언어 모델은 사전 훈련을 하는 동안에 작업 시퀀스에 노출되고 이를 바탕으로 추론에 적용할 수 있음
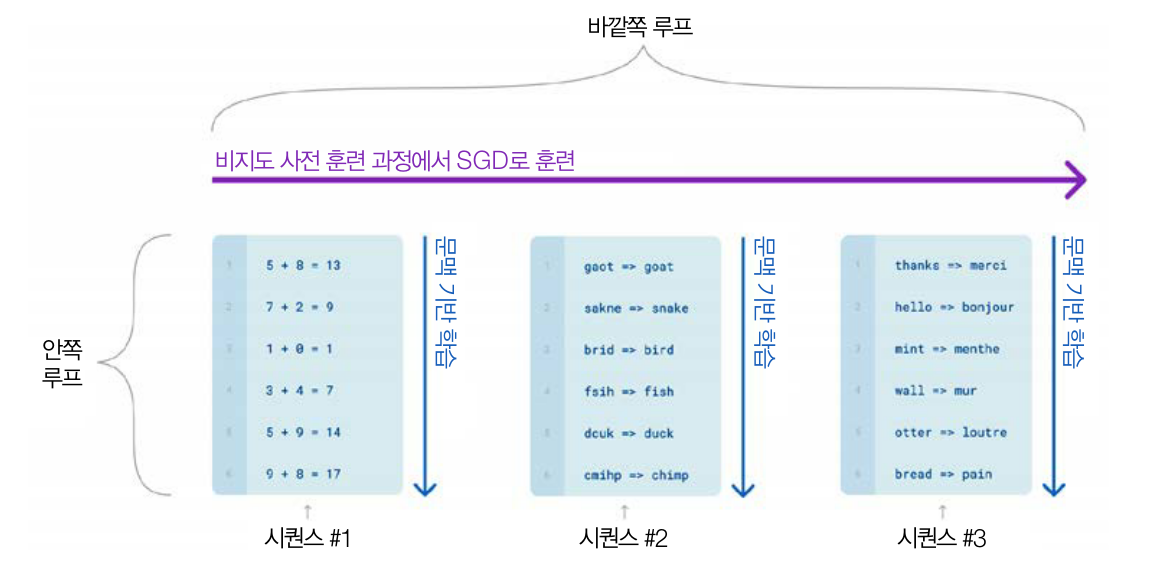
시퀀스1 : 덧셈
시퀀스2 : 단어 철자 배열
시퀀스3 : 번역
일관성 있는 텍스트 생성의 어려움
- 시퀀스나 토큰 분류 같은 작업에 특화된 헤드에서 예측 생성은 매우 간단함
- case1 모델이 일련의 로짓을 출력하고 최댓값을 선택해 예측 클래스를 얻음
- case2 소프트맥스 함수를 적용해 클래스별 예측 확률을 얻음
- 디코딩 방법(decoding method) 필요
- 모델의 확률 출력을 텍스트로 변환할 때 사용
- 디코딩이 반복적으로 수행되므로 입력이 모델의 정방향 패스를 한 번 통과할 때보다 많은 계산이 필요함
- 생성된 텍스트의 품질과 다양성은 디코딩 방법과 이에 관련된 하이퍼파라미터에 따라 달라짐
GPT-2 사례
- 자기회귀 모델(autoregressive model) 또는 코잘 언어 모델(causal language model)과 유사
- 조건부 텍스트 생성(conditional text generation), 즉 출력 시퀀스가 입력 프롬프트에 따라 결정됨
- 시작 프롬프트 or 문맥 시퀀스에 대한 확률의 연쇄 법칙(chain rule)을 사용한 조건부 확률(conditional probability)의 곱으로 나타남
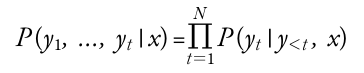
- 입력 시퀀스 : x = x1, x2, ... , xk
- 텍스트에 등장하는 토큰 시퀀스 : y = y1, y2, ..., yt의 확률 p(y|x) 추정
- 프롬프트로 시작하면 모델은 다음 토큰을 예측하고, 특수한 시퀀스 종료 토큰이나 사전에 정의한 최대 길이에 도달할 때까지 반복함
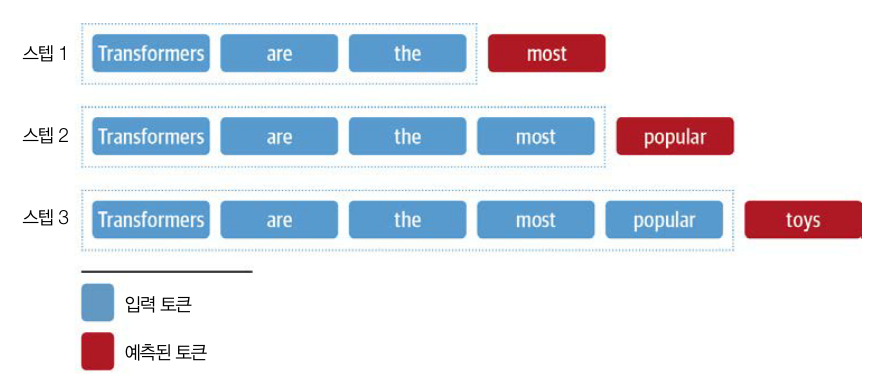
- 각 타임스텝에서 어떤 토큰을 선택할지 결정하는 디코딩 방법이 주요 핵심 과정임
- 일반적인 분류 방법과 유사함
- process1 : 언어 모델의 헤드는 각 스텝에서 어휘사전에 있는 토큰마다 로짓 Zt,i을 생성
- process2 : 소프트맥스 적용하여 확률 분포값 획득
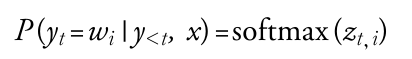
* process3 : 가장 높은 확률의 값 선택
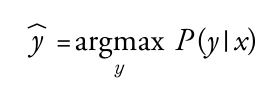
그리디 서치 디코딩
- 연속적인 모델 출력에서 이산적인 토큰을 얻는 가장 간단한 디코딩 방법
# hide_output
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
# model_name = "gpt2-xl" # 6기가 이상 필요
model_name = "gpt2" # 메모리 에러시 작은 사이즈
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
- 디코딩 메서드 구현
# hide_output
import pandas as pd
input_txt = "Transformers are the"
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
iterations = []
n_steps = 8 # 8번의 타임 스텝 디코딩 수행
choices_per_step = 5 # 각 타임스텝마다 확률이 가장 높은 토큰 5개 저장
with torch.no_grad():
