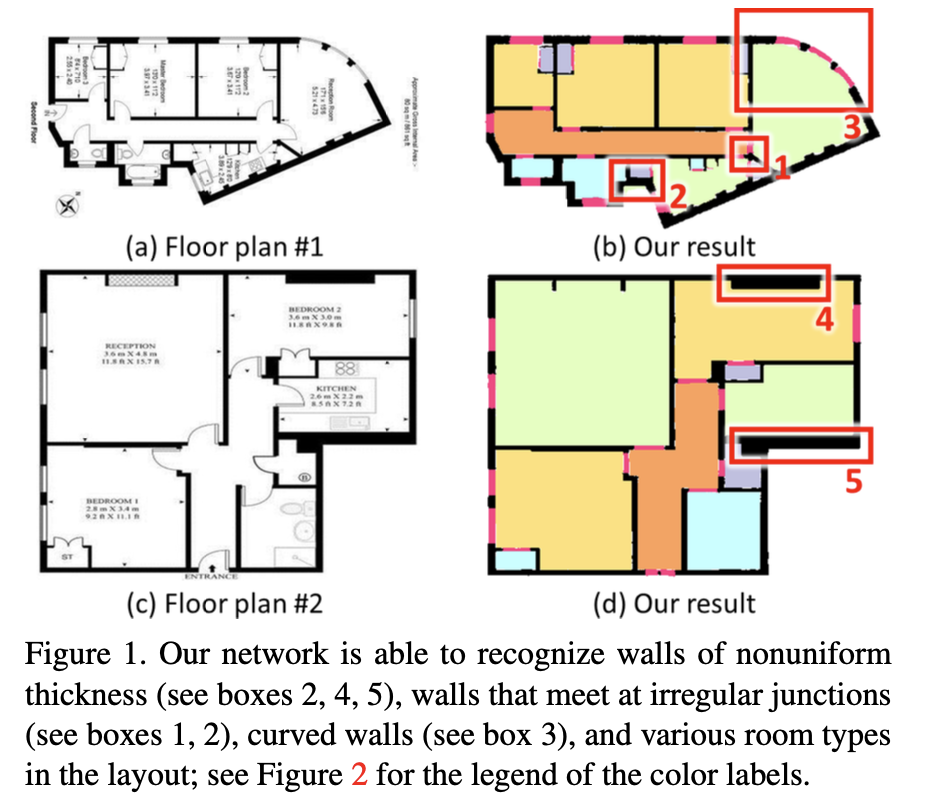
논문 리뷰: Deep Floor Plan Recognition Using a Multi-Task Network with Room-Boundary-Guided Attention
프로젝트
Keywords
- A hierarchy of labels for the floor plan elements.
- Room-boundary-guided attention mechanism.
- Spatial Contextual Module.
- Cross-and-Within-Task Weighted Loss.
- Within-Task Weighted Loss
- Cross-Task Weighted Loss
- Entropy
- Room Boundary & Room Type
- Encoder - Decoder
Summary
평면도 인식을 위해, Room을 구성하는 Room Bondary의 정보를 활용하여 Room Type 학습에 이득을 준다. Room Boundary Guided Attention과 Multi-Task Network 가 포인트.
-
Room Boundary Guided Attention: Room Type 예측(Walls, Doors, Windows) 을 위해 중요한 요소인 Room Boundary를 활용하여 Room Type 학습에 필요한 Attention Weights를 학습한다.
-
Spatial Contextual Module: Room Boundary 학습으로 얻은 어텐션 가중치를 의미하며, Room Type Prediction에 개입한다.
-
Spatial Contextual Feature: Room Type과 Room Boundary를 동일 차원(예. 동일 해상도)에서 연결하여 Contextual Feature 생성.(이미지의 Red Box)
-
