구성도: Deep Floor Plan Recognition Using a Multi-Task Network with Room-Boundary-Guided Attention
프로젝트
전박적인 코드 및 구성 이해를 위해 글을 작성한다.
구조
데이터셋
- tfrecord 파일 변환 코드: https://github.com/zlzeng/DeepFloorplan/tree/master/utils
훈련 (train.py)
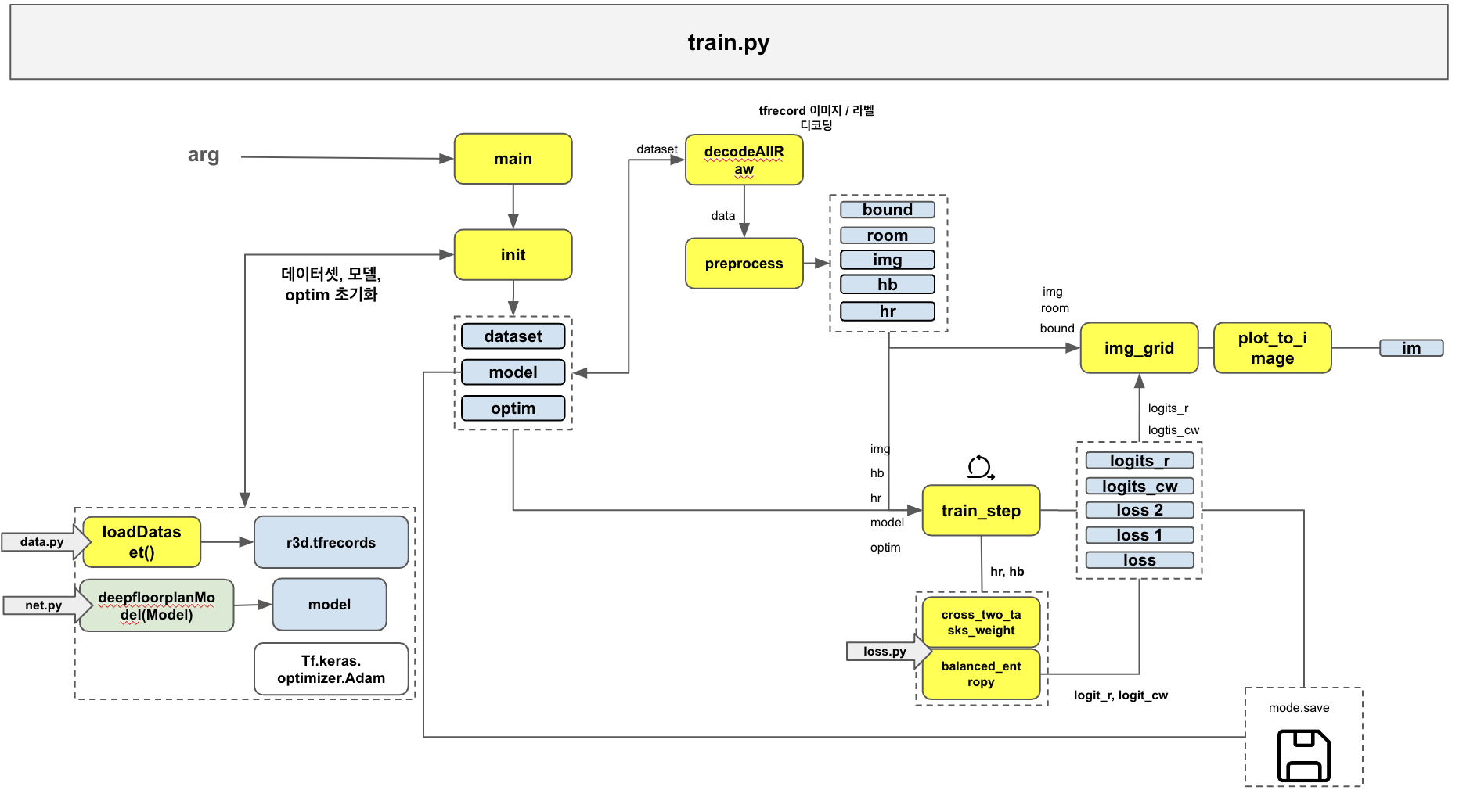
모델의 초기화(init), 학습 (train_step)을 담당.
