
본격적으로 Cipher 에 대해 알아보도록 합시다. 이번 글에서 다룰 내용은 바로 Symmetric Ciphers 입니다.
Symmetric Cihpers
암호화의 가장 기본 알고리즘 2개는 바로 Substitution(치환) 과 Transposition(전환) 입니다.
Substitution 은 치환, 즉 실제 값을 다른 값을 바꾸는 것을 의미합니다. 평문의 글자를 key 값을 적용한 다른 글자로 바꾸는 거죠. 이때 가장 많이 쓰는 연산은 XOR 연산입니다. 평문의 글자와 매칭되는 key 글자를 XOR 한 값을 암호문에 쓰는 것지요. Transposition 은 글자와 글자를 서로 바꾸는 것입니다. 자리를 바꿔서 순열의 순서를 뒤바꾸는 것이지요. 이 두 과정이 모두 섞여 있어야 key 값의 유추가 매우 어려워 지는 것입니다.
앞선 글에서 설명했듯이 Symmetric Ciphers 는 Encryption 하는 key 와 Decryption 할 때의 key 가 같은 것을 의미합니다. 첫 번 째 Symmetric Ciphers 로 Steram Ciphers 에 대해 알아보도록 하겠습니다.
Stream Ciphers
알고 계시겠지만, Stream 은 바이트의 흐름을 뜻합니다. 바이트 단위의 연속적인 데이터 열을 의미하지요. Stream Ciphers 는 key 값이 stream 인 암호입니다.
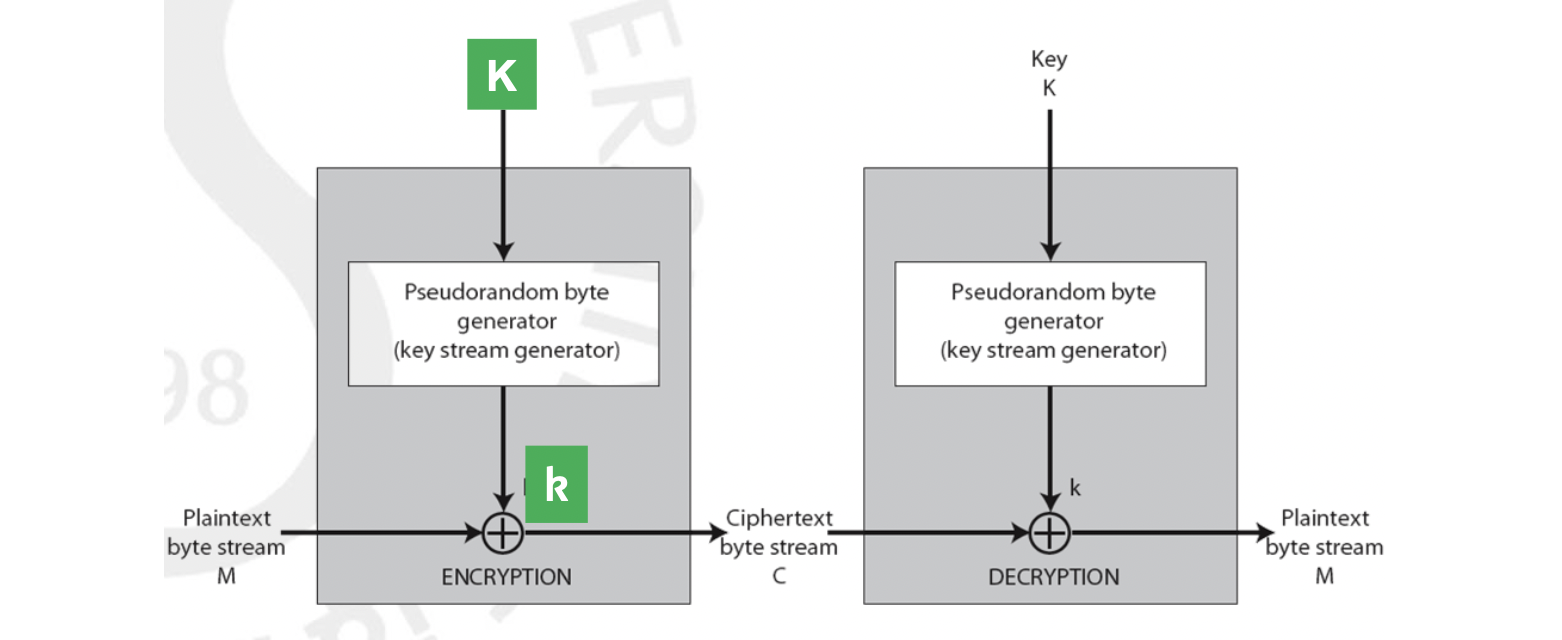
평문 M은 하나의 stream으로써 한 글자(바이트) 단위로 들어옵니다. K는 시드입니다. 비밀로 유지되어야 하는 값이죠. K가 앞서 공부하였던 Pseudorandom Generator 로 입력 되면 바이트 순열 k가 출력으로 나옵니다. 이 값을 key로 사용하고 stream 이기 때문에 keystream 이라 부릅니다. 들어온 평문 바이트와 매칭되는 keystream의 바이트를 XOR 연산한(예시가 그렇다는 거지 항상 XOR 인 건 아닙니다!) 값을 암호문의 바이트로 출력합니다. 이 바이트 단위의 과정이 물처럼 연속적으로 쭈루루룩 이어지는 stream 들이기 때문에 이를 Stream Cipher 라 합니다.
Decryption 도 이와 같은 흐름으로 이루어집니다. Symmetric 이기 때문에 Decryption 할 때의 key 값, Seed는 Encryption 할 때의 값과 같습니다. 이러한 Stream Cipher 는 앞서 공부하였던 OTP 를 만들 때 사용되죠.
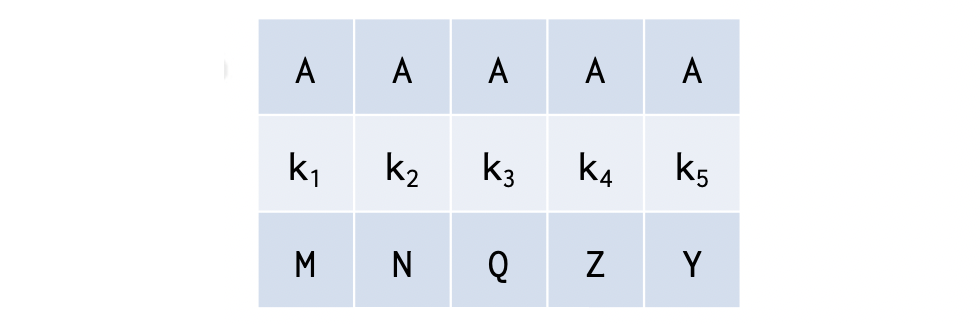
Stream Cipher 는 Substitution 을 이용합니다. 평문의 같은 A 들이 서로 다른 keystream 의 바이트와의 연산을 통해 서로 다른 암호문의 글자들로 치환됬기 때문입니다. 이렇게 되면 공격자 입장에서는 평문과 암호문을 보고 이들의 상관관계를 예측하기가 매우 어려워지게 됩니다. 암호문을 보고 평문을 유추하는 것이 불가능에 가까워지는 것입니다. 이를 보고 Confusion(혼란) 을 제공한다고 표현합니다.