for _ in range(n_steps):
iteration = dict()
iteration["Input"] = tokenizer.decode(input_ids[0])
output = model(input_ids=input_ids)
# 첫번째 배치의 마지막 토큰의 로짓을 선택
next_token_logits = output.logits[0, -1, :]
# 소프트 맥스 함수 적용
next_token_probs = torch.softmax(next_token_logits, dim=-1)
# 확률이 가장 높은 순으로 정렬
sorted_ids = torch.argsort(next_token_probs, dim=-1, descending=True)
# 가장 확률이 높은 토큰 저장
for choice_idx in range(choices_per_step):
token_id = sorted_ids[choice_idx]
token_prob = next_token_probs[token_id].cpu().numpy()
token_choice = (
f"{tokenizer.decode(token_id)} ({100 * token_prob:.2f}%)"
)
iteration[f"Choice {choice_idx+1}"] = token_choice
# 입력에 예측한 다음 토큰 추가
input_ids = torch.cat([input_ids, sorted_ids[None, 0, None]], dim=-1)
iterations.append(iteration)
pd.DataFrame(iterations)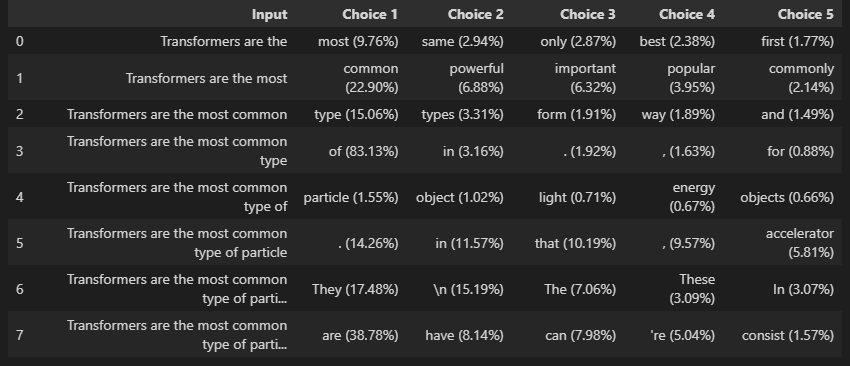
- 트랜스포머에 자기회귀 모델(like GPT-2)을 위해 generate() 함수 제공
- generate() 함수 사용
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
# do_sample=False 앞선 결과를 재현하기 위한 파라미터
output = model.generate(input_ids, max_new_tokens=n_steps, do_sample=False)
print(tokenizer.decode(output[0]))
# Transformers are the most common type of particle. They are- 그리드 서치의 단점 : 반복적인 출력 시퀀스를 생성하는 경향이 있어 생성에 적합하지 않음
max_length = 128 # 최대 생성 토큰값
input_txt = """In a shocking finding, scientist discovered \
a herd of unicorns living in a remote, previously unexplored \
valley, in the Andes Mountains. Even more surprising to the \
researchers was the fact that the unicorns spoke perfect English.\n\n
"""
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output_greedy = model.generate(input_ids, max_length=max_length,
do_sample=False)
print(tokenizer.decode(output_greedy[0]))
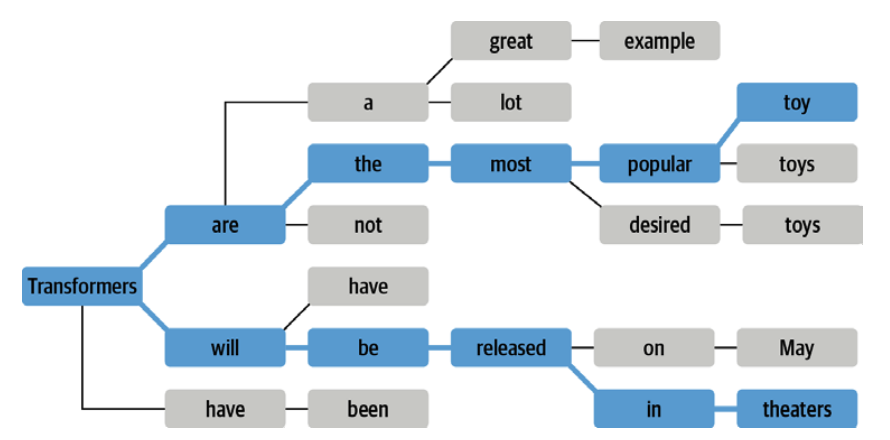
