chapter3 : 트랜스포머 파헤치기
트랜스포머 아키텍처
트랜스포머의 기본 구조는 '인코더-디코더(Encoder-Decoder)이다.
-
인코더 : 입력 토큰의 시퀀스를 은닉 상태(Hidden state) 또는 문맥(context)라 부르는 임베딩 벡터의 시퀀스로 변환함
-
디코더 : 인코더의 은식 상태를 사용해 출력 토근의 시퀀스를 한 번에 하나씩 반복적으로 생성함
-
[추가 참조]
- 인코더 : 소스 시퀀스의 정보를 압축해 디코더로 보내는 역할 담담
- 인코딩 : 인코더가 소스 시퀀스 정보를 압축하는 과정
- 디코더 : 인코더가 보내 준 소스 시퀀스의 정보를 받아서 타깃 시퀀스를 생성함
- 디코딩 : 디코더가 타깃 시퀀스를 생성하는 과정
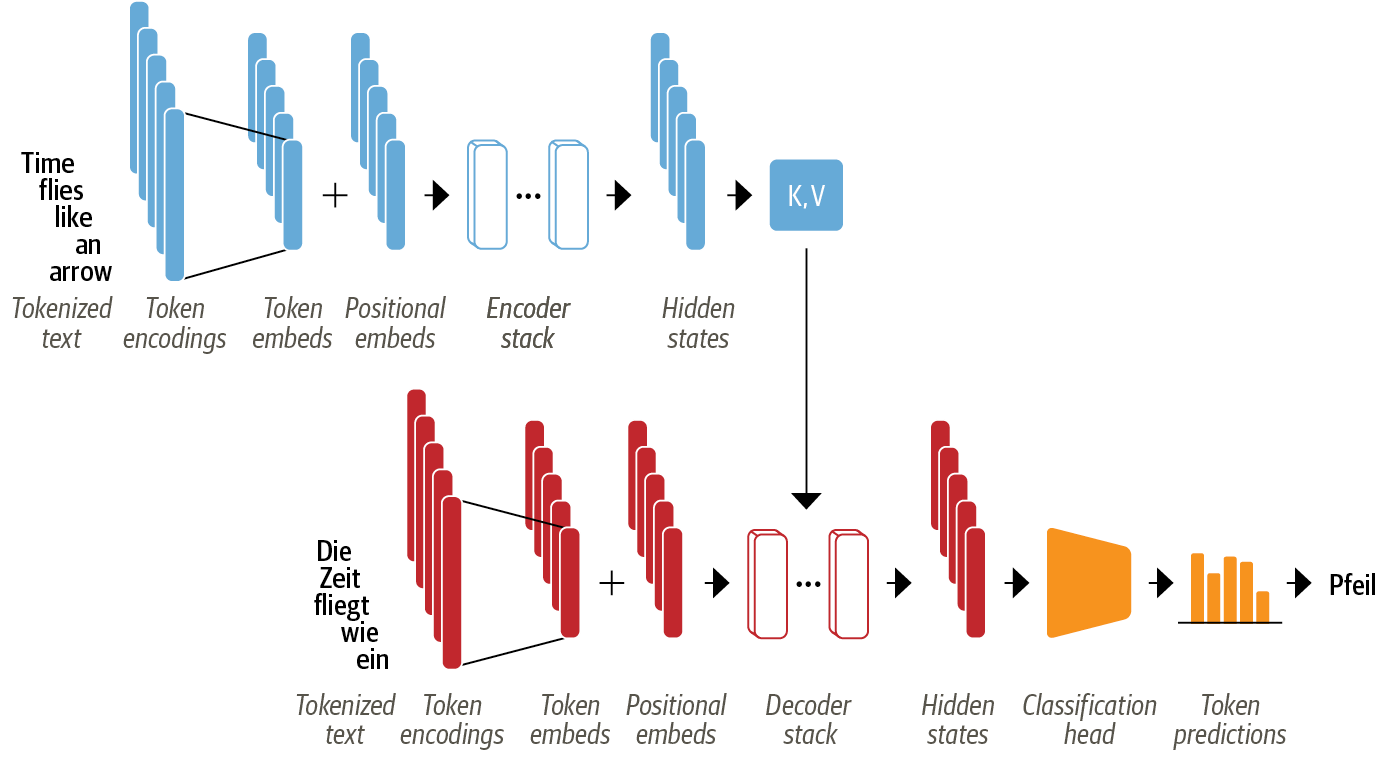
1. 트랜스포머 아키텍처의 특징
- 텍스트 데이터를 토큰화하여 토큰 임베딩(token embedding)으로 변환하고, 토큰의 위치 정보가 담긴 위치 임베딩(position embedding)을 함께 입력하여 어텐션 메커니즘이 토큰의 상대적 위치를 알게함
- 인코더에 인코더 층(encoder layer)의 스택(or 블록)과 디코더에 디코더 층(decoder layer)의 스택으로 구성됨
- 스택 혹은 블록은 컴퓨터 비전에서 합성곱 층의 스택과 유사함
- 디코더 층마다 인코더의 출력이 주입되어 다음 토큰을 예측하고, 예측된 다음 토큰이 다시 디코더에 주입되어 그 다음 토큰을 또 다시 예측하며 EOS(end-of-sequence) 토큰 혹은 최대 예측 길이까지 지속됨
2. 트랜드포머 모델의 유형 분류
1) 인코더 only
- 시퀀스 표현법 : 텍스트 시퀀스 입력을 풍부한 수치 표현으로 변환함
- 모델링 방법 : 양방향 어텐션(bidirectional attention), 한 토큰에 대한 계산은 좌우(이전 토큰, 이후 토큰) 문맥에 따라 달라짐
- 적합한 task : 텍스트 분류, 개체명 인식기
- 모델 예: Bert, RoBERTa, DistilBERT
2) 디코더 only
- 시퀀스 표현법 : 시작 텍스트를 기반으로 다음 단어를 반복 예측하여 시퀀스 자동 완성
- 모델링 방법 : 코잘 어텐션(causal attention), 자기회귀 어텐션(autoregressive attention), 한 토큰에 대한 계산은 오직 왼쪽 문맥에 따라 달라짐
- 모델 예 : GPT 계열
3) 인코더-디코더 결합
- 모델링 방법 : 한 텍스트의 시퀀스를 다른 시퀀스로 매핑
- 적합한 task : 기계 번역, 요약 작업
- 모델 예 : BART, T5
3. 인코더
트랜스포머 인코더는 여러 개의 인코더 층이 서로 쌓여 구성됨
- Encoder block
- 멀티 헤드 셀프 어텐션(multi-head self-attention)
- 각각의 입력 임베딩에 적용되는 완전 연결 피드 포워드 층(fully connected feed-forward layer)
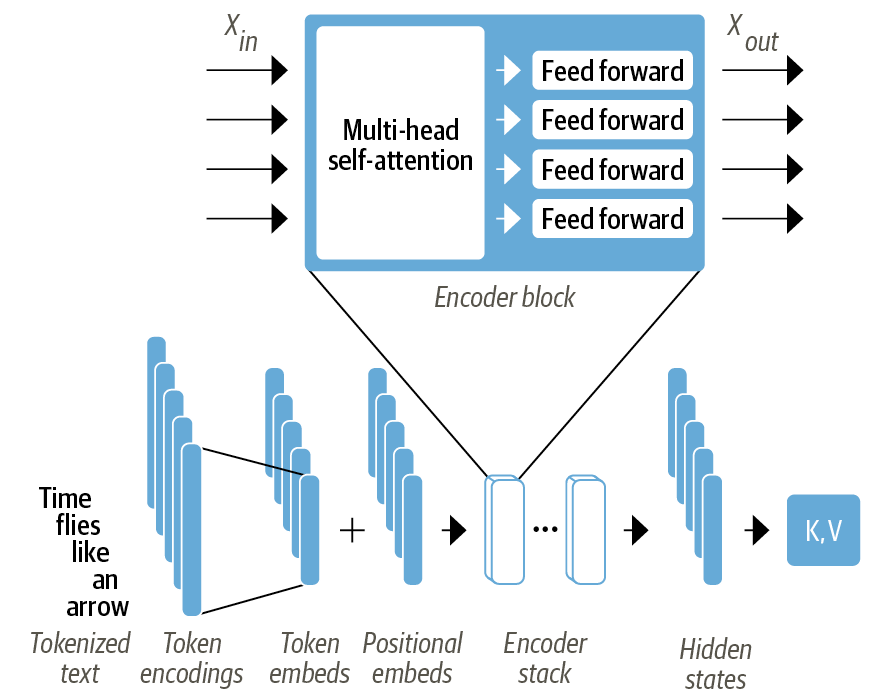
인코더 블록의 각 층은 심층 신경망을 효율적으로 훈련하기 위해 표준 기법인 스킵 연결(skip connection)과 층 정규화(layer normalization)도 사용함
1) 셀프 어텐션(self-attention)
개념이해
- 각 토큰에 고정된 임베딩이 아닌 전체 시퀀스(문맥)를 사용하여 임베딩의 가중 평균을 계산함