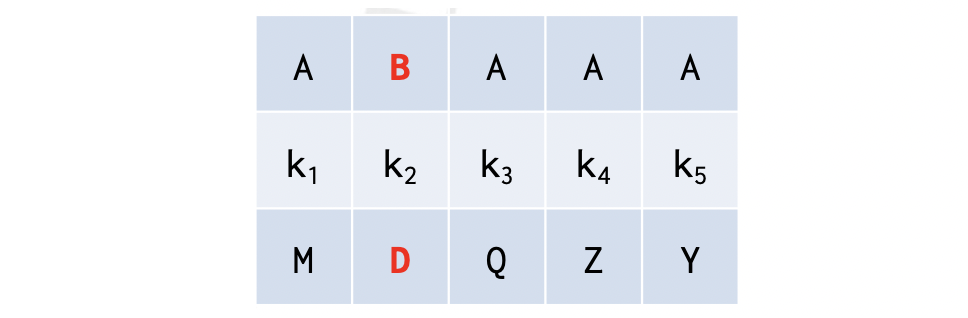
그런데 여기서 위와 같이 A 하나가 B로 바뀌었다고 해봅시다. 그러면 한 글자(바이트) 단위로 연산을 해서 암호문 한 글자(바이트)를 뱉는 Stream Cipher 는 위와 같이 해당되는 암호문의 글자만 바뀔 것입니다. 그러면 공격자는 똑같은 keystream 을 통해서 평문의 어디가 바뀌었는지에 대한 정보를 획득할 수 있는 것이지요.
XOR 연산이라고 생각해봅시다. 평문 에 대응하는 암호문 을 알고 있다면 이 성립합니다. 새로운 암호문 를 알고 있을 때 이에 대응하는 평문이 이며 같은 keystream 을 사용한다는 것을 알면 마찬가지로 인데 이 두 식을 이용하면 이기 때문에 쉽게 평문 을 알 수 있게 되는 겁니다.
그렇기 때문에 Transposition가 필요한 것입니다. 단순히 한 글자(바이트)가 바뀌는 것 뿐만 아니라 이 값의 순서를 다른 값들과 바꾸고 바꿔서 바뀐 위치를 눈치 못채게 해야합니다. 이를 보고 Diffusion(확산) 을 제공한다고 표현합니다.
이처럼, Stream Ciphers 는 오직 confusion 만을 제공하기 때문에 Lack of Diffusion 이라는 상당한 약점을 가지고 있습니다.
RC4
대표적인 Stream Cipher 로는 RC4 가 있습니다. Don Rivest가 1987년에 디자인한 것으로 key의 크기가 가변적이고, 위에서 Stream Cipher 를 설명한 예시처럼 평문과 keystream과의 XOR 연산으로 암호문을 생성하기 때문에 매우 빠르다는 특징을 가집니다. 그러나 Stream Cipher의 고질적인 문제인 Lack of Diffusion ㅡ로 인해 현재는 많은 브라우저들이 더 이상 사용하지 않고 있습니다. RC4 에서 key 를 가지고 keystream 을 생성하는 알고리즘에 대해 알아보도록 하겠습니다.
for i = 0 to 255
do
S[i] = i
T[i] = K[i % keylen]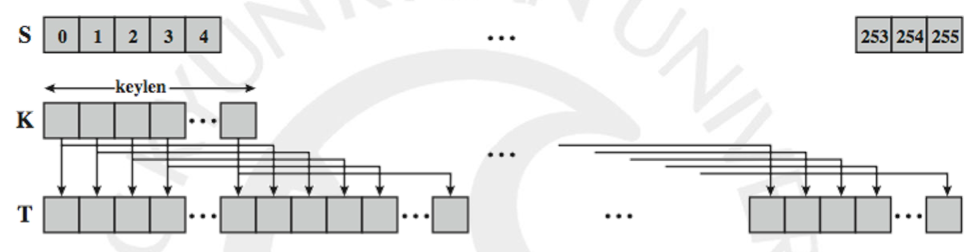
먼저 위와 같이 S는 0부터 255까지를 담고 있으며 K는 크기가 keylen 으로 가변적입니다. T에는 256개의 요소에 key 값이 크기에 따라 반복적으로 대입됩니다.
j = 0
for i = 0 to 255 do
j = (j + S[i] + T[i]) % 256
swap(S[i], S[j])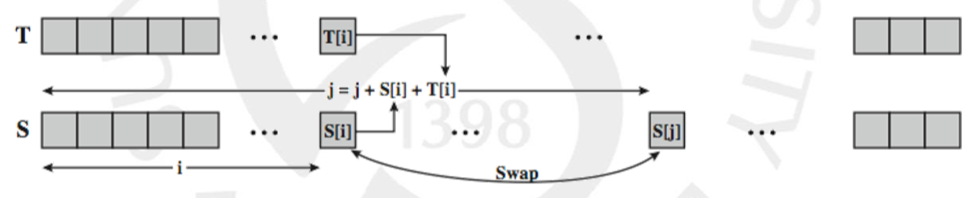
계속해서 j의 값을 마치 random 처럼 바꿔가면서 S의 i번째 요소와 j 번째 요소를 스왑합니다.
i =j = 0
while {
i = (i + 1) % 256)
j = (j + S[i]) % 256
swap(S[i], S[j])
t = (S[i] + S[j]) % 256
k = S[t]
}
또 위와 같이 S 안의 내용들이 뒤죽박죽 섞어서 나온 임의의 요소를 keystream 에 한 글자로 뱉어서 이를 평문의 글자와 XOR 하는 것입니다.
Block Ciphers
결국 비트 단위로 암호화하는 Stream Ciphers 는 diffusion 을 달성하기에는 어려움이 있습니다. 한 비트가 암호화되면 바로 나가버리기 때문에, 다른 비트들에 영향을 줄 수가 없는 것입니다. 그래서 조금 더 큰 단위인 Block 으로 암호화하는 방법들이 고안되기 시작했습니다. 같은 평문과 같은 key 를 넣었을 때 다른 암호문이 나오는 것, 그것이 바로 Block Ciphers 입니다.
잠시 지금까지 알고 있는 개념들을 짚고 넘어가볼까요? 안전한 암호화를 위해서는 알고리즘이나 key 둘 중 하나는 공격자가 알아서는 안됩니다. 그런데 알고리즘은 언제나 다를 수 없고 금방 공개되기까지 합니다. 그래서 이제 안전한 암호화의 핵심은 key 를 지키는 것이 되엇습니다. 암호학의 대가인 Kerckhoff 의 원칙에서도 '시스템의 모든 것이 들통 나더라도 key 만 모른다면 안전한 것이다.' 라고 말하고 있지요.