Multi-Task Network: Room Boundary 와 Room Type을 동시에 학습하는 신경망이다. Decoder가 2개의 브랜치로 학습어 Multi-Task Network라고 정의한다.
구성
데이터셋 및 레이블
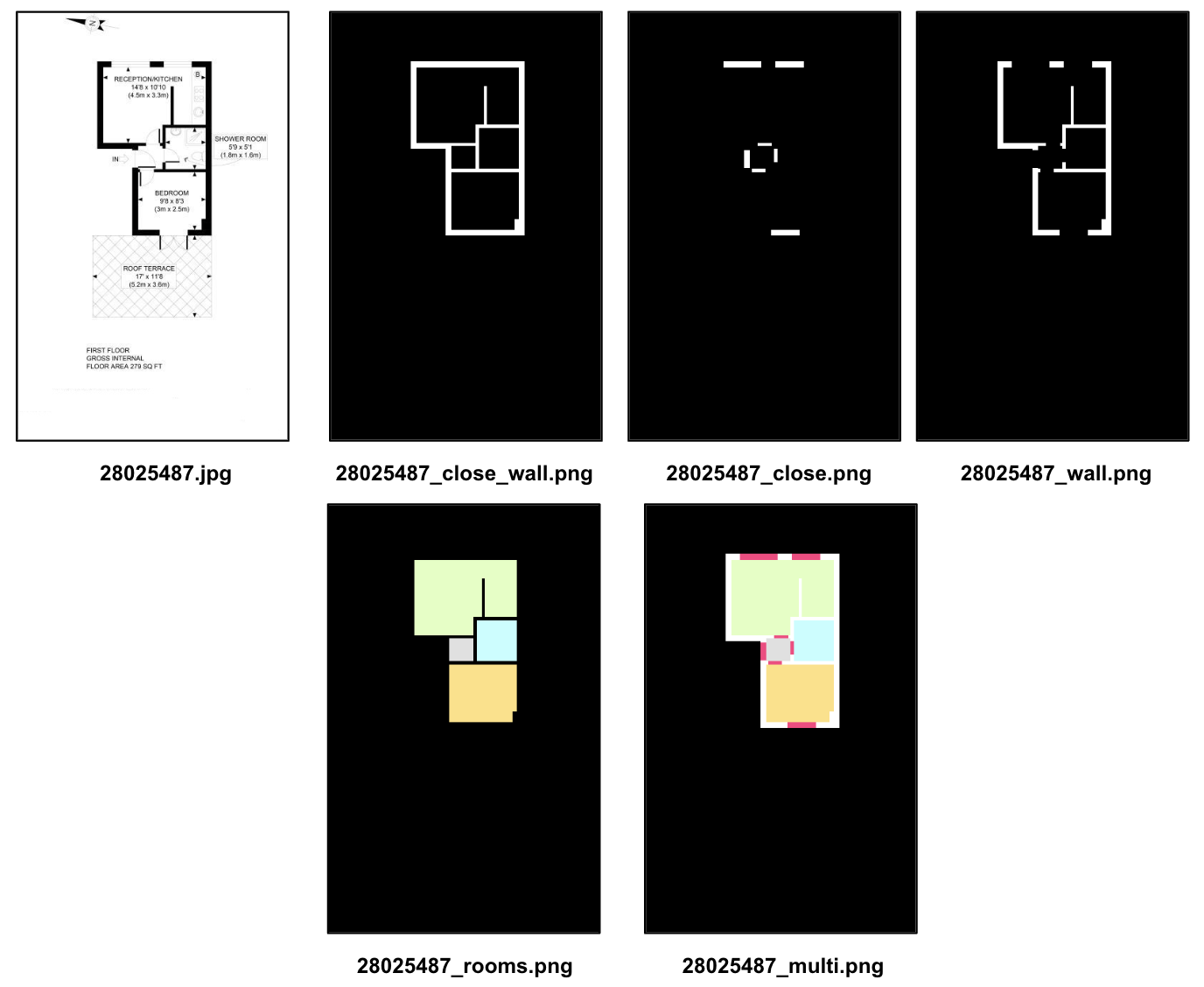
라벨은 Room Boundary 학습에 필요한close_wall, close_close, wall, Room Type 학습에 필요한 rooms 가 있는것으로 확인된다. multi는 아마도, Contextual Feature 결과가 아닐까라는 추측이다.
추가로, 논문에서는 r3d, r2d 데이터셋을 사용한다. 하지만 실제로, 코드내에서는 해당 데이터셋이 아닌,r3d.tfrecords 라는 파일로 dataset을 로드하여 학습하는데, 아마도 이미지를 tfrecords라는 파일로 변환하는 방법이 있는 것 같다.
def loadDataset(size: int = 512) -> tf.data.Dataset:
raw_dataset = tf.data.TFRecordDataset("r3d.tfrecords")
parsed_dataset = raw_dataset.map(_parse_function)
return parsed_dataset- 추가 :
- tfrecords는 다수의 데이터(이미지, 라벨, 메타데이타 등)를 Serialize하여 바이너리로 .tfrecords 형식으로 저장한다.
- "_close_wall.png"은 실제 논문에서 사용하지는 않음
- "_multi.png"은 모든 레이블 조합이고, 일반적인 세그멘테이션 네트워크를 재학습시 사용한다.
- tfrecord 파일 변환 코드: https://github.com/zlzeng/DeepFloorplan/tree/master/utils
- 색상 레이블 관련 코드: https://github.com/zlzeng/DeepFloorplan/blob/master/utils/rgb_ind_convertor.py
네트워크

