
📝Carrotww의 코딩 기록장
🧲 Titanic Dataset으로 인공지능 학습시키기
🔍 sklearn을 사용하여 데이터 학습시켜보기
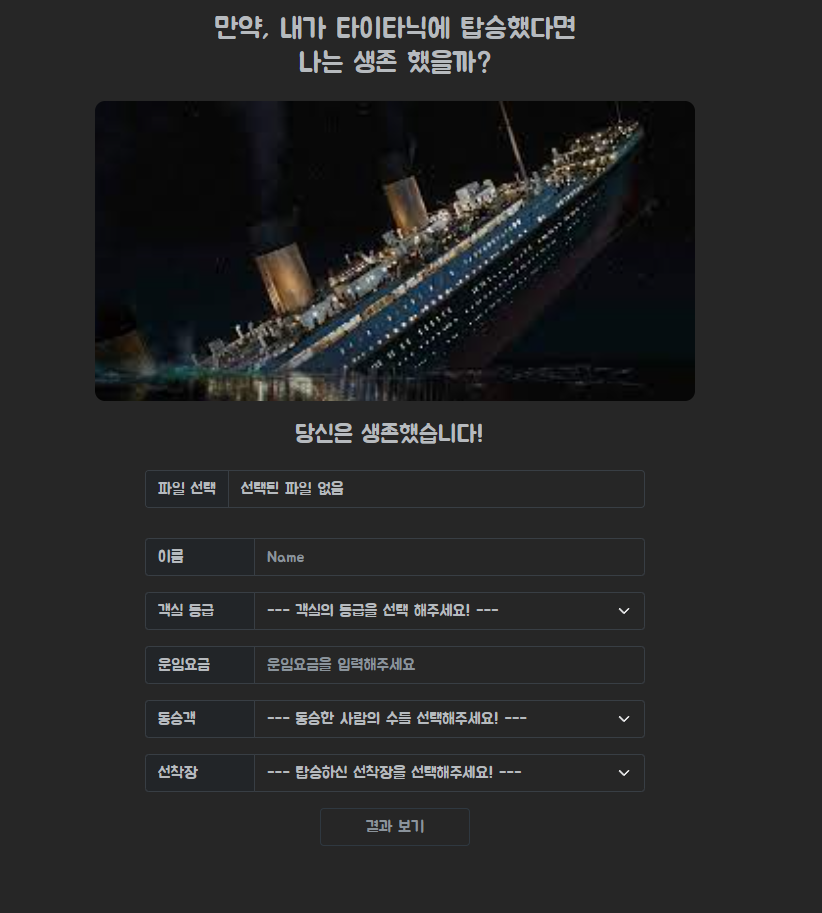
위와 같은 화면에서 사용자의 얼굴 사진을 넣으면 아래의 정보를 입력하고 이미지는 성별과 나이를 탐색하는 다른 이미지 인식 모델을 가져와 사용, 사용자 정보를 입력받아 생존 여부를 알려주는 머신러닝을 적용한 장고 프로젝트를 진행중이다.from pdb import post_mortem import pandas as pd import matplotlib.pyplot as plt from IPython.display import display from sklearn import svm from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split #training and testing data split from sklearn import metrics #accuracy measure import torch plt.style.use('fivethirtyeight') import warnings warnings.filterwarnings('ignore') # 데이터를 불러오고 보여준다. train_data=pd.read_csv('/titanic/train.csv') test_data=pd.read_csv('/titanic/test.csv') # data.head()는 앞의 5개만을 보여준다. # print(train_data.head()) for col in train_data.columns : msg = '항목 {:>10}\t 비어있는 자료의 비율 : {:.2f}%'.format(col, 100 * (train_data[col].isnull().sum() / train_data[col].shape[0])) # print(msg) for col in test_data.columns : msg = '항목 {:>10}\t 비어있는 자료의 비율 : {:.2f}%'.format(col, 100 * (test_data[col].isnull().sum() / test_data[col].shape[0])) # print(msg) train_data.isnull().sum() # print(train_data.isnull().sum()) # train_data 열 부분의 비어있는 데이터 모두 sum() 하여 보여줌 train_data['Initial']= train_data.Name.str.extract('([A-Za-z]+)\.') test_data['Initial']= test_data.Name.str.extract('([A-Za-z]+)\.') # print(test_data.Name.str.extract('([A-Za-z]+)\.')) # print(train_data.Name.str.extract('([A-Za-z]+)\.')) train_data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],inplace=True) test_data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],inplace=True) # 라벨에 따라 평균 값을 나타낸다. train_data.groupby('Initial')['Age'].mean() # print(train_data.groupby('Initial')['Age'].mean()) train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Mr'),'Age']=33 train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Mrs'),'Age']=36 train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Master'),'Age']=5 train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Miss'),'Age']=22 train_data.loc[(train_data.Age.isnull())&(train_data.Initial=='Other'),'Age']=46 test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Mr'),'Age'] = 33 test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Mrs'),'Age'] = 36 test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Master'),'Age'] = 5 