그리고 이 시대의 우리는 Computationally Secure 를 지향하고 있습니다. Brute Force 를 하는 한 완벽하게 뚫리지 않는 암호는 존재할 수 없습니다. 키의 경우의 수의 반 저도만 하면 다 뚫리니까요. 그래서 목적은 이 전수 조사를 굉장히 오래 걸리게(죽을 때까지 불가능하게) 하는 것이 되었습니다. 즉 빨라지는 컴퓨팅 파워에 맞춰 경우의 수를 늘리기 위해서 키의 길이를 맞춰 늘리는 것이 관건이 되었지요. 그럼 이제 그만 진짜 Block Cipher 의 하나인 DES 를 확인해보러 가봅시다.
Data Encryption Standard(DES)
DES 는 NIST 에서 1977년 채택한 암호화 방식으로 다수의 라운드 동안 비트를 쪼개서 간단한 함수를 계속하는 Feistel Cipher 구조로서 강력한 암호화 중의 하나로 인정받습니다. 64 비트의 block 을 사용하며 56 비트의 키를 16개의 48비트로 파생시켜서 16 번의 라운드 동안 함수를 돌리는 방식입니다. 아래 그림과 함께 Encryption 과정을 조금 더 자세히 알아봅시다.
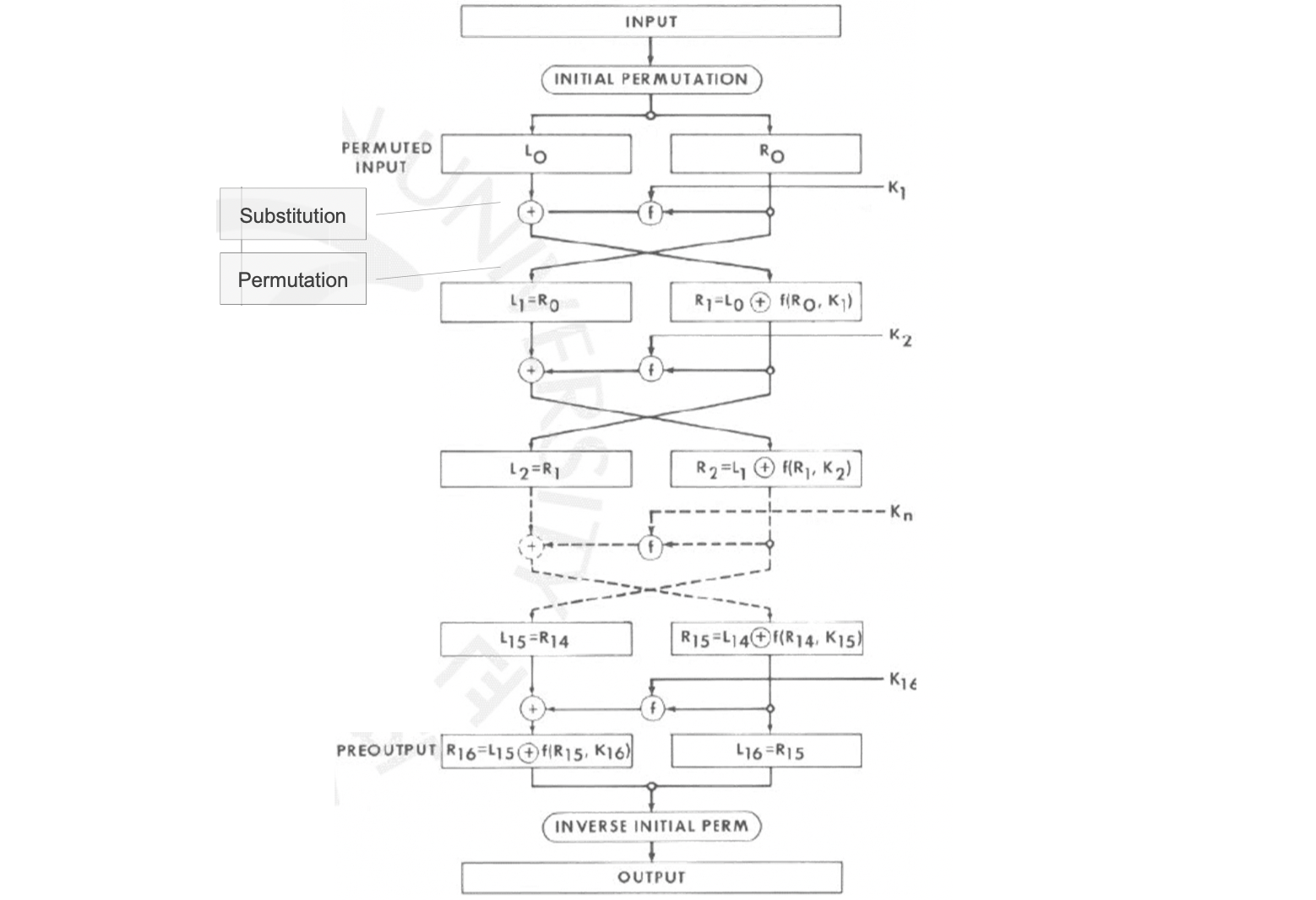
자 기본적으로 INPUT 과 OUTPUT 은 블럭 단위로 이루어지며, DES 에서는 말했듯이 64비트, 즉 8 바이트가 됩니다. 그리고 앞서 말했듯이 56비트의 키를 이용해 48비트의 Subkey, 를 생성합니다. 처음에는 이 INPUT에 Permutation 을 적용해서 섞습니다. 그리고 왼쪽 오른쪽 각각 4 바이트씩으로 쪼개는 것이죠. 그리고 오른쪽의 비트는 그대로 다음 라운드의 왼쪽의 비트가 됩니다. 다음 라운드의 왼쪽 비트는 오른쪽 비트와 Subkey 를 Round Function 한 값을 왼쪽 비트와 XOR 하여 만듭니다. 이를 매 16번의 라운드 동안 반복한 뒤, 가장 처음에 하였던 Permutation 을 역으로 적용시켜 최종적인 OUTPUT 블럭을 만드는 것입니다. 이와 같이 많은 반복하는 연산이 간단하기 때문에 빠르다는 장점 이외에도 DES 의 가장 큰 장점은 다음과 같습니다.
Decryption 과정이 Encryption 과정과 동일합니다.
보통, Decryption 을 생각한다면 지금까지 따라갔던 이 Encryption을 역으로 진행하는 것일텐데요. DES 는 알고리즘 특성 상 key 값이 같다면 역으로 수행하는 것과 이 OUTPUT 값을 INPUT으로 똑같이 Encryption 을 수행한 결과가 같다는 것입니다. 따로 복호화 알고리즘이 필요하지 않은 것이지요. 그렇다면 암호화 과정에서 핵심적으로 사용되었던 이 Round Function 은 어떻게 진행될까요?
