환경 세팅
1. anaconda 설치
2. 가상환경 생성(python 버전 설정)
conda create -n <환경명> python=<버전(ex:3.8)> #환경명 :MS 파이썬 버전 : 3.83. 가상환경 실행
conda activate <환경명>4. 가상환경에 jupyter notebook 설치
pip install jupyter notebook- jupyter notebook 이 설치 될 때 ipykernel이 자동으로 받아지지만 설치 되지 않았다면 따로 install 해줘야함
pip install ipykernel5. 가상환경에 kernel 연결
python -m ipykernel install -user -name <환경명> -display-name <환경명>IPykernel은 주피터 노트북과 주피터 인터랙티브 컴퓨팅 프레임워크를 위한 파이썬 커널이다. 이 커널을 사용하면 노트북 환경에서 파이썬 코드를 실행하고 상호작용할 수 있다.- IPykernel은 사용자 인터페이스(주피터 노트북 또는 주피터랩 등)와 파이썬 커널 간의 통신을 담당함.
통계기반 데이터 분석 수업 전체적인 흐름
- 통계 개념 간단 소개
- 데이터 파트
- 가설 감정
- 상관 분석
- 분포 모형
- 비모수적 방법
- 시계열 분석
- 다변량 분석
통계 개념 소개
- 통계에서 가장 기본적인 개념은 데이터
- 데이터를 이해하기 위해서는 분포와 패턴을 파악할 필요가 있음
- 통계에서 가장 중요한 개념은 가설 검정과 추론
통계 기반 데이터 분석 적용하기 위한 방법으로 무엇이 있는가?
데이터 수집 전처리
- 데이터의 품질을 확인하고 결측치, 이상치, 중복 등의 문제를 처리함.
- 데이터를 적절한 형식으로 변환하고 필요한 변수를 추출하는 관정이 필요
기술통계 분석
- 데이터의 특성과 패턴을 파악하기 위해 기술 통계 분석을 수행함.
- 평균, 분산, 상관관계 등의 통계량을 계산하여 데이터의 분포와 관계를 이해함.
추론 통계 분석
- 데이터로부터 일반적인 패턴이나 관계를 추론하기 위해 추론 통계분석 수행
- 가설검정, 신뢰구간, 회귀 분석등의 방법을 사용하여 통계적으로 유의한 결과를 도출
데이터 시각화
- 데이터를 시각적으로 표현하여 인사이트를 도출하고 결과를 전달하는 데 도움이 되는 시각화 기술 필요
- 히스토그램, 선, 그래프, 산점도 등 다양한 시각화 도구를 사용하여 데이터의 패턴과 관계를 시각적으로 확인
예측 모델링
- 통계 기반 데이터분석은 예측 모델링에도 적용됨
- 회귀분석, 시계열 분석, 분류 모델등을 활용하여 미래의 값을 예측하고 패턴을 분석
소프트웨어 및 프로그래밍 기술
- 데이터 분석을 위해서는 통계 소프트웨어나 프로그래밍 언어를 사용해야함
- R, Python과 같은 통계 및 데이터 분석에 특화된 언어를 사용
이외에도 통계 기반 데이터 분석에는 표본 추출, 분포 가정 등 다양한 기법과 개념이 포함 될 수 있음
AI 통계를 이용한 서비스 소개
마케팅 분석 및 예측
- 기존의 통계 분석 방법에 AI 기술을 접목하여 더욱 정확한 분석 결과를 제공
금융 분석
- 주식 시장 예측, 부동산 시장 분석, 투자 추천 등 다양한 분야에서 활용
의료 진단
- 의료 데이터 기반으로 AI 알고리즘을 활용하여 질병 진단과 예측을 수행
교육
- 학습자의 학습 데이터를 기반으로 개인 맞춤형 교육 컨텐츠를 제공
공공 서비스
- 예를 들어 도시 계획과 교통 체계를 개선하기 위해 도시 데이터를 기반으로 AI알고리즘을 활용한 서비스가 있음
통계 기반 데이터 분석 Basic - data
데이터의 개념
- 데이터는 정보의 집합으로 현실세계에서 측정된/관찰된 값 또는 사실들의 모임
- 가장 일반적인 분류 방법은 데이터 형태에 따라 구분됨
데이터의 종류
연속형 데이터
- 연속적인 값으로 이루어진 데이터 (온도, 길이, 시간 등이 대표적임)
- 수치형 데이터의 하나로서 측정된 값이 정확한 수치를 가지며 연속적인 범위 내에서 무한히 변화 할 수 있음.