# "The unicorns were very intelligent, and they were very intelligent," said Dr. David S. Siegel, a professor of anthropology at the University of California, Berkeley. "They were very intelligent, and they were very intelligent, and they were very intelligent, and they were very intelligent, and they were very intelligent, and they were very intelligent, and they were very intelligent, and they were very빔 서치 디코딩(beam search decodrig)
- 확률이 가장 높은 상위 b개(빔, beam, 불완전 가설, partial hypothesis)의 다음 토큰을 추적함
- n-그램 패널티와 같이 사용하면 반복을 줄일 수 있음
- 사실적인 정확성을 요하는 기계번역 등의 어플리케이션에서 많이 활용함
[예시 : b=2인 빔 서치]
- 확률이 아닌 로그 확률로 시퀀스 점수를 매김
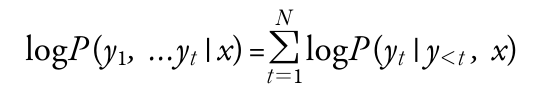
- 시퀀스 전체 확률을 계산하려면 조건부 확률의 곱(0~1 범위)을 계산해야 하는데, 이때 전체 확률은 언더플로(underflow)가 쉽게 발생하기 때문에 로그 적용
- 상대적 확률만 비교하면 되기 때문에 로그 확률을 사용해서도 비교 가능함
- 예시 : 토큰이 1024개인 시퀀스에서 토큰의 확률이 0.5인 경우의 결과값 비교
- 확률의 곱셈값 : 5.562 ==> 로그 확률의 덧셈값 : -709.7827
0.5 ** 1024 # 5.562684646268003e-309
import numpy as np
sum([np.log(0.5)] * 1024) # -709.7827128933695import torch.nn.functional as F
def log_probs_from_logits(logits, labels):
logp = F.log_softmax(logits, dim=-1) # 로짓 정규화
#예측하려는 시퀀스에 있는 토큰 확률만 선택
logp_label = torch.gather(logp, 2, labels.unsqueeze(2)).squeeze(-1)
return logp_label
def sequence_logprob(model, labels, input_len=0):
with torch.no_grad():
output = model(labels)
# 모델이 다음 토큰을 예측하기 때문에 첫번째 레이블 로짓 제외
# 마지막 로짓에 대한 정답이 없기 때문에 마지막 로짓 제외
log_probs = log_probs_from_logits(
output.logits[:, :-1, :], labels[:, 1:])
seq_log_prob = torch.sum(log_probs[:, input_len:]) # 토큰의 로그 확률 더하기
return seq_log_prob.cpu().numpy()
logp = sequence_logprob(model, output_greedy, input_len=len(input_ids[0]))
print(tokenizer.decode(output_greedy[0]))