-
Xi는 모든 xj(1 to n)의 선형 결합으로 나타낼 수 있음
-
xi에 대한 어텐션 가중치 Wji의 총합은 1(확률)이 되도록 정규화됨
-
예시
- 문구 : "time flies like an arrow"
- files(3인칭 동사인 치솟다는 뜻과 명사인 파리라는 뜻을 갖은 동음이의어의 의미 파악을 할 때)가 여러 의미를 갖을 때, time꽈 arrow 토큰 임베딩에 더 큰 어텐션 가중치가 할당되어 맥락을 통합함
=> 이렇게 생성된 임베딩을 컨텍스트에 맞춘 임베딩(contextualized embedding)이라함
=> ELMO등의 언어 모델에서 사용되고 있었음

스케일드 점곱 어텐션(scaled dot-product attention)
- 셀프 어텐션 레이어를 구현하는 일반적인 방법 중 하나임
- 구현 방법
1) 각 토큰 임베딩을 query, key, value로 변환
2) 어텐션 스코어 계산 : key와 value의 유사도 값 계산(n X n)
3) 어텐션 가중치 계산 : 첫번째 dot product(스칼라곱)에서 스케일링 팩터를 곱하여 정규화하고, 그 다음 softmax 함수로 총합이 1이 되로록 정규화함
4) 토큰 임베딩 값 업데이트 : 어텐션 가중치가 얻어지면 v1 to vn까지 가중치를 반복해서 업데이트함

# 1) 텍스트 데이터 토크나이징
from transformers import AutoTokenizer
model_ckpt = "bert-base-uncased"
text = "time flies like an arrow etc"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
"""
tokenizer info : BertTokenizerFast(name_or_path='bert-base-uncased', vocab_size=30522, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
"""
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False) # add_special_tokens=False <== [CLS], [SEP] 포함
"""
inputs info : {'input_ids': tensor([[ 2051, 10029, 2066, 2019, 8612, 4385]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]])}
"""
# 2) 텍스트 임베딩
from torch import nn
from transformers import AutoConfig
config = AutoConfig.from_pretrained(model_ckpt)
"""
config info :
BertConfig {
"_name_or_path": "bert-base-uncased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.30.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
"""
token_emb = nn.Embedding(config.vocab_size, config.hidden_size)
token_emb # Embedding(30522, 768)
inputs_embeds = token_emb(inputs.input_ids)
