preprocessing pipeline. Left: Original toy, 2-dimensional input data. Middle: The data is zero-centered by subtracting the mean in each dimension. The data cloud is now centered around the origin. Right: Each dimension is additionally scaled by its standard deviation. The red lines indicate the extent of the data - they are of unequal length in the middle, but of equal length on the right.
표준화계산
- 리스트2개로 차원확장됨! 세번째진행.
mean subtraction
- for _ in range(n_class):
score_sums.append(0)
-빈리스트라서 그 안에 math, english 자리 두 개 만들어 준 거임. 그냥 바로 리스트에 넣을 순 없음
#두 과목 평균 구하기
math_scores=[40,60,80]
english_scores=[30,40,50]
n_class=2
n_student=len(math_scores)
score_sums=list()
score_means=list()
for _ in range(n_class)
score_sums.append(0)
for student_idx in range(n_student):
score_sums[0]+=math_scores[student_idx]
score_sums[1]+=english_scores[student_idx]
print("sums of scores: ",score_sums)
for class_idx in range(n_class):
class_mean=score_sums[class_idx]/n_student
score_means.append(class_mean)
print("means of scores: ",score_means)
#mean subtraction(4)
for student_idx in range(n_student):
math_scores[student_idx]-=score_means[0]
english_scores[student_idx]-=score_means[1]분산과 표준편차(3)
scores=[10,20,30]
n_student=len(scores)
score_sum,score_square_sum=0,0
for score in scores:
score_sum+=score
score_square_sum+=score**2
mean=score_sum/n_student
square_of_mean=mean**2
mean_of_square=score_square_sum/n_student
variance=mean_of_square-square_of_mean
std=variance**0.5
print("variance: ",variance)
print("standard deviation: ",std)
print(scores) #standardization전 scoresstandardization(3)
for student_idx in range(n_student):
scores[student_idx]=(scores[student_idx]-mean)/std
print(scores)#standardization후 scores
#위에 <분산과 표준편차(3)>과정 반복
n_student=len(scores)
score_sum,score_square_sum=0,0
for score in scores:
score_sum+=score
score_square_sum+=score**2
mean=score_sum/n_student
square_of_mean=mean**2
mean_of_square=score_square_sum/n_student
variance=mean_of_square-square_of_mean
std=variance**0.5
print("mean: ",mean)
print("standard deviation: ",std)분산과 표준편차(4)
math_scores,english_scores=[50,60,70],[30,40,50]
n_student=len(math_scores)
math_sum,english_sum=0,0
math_square_sum,english_square_sum=0,0
for student_idx in range (n_student):
math_sum+=math_scores[student_idx]
math_square_sum+=math_scores[student_idx]**2
english_sum+=english_scores[student_idx]
english_square_sum+=english_scores[student_idx]**2
math_mean=math_sum/n_student
english_mean=english_sum/n_student
math_variance=math_square_sum/n_student-math_mean**2
english_variance=english_square_sum/n_student-english_mean**2
math_std=math_variance**0.5
english_std=english_variance**0.5
print("mean/std of Math: ",math_mean,math_std)
print("mean/std of English: ",english_mean,english_std)standardization(4)
for student_idx in range(n_student):
math_scores[student_idx]=(math_scores[student_idx]-math_mean)/math_std
english_scores[student_idx]=(english_scores[student_idx]-english_mean)/english_std
print("Math scores after standardization: ",math_scores)
print("English scores after standardization: ",english_scores)
#위에 <분산과 표준편차(4)>과정 반복
n_student=len(math_scores)
math_sum,english_sum=0,0
math_square_sum,english_square_sum=0,0
for student_idx in range (n_student):
math_sum+=math_scores[student_idx]
math_square_sum+=math_scores[student_idx]**2
english_sum+=english_scores[student_idx]