네트워크 (net.py)

신경망의 아키텍쳐를 담당함. 네트워크의 구조는 ENCODER - DECODER로 구성되는데, 논문의 Figure (3,4)와 코드를 비교 대조했을때 머릿속에서 제대로 정리가 되지 않았다. 해당 네트워크의 레이어를 이해하기 위해서는 Auto Encoder-Decoder 개념이 적용되는 듯 하다. 아래는 참고자료이다.
💡 오토인코더https://arc.net/l/quote/gzauwxzp
-
Activation Function이 없는 Encoder는 Linear Auto Encoder라고 한다. 게속 이해가 되지 않아, 논문의 본저자가 작성한 네트워크(net.py)와 비교하여 분석해보기로 했다.

Encoder
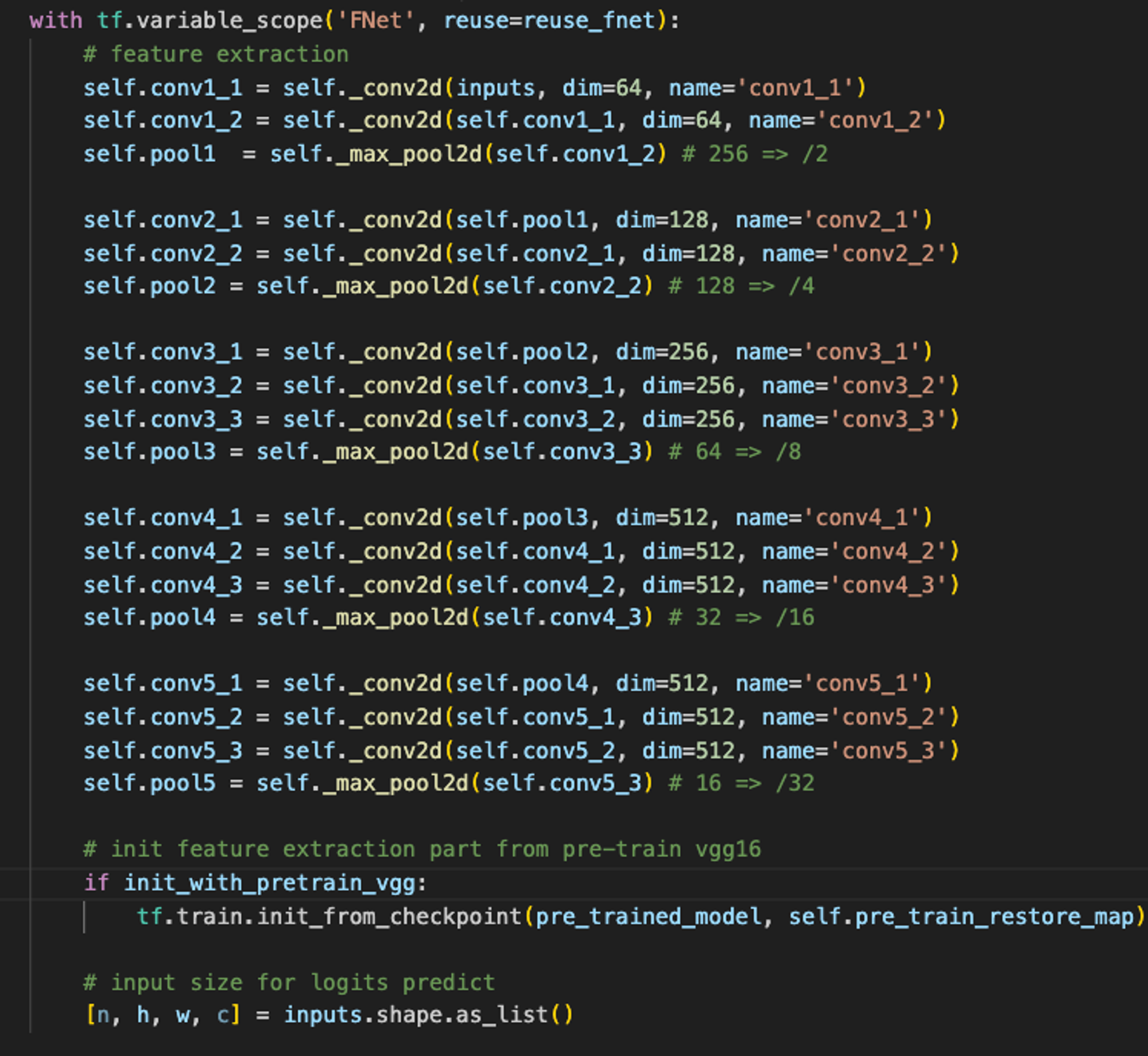
Decoder: CWNet (Room Boundary Prediction)