"""
>>> inputs_embeds
tensor([[[-2.3282, -0.0118, -1.9412, ..., 1.5498, -0.9696, 0.5593],
[-0.7488, 0.0046, -0.2549, ..., 0.1123, -0.2114, 0.6592],
[ 1.0944, 1.1721, -0.0549, ..., 1.2206, -1.6383, -0.0529],
[-0.2461, -0.7813, 0.0361, ..., 0.8733, 0.8599, 0.4416],
[-1.0326, 1.4316, -1.0660, ..., 0.3551, -0.6275, 1.8587],
[-1.3137, 1.0480, -1.1594, ..., -1.3812, -1.3219, 0.0499]]],
grad_fn=<EmbeddingBackward0>)
"""
inputs_embeds.size() # torch.Size([1, 6, 768])
# 3) attendtion score 계산하기 및 가중치 update
import torch
from math import sqrt
query = key = value = inputs_embeds
dim_k = key.size(-1) # 768
# key.transpose(1,2).shape == torch.Size([1, 768, 6])
scores = torch.bmm(query, key.transpose(1,2)) / sqrt(dim_k)
scores.size() # torch.Size([1, 6, 6])
# 4) 소프트 맥스로 가중치의 합이 1이 되도록 정규화
import torch.nn.functional as F
weights = F.softmax(scores, dim=-1)
# weights.shape # torch.Size([1, 6, 6])
weights.sum(dim=-1) # tensor([[1., 1., 1., 1., 1., 1.]], grad_fn=<SumBackward1>)
# 5) 위치
attn_outputs = torch.bmm(weights, value)
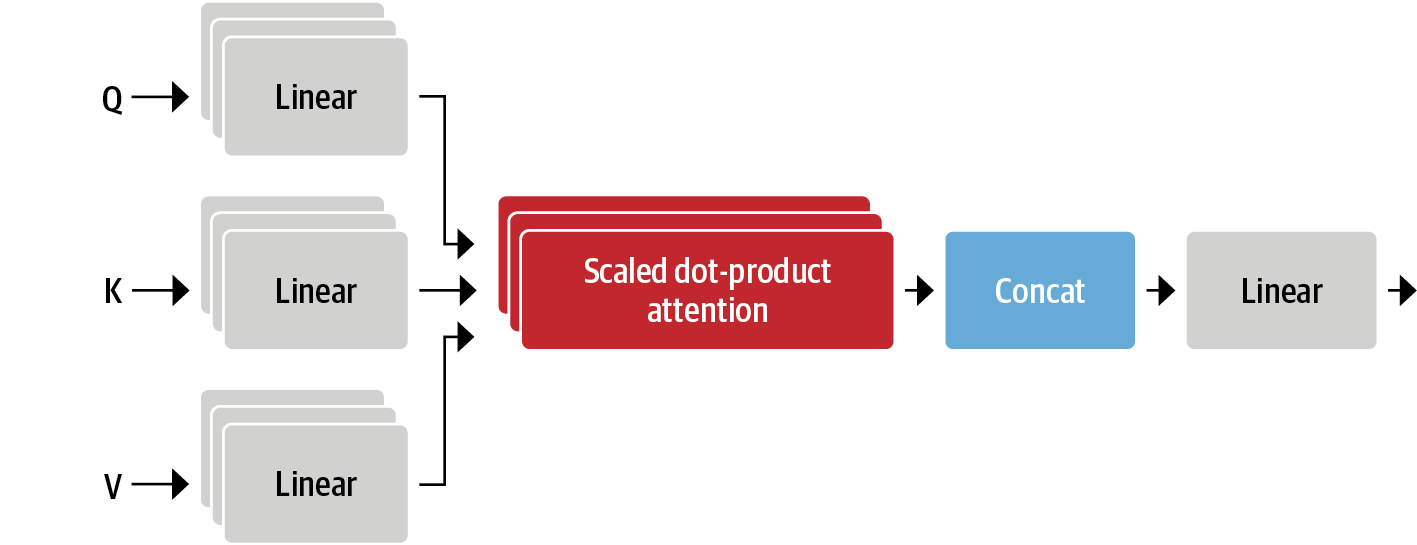
attn_outputs.shape # torch.Size([1, 6, 768])멀티 헤드 어텐션
- 셀프 어텐션으로 각각 독립된 linear transformation으로 Q, K, V 벡터 생성
- 셀프 어텐션 레이어가 시퀀스의 다양한 의미적 측면에 집중할 수 있도록 학습가능한 파라미터 셋을 갖음
- 멀티 헤드 어텐션이 필요한 이유
- 각각의 헤드가 각각의 목적(예: 주어-동사 상호작용에 집중하는 헤드 1개, 근처 형용사를 찾는 헤드 1개 등)에 맞춰 여러 정보를 갖을 수 있음
def scaled_dot_product_attention(query, key, value):
# self-attention
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
weights = F.softmax(scores, dim=-1)
return torch.bmm(weights, value)
class AttentionHead(nn.Module):
# 단일 어텐션
def __init__(self, embed_dim, head_dim):
super().__init__()
