
Web Security 에 대해서 간단히 살펴본 내용은 괜찮으셨나요? 다음 주제는 바로 Cihpers(암호) 입니다. 이과생이라면 관심을 가질만한 암호학을 주제로 이야기를 드리려 합니다.
먼저, 큰 그림을 그려보기 위해 Cryptography Model 을 살펴보도록 합시다. 아래 그림을 보시죠.
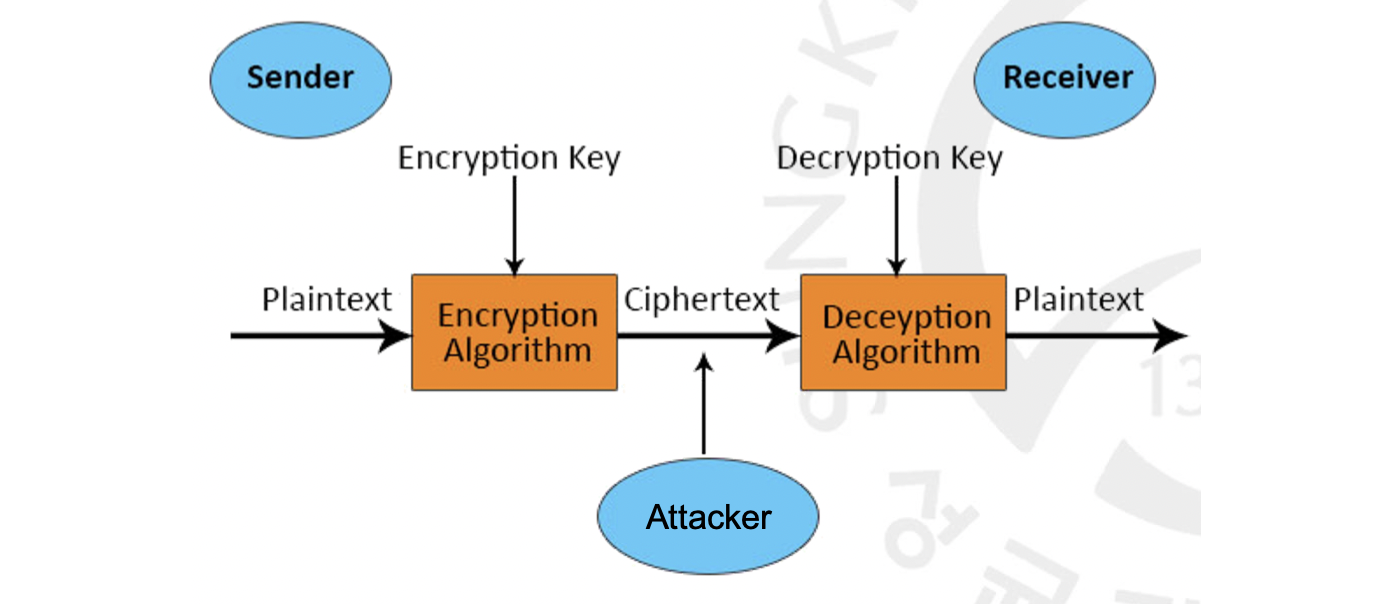
보안 이야기를 하면서 계속 얘기하는 말이지만 인터넷 영역에서 Sender 와 Receiver 를 잇는 완전하게 안전한 채널은 존재할 수 없게 되었습니다. 그렇기 때문에 Sender 가 쓴 메시지인 Plaintext(평문)를 알고리즘을 돌려 Ciphertext(암호문)으로 바꾼 뒤 송신하게 됩니다. 그렇기 때문에 공격자가 채널에 들어와 이를 가로채어도 무슨 메시지인지 알 수 없게 되는 것입니다.
암호문을 돌리는 Encryption Algorithm(암호화 알고리즘)을 돌릴 때 가장 중요한 것이 바로 Encryption Key 입니다. 사실 이 알고리즘은 대부분 세상에 공개되어 있기 때문에 공격자들도 이를 알 수 있습니다. 그렇다면 암호문을 다시 평문으로 바꾸는 것이 그리 어려운 일은 아닐 겁니다. 그래서 우리는 바로 Key 가 필요한 겁니다. 같은 알고리즘이더라도 이 Key 에 따라서 출력되는 암호문을 다르게 하는 겁니다. 물론 Receiver 영역에서 이를 다시 평문으로 돌리기 위해 수행하는 Decryption(복호화)도 다르지 않습니다. 이 Encryption Key 와 Decryption Key 는 서로 같을 수도, 다를 수도 있는데 같을 때를 Symmetry Key, 다를 때를 Asymmetry Key 라고 합니다.