주의할 점
- 정확한 측정과 적절한 분포 가정이 필요함
- 연속형 데이터는 무한히 많은 값이 있기 때문에 표본 데이터로부터 모집단의 특성을 추정할 때 적절한 범위를 정해야함
lab01
필요한 libraray install
!pip install pandas
!pip install matplotlib- 실습할 dataset load :
Black Friday Sales
히스토그램
- 직사각형의 막대 그래프로 나타낸 것
- 자료의 분포 형태를 쉽게 파악 할 수 있어서 데이터 분석에서 많이 사용됨
import pandas as pd
import matplotlib.pyplot as plt
# 데이터셋 불러오기
data= pd.read_csv('./data/BlackFriday.csv')
# User_ID별 구매 총 금액 계산
user_total_spent=data.groupby('User_ID')['Purchase'].sum()
print(user_total_spent)User_ID
1000001 334093
1000002 810472
1000003 341635
1000004 206468
1000005 821001
...
Name: Purchase, Length: 5891, dtype: int64
matplotlib을 이용해 시각화하기
plt.hist(user_total_spent,bins=50)
plt.title('Histogram of Total Purchase Amount by User')
plt.xlabel('Total Purchase Amount')
plt.ylabel('Frequency')
plt.show()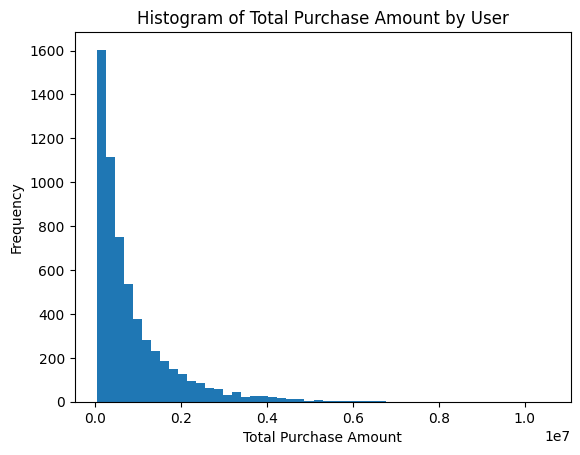
밀도 그래프
- 구매 금액의 분포를 더 부드럽게 나타낸 그래프
- 선이 높을 수록 분포도가 높다고 할 수 있음
!pip install scipy# 밀도 그래프 시각화
plt.figure()
user_total_spent.plot.kde()
plt.title('Density plot of Total Amount by User')
plt.xlabel('Total Purchase Amount')
plt.show()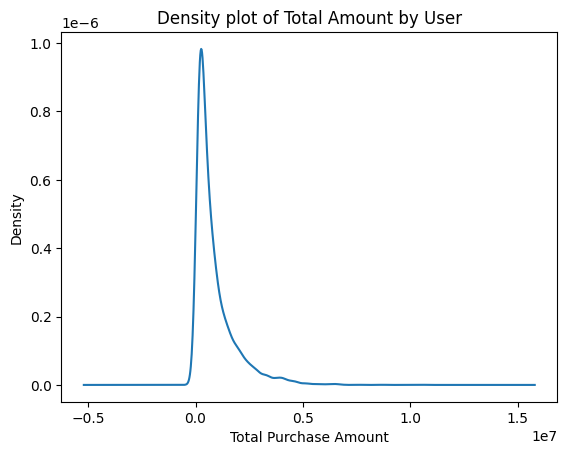
확률밀도함수(PDF,Probabilty Density Function)
- 확률의 값이 구간 내에서 어떻게 분포하는지를 나타냄
- 이함수를 이용하여 특정값이 나올 확률, 혹은 특정값의 범위내에서 값이 나올 확률 등을 계산 할 수 있음
lab02
library install
!pip install seaborn
!pip install numpy데이터 시각화 튜토리얼
https://seaborn.pydata.org/tutorial.html
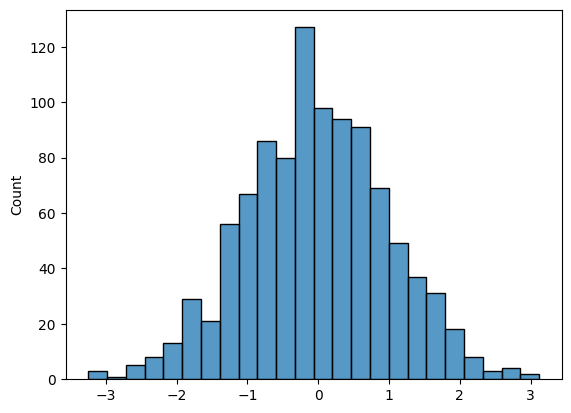
정규분포