# In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
# "The unicorns were very intelligent, and they were very intelligent," said Dr. David S. Siegel, a professor of anthropology at the University of California, Berkeley. "They were very intelligent, and they were very intelligent, and they were very intelligent, and they were very intelligent, and they were very intelligent, and they were very intelligent, and they were very intelligent, and they were very
print(f"\nlog-prob: {logp:.2f}") # log-prob: -83.32
# num_beams=5 : num_beams 매개변수에 빔 개수 지정
#크기가 클수록 결과가 더 좋을 가능성이 높지만 시간이 오래 걸림
output_beam = model.generate(input_ids, max_length=max_length, num_beams=5,
do_sample=False)
logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
# The researchers, from the University of California, San Diego, and the University of California, Santa Cruz, found that the unicorns were able to communicate with each other in a way that was similar to that of human speech.
# "The unicorns were able to communicate with each other in a way that was similar to that of human speech," said study co-lead author Dr. David J.
print(f"\nlog-prob: {logp:.2f}") # log-prob: -78.34
# no_repeat_ngram_size : n-그램 패널티 부과
# n-그램을 생성하는 경우 다음 토큰 확률이 0이됨
output_beam = model.generate(input_ids, max_length=max_length, num_beams=5,
do_sample=False, no_repeat_ngram_size=2)
logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
# In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
# The researchers, from the University of California, San Diego, and the National Science Foundation (NSF) in Boulder, Colorado, were able to translate the words of the unicorn into English, which they then translated into Spanish.