english_square_sum+=english_scores[student_idx]**2
math_mean=math_sum/n_student
english_mean=english_sum/n_student
math_variance=math_square_sum/n_student-math_mean**2
english_variance=english_square_sum/n_student-english_mean**2
math_std=math_variance**0.5
english_std=english_variance**0.5
print("mean/std of Math: ",math_mean,math_std)
print("mean/std of English: ",english_mean,english_std)벡터연산
Hadamard Product
v1=[1,2,3,4,5]
v2=[10,20,30,40,50]
#method.1
v3=list()
for dim_idx in range(len(v1)):
v3.append(v1[dim_idx]*v2[dim_idx])
print(v3)
#method.2
v3=list()
for _ in range(len(v1)):
v3.append(0)
for dim_idx in range(len(v1)): #dim=dimension
v3[dim_idx]=v1[dim_idx]*v2[dim_idx]
print(v3)
#list바로 선언 안되는 이유
v3=[v1[dim_idx]*v2[dim_idx]]
print(v3)vector norm(3)
square_sum=0
for dim_val in v1:
square_sum+=dim_val**2
print("square_sum of v1: ",square_sum)
norm=square_sum**0.5
print("norm of vl: ",norm)making unit vectors(3)
for dim_idx in range(len(v1)):
v1[dim_idx] /= norm #자기자신의 norm으로 나눔
#norm으로 나눈 값을 다시 vertor norm(3) 계산 거침
square_sum=0
for dim_val in v1:
square_sum+=dim_val**2
print("square_sum of v1: ",square_sum)
norm=square_sum**0.5
print("norm of v1: ",norm)dot product(3)
v1,v2=[1,2,3],[3,4,5]
dot_prod=0
for dim_idx in range(len(v1)):
dot_prod+=v1[dim_idx]*v2[dim_idx]euclidean distance(3)
diff_square_sum=0
for dim_idx in range(len(v1)):
diff_square_sum+=(v1[dim_idx]-v2[dim_idx])**2
print(diff_square_sum)
e_distance=diff_square_sum**0.5MSE(Mean Squared Error)
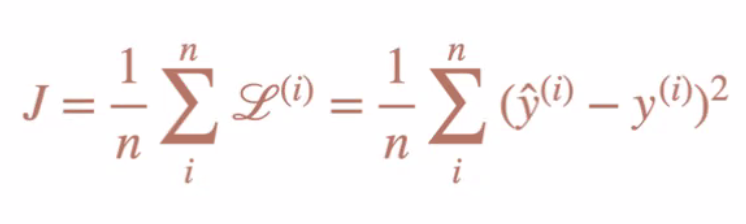
predictions=[10,20,30]
labels=[10,25,40]
n_data=len(predictions)
diff_square_sum=0
for data_idx in range(n_data):
diff_square_sum+=(predictions[data_idx]-labels[data_idx])**2
mse=diff_square_sum/n_data파이썬 기본문법
for문 연습
#for문 연습.
numbers=[0,2,4,2,1,4,3,1,2,3,4,1,2,3,4]
number_cnt=[0,0,0,0,0]
for num in numbers:
number_cnt[num]+=1 #인덱스 활용한 것. number_cnt[인덱스번호(0 1 2 3 4)]
print(number_cnt)
#0 1개, 1 3개, 2 4개, 3 3개, 4 4개if문 단순크기비교
score=60
cutoff=70
if score>50:
print("Pass!")
if score>cutoff:
print("Pass!")
else:
print("Try Again!")num1,num2=10,12
if num1>num2:
print("first number")
elif num1==num2:
print("equal")
else:
print("second number")if문 성적데이터 활용
- 성적으로 등급매기기
score=70
if score>80:
grade='A'
elif score>60:
grade='B'
elif score>40:
grade='C'
else:
grade='F'
print("Grade: ",grade)- 성적들의 등급매기기
scores=[20,50,10,60,90]
grades=list()
for score in scores:
if score>80:
grades.append('A')
elif score>60:
grades.append('B')
elif score>40:
grades.append('C')
else:
grades.append('F')
print(grades)- 합격/불합격 학생들의 평균 구하기
cutoff=50 #커트라인
pass_score_sum,n_pass=0,0
fail_score_sum,n_fail=0,0
for score in scores:
if score>cutoff:
pass_score_sum+=score
n_pass+=1
else:
fail_score_sum+=score
n_fail+=1
pass_score_mean=pass_score_sum/n_pass
fail_score_mean=fail_score_sum/n_fail
print("mean of passed scores: ",pass_score_mean)
print("mean of failed scores: ",fail_score_mean)- for, if문 크기비교-리스트데이터
scores=[20,50,10,60,70]
cutoff=50
for score in scores:
if score>cutoff:
print("Pass!")
else:
print("Try Again!")- #if문-시분초 계산
seconds=3600
if seconds>=3600:
hours=seconds//3600
seconds-=hours*3600
else:
hours=0
if seconds>=60:
minutes=seconds//60
seconds-=minutes*60
else:
minutes=0
print(hours,"hr",minutes,"min",seconds,"sec")- if문-홀수(odd)/짝수(even) 구하기
#method.1
number=10
if number%2==0:
print("Even!")
else:
print("Odd!")