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
def forward(self, hidden_state):
# 셀프어텐션
attn_outputs = scaled_dot_product_attention(
self.q(hidden_state), self.k(hidden_state), self.v(hidden_state))
return attn_outputs
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.hidden_size #768
num_heads = config.num_attention_heads # 12
head_dim = embed_dim // num_heads # 64
# 셀프어텐션 초기화 후 모듈리스트에 넣기
self.heads = nn.ModuleList(
[AttentionHead(embed_dim, head_dim) for _ in range(num_heads)]
)
# 최종 W0 값 초기화
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, hidden_state):
# self-attentiond의 hidden_state를 멀티 헤드 수 만큼 도출하여 concat
x = torch.cat([h(hidden_state) for h in self.heads], dim=-1)
# W0 업데이트
x = self.output_linear(x)
return x
multihead_attn = MultiHeadAttention(config)
attn_output = multihead_attn(inputs_embeds)
attn_output.size() # torch.Size([1, 6, 768])
2) 피드 포워드 층
- 두 개의 레이어로 이뤄진 완전 연결 신경망임
- 전체 임베딩 시퀀스를 단일 벡터가 아닌 각 임베딩을 독립적으로 처리함
- GELU(Gaussian Error Linear Unit) 활성화 함수 사용
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size) # (768, 3072)
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size) # (3072, 768)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob) # 0.1
def forward(self, x):
x = self.linear_1(x)
x = self.gelu(x)
x = self.linear_2(x)
x = self.dropout(x)
return x
feed_forward = FeedForward(config)
ff_outputs = feed_forward(attn_outputs)
ff_outputs.size() # torch.Size([1, 6, 768])3) 층 정규화 하기
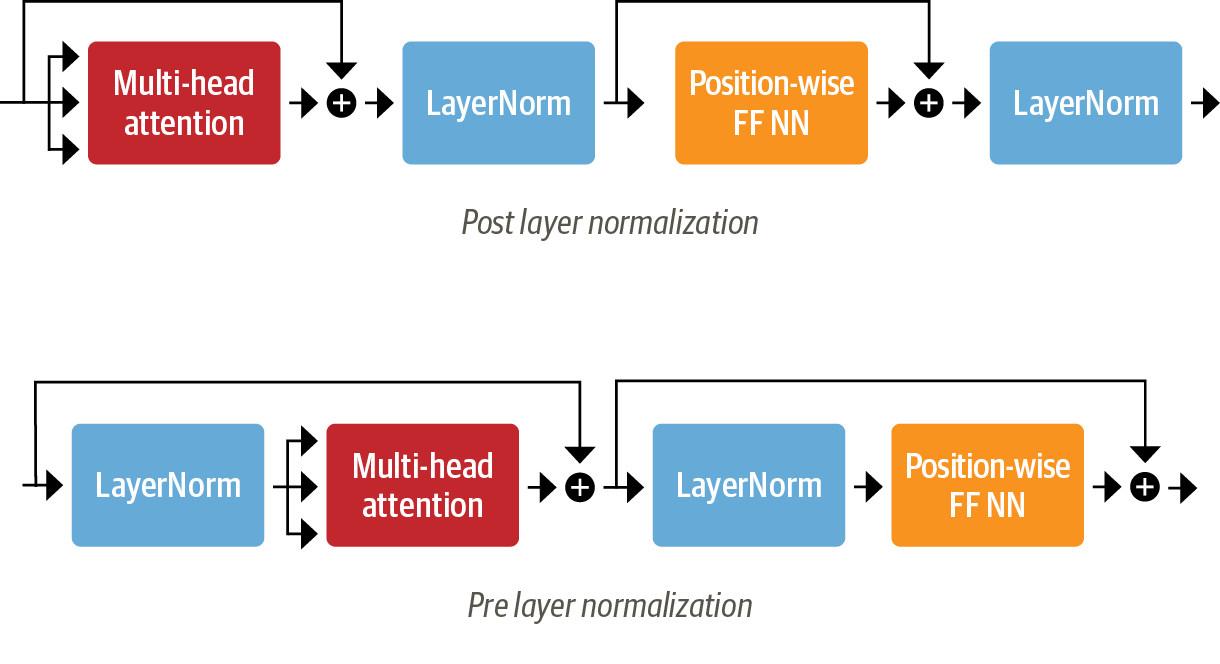
- layer normalization : 레이어 정규화는 배치 내 각 입력을 평균 0, 분산 1이 되도록 정규화함
- Post layer normalization : 그래디언트가 발산할 수 있어서 학습률 웜업(learning rate warm-up)으로 훈련 중에 학습률을 점차적으로 작은 값에서 최대 값까지 증가시킴