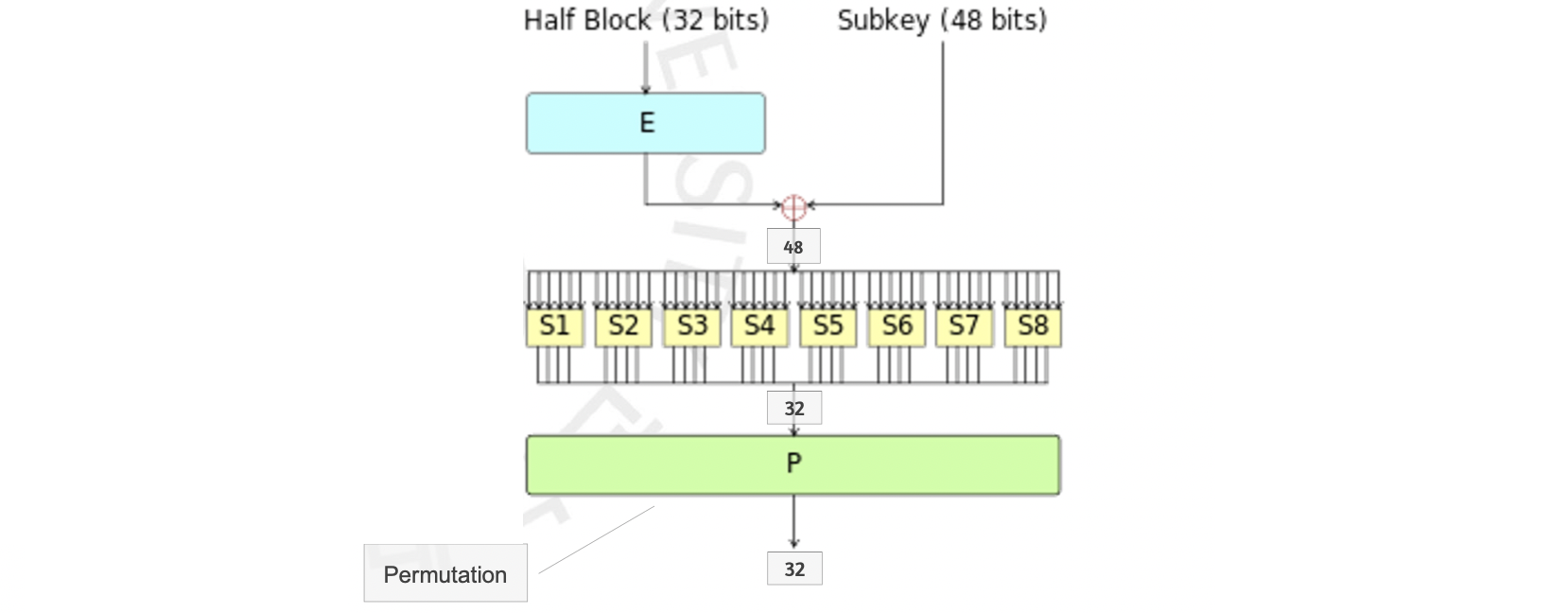
먼저, 반으로 쪼갠 32비트의 블럭을 확장(Expansion) 하여 48비트로 만든 뒤, 이를 48비트의 Subkey 와 XOR 합니다. 그리고 이 48비트를 6 비트의 8개의 S-box 에 넣습니다. 그러면 이 S-box 에서는 결과로 4 비트가 나옵니다. S-box 에는 4 개의 행과 16 개의 열을 가진 Table 이 있습니다. 그래서 비트 에 따라 행을 정하고 에 따라 열을 정합니다. 이렇게 Table Lookup 과정을 통해 4 비트를 출력하기에 빠르면서도 Confusion 을 달성할 수 있습니다. 이 32 비트에 마지막으로 Permutation 과정까지 추가시켜 Diffusion 까지 달성하는 것입니다.
하지만 결국 56 비트 밖에 안되는 key 를 사용하는 DES 는 일찍이 1999년 22시간 15분만에 깨지게 됩니다. 그래서 이 key 를 늘리기 위해 서로 다른 두 개의 key 로 DES 과정을 두 번 수행하는 Double-DES 아이디어가 대두되었습니다.

그런데 이러한 Double-DES 는 치명적인 문제점이 있죠. 바로 Meet-In-The-Middle Attack 에 취약하다는 것입니다. 암호화를 두 번 진행하는 Cipher 에서는 피할 수 없는 문제가 있습니다. Double-DES 를 푸는 데 얼마나 많은 전수조사가 필요할까요? 만큼을 기대하기 위해 이와 같이 연속으로 두 DES 를 붙였지만 실제로는 그렇지 않습니다. 문제는 DES 사이의 값, 즉 라는 것입니다.
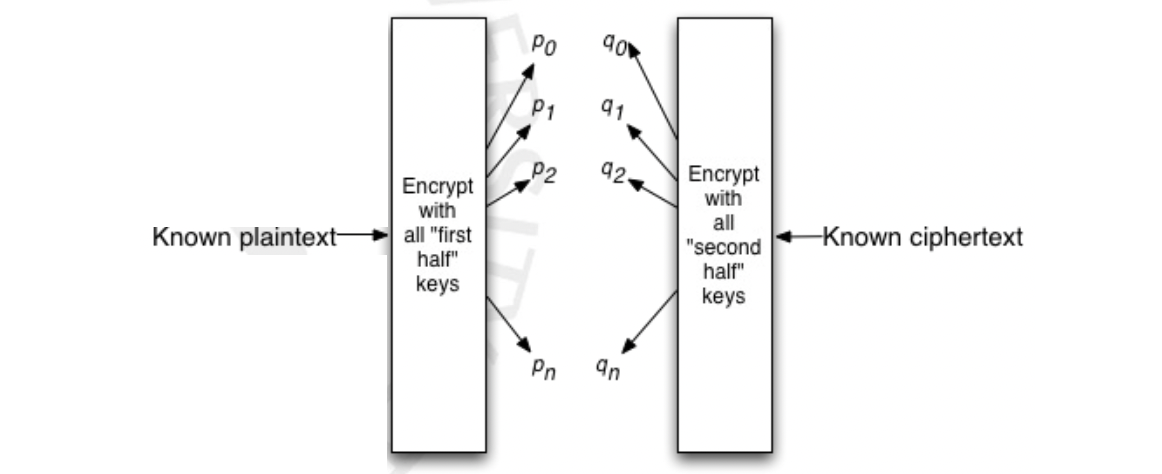
그렇기 때문에 Plaintext 에 모든 의 경우의 수를 전수조사 해본 결과를 저장한 뒤, 마찬가지로 Ciphertext에 모든 의 경우의 수를 전수조사 해보며 저장한 결과와 매칭한 결과와 비교해보면 됩니다. 모든 Plaintext 의 Encryption 결과에 대해 또 다시 전수조사 할 필요 없이 양쪽을 독립적으로 한 번씩 해보면 되기 때문에 가 아닌 이 되는 것입니다.

이러한 문제로 인해서 DES 를 세 번 수행하는 Triple-DES 까지 나오게 되었습니다. 이렇게 되면 비로소 의 모든 경우의 수에 대해서 또 를 수행한 값과 의 모든 경우의 수를 비교하는 것이므로 만큼이 필요하게 됩니다. 그러나 결국 이 Triple-DES 도 세 번의 stage 로 인해 느리고 작은 블럭으로 인한 비효율성을 피할 수 없었습니다. 그래서 NIST 는 1997 년 대대적으로 새로운 Cipher 에 대한 공모를 진행하였고, 그렇게 2000년 10월 AES 가 새로운 표준 Cipher 로서 등장하게 됩니다.
