
기존 Hypothesis와 Cost 함수를 코딩해보죠
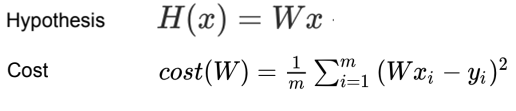
가설함수Hypothesis Function와 비용함수Cost Function은 이렇게 생겼습니당.
이걸 순수 Python으로 작성하면 아래와 같은 모습이 됩니당.
import numpy as np
X = np.array([1, 2, 3])
Y = np.array([1, 2, 3])
# 비용함수
def cost_func(W, X, Y):
c = 0
for i in range(len(X)):
c += (W * X[i] - Y[i]) ** 2 # W * X가 가설함수
return c / len(X)
for feed_W in np.linspace(-3, 5, num=15):
curr_cost = cost_func(feed_W, X, Y)
print("{:6.3f} | {:10.5f}".format(feed_W, curr_cost))결과는 아래와 같습니당.

cost_func을 보면 프로그래밍 언어에 익숙한 사람들이 봐도 좌측에 W, 그리고 우측에 오차의 제곱을 평균화한 결과 값, 현재의 cost 값을 반환하는 것을 확인할 수 있습니당.
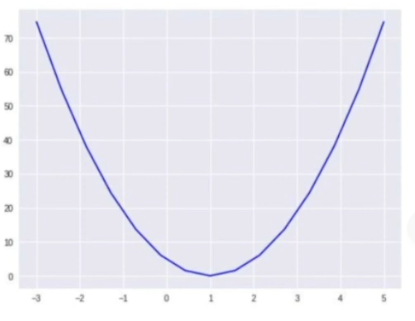
그리고 W 수치가 0에 수렴할 수록 cost 값이 줄어들다, 멀어지면 다시 cost가 늘어나는 것을 확인할 수 있습니당! 그래프로 표현하면 아래와 같습니당.
그전에 다소 어색한 np.linspace
Python에 익숙하지 않은 사람들에게 다소 생소한 문법이 있는데 바로 np.linspace(-3, 5, num=15)죠.
이 의미는 -3부터 5(포함)까지 15번을 나눠서 값을 제공한다는 의미입니당.
실제 좌측 결과 값을 보면 -3부터 해서 5까지 총 15번째로 나눠서 값을 제공하고 있습니당.
그리고 format
{:n.mf}의 의미는 n칸의 여유 공간을 두고 소수점 m자리까지 표현한다는 의미입니당.
TensorFlow로도 구현해 봅니다
TensorFlow로 구현해보면 아래와 같습니당. 크게 다르진 않아용
import numpy as np
import tensorflow as tf
X = np.array([1, 2, 3])
Y = np.array([1, 2, 3])
def cost_func(W, X, Y):
hypothesis = X * W
return tf.reduce_mean(tf.square(hypothesis - Y))
W_values = np.linspace(-3, 5, num=15)
cost_values = []
for feed_W in W_values:
curr_cost = cost_func(feed_W, X, Y)
cost_values.append(curr_cost)
print("{:6.3f} | {:10.5f}".format(feed_W, curr_cost))Gradient Descent를 만들어보죠
선형 회귀Linear Regression는 이렇게 cost 값을 찾지 않고 경사하강법Gradient Descent Method을 통해 천천히 학습을 하면서 최적의 cost 값을 찾는다고 했죠!
TensorFlow로 충분히 구현할 수 있습니다!(그러라고 있는 라이브러리니까 당연하겠죠 ㅎㅎ)
전에 미분을 통해 이를 구할 수 있다 했었고, 수식은 아래와 같습니당!

자 이걸 코드로 옮기면 이렇게 되요!
learning_rate = 0.01
gradient = tf.reduce_mean(tf.multiply(tf.multiply(W, X) - Y, X))
descent = W - tf.multiply(learning_rate, gradient)
W.assign(descent)learning_rate는 기울기를 진행하는 정도의 수치이고, gradient는 cost의 기울기, 그리고 descent는 W와 gradient와 learning_rate를 곱한 수치 만큼 차를 낸 W의 수치입니당!
W.assign을 통해 천천히 cost의 최적값에 가까워지는 방식, 경사하강법Gradient Descent Method를 수행하는 겁니당!
필요한건 다 준비됐으니 이제 써보죠
여지껏 배운걸 토대로 프로그래밍을 짜면 아래와 같은 코드가 나옵니당!
import numpy as np
import tensorflow as tf
tf.random.set_seed(0)
X = np.array([1., 2., 3., 4.])
Y = np.array([1., 3., 5., 7.])
W = tf.Variable(tf.random.normal([1], -100., 100.))
for step in range(300):
hypothesis = W * X
cost = tf.reduce_mean(tf.square(hypothesis - Y))
learning_rate = 0.01
gradient = tf.reduce_mean(tf.multiply(tf.multiply(W, X) - Y, X))
descent = W - tf.multiply(learning_rate, gradient)
W.assign(descent)
if step % 10 == 0:
print("{:5} | {:10.4f} | {:10.6f}".format(step, cost.numpy(), W.numpy()[0]))tf.random.set_seed(0)는 코드를 다시 컴파일하고 수행했을 때도 동일한 결과를 내기 위해 기준점을 따로 정해 놓는다고 보시면 됩니당.
tf.random.normal을 보시면 첫번째 매개변수는 차원을 보시면 되고, 여기서 [1]은 1차원의 1개의 변수로 보시면 됩니당(-100 ~ 100)
gradient와 descent를 통해 learning_rate를 곱한 만큼 점점 W를 변화시켜 나가는 것을 보실 수 있습니당
그리고 총 300회를 진행하고 10번째 단위로 결과 값을 표시한다고 보시면 됩니당!

처음에 cost(가운데) 값은 매우 큰 수치였다가, 점점 내려가면서 특정 수치에 도달하는 것을 확인할 수 있습니당!
후기
꽤나 오래 걸렸습니당 ㅠ 게으른건 아직 극복하기 어렵습니당
10분짜리 강의도 블로그에 정리하다보면 1~2시간이 훌쩍 넘겨버리니 아직 의욕이 부족한거 같습니당!
포기하지 않고 꾸준히 나아가겠습니돠!