- Pre layer normalization : 안정적인 훈련이 가능하며, 학습률 웜업이 필요하지 않음
- skip connections : 연결 스킵은 텐서를 모델의 가음 레이어에 처리하지 않고 전달함
class TransformerEncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.layer_norm_1 = nn.LayerNorm(config.hidden_size)
self.layer_norm_2 = nn.LayerNorm(config.hidden_size)
self.attention = MultiHeadAttention(config)
self.feed_forward = FeedForward(config)
def forward(self, x):
# Apply layer normalization and then copy input into query, key, value
hidden_state = self.layer_norm_1(x) # pre layer normalize
# Apply attention with a skip connection
x = x + self.attention(hidden_state)
# Apply feed-forward layer with a skip connection
x = x + self.feed_forward(self.layer_norm_2(x))
return x
encoder_layer = TransformerEncoderLayer(config)
inputs_embeds.shape, encoder_layer(inputs_embeds).size()4) 위치 임베딩
- 절대 위치 표현 (Absolute positional representations)
- 변조된 사인과 코사인 신호로 구성된 정적 패턴 사용
- 데이터가 많이 없을 때 효과적
- 상대 위치 표현 (Relative positional representations)
- 토큰 간의 상대적인 위치를 인코딩
- 상대적인 임베딩은 시퀀스의 어디에서 해당 토큰에 어텐션을 기울이는지에 따라 토큰마다 변경
- 어텐션 메커니즘 자체가 상대 위치를 고려하는 추가적인 항목으로 수정
- DeBERTa와 같은 모델은 이러한 표현 사용
class Embeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.token_embeddings = nn.Embedding(config.vocab_size,
config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings,
config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout()
def forward(self, input_ids):
# Create position IDs for input sequence
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long).unsqueeze(0) # index 입력
# Create token and position embeddings
token_embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
# Combine token and position embeddings
embeddings = token_embeddings + position_embeddings #