Advanced Encryption Standard(AES)
벨기에의 Rijmen 과 Daemen에 의해 디자인된 AES 는 128 비트의 블럭을 사용하며 key 값으로 128 / 192 / 256 비트를 선택에 따라 가변적으로 지원합니다. 주목해야 할 점은 AES 는 DES 와 같은 Feistel 구조가 아니라는 것입니다. 비트를 나누지 않고 각 라운드에서 대체(substitution)와 치환(permutation)을 이용해서 데이터 블록 전체를 병렬 처리하는 것이 특징입니다. 그렇기에 많은 CPU 에서 속도와 코드의 크기, 디자인의 단순함 등에서 압도적인 성능을 자랑합니다.
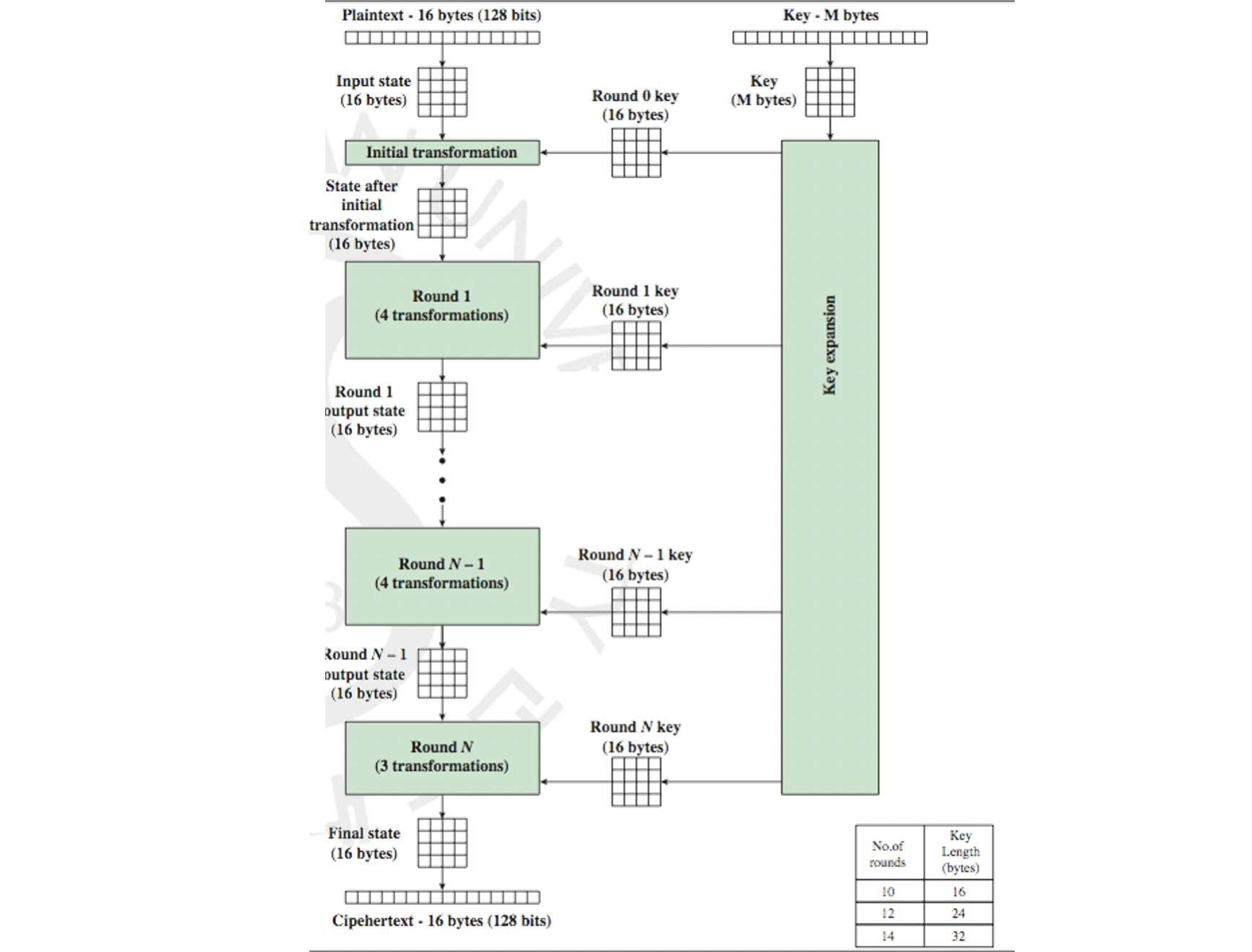
라운드의 수는 각각 key 길이 128 / 192 / 256 비트에 따라서 10 / 12/ 14 라운드로 진행됩니다. 위의 예시는 128 비트를 기준으로 해보겠습니다. 먼저 128비트, 즉 16 바이트의 Plaintext 를 한 바이트씩 4 x 4 배열(행렬) 형식으로 만듭니다. 그리고 key 값을 파생시켜 마찬가지로 라운드마다의 16 바이트의 4 x 4 배열(행렬)을 만듭니다. 그리고 첫 번째는 Round 0 로 해당 라운드 key 와 함께 한 번의 초기 Transformation 을 적용합니다. 그 이후에는 매 라운드마다 4 번의 Transformation 이 수행되는 Round Function 을 돌린 뒤, 마지막 라운드에서만 3 번의 Transformation 을 수행함으로써 최종적으로 128비트, 16 바이트의 Ciphertext 를 출력합니다.