- 정규분포를 따르는 데이터를 다룰 때는 평균과 분산을 중심으로 분포를 파악
- 시각화된 그래프를 보면 데이터가 대략적으로 평균을 중심으로 좌우대칭인 분포를 따르게 됨
- 정규분포에서는 평균과 표준편차가 매우 중요함
- 대부분의 자연현상에서 나타나는 데이터 분포와 비슷(인구의 키나 체중 등)
data=np.random.normal(loc=0,scale=1,size=1000)
# 데이터 분포 시각화
sns.histplot(data)
plt.show()
# 데이터 통계 지표 계산
mean= np. mean(data) #mean() : 평균
std=np.std(data) #std() : 표준편차
print('평균 : ', mean)
print('std : ',std)
평균 : -0.028850057890706715
std : 1.0073938448282973
연속형 데이터 분석 시 고려해야 할 사항
lab03
중심 경향성
- 대표적으로 평균(mean), 중앙값 (median), 최빈값(mode)을 계산 할 때 데이터의 분포가 비대칭적이면 평균보다 중앙값이나 최빈값이 더 적합한 경우가 있음
평균
- 데이터가 대략적으로 어디에 분포해 있는지 알 수 있음
중앙값
- 데이터를 크기 순서대로 정렬했을 때 가운데 위치한 값, 극단적으로 크거나 작은 값들이 있는 경우 평균보다 대표성이 높을 수 있음
최빈값
- 가장 자주 등장하는 값, 데이터의 분포 형태와 관련이 있으므로 데이터가 대표성을 가질 수 있도록 중심 경향성을 나타내는 지표로 활용됨
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
data=np.random.normal(loc=0,scale=1,size=10000)
# 중심 경향성 계산
# 평균(mean),중앙값(median),최빈값(mode)
mean = np.mean(data)
median=np.median(data)
mode=np.round(np.mean(data))
print(mean,median,mode)0.008870126744707763 -0.0007172149572973895 0.0
정규분포그래프 시각화
# 분포 시각화
fig, ax = plt.subplots()
ax.hist(data, bins=50)
ax.axvline(mean, color='red', linestyle='dashed', linewidth=2)
ax.axvline(median, color='green', linestyle='dashed', linewidth=2)
ax.axvline(mode, color='purple', linestyle='dashed', linewidth=2)
ax.legend(['Mean: {:.2f}'.format(mean), 'Median: {:.2f}'.format(median), 'Mode: {}'.format(mode)])