-
up2_cw를 생성하기 위해서, 컨볼루션 연산한pool4와pool5를 업샘플링 후 더하는데, 왜그런지는 정확하게 잘 모르겠지만, figure3 (b)에서 “1x1 conv & element-wise add”라고 적혀있는걸 보니, 아마도 Element Wise add를 하기 위해서가 아닐까? -
up4_cw,up8_cw,up16_cw모두up2_cw와 동일한 계산 방식이다. -
up4_cw,up8_cw,up16_cw는 Room Type Prediction을 위한 attention weight를 생성하는데 역할을 한다. (_non_local_context)
Decoder: RNet (Room Type Prediction)
-
CWNet과 동일한 연산방식을 가지고 있지만, 마지막에
_non_local_context에서 attention weight를 계산할 수 있다. (아래 참고)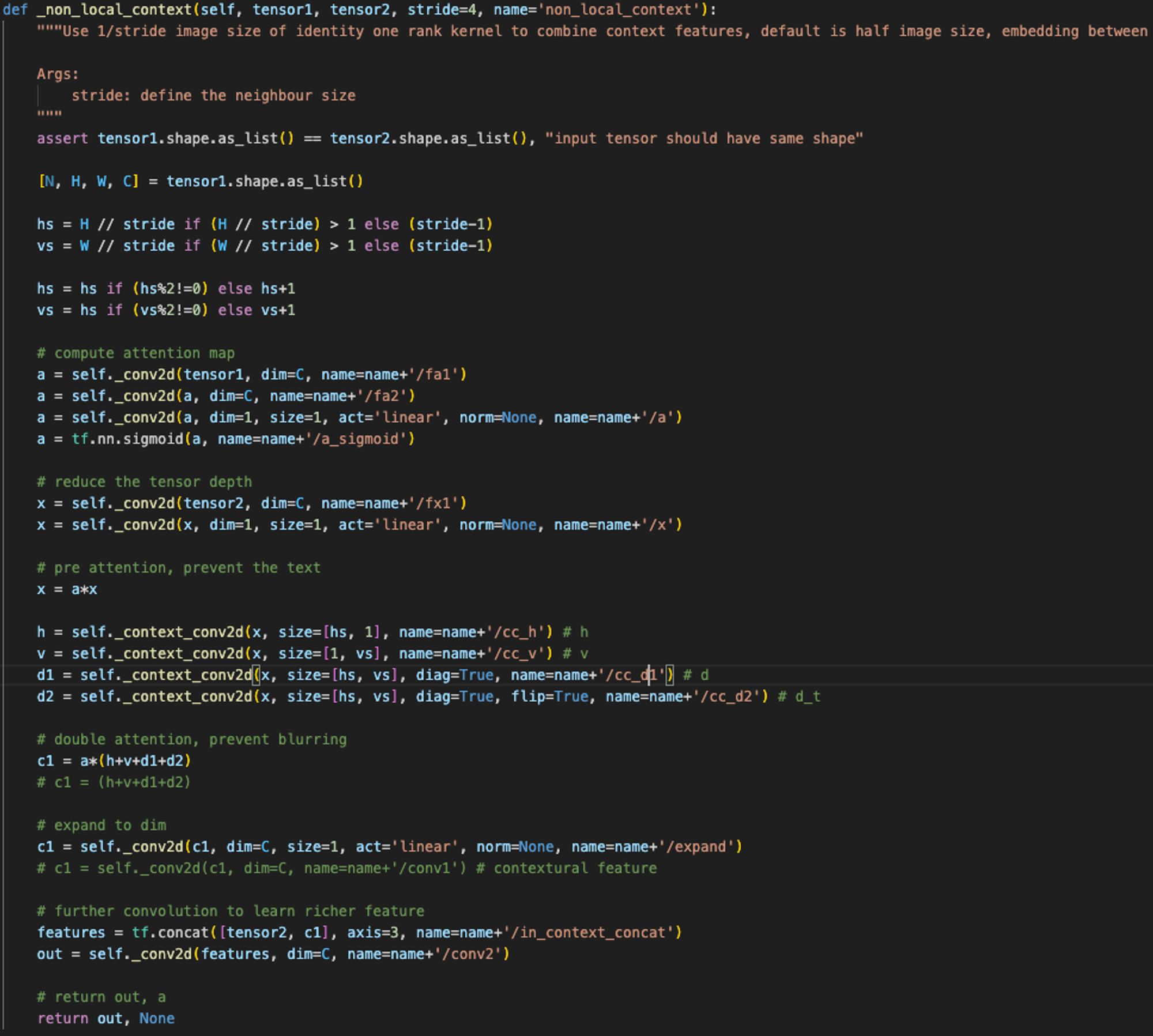