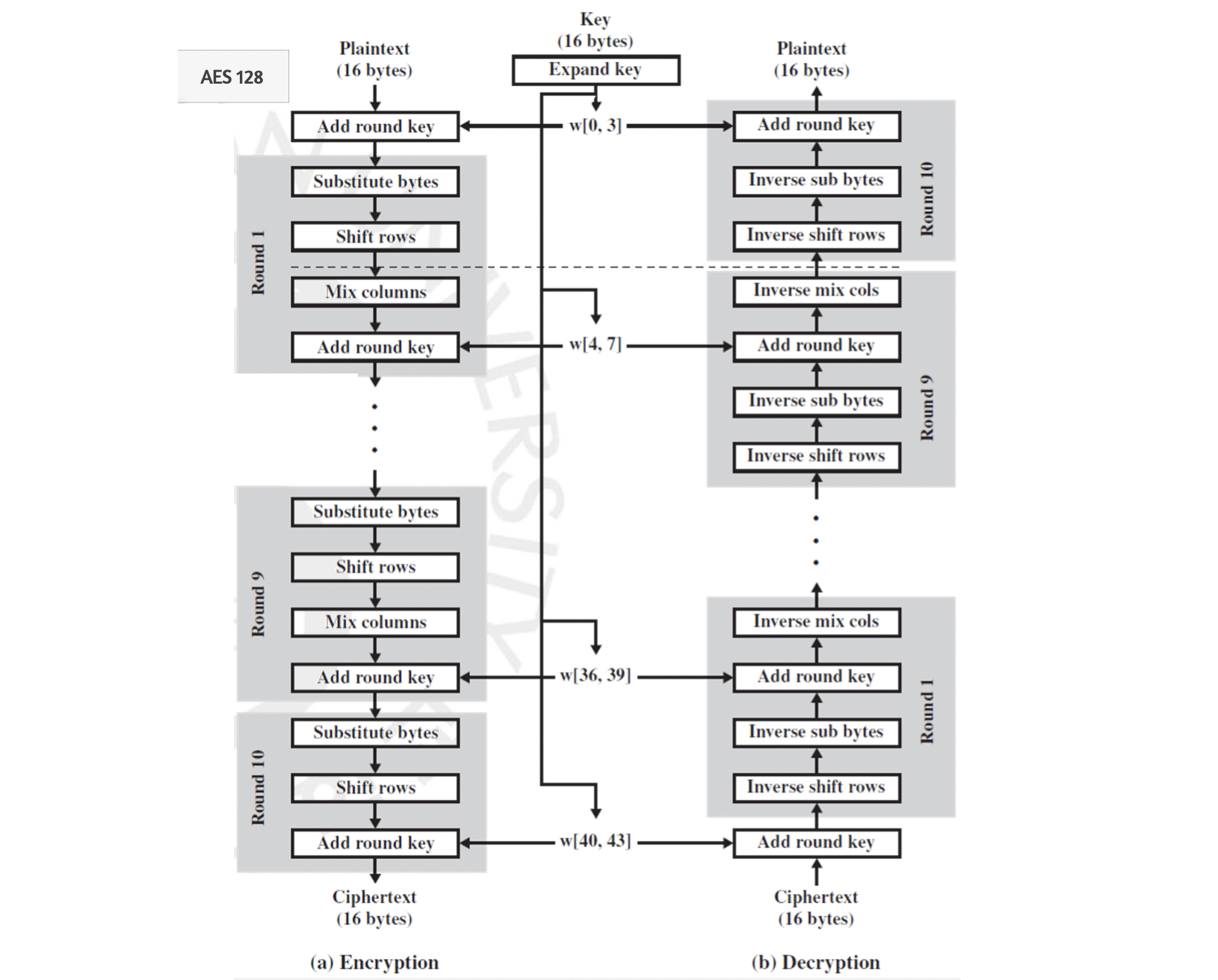
Round Function 을 조금 더 자세히 표현한 그림은 위와 같습니다. 각각의 Transformation 은 바이트들을 치환하고, 열을 바꾸고, 행을 섞고, key를 더하는 Operation 임을 확인할 수 있습니다. 바이트를 치환함으로써 Substitution 을 수행하고, 열을 바꾸고 행을 섞음으로써 Transposition 까지 합니다. 그런데 왜 마지막에는 Mix columns 가 빠졌을까요?
이유는 이와 같습니다. AES 의 4번의 Transformation 과정은 1-2번, 3-4번 과정은 그 둘의 순서가 바뀌더라도 결과에 영향을 미치지 않는다는 특징을 가집니다. 따라서, 마지막 라운드의 Add round key - Mix columns 의 순서를 바꾸었다고 생각해 봅시다. 그런데 실제로 우리가 비밀을 적용하는 과정은 바로 Add round key 입니다. Mix-columns 는 그것을 위한 준비 작업일 뿐이죠. 그런데 마지막 round 이후에는 Add round key 가 없기 때문에 Mix-columns 가 굳이 불필요한 과정이 되어버립니다. 따라서 연산 속도를 이해 뺀 것이지요.
Decryption 과정은 DES 때와는 달리 과정을 거꾸로 진행해야 합니다. 그대로 거꾸로 진행되는 것이 아니라 Encryption의 흐름을 따르지만, key 값이 반대 순서대로 적용되어야 하며 각각의 Operation 들은 그것의 Inverse 함수로 실행되어야 합니다.
Encryption 을 과정을 보다 세세하게 그림으로 표현한 것은 아래와 같습니다.
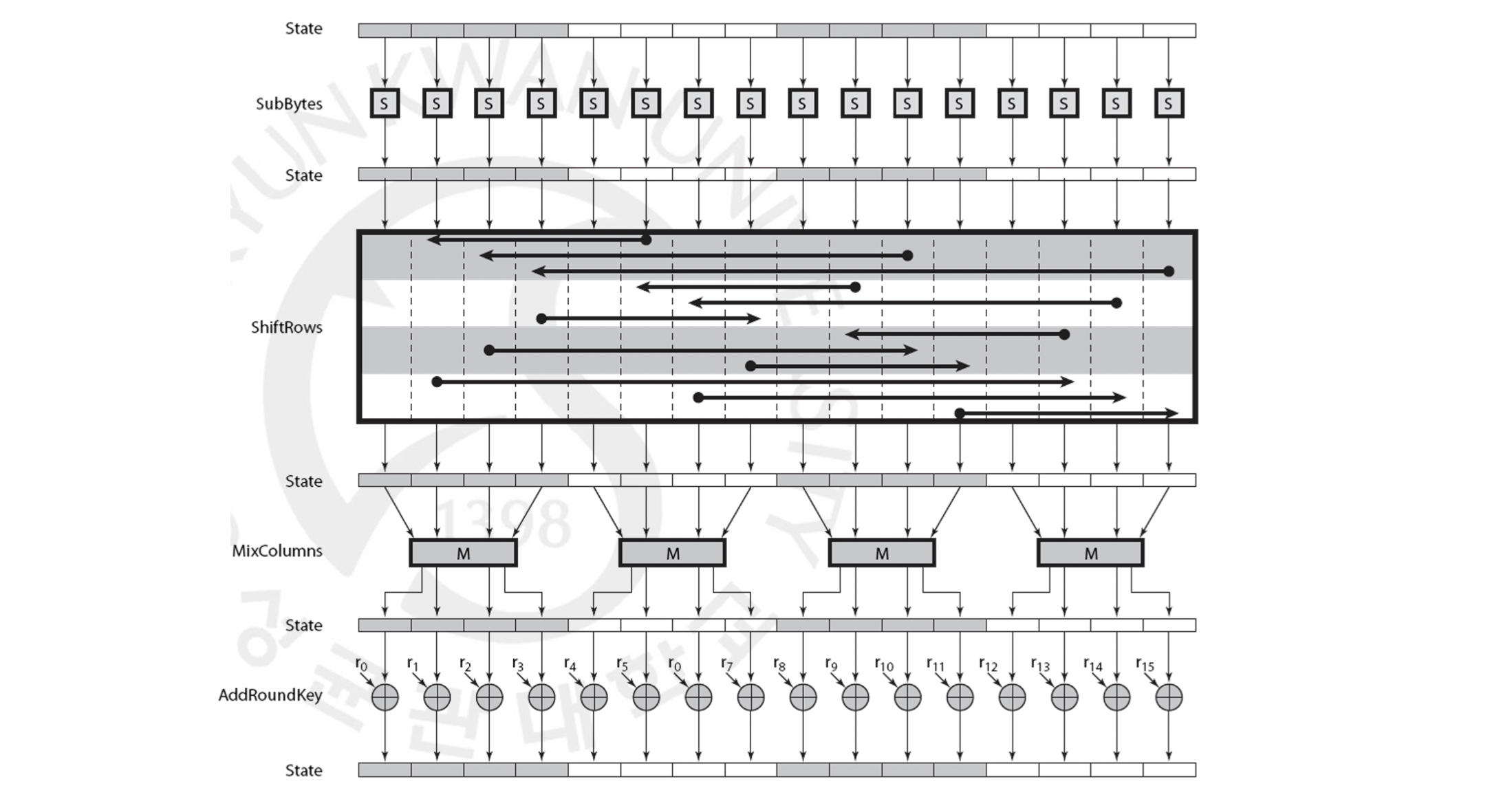
Mode of Operations
이제 블럭을 암복호화하는 방법은 알았으니, 여러 개의 블럭으로 이루어진 큰 데이터를 어떻게 처리하는지 Mode of Operations 를 알아봅시다. Block Cipher 의 장점 중 하나는 Stream Cipher 에서 부재했던 Transposition 을 적용한 것을 넘어, 같은 Plaintext 와 Key 여도 Ciphertext 가 다르게 나올 수 있다는 것입니다.