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
embedding_layer = Embeddings(config)
class TransformerEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.embeddings = Embeddings(config)
self.layers = nn.ModuleList([TransformerEncoderLayer(config)
for _ in range(config.num_hidden_layers)])
def forward(self, x):
x = self.embeddings(x)
for layer in self.layers:
x = layer(x)
return x
5) 분류 헤드 추가하기
- 헤드에 분석 task 변경해서 사용
class TransformerForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__()
self.encoder = TransformerEncoder(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
def forward(self, x):
x = self.encoder(x)[:, 0, :] # select hidden state of [CLS] token
x = self.dropout(x)
x = self.classifier(x)
return x
config.num_labels = 3
encoder_classifier = TransformerForSequenceClassification(config)
encoder_classifier(inputs.input_ids).size()4. 디코더
디코더 특징 : 두 개의 어텐션 층이 있음
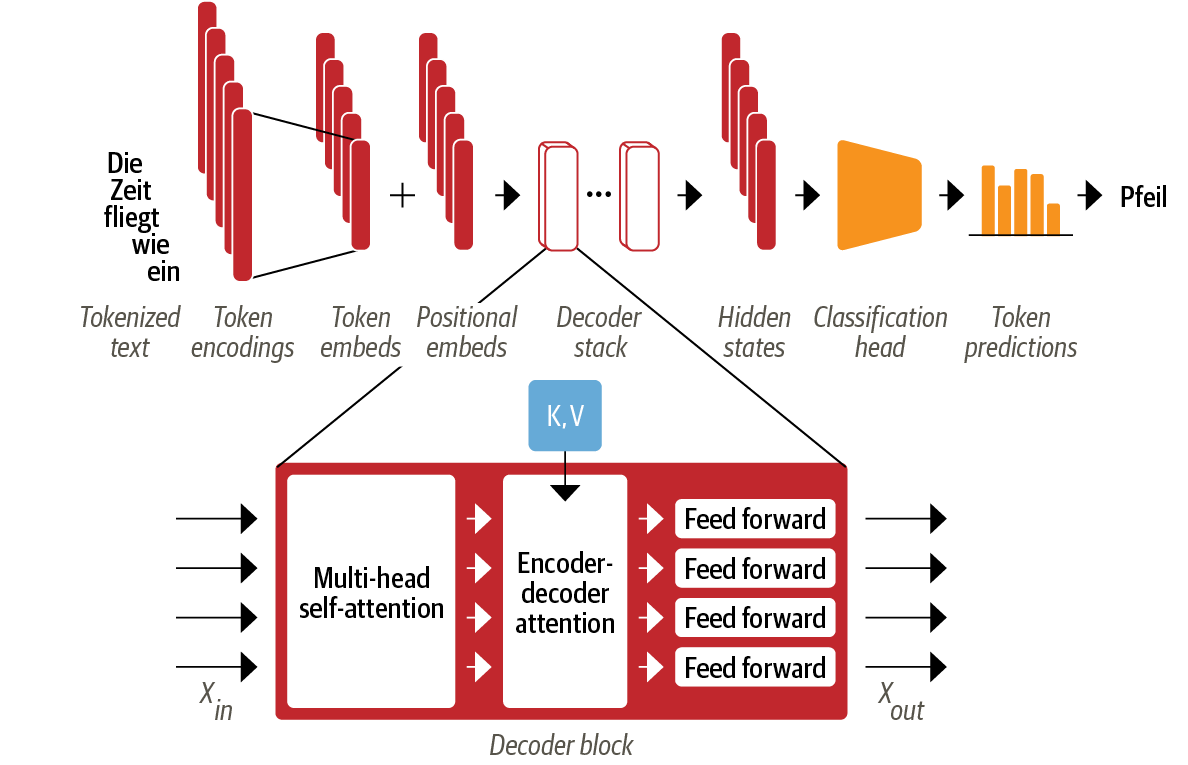
1) 마스크드 멀티 헤드 셀프 어텐션
- 타임스텝마다 지난 출력과 예측한 현재 토큰만 사용하여 토큰 생성
=> 디코더가 훈련하는 동안 단순히 타깃 번역을 복사하는 방식의 부정행위 방지 - 대각선 아래는 1이고 대각선 위는 0(하삼각행렬, lower triangular matrix)인 마스크 행렬을 도입해 구현함
seq_len = inputs.input_ids.size(-1)
mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0)
mask[0]
scores.masked_fill(mask == 0, -float("inf")) # 0을 -inf로 치환 => 0을 -inf(무한대)로 바꾸면 어텐션 헤드가 미래 토큰을 보지 못 함
=> -inf에 소프트맥스 함수를 적용하면 0이 되어 어텐션 가중치가 모두 0이 됨
def scaled_dot_product_attention(query, key, value, mask=None):
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
weights = F.softmax(scores, dim=-1)
return weights.bmm(value) 2) 인코더-디코더 어텐션 층
- 디코더의 중간 표현을 쿼리처럼 사용해서 인코더 스택의 출력 키와 값 벡터에 멀티 헤드 어텐션 수행