-
따라서, figure3, 4 를 보면, Contextual Module을 계산하기 위해 attention weight를 계산하는 프로세스가 있음. 나는 처음에 Blue / Green Box 를 포함해서 전 과정이 Decoder에 포함되는 건 줄 알았는데 그게 아니었음. Room Boundary Features 와 Room Type Figures 는 그냥 Decoder이고, 그 이후의 모든 과정이
_non_local_context에서 사용되는 contextual module 생성 과정임.
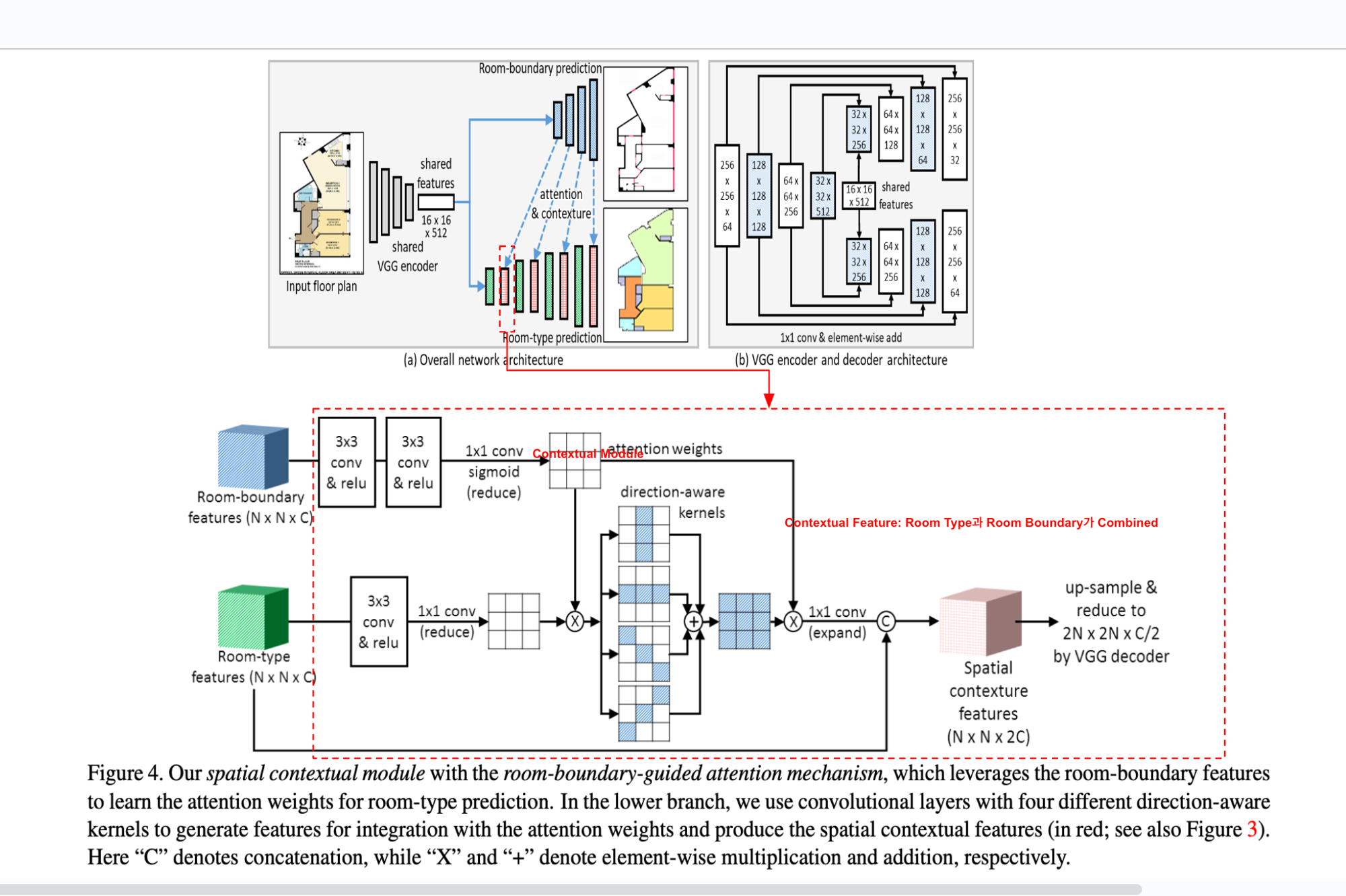
-
따라서 해당 코드를 TF2에 삽입해서 다시 학습을 돌리거나, 아니면 TF2의 net.py 코드를 다시 이해 해봐야할 듯 하다. 추가로 오토 엔코더에 대해서 조금 더 자세히 공부해봐야겠다.
손실 계산 (loss.py)
-
Within-task weithed loss: 엔트로피 스타일로 적용
-
💡 설명
- 작업 내 손실
- : 클래스의 총 수
- : 실제 라벨이 i인 클래스에 대한 라벨
- : i번쨰 요소에 대한 픽셀 예측 라벨 [0,1]
- : 클래스 i에 대한 가중치
따라서, 가중치 는 손실 함수에서 사용될 때 픽셀수가 다른 각 클래스에 대한 기여도를 조절하게 된다.
-
-
Cross-and-within-task weighted loss:
-
💡 설명
-
⇒ : 픽셀 수
-
⇒ : 픽셀 수
: i 번째 요소의 ground-truth 픽셀 수
: 모든 클래스에 대한 전체 픽셀 수 =
-
-
이제 원문 DeepFloorplan의 net.py 를 TF2DeepFloorPlan net.py 재해석해서 코드를 재구성해보아야 겠다.