test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Miss'),'Age'] = 22 test_data.loc[(test_data.Age.isnull())&(test_data.Initial=='Other'),'Age'] = 46 train_data.Age.isnull().any() test_data.Age.isnull().any() train_data['Embarked'].fillna('S',inplace=True) train_data['Age_band']=0 train_data.loc[train_data['Age']<=16,'Age_band']=0 train_data.loc[(train_data['Age']>16)&(train_data['Age']<=32),'Age_band']=1 train_data.loc[(train_data['Age']>32)&(train_data['Age']<=48),'Age_band']=2 train_data.loc[(train_data['Age']>48)&(train_data['Age']<=64),'Age_band']=3 train_data.loc[train_data['Age']>64,'Age_band']=4 train_data.head() #family size max=4 train_data['Family_Size']=0 train_data['Family_Size']=train_data['Parch']+train_data['SibSp'] #Alone train_data['Alone']=0 train_data.loc[train_data.Family_Size==0,'Alone']=1 train_data['Sex'].replace(['male','female'],[0,1],inplace=True) train_data['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True) train_data['Initial'].replace(['Mr','Mrs','Miss','Master','Other'],[0,1,2,3,4],inplace=True) train_data.drop(['Name','Age','Ticket','Cabin','PassengerId','SibSp','Parch','Initial'],axis=1,inplace=True) train,test=train_test_split(train_data,test_size=0.3,random_state=0,stratify=train_data['Survived']) train_X=train[train.columns[1:]] train_Y=train[train.columns[:1]] test_X=test[test.columns[1:]] test_Y=test[test.columns[:1]] X=train_data[train_data.columns[1:]] Y=train_data['Survived'] model = LogisticRegression() model.fit(train_X,train_Y) prediction3=model.predict(test_X) test_x = [[1, 0, 10.0000, 1, 1, 1, 1]] print('The accuracy of the Logistic Regression is',metrics.accuracy_score(prediction3,test_Y)) print(model.predict(test_x)) test_test = model.predict(test_x)https://welcome-to-dewy-world.tistory.com/4?category=913368
위 코드를 참조하여 작성하였다. 모든 줄의 실행 결과와 해당 코드를 왜 사용하였는지는 직관적으로 알 수 있다. 개인적으로 이미지 처리하는 코드는 2차원 배열, 3차원까지 다루며 코드가 직관적이지 않아 이해하기 너무 힘들었지만 이미지 처리가 아닌 데이터 학습을 시키는 것은 간단한 방법이면 나름 이해하기가 쉽다.
케글 추천수 10000개의 학습법은 주말에 시간이 되면 해봐야겠다.
위 코드와 정확도가 4퍼센트정도 차이가 나며 프로젝트를 완성하고 나면 코드를 하나하나 다시 뜯어봐야겠다.개인적으로 처음에 C++을 공부하듯 엄청 막막했는데 데이터 학습을 시키며 결과가 나오는게 너무 신기했다.
test_x 의 데이터는 프로젝트에서 사용할 데이터 전달 방식이다 해당 배열을 입력받아 그대로 넣어줄 것이다.
편의상 학습에 영향을 많이 주지만 재미로 해보는 테스트이기에 항구(탑승지)는 한국 항구로 임의로 정하였다.
🧲 Algorithm
🔍 문제가 안풀린다 ㅠㅠㅠ 시간도 넉넉치 않아 못했다 ㅠㅠ 일주일 할당치를 못 풀 것 같다... 금요일 오전까지 프로젝트가 진행되니 금요일과 주말에 많이 풀어야겠다...