# "This is the first time that we have translated a language into an English language," said study co-author and NSF professor of linguistics and evolutionary biology Dr.
print(f"\nlog-prob: {logp:.2f}") # log-prob: -101.87샘플링방법
-
사실적인 정확성보다는 다양성이 더 중요한 잡담이나 분야에 국한도지 않은 기사 작성에 활용 가능
-
방법1. 각 타임스텝내에 모델이 출력한 전체 어휘의 확률분포값에서 랜덤 샘플링
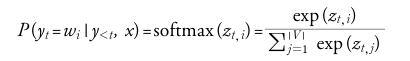
|V|는 어휘사전의 크기, T는 로짓의 스케일을 조정하는 온도 파라미터를 추가하여 출력의 다양성 제어
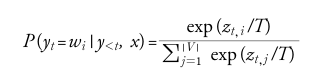
-
T의 값을 여러 개로 줘서 결과 비교
- T < 1 : 드문 토큰 억제, 정점에서 확률이 높음
- T > 1 : 숫자기 커질 수록 변별력이 떨어짐
#hide_input
#id temperature
#alt Token probabilities as a function of temperature
#caption Distribution of randomly generated token probabilities for three selected temperatures
import matplotlib.pyplot as plt
import numpy as np
def softmax(logits, T=1):
e_x = np.exp(logits / T)
return e_x / e_x.sum()
logits = np.exp(np.random.random(1000))
sorted_logits = np.sort(logits)[::-1]
x = np.arange(1000)
for T in [0.5, 1.0, 2.0]:
plt.step(x, softmax(sorted_logits, T), label=f"T={T}")
plt.legend(loc="best")
plt.xlabel("Sorted token probabilities")
plt.ylabel("Probability")
plt.show()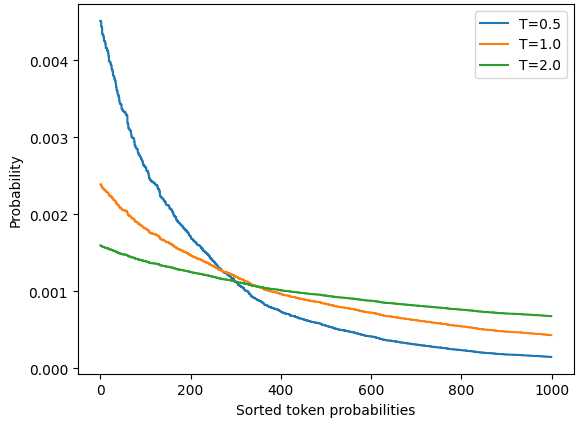
- 실제 결과로 확인
# hide
torch.manual_seed(42)
output_temp = model.generate(input_ids, max_length=max_length, do_sample=True,
temperature=2.0, top_k=0)
print(tokenizer.decode(output_temp[0]))
# Feed Boost Year Hampe Eagle Rouse Symbol Steal Therefore inappropriate Sprite 69 151 NO-James Ridene Castle joviespantry Spy legislative Truever Beast Pascal Hermes Musk Central Bombsaver democracy Civil codesRosSkill lives your choicesFight scan buggy huntDun 550 micro brightly Byrne Join Bittees Radiustool toddlersAustin Ahmad Alexandophyete four 32 Democratic Pledgeson idea Masterserrors order againtonache013 robot Palest VP carrotsinvest# hide
torch.manual_seed(42)
output_temp = model.generate(input_ids, max_length=max_length, do_sample=True,
temperature=0.5, top_k=0)
print(tokenizer.decode(output_temp[0]))
# "They didn't speak any different languages than normal humans, and they were able to communicate with us in the same way that we communicate with our cousins in other parts of the world," says Dr. David W. Waddell, a professor of animal behavior and ecology at the University of California, San Francisco.