- 인코더-디코더는 두 개의 다른 시퀀스에 있는 토큰을 연관짓는 방법 학습
- 디코더는 각 블록에서 인코더의 Key와 value 값을 참조함
5.트랜스포머 모델 계보
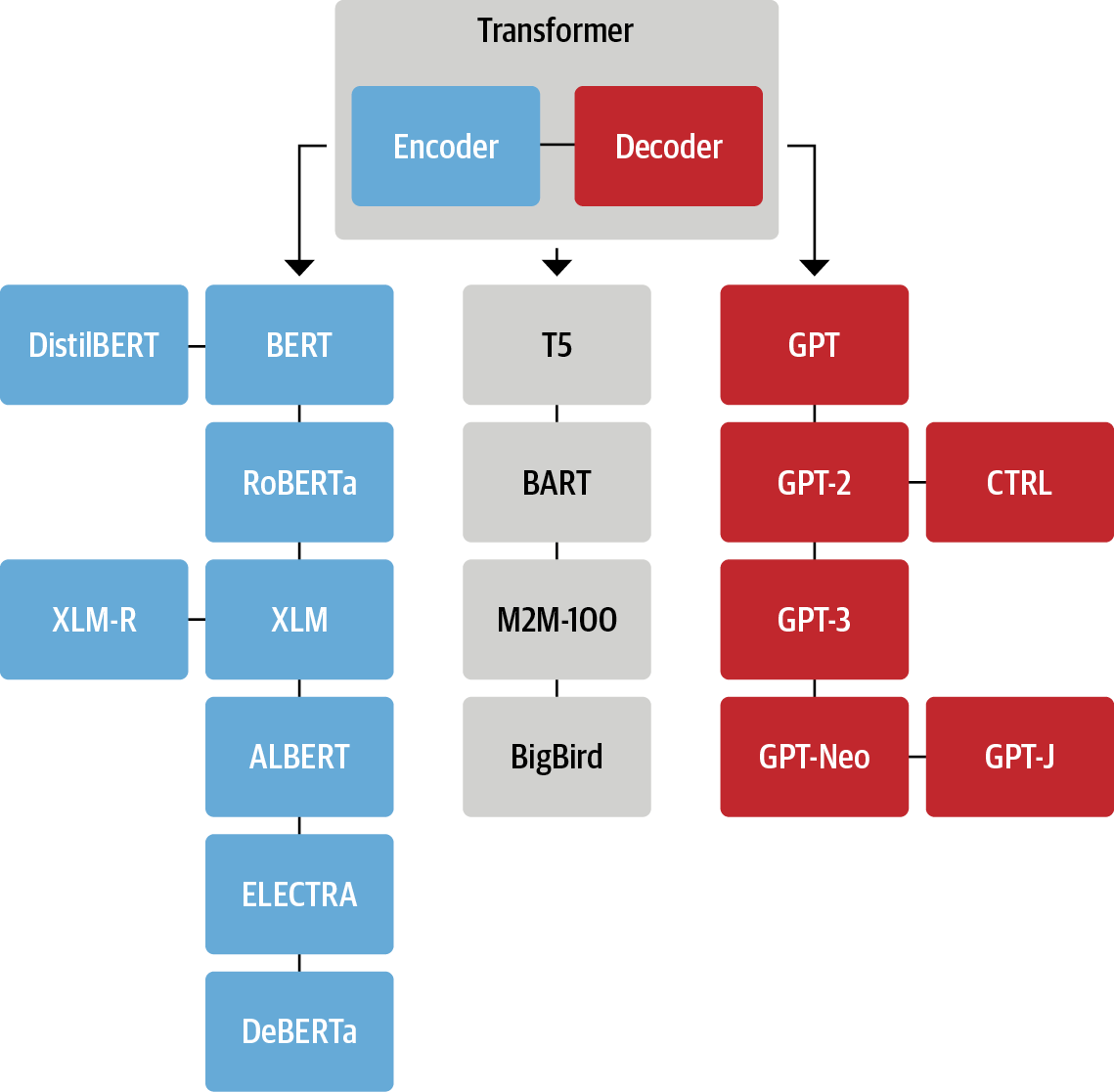
1) 인코더 유형
BERT
특징 : BERT는 두 가지 목표(MLM, NSP)로 사전 훈련됨
- 마스크드 언어 모델 (Masked Language Modeling, MLM) : 텍스트 내의 가려진 토큰을 예측
- 다음 문장 예측 (Next Sentence Prediction, NSP) : 하나의 텍스트 단락이 다른 텍스트 단락을 따를 가능성을 판별
DistilBERT
특징 : 메모리 및 시간 개선한 모델
- 지식 증류(knowledge distillation)라는 기술을 사전 훈련 중에 사용 => BERT의 성능의 97%를 달성, 40% 더 적은 메모리 사용, 속도는 60% 더 빠름
RoBERTa
특징 : Bert 대비 모델 성능 개선
NSP 작업을 제외하고, 더 오랫동안 더 큰 배치로 더 많은 훈련 데이터로 모델 훈련
XLM
특징 : 다국어 모델을 구축하기 위한 사전 훈련 목표로 크로스-언어 언어 모델(XLM)의 작업의 한 방법
- GPT와 유사한 모델의 자기 회귀 언어 모델링과 BERT의 MLM도 포함
- 여러 언어 입력에 대한 확장으로 번역 언어 모델링(Translation Language Modeling, TLM)을 소개
- 몇몇 다국어 자연 언어 이해(NLU) 벤치마크 및 번역 작업에서 벤치마크
XLM-RoBERTa(or XLM-R 모델)
특징 : 다국어 사전 훈련을 대규모로 확장
- Common Crawl 말뭉치를 사용하여 2.5 테라바이트의 텍스트 데이터셋을 생성하고, 이를 기반으로 MLM으로 인코더를 훈련
ALBERT
특징 : 매개변수를 효과적으로 사용
- 토큰 임베딩 차원을 숨겨진 차원과 분리 => 임베딩 차원을 작게 유지 => 어휘가 커질 때 매개변수 절약
- 모든 레이어가 동일한 매개변수 공유 => 효과적인 매개변수 수 감소
- NSP 목표는 문장 순서 예측으로 대체
=> 이 모델은 두 개의 연속된 문장의 순서가 교환되었는지 아닌지를 예측해야 하므로, 이러한 변경 사항을 통해 더 적은 매개변수로 더 큰 모델을 훈련하고 NLU 작업에서 우수한 성능을 달성
ELECTRA
문제상황 : 표준 MLM 사전 훈련 목표의 한 가지 제한은 각 훈련 단계에서 가려진 토큰의 표현만 업데이트되고 다른 입력 토큰은 업데이트되지 않음
특징 : 이 문제를 해결하기 위해 ELECTRA는 두 개의 모델 접근 방식 사용
- 마스크드 언어 모델처럼 작동하며 가려진 토큰 예측
- 두번쨰 모델은 판별자(discriminator)라고 하며, 첫 번째 모델의 출력에서 원래 가려진 토큰을 예측하는 작업 수행
=> 판별자는 각 토큰에 대해 이진 분류를 수행하므로 훈련이 30배 더 효율적임
=> Downstream 작업에서 판별자는 표준 BERT 모델처럼 세밀하게 조정됨
DeBERTa
특징 : 앙상블로 구성된 첫 번째 모델로서 토큰의 절대적 위치 및 상대적 위치 모두를 효과적으로 활용하는 모델
- 각 토큰은 내용을 위한 하나의 벡터와 상대 위치를 위한 다른 하나의 벡터로 표현
=> 토큰의 내용을 상대 위치로부터 분리함으로써 셀프 어텐션 레이어는 인접한 토큰 쌍의 의존성을 더 잘 모델링할 수 있음 - 절대 위치 임베딩이 토큰 디코딩 헤드의 소프트맥스 레이어 바로 앞에 추가됨