ax.set_xlabel('Data Values')
ax.set_ylabel('Frequency')
ax.set_title('Data Distribution')
plt.show()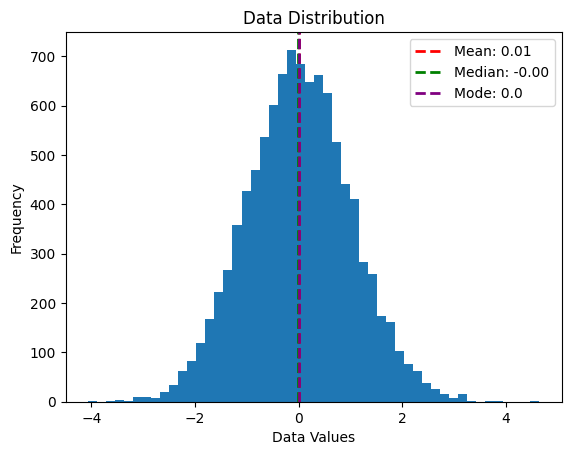
- x축은 데이터 값, y축은 빈도수를 나타냄
lab04
산포도
- 데이터의 분산 정도를 나타내는 그래프, 대표적으로 분산(variance), 표준편차(standard deviation), 범위(range), 사분위간범위(interquartile range) 등을 계산 할 수 있음
- 산포도가 작으면 데이터 값들이 모여 있어 분포가 집중되어 있다는 것을 의미, 반대로 크면 데이터 값들이 흩어져 있어 넓게 펴져 있다는 것을 의미함
import numpy as np
import matplotlib.pyplot as plt
# 두 변수 간의 상관관계 설정
np.random.seed(0)
x=np.random.normal(loc=0,scale=1,size=100)
y=x+np.random.normal(loc=0,scale=0.5,size=100)
# 산포도 그리기
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_title('Scatter Plot')
plt.show()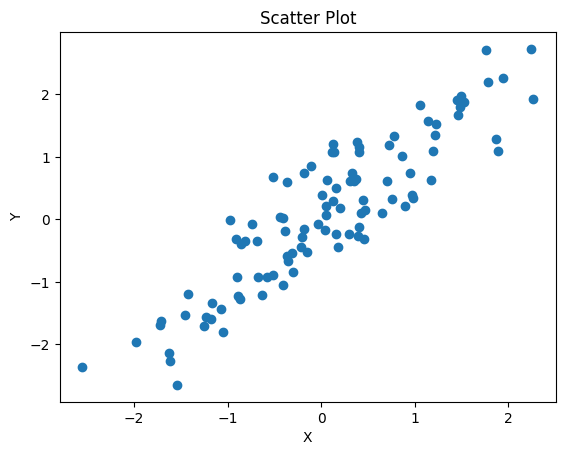
lab05
이상치
- 이상치는 대부분의 데이터가 모여 있는 부분에서 벗어나 극단적인 값으로 나타나는 데이터를 의미함
- 연속형 데이터에서 분석결과를 왜곡 할 수 있으므로 주의가 필요함
- 이상치를 식별하기 위해서는 데이터 분포를 파악하고 통계지표를 계산한 후 분석 결과를 검토함
- 이상치 탐지 방법으로는 z-score나 IQR(Interquartile Range)등을 이용함
Box Plot
- 상자 부분의 길이와 위치를 통해 데이터의 분산 정도를 파악 할 수 있음
- 상자의 길이가 짧고 하단의 수염과 상단의 수염이 길게 나타나면 데이터가 중앙 값을 중심으로 분산되어 있고 극단값이 존재하지 않는 것을 나타냄
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
data=np.concatenate([np.random.normal(0,1,900),
np.random.normal(8,2,100),
np.random.normal(-4,2,100)])
# 상자 그림(Box Plot) 시각화
fig, ax = plt.subplots()
ax.boxplot(data)
ax.set_xlabel('Data')
ax.set_ylabel('Values')
ax.set_title('Box Plot')
plt.show()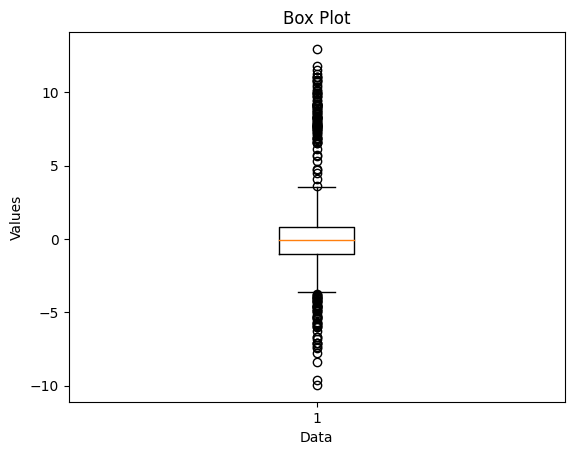
박스