이를 통해 알 수 있듯이, 결국 암호 분야에서의 관건은 Key 입니다. 방어자의 목표는 이 Key 를 지키는 것이고, 공격자의 목표가 바로 이 Key 를 강탈하는 것이죠. 결국 공격자의 입장에서 이 Key 를 알기 위해서 필요한 것은 Input 인 Plaintext 와 이에 대응하는 Output인 Ciphertext 를 구하는 것이 됩니다. 이러한 위협 모델들을 알아보도록 합시다.
Threat Model for Encryption
첫 번 째는 바로 Ciphertext-only Attack 입니다. 오직 Cihpertext 만을 알고있는 경우입니다. 네트워크를 통해 날라가는 이 암호문을 잡는 것은 그리 어려운 일이 아니기 때문에 가장 흔한 경우라고도 볼 수 있겠습니다. 그런데 이에 대응하는 평문을 모르기 때문에 공격자 입장에서는 키를 넣어보며 의미 있는 평문이 나올 때까지 Brute-Force 를 하는 방법 이외에는 할 수 있는 것이 많지 않을 것입니다. 이는 달리 봤을 때 방어자 입장에서 막기 가장 쉬운 공격이라고 할 수도 있습니다.
두 번 째는 Known-plaintext Attack 입니다. 말 그대로 공격자가 아는 Plaintext와 이에 대응하는 Ciphertext 의 Pair 을 몇 개 알고 있는 것입니다. 이전 Ciphertext-only Attack 보다는 조금 더 연역적인 추론이 가능하게 됩니다. 이 경우는 실제 공격에서 가장 빈번히 발생하는 상황이라고 합니다.
세 번 째는 Chosen-plaintext Attack 입니다. 이는 공격자가 선택한 Plaintext 에 대해서 이에 대응하는 Ciphertext 까지 아는 경우를 뜻합니다. 생각을 좀만 해보면 이 공격 또한 쉽게 일어나는 공격임을 짐작할 수 있습니다. 우리가 예를 들어 ssh 암호를 입력할 때를 생각해 보죠. 직접 어떤 메시지를 입력하고 바로 날아가는 채널에서 암호문을 캐치하는 것입니다. 공격자 입장에서는 key 의 구조를 파악하기 용이하도록 의도적으로 일정한 패턴을 지닌 평문을 넣어보면서 실험할 수 있기 때문에 보단 위험한 공격이 되겠습니다.
네 번 째는 Chosen-Ciphertext Attack 입니다. 이 또한 말 그대로 공격자가 선정한 어떤 Ciphertext 에 대한 Plaintext 를 아는 경우입니다. 공격자 입장에서는 제일 쉽지 않은 경우이지만 방어자 입장에서는 한 번 발생하면 제일 막기 까다로운 공격이 될 겁니다.
그러나, 세네 번 째의 Chosen 상황들은 실질적으로 일어나기 어렵기 때문에 제일 발생 빈도가 흔하지 않은 공격들입니다.
Security Goal in Encryption
다시 한 번 말해 우리가 암호화를 하기 위한 가장 큰 목표는 공격자가 Ciphertext 가 아니라, Key를 알지 못하도록 하는 것입니다.
그런데 사실 Key를 Brute-Force, 즉 전수 조사를 한다면 결국에는 알 수 밖에 없기 때문에 이는 불가능에 가깝습니다. 그렇기 때문에 우리는 Ciphertext 를 통해 Plaintext 를 유추하지 못하도록, 즉 Unconditonally Secure 하게 만들어야 합니다. 여기서 새로 나온 개념이 바로 Computationally Secure 입니다. 전수 조사를 하는 경우의 수를 대폭 늘려서 공격자가 Key 를 알기 위해 소요되는 Cost(시간, 돈)를 Key 를 알게 되었을 때의 이익보다 더 비싸게 만들어 버리는 겁니다. 비트코인 채굴이 좋은 예시겠죠?채굴을 했을 때 받는 돈보다 채굴을 하기 위한 인프라 비용 및 시간이 더 많이 들면 그 누구도 채굴을 포기하게 될 것입니다.

새로운 개념을 소개하기 위해 간단한 상황을 생각해죠. 만약 당신이 빈 방에서 저와 내기를 한다고 생각해봅시다. 당신은 위에 보이는 여러 장의 카드 중에서 하나를 뽑습니다. 목표는 제가 당신이 뽑은 그 카드를 알지 못하도록 하는 것입니다. 그리고 방에는 위와 같이 상자와 갖가지 자물쇠들이 있고 이를 사용할 수 있습니다. 이 때 당신이 어떤 전략을 쓰는 것이 가장 효과적일까요? 답은 의외로 뽑은 카드를 카드 더미 안에 랜덤한 위치에 꼽아두는 것일 겁니다.