#The unicorns were found in a valley in the Andes Mountains, about 50탑-k 및 뉴클리어스 샘플링(탑-p)
- 문맥상 이상한 단어 제어 방법
- 각 타임스텝에서 샘플링 수를 줄이는 방법
- 탑-k : 고정된 k값을 주어 제어, 확률이 높은 k개를 선택하여 사용
- 뉴클리어스 샘플링 : 동적인 p값을 주어 제어, 확률질량으로 예를 들면 95% 이내의 단어 활용
- 탑-k & 탑-p : top_k = 50, top_p = 0.9 이면 확률이 높은 50개의 토큰에서 확률질량이 90프로인 토큰 선택하여 생성
# hide
torch.manual_seed(42)
# hide
input_txt = """In a shocking finding, scientist discovered \
a herd of unicorns living in a remote, previously unexplored \
valley, in the Andes Mountains. Even more surprising to the \
researchers was the fact that the unicorns spoke perfect English.\n\n
"""
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
import torch.nn.functional as F
with torch.no_grad():
output = model(input_ids=input_ids)
next_token_logits = output.logits[:, -1, :]
probs = F.softmax(next_token_logits, dim=-1).detach().cpu().numpy()
#id distribution
#alt Probability distribution of next token prediction.
#caption Probability distribution of next token prediction (left) and cumulative distribution of descending token probabilities
import matplotlib.pyplot as plt
import numpy as np
fig, axes = plt.subplots(1, 2, figsize=(10, 3.5))
axes[0].hist(probs[0], bins=np.logspace(-10, -1, 100), color="C0", edgecolor="C0")
axes[0].set_xscale("log")
axes[0].set_yscale("log")
axes[0].set_title("Probability distribution")
axes[0].set_xlabel("Probability")
axes[0].set_ylabel("Count")
#axes[0].grid(which="major")
axes[1].plot(np.cumsum(np.sort(probs[0])[::-1]), color="black")
axes[1].set_xlim([0, 10000])
axes[1].set_ylim([0.75, 1.01])
axes[1].set_title("Cumulative probability")
axes[1].set_ylabel("Probability")
axes[1].set_xlabel("Token (descending probability)")
#axes[1].grid(which="major")
axes[1].minorticks_on()
#axes[1].grid(which='minor', linewidth='0.5')
top_k_label = 'top-k threshold (k=2000)'
top_p_label = 'nucleus threshold (p=0.95)'
axes[1].vlines(x=2000, ymin=0, ymax=2, color='C0', label=top_k_label)
axes[1].hlines(y=0.95, xmin=0, xmax=10000, color='C1', label=top_p_label, linestyle='--')
axes[1].legend(loc='lower right')
plt.tight_layout()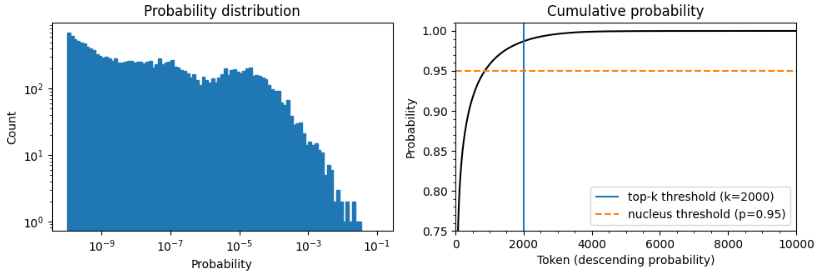
torch.manual_seed(42)
output_topk = model.generate(input_ids, max_length=max_length, do_sample=True, top_k=50)
print(tokenizer.decode(output_topk[0]))
#To get to the mountains, the researchers first needed to make sure that each of the animals, except those the researchers said were native to northern countries, didn't get injured.
#The researchers also found only one unicorn, also believed to be the same species as the original unicorn, who, according to the Spanish government, is described only in the journal Dinos Métropolitana.torch.manual_seed(42)
output_topp = model.generate(input_ids, max_length=max_length, do_sample=True, top_p=0.90)
print(tokenizer.decode(output_topp[0]))
# To get to the mountains, the researchers first needed to make sure that each of the animals, except for the unicorns, were properly social. To do this, they had to use technology to help the group to understand each other and to help the animal communicate with one another.
#It took only 15 minutes, but the animals began to talk to each other in a way that they thought was human
개발 스터디 노트입니다.