가장 먼저 알아야 할 것은 바로 Initialization Vector(IV) 입니다. 하나의 파일, 즉 한 번의 암호화마다 반영되는 반복적이지 않은 랜덤의 값입니다. 이것이 다르면 아무리 Plaintext 와 Key 가 같더라도 결과로 나오는 Ciphertext 가 서로 다르게 됩니다. 그래서 공격자를 힘들게 하기 위해, IV 를 날마다 바꾸면 같은 Plaintext 와 Key 더라도 그에 따른 Ciphertext 도 매번 바뀌기 때문입니다.
그렇기 떄문에 IV 는 상대와 서로 공유되어야 하며 공개해도 되는 값입니다. 어차피 공격자가 IV 를 알더라도 이게 메시지가 달라서 다른 암호문인건지, IV 가 달라서 다른 암호문인건지를 분간할 수 없기 때문이죠.
다음으로 알아야 하는 개념은 Padding 입니다. 블럭은 보통 16바이트인데 보내려는 Plaintext 가 항상 16 바이트의 배수의 크기를 갖지는 않을 겁니다. 이를 위해 임의의 값으로 크기로 맞춰주는 Padding 이 필요한 것입니다. 당연히 이 정보는 복호화하는 사람도 알고 있어 반영해 주어야 합니다. Mode of Operations 는 그 종류가 굉장히 많지만 이 번 글에서는 그 중 대표적인 몇 개만 알아보도록 하겠습니다.
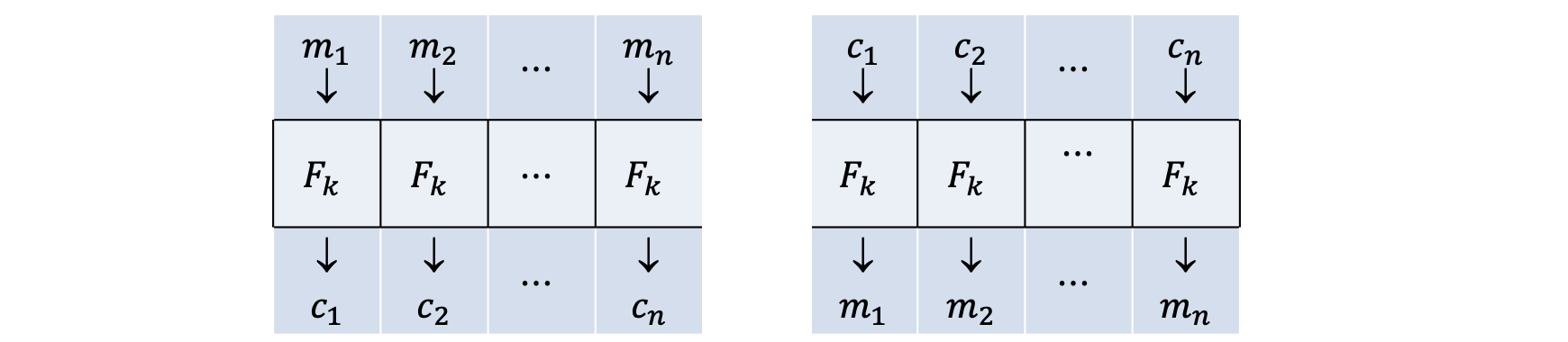
첫 번째는 Electronic Code Book(ECB) 입니다. 가장 초반의 Mode of Operations 는 이와 같이 각 블럭들이 독립적으로 암복호화 되었습니다. 가장 간단하지만 Plaintext 와 Key 가 같으면 항상 같은 Ciphertext 가 나온다는 것이 문제였고, 그래서 Chaining 이 대두되기 시작했습니다.
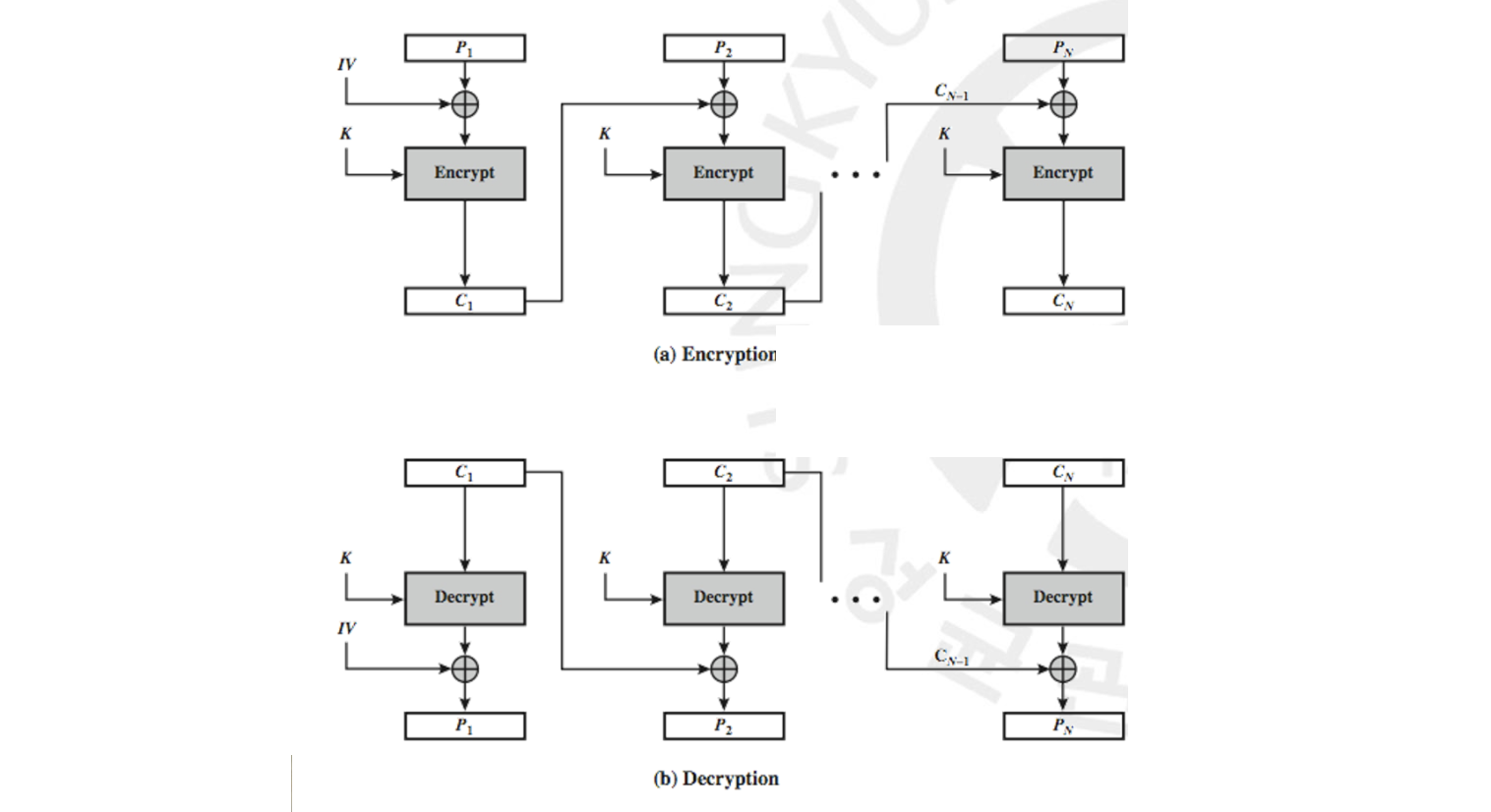
바로 Cipher Block Chaining(CBC) 입니다. 메세지(Plaintext)를 쪼갠 첫 블럭 이 먼저 IV 와 XOR 됩니다. 이를 key 값 로 암호화(ex. AES)하여 을 구합니다. 그러면 그 다음 블럭이 이 과 XOR 되고 이와 같은 과정을 마치 체인이 연결된 것처럼 마지막 블럭까지 계속하는 것입니다. 이 때문에 IV 만 달라도 서로 다른 Ciphertext 가 나오게 되는 것이지요. Decryption 은 반대로 진행하면 되지만, 관건은 IV 가 같아야 한다는 것입니다.