당신이 박스에 숨기고 모든 자물쇠를 잠군다면 저는 그 상자를 따는데만 집중하면 될 것입니다. 어디에 숨겼는지를 알 수 있다는 것은 공격자인 제가 그 곳만을 공략할 수 있다는 뜻이니까요. 허나, 카드 안에 숨겨 놓는다면 저에게 카드를 찾는 것은 더 이상 노력의 영역이 아닌 운의 영역이 되어 버립니다. 이처럼 무언가를 알지 못하게 하는 가장 좋은 방법은 확률 게임을 만들어 버리는 것입니다.
당신이 뽑은 카드는 카드 더미 안 다른 카드들과 같은 확률로 선택될 겁니다. 이 때 나온 개념인 EQUALLY LIKELY 는 내 비밀값이 다른 후보자들 안에 평범하게 숨겨져 있는 상태를 의미합니다. 보안의 대가인 Calude Shannon은 암호란 평문의 개수만큼의 후보 키들이 존재하고 이 키들이 모두 equally likely, 즉 진짜 key 일 확률이 같을 때 완벽한 보안을 달성한다고 말하기도 했습니다.
(key 의 개수) = (Plaintext 의 개수) = (Ciphertext 의 개수)
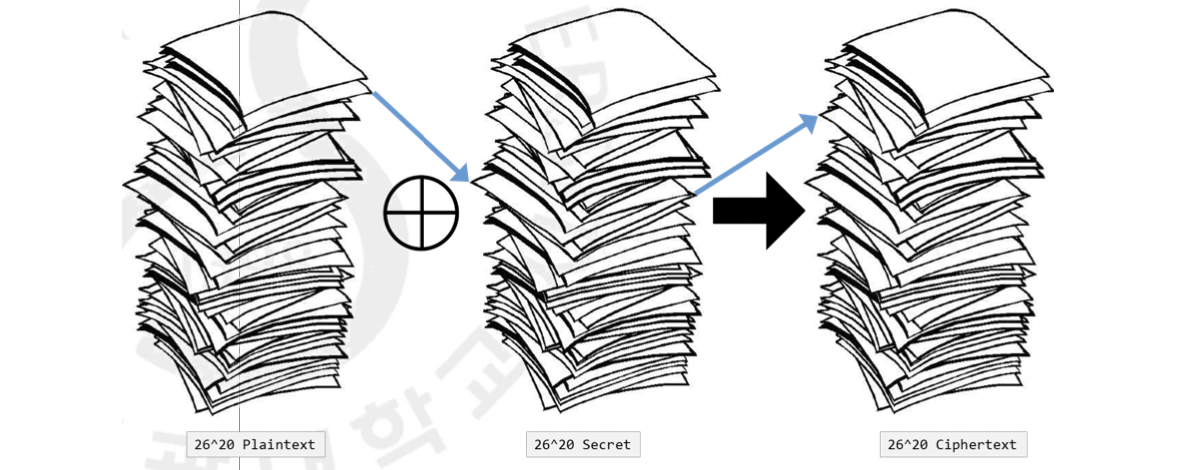
이를 달성하기 위한 방법의 예시는 아래와 같습니다. 20글자로 이루어진 평문을 암호화한다고 생각해봅시다. a-z 까지 한 글자의 경우의 수가 26이기 때문에 20글자인 평문의 경우의 수는 이 됩니다. 그렇기 때문에 key 또한 1부터 26까지 20개를 랜덤하게 뽑아 만듭니다. 이를 XOR 시키면 똑같은 크기의 암호문이 만들어지게 되는 것이지요. 공격자 입장에서 이 key를 찾을 확률은 이 되어버리는 겁니다.
OTP (One-Time Pad)
은행에서 통장을 만들 때 OTP 를 꼭 한번 써보셨죠? 그 OPT가 맞습니다. 유일한 완전한 보안, 즉 perfect secrecy 를 달성할 수 있는 OTP 에 대해 알아보고 넘어가도록 하겠습니다.