2) 디코더 유형
특징 : 시퀀스에서 다음 단어 예측에 뛰어난 성과를 보여 주로 텍스트 생성에 사용됨
GPT
특징 : NLP에서 두 가지 핵심 아이디어(트랜스포머 디코더 아키텍처와 전이 학습)의 결합 결과
- 이전 단어를 기반으로 다음 단어를 예측하는 사전 훈련 모델
- BookCorpus에서 훈련되었으며 분류와 같은 Downstream 작업에서 훌륭한 결과 도출
GPT-2
특징 : 원래 모델에 훈련 데이터 세트를 확장
- 일관된 긴 텍스트 시퀀스 생성 가능
CTRL
특징 : GPT-2와 같은 모델은 입력 시퀀스 (또는 프롬프트)를 이어나갈 수 있음
- Conditional Transformer Language (CTRL) 모델은 시퀀스의 시작 부분에 "제어 토큰"을 추가하여 사용자가 생성된 시퀀스의 스타일 제어 가능
GPT-3
특징 : GPT-2를 100배로 확장하여 1750억 개의 매개변수를 가짐(서로 다른 규모의 언어 모델의 동작을 분석한 결과, 계산량, 데이터셋 크기, 모델 크기, 언어 모델의 성능 간의 관계를 지배하는 간단한 거듭제곱 법칙 발견)
- 현실적인 텍스트 단락을 생성 가능
- 몇 가지 샘플만으로도 손쉬운 학습 능력
GPT-Neo/GPT-J-6B
특징 : EleutherAI라는 연구자 집단이 훈련한 GPT와 유사한 모델로 현재 이 모델들은 전체 1750억 개의 매개변수를 가진 모델의 작은 변형이며, 각각 13억 개, 27억 개 및 60억 개의 매개변수를 가짐
3) 인코더-디코더 유형
T5
특징 : 모든 NLU 및 NLG 작업을 텍스트 대 텍스트 작업으로 변환하여 통합함
- 모든 작업은 시퀀스 대 시퀀스 작업으로 구성되어 인코더-디코더 아키텍처 사용
=> 예) 텍스트 분류 문제의 경우 텍스트는 인코더 입력으로 사용되고 디코더는 레이블을 일반 텍스트로 생성 - T5 아키텍처는 origin 트랜스포머 아키텍처 사용
- 크롤링된 C4 데이터셋을 사용하여 모델은 마스크드 언어 모델링과 SuperGLUE 작업을 텍스트 대 텍스트 작업으로 모두 변환하여 사전 훈련됨
- 110억 개의 매개변수를 가진 가장 큰 모델 존재, 벤치마크에서 순위권 석권
BART
특징 : BART는 BERT와 GPT의 사전 훈련 절차를 인코더-디코더 아키텍처 내에서 결합함
=> 입력 시퀀스는 간단한 마스킹에서 문장 순열, 토큰 삭제 및 문서 회전까지 여러 가지 변형 중 하나를 거침.
=> 수정된 입력은 인코더를 통과하고 디코더는 원래의 텍스트를 재구성함
=> 모델은 NLU 및 NLG 작업에 모두 유연하게 사용될 수 있는 모델
M2M-100
특징 : 일반적으로 하나의 언어 쌍과 번역 방향에 대한 번역 모델이 구축됨
- 100개 언어 중 어느 언어든 번역할 수 있는 최초의 번역 모델임
=> 흔치 않거나 대표되지 않은 언어 간 고품질 번역이 가능함 - 이 모델은 소스 및 대상 언어를 나타내기 위해 접두어 토큰(특수한 [CLS] 토큰과 유사함)을 사용함
BigBird
특징 : 선형적으로 확장 가능한 희소한 어텐션 형태를 사용하여 메모리 문제(최대 문맥 크기) 해결
=> 이로써 대부분의 BERT 모델에서 512 토큰인 문맥을 BigBird에서 4,096 토큰으로 drastics하게 확장가능해짐
- 이는 텍스트 요약과 같이 긴 종속성을 보존해야 하는 경우에 특히 유용함

글 재미있게 봤습니다.