-
Input Image > VGG Encoder > Shared Feature 학습 > 2개의 분기된 VGG Decoder 브랜치 (Multi Task Layer)로 전달
-
Blue Box (Room Boundary Features) > Top Decoder 에서 3x3 Conv Layer로 2D Feature Map 생성! > Attention Weights (Spatial Contextual Module) 학습
-
Green Box (Room Type Features) > Bottom Decoder 에서 3x3 Conv Layer로 2D Feature Map 생성 > Attention Weights 와 곱연산 > K unit의 Direction Kernel 과 합연산 >> Room Type Feature 와 Concatenate >> Spatial Contextual Feature 생성
Attention Weight는 2번 적용된다. 첫번쨰 Attention Weights는 노이즈 특징 압축을 위해 Room Type Feature에서 생성된 2D Feature Map과 곱연산 한다. 수식으로 표현하면

이어서 4개의 방향을 고려한 K-Unit Direction Kernels (수평 / 수직 / 대각 1/ 대각 2)로 특징을 처리 후 합연산하여, Attention Weights를 곱연산하여 Blurring 을 감쇄한다. 수식으로 표현하면,

이후 Room Type Feature와 같은 차원에서 연결하여 Spatial Contextual Feature를 생성하는 과정임.
이를, 다시 한번 더 아래 그림으로 설명하면, Attention 이 Dashed Arrow 로 4개의 레벨에서 Contextual Module (Red Box)로 적용되고 있음을 알 수 있다.

Training
-
Cross-and-within-task weighted loss: 요소별, Room Type, Room Boundary의 픽셀수가 다르기 때문에 학습의 균형을 맞추기 위해 별도 태스크로 구분한다.
-
Within-task weithed loss: 엔트로피 스타일로 적용
- : 작업 내 손실
- : 클래스의 총 수
- : 실제 라벨이 i인 클래스에 대한 라벨
- : i번쨰 요소에 대한 픽셀 예측 라벨 [0,1]
- : 클래스 i에 대한 가중치
: i 번째 요소의 ground-truth 픽셀 수
: 모든 클래스에 대한 전체 픽셀 수=
따라서, 가중치 는 손실 함수에서 사용될 때 픽셀수가 다른 각 클래스에 대한 기여도를 조절하게 된다.
-
Cross-and-within-task weighted loss:
은 전체 픽셀 수
Training
설정값
- Optimizer: Adam
- lr: 1e-4
- input_shape=(512, 512, 3)
- 배치 정규화는 사용하지 않음
- 100 Epochs 가 디폴트
픽셀 단위 예측이기 때문에 예측 시 노이즈가 포함된다. 이를 개선하기 위해 Room Boundary 픽셀로 묶여진 영역을 찾아서, 예측된 Room Type의 픽셀수를 Count 하고, 가장 많은 빈도로 예측된 Room Type을 출력한다. 아래는 기존 도면 인식 네트워크와 비교 테이블.
DFPN은 후처리를 통해 더욱 정교하게 도면 요소들을 인식하는 걸 확인할 수 있다. 특히, Room Boundary와 Hall 에 대한 인식률이 상당히 높다.

결론
-
담벼락 프로젝트에 적용해볼만 하다. 단순히 Wall / Door 인식이 필요하다. 하지만, EL 쪽 인식을 위해서 별도의 Ground Truth 데이터셋이 필요하다.
-
추가로, 호텔 / 빌딩 등 다양한 평면도의 데이터 셋이 필요하다.
-
5년전 투고된 논문이기에, 개선된 네트워크를 적용해보고 싶다. 특히 1:1 그대로 사용하기 보다는, 잔여학습을 통해 일부 가중치 사용하는게 좋을 것 같다.