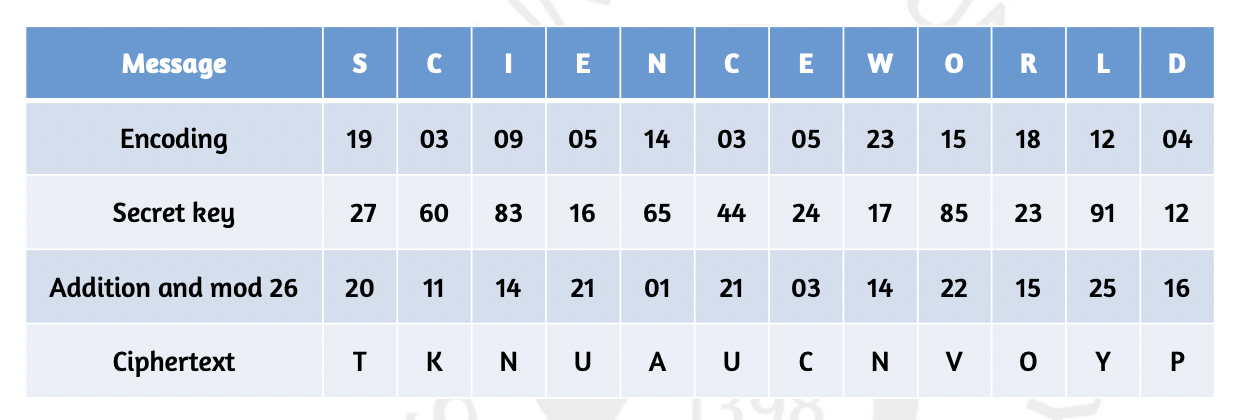
Encryption 예시를 봅시다. 평문 메시지가 12글자네요? 그렇다면 당연히 키도 12개여야 합니다. 그리고 이 키는 1이상 100까지의 숫자 중에서 랜덤하게 고른 겁니다. 그렇기 때문에 중 하나의 equally likely 를 달성하게 됩니다. 이 평문값과 그에 대응되는 키 값을 더 하고 모듈러 연산을 취해 암호문을 만들어서 보냅니다.
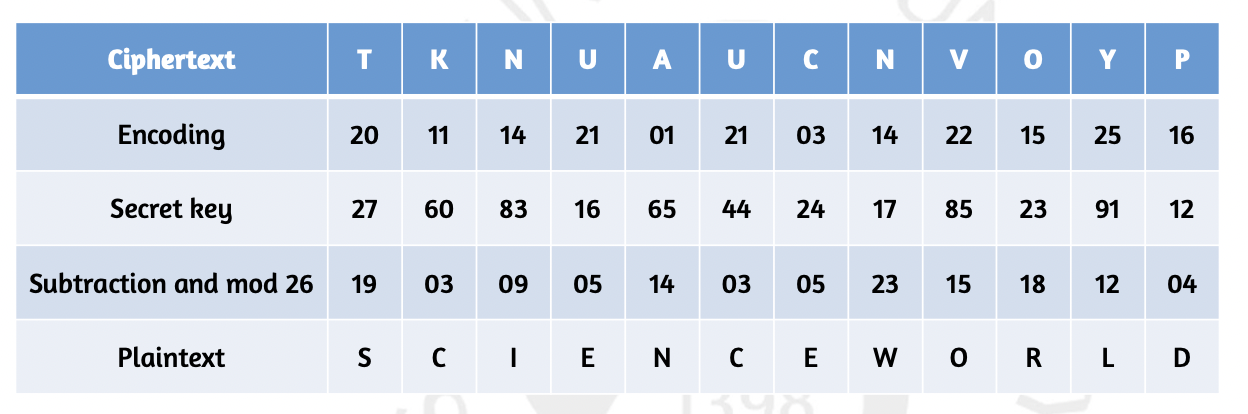
이어서 Decryption 을 확인해 봅시다. 받은 사람은 사전에 채널을 통해 같은 key 값을 가지고 있습니다. 그렇다면 반대로 빼고 모듈러 연산을 취함으로써 복호화 알고리즘을 통해 평문을 가질 수 있게 됩니다. 똑같은 크기 의 key를 랜덤 하게 생성하기 때문에 OTP는 이론적으로 perfect secrecy 를 달성하게 됩니다.
이렇게 되면 암호문을 통해서 평문을 유추하는 것은 불가능에 가까울 정도로 매우 어려워지게 됩니다. 그래서 이론적으로는 모든 암호화 알고리즘 중에서 OTP 만이 유일하게 perfect secrecy를 보장합니다. 하지만 평문과 같은 크기의 key 가 필요한 것은 치명적인 문제입니다. 이는 4GB의 비디오 파일을 암호화하기 위해서 4GB 만큼의 key를 나눠가져야 함을 의미합니다. 터무니 없는 일이지요...