#method.2
numbers=list()
for num in range(20): #range(20) : 0~19
numbers.append(num)
numbers.append(3.14)
print(numbers)
for num in numbers:
if num%2==0:
print("Even Number")
elif num%2==1:
print("Odd Number")
else:
print("Not an Interger") #interger인티저:정수- n배수들의 합 구하기
-multiple_of 변수로 몇배수인지 지정. 이 예시에서는 0~99 사이의 3의배수의 합
multiple_of=3
numbers=list()
for num in range(100):
numbers.append(num)
sum_multiple_of_n=0
for num in numbers:
if num%multiple_of==0:
sum_multiple_of_n+=num
print(sum_multiple_of_n)파이썬기본-min, max
for,if문-최댓값 최솟값 구하기
#method.1 : 최댓값은 0, 최솟값은 100으로 초기화
scores=[60,40,70,20,30]
M,m=0,100
#but 이건 추천하지 않음. why 지금은 데이터값이 0~100사이의 점수값인거 대충 앎
#근데 100을 훨씬 넘거나 음수값이 있는 경우 제대로 돌아가지 않음
for score in scores:
if score>M:
M=score
if score<m:
m=score
print("Max value: ",M)
print("min value: ",m)
#method.2 데이터값 범위가 더 다양한 경우
scores=[-20,60,40,70,120]
#method.2-1 : 최댓값최솟값을 list 맨 첫값으로 초기화
M,m=scores[0],scores[0] #scores[0]=-20
for score in scores:
if score>M:
M=score
if score<m:
m=score
print("Max value: ",M)
print("Min value: ",m)
#method.2-2 : 최댓값최솟값을 none으로 초기화, for loop돌면서 list맨 첫 값 넣게됨
M,m=None,None
for score in scores:
if M==None or score>M:
M=score
if m==None or score<m:
m=score
print("Max value: ",M)
print("Min value: ",m)min-max normalization
- 정규화의 한 방법.
-0~1 사이로 값이 들어감
-피처 간 스케일의 범위를 좁혀주는 역할
-스케일이 큰 피처가 영향력을 크게 미치게 되니까, 그 영향력을 줄여주고자 정규화와 같은 스케일링(전처리)를 거친다.
-정규화는 영어로 normalization, standardization, regularization
-용어가 뭐인지는 중요하지 않고, 어떤 방법론을 쓰는지가 더 중요함
#앞에서 이어서 min-max normalization 진행!!
for score_idx in range(len(scores)):
scores[score_idx]=(scores[score_idx]-m)/(M-m)
print("scores after normalization:n",scores) # :n???????????뭐쓸려고 했던거지
#2-2방식으로 최댓값최솟값 다시 찾기
M,m=None,None
for score in scores:
if M==None or score>M:
M=score
if m==None or score<m:
m=score
print("Max value: ",M)
print("Min value: ",m)기타 최댓값최솟값 관련 작업
- 최댓값, 최솟값의 위치구하기
scores = [60, -20, 40, 120, 70]
M,m = None,None
M_idx,m_idx = 0, 0
for score_idx in range(len(scores)):
score=scores[score_idx]
if M==None or score>M:
M=score
M_idx=score_idx
if m==None or score<m:
m=score
m_idx=score_idx
print("M/M_idx: ",M,M_idx)
print("m/m_idx: ",m,m_idx)- 최댓값과 최솟값의 위치를 이용하여 list정렬
-M,M_idx = scores[0], 0
-> M : 인덱스 내의 값, M_idx : 인덱스번호
-for score_idx in range(len(scores)):
-> list의 인덱스로 접근하는 것
-원화기호가 역슬래시랑 같은 역할. 줄바꿈기호
scores=[40,20,30,10,50]
sorted_scores=list()
for _ in range(len(scores)):
M,M_idx = scores[0], 0
for score_idx in range(len(scores)):
if scores[score_idx] > M:
M = scores[score_idx]
M_idx = score_idx
tmp_scores = list()
for score_idx in range(len(scores)):
if score_idx == M_idx:
sorted_scores.append(scores[score_idx])
else:
tmp_scores.append(scores[score_idx])
scores=tmp_scores
print("remaining scores: ", scores)
print("sorted scores: ", sorted_scores,'\n')
안녕하세요를레히