하지만 이런 Chaning 과 같은 방식도 문제가 있습니다. 앞의 ECB 와 같이 독립적으로 하면 내가 딱 원하는 블럭, 예를 들어 번째 블럭만 암복호화를 할 수 있습니다. 그런데 Chaning 방식에서는 딱 하나의 블럭을 암복호화하기 위해 앞에서부터 한 번씩 다 무조건 암복호화를 진행해야 하는 것입니다.
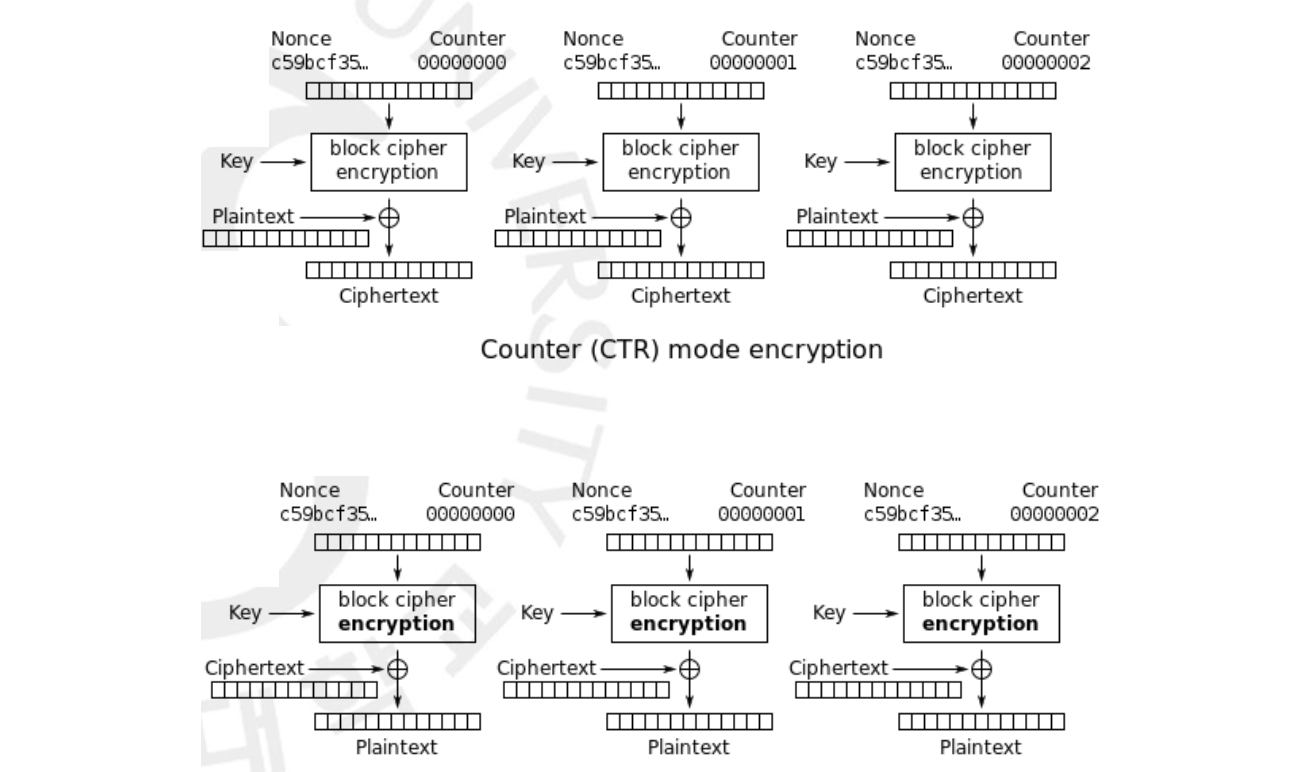
그렇게 나온 것이 Counter Mode(CTR) 입니다. 특이한 점은 Plaintext 가 아닌 Counter 를 암호화 하는 것입니다. 각 Block 마다 각기 다른 Counter 값을 Key 로 암호화 합니다. Counter 는 IV 를 1씩 더해서 만들고는 합니다. 이 값은 암호화가 될 값이기 때문에 굳이 비밀일 필요 없이 공개됩니다.
재미있는 점은 이 CTR 은 Padding 을 하지 않습니다. 따라서, 마지막으로 남은 Plaintext 가 블럭 단위 보다 작으면 그냥 그 값만 XOR 해서 그에 맞는 길이를 Ciphertext 로 내보냅니다. 일반적으로 Padding 을 하지 않는 Cipher 는 모두 Stream Cipher 라고 칭합니다. 그렇기 때문에 CTR 은 Block Cipher 와 사용할 경우 이를 Stream Cipher 로 만들어버리는 특징이 있습니다.
Chaning 을 하지 않기 때문에 특정 블럭만 연산이 가능하면서도, IV 만 다르면 Plaintext 와 Key 가 같더라도 결과가 다르게 나오기 때문에 앞의 두 Mode of Operations 의 장점들을 모두 가졌다고 할 수 있습니다. Chaning 과는 다르게 병렬적으로 처리할 수 있기 때문에 속도에서도 굉장히 뛰어납니다.
이렇게 Mode of Operations 을 정하고 Encryption 으로써 사용할 Block Ciphers 를 정해 최종적으로 암복호화가 이루어지게 됩니다.😊