그런데 컴퓨터가 완벽하게 랜덤을 구사할 수 있나요? 컴퓨터에서 만드는 랜덤에는 모두 주기가 있기 때문에 랜덤을 흉내내는 것일 뿐 완전한 랜덤을 만들 수가 없습니다. 그래서 이론이 아닌 우리가 실제로 쓰는 OTP를 얘기한다면 perfect secrecy 라 절대 할 수 없는 것입니다...🥲
그래서 요즘 들어 사용하는 것이 바로 Computationally Secure 인 것이죠. 이 세상의 모든 key 는 사실 모든 경우의 수를 직접 다 하는 전수조사, 즉 Brute-Force 를 수행해보면 언젠가는 결국 깨지게 됩니다. 실제로 확률적으로 모든 경우의 수의 반 정도를 수행해보면 key 보안이 깨진다고 합니다. 이 방법은 보안상으로 절대 막을 수가 없는 유일무이한 방법입니다. 그렇기 때문에 아예 사이즈를 키워버려서 경우의 수를 대폭 늘려버리는 방법을 택하거나 이 Computationally Secure을 사용하는 것입니다.
일상 생활에서 볼 수 있는 예로는 자전거 자물쇠가 있습니다. 대부분의 자전거 자물쇠는 0 부터 9까지의 4자리의 비밀번호를 취하고 있습니다. 그렇기 때문에 이론적으로는 , 즉 5000번 돌려보면 결국 풀리게 됩니다. 그런데 이 5000번을 돌리는 8시간 동안은 주인이 돌아온다는 가정을 했기 때문에 이와 같은 구조로 만들게 된 것이지요.
Pseudorandom
그렇다 하더라도 말했듯이 랜덤으로 key를 생성하는 것이 명실상부 최고의 방법입니다. deterministic 한 컴퓨터에서 nondetermistic, 즉 랜덤의 수열을 만들기 위해 고안된 것이 바로 Pseudorandom 입니다. 랜덤인 수들을 계속해서 만들어내는 것이 어렵기 때문에, 하나의 랜덤값으로 기계적인 알고리즘을 써서 무작위적인 것 처럼 보이는 랜덤 수열들을 만들어내는 것입니다. 여기서 이 하나의 랜덤값을 Seed(시드) 라고 합니다. 이러한 시드는 실제 존재하는 노이즈나 현재 시각을 밀리초로 표현하고 선정할 수 있습니다.
대표적인 Pseudorandom 에는 폰 노이만이 개발한 Middle Square Expansion 이 있습니다. 예를 들어, 3자리인 seed로 121이 주어졌을 경우, 121 x 121 = 14641 에서 가운데 숫자인 464를 추출합니다. 그리고 이를 이용해 464 x 464 = 215296이므로 가운데 529를 추출합니다. 마찬가지로 529 x 529 = 279841 이므로 984가 추출됩니다. 이를 계속해서 464 529 984 ... 으로 계속되는 sequence, 즉 순열을 만들 수 있게 됩니다. 하나의 값으로 마치 무작위적인 것처럼 보이는 값들을 계속해서 뽑아낼 수 있게 되는 것입니다. 송신자와 수신자가 key(sequence) 전체를 공유할 필요없이 오직 Seed 만 공유해도 되는 것입니다. 그렇기 때문에 OTP의 용량 문제를 해결할 수 있지요.

Pseudorandom 문제는 주기가 있다는 것입니다. 예를 들어 방금 설명한 알고리즘의 경우를 보더라도 위와 같은 순열을 계속해서 만들다가 기존 seed 값이 였던 121 이 나온다면 이후에 나오는 순열들은 이전 값들과 같을 것이기 때문에 랜덤과 거리가 완전히 멀어지게 됩니다.
또한, Pseudorandom으로 만든 순열은 결국 Seed 가 가질 수 있는 경우의 수만큼 개수를 가지게 됩니다. 예를 들어 3자리 시드로 만들 순열은 결국 개만이 존재한다는 것입니다. 이 값으로 24자리 순열을 만들었다 생각하면 의 경우의 수가 나올 수 있는 데 말입니다.
그렇기 때문에 Pseudorandom 의 수열을 진짜 랜덤인 수열과 구분하지 못하도록 만들기 위해서는 Seed 도 마찬가지로 충분히 키워 주기를 늘려야 합니다.(요즘은 보통 128비트를 사용합니다.) 컴퓨터가 모든 Seed 를 보고 같은 수열을 찾는 것을 비현실적이도록 해야 한다는 것이죠. 결국 Pseudorandom 또한 Computationally Secure 로 문제를 해결하게 됩니다.