- 박스의 가운데에 수평선이 존재하는데, 이는 데이터의 중앙값(median)을 나타냄
- 중앙값은 데이터를 작은 값부터 큰 값으로 정렬했을 때 중간에 위치한 값
- 박스는 데이터의 중간 50%를 나타냄
- 박스의 하단 경계는 25번째 백분위수(1사분위수, Q1)를 나타내며, 상단 경계는 75번째 백분위수(3사분위수, Q3)를 나타내는데, 이는 데이터를 작은 값부터 큰 값으로 정렬했을 때 25%와 75% 지점에 해당하는 값
수염
- 박스 플롯에서 수염은 데이터의 전체 분포를 나타냄
- 일반적으로 수염은 박스 경계 범위에서 1.5배의 사분범위(IQR, Interquartile Range)만큼 확장된 길이로 그려짐
- 수염의 끝은 이상치를 나타내며, 이상치는 일반적인 데이터 범위를 벗어난 값을 의미
- 이상치는 표시되는 경우에만 별도로 점 또는 표식으로 표시
이상치
- 박스 플롯에서 이상치는 일반적인 데이터 값과는 동떨어진 값
- 이상치는 데이터 분포의 극단적인 값을 나타낼 수 있으며, 특이한 사례 또는 오류로 간주
lab06
히스토그램
- 도수분포표를 그래프로 나타낸 것으로, 데이터의 빈도를 막대그래프로 나타냄
- X축은 데이터의 범위를, y축은 해당 범위 안에서의 빈도수를 나타냄
# 히스토그램(Histogram) 시각화
fig, ax = plt.subplots()
ax.hist(data, bins=50)
ax.set_xlabel('Data')
ax.set_ylabel('Frequency')
ax.set_title('Histogram')
plt.show()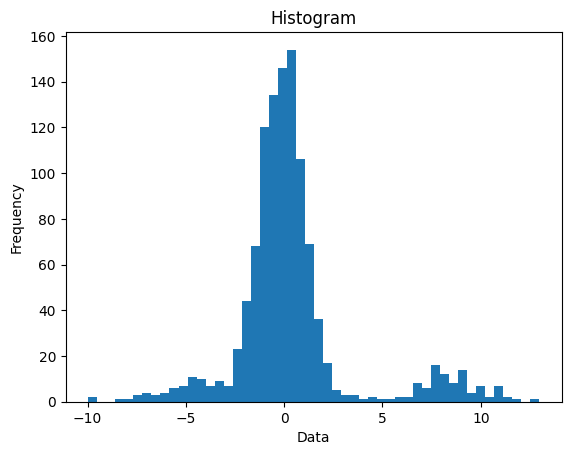
상관관계
- 두 변수 사이의 관계를 파악할 때 유용한 지표, 대표적으로 상관계수(correlation coefficient)를 이용하여 파악함
- 두 변수 간의 관련성을 -1부터 1 사이의 값으로 나타내며 값이 1에 가까울 수록 두 변수는 양의 상관관계이며 반대로 -1에 가까울수록 음의 상관관계임
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
np.random.seed(0)
x=np.random.normal(loc=0,scale=1,size=100)
y=2*x+np.random.normal(loc=0,scale=1,size=100)
# 2*x 해준 이유?
# 그래프가 이쁘게 나와서
# 선점도 시각화
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_title('Scatter Plot')
plt.show()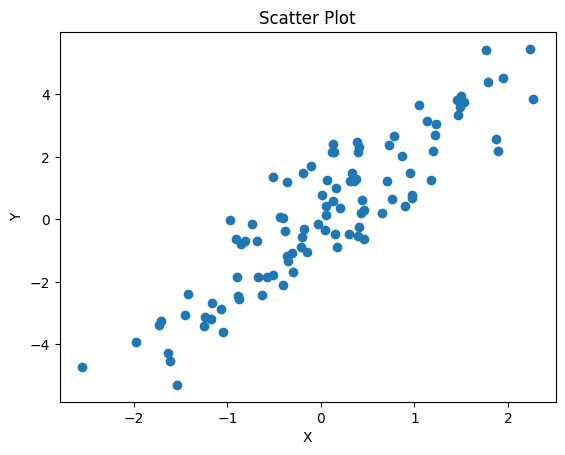
일반적인 모델링을 할 때 다음과 같은 절차로 수행
모델 튜닝
- 모델의 성능을 향상시키기 위해 조정
모델 예측
- 모델을 사용하여 예측
모델링
- 데이터 분석의 핵심 기술 중 하나로 다양한 분야에서 활용됨
