가설 검정
- 어떤 가설이 옳은지 틀렸는지를 검증하는 과정
- 일반적으로 데이터를 수집하고 분석하여 추론하는 과정에서 사용
가설 검정 필요성
- 정확한 결정을 내리기 위해 필요한 과정
- 우리가 가지고 있는 주장이나 가설이 진실에 근접한지, 혹은 틀린 것인지를 판단할 수 있음
귀무 가설
- 검증하고자 하는 가설로 일반적인 상황을 나타내는 가설
- "검정하려는 주장이 틀렸다" 는 것을 입증하기 위해 세우는 가설
- 어떠한 인과 관계나 차이가 존재하지 않는다는 가정을 말함
- 귀무 가설은 연구자가 반드시 입증해야 할 가설로 이를 기각하는 것이 주요 목표
ex) "약을 복용한 환자의 회복력이 개선되었다" 는 주장을 검정하기 위해 귀무 가설은 "약을 복용한 환자와 복용하지 않은 환자의 회복력에 차이가 없다"로 세울 수 있음 - 귀무 가설을 기각하기 위해 사용되는
유의수준은 보통 0.05 또는 0.01로 설정됨
(p.121)
대립 가설
- 귀무 가설의 반대되는 가설, 연구자가 입증하고자 하는 가설
- 실험 결과에 영향을 주는 요인이 있다는 가정, 귀무 가설이 기각 될 때 채택 됨
- 대립 가설은 양측성과 단측성으로 구분 됨
t-검정
- 모집단의 표준 편차가 알려지지 않은 경우 사용됨
- 표본의 표준 편차를 이용하여 검정을 수행함
- t-검정은 표본의 크기가 작을 때 더우 유용함, 일반적으로 모집단의 분산이나 표준편차를 추정할 수 없는 경우에 사용됨
z-검정
- 모집단의 표준 편차가 알려져 있을 경우 사용됨
검정통계량
귀무 가설 간단한 실습
lab08
귀무 가설 설정
"타이타닉 호에 탑승한 남성 승객들과 여성 승객들의 생존율이 같다"
import pandas as pd
import scipy as stats
# 데이터 가져오기
titanic_df=pd.read_csv('../data/Titanic_data.csv')
# 남성 승객과 여성 승객의 생존 여부에 따른 데이터 프레임 생성
male_df=titanic_df[titanic_df['Sex']=='male']
female_df=titanic_df[titanic_df['Sex']=='female']
# .mean()
male_survival_rate=male_df['Survived'].mean()
female_survival_rate=female_df['Survived'].mean()
print(male_survival_rate)
print(female_survival_rate)
# t-검정
t,p=stats.ttest_ind(male_df['Survived'],female_df['Survived'])
alpth=0.05
if p<alpth:
print(f'p-value : {p:.4f}, 귀무 가설 기각')
else:
print(f'p-value : {p:.4f}, 귀무 가설 채택')
출력
0.18890814558058924
0.7420382165605095
p-value : 0.0000, 귀무 가설 기각
- t-검정을 수행하였고, 유의 수준(alpth)을 0.05로 설정
- p-value가 0.00으로 귀무 가설이 기각됨, 즉 남성 승객과 여성 승객의 생존 여부가 통계적으로 유의하게 차이가 있음을 의미
lab09
chi-squre 검정
import pandas as pd
import numpy as np
from scipy.stats import chi2_contingency
# 가상 데이터 생성
data={
'Gender' : ['M','M','M','M','F','F','F','F'],
'Smoker' : ['Yes','No','No','Yes','Yes','No','No','Yes'],
'Count' : [20,80,40,60,40,160,80,120]
}
df=pd.DataFrame(data)
print(df)
# 데이터 프레임을 이용한 분할표 생성
table=pd.pivot_table(df,values='Count',index='Gender',columns='Smoker')
print(table)
# chi2_contingency
stat,p,dof,expected=chi2_contingency(table)
alpha=0.05
if p<alpha:
print(f'p-value:{p:.4f}, 귀무가설 기각')
else :
print(f'p-value:{p:.4f}, 귀무가설 채택')출력
Gender Smoker Count
0 M Yes 20
1 M No 80
2 M No 40
3 M Yes 60
4 F Yes 40
5 F No 160
6 F No 80
7 F Yes 120
Smoker No Yes
Gender
F 120 80
M 60 40
p-value:1.0000, 귀무가설 채택lab10
일원 분산 분석(one-way ANOVA)
- 한 개의 독립 변수를 가지고 이 변수의 값에 따라 종속 변수의 평균 차이가 있는지 검정하는 방법
- 종속 변수는 수치형 데이터이며 정규 분포를 따르는 것이 좋음
- 여러 개의 그룹을 비교할 때 유용한 방법
F-통계량을 사용하여 검정, 각 그룹의 평균값들의 분산과 그룹 내 오차의 분산 비율로 계산됨
import pandas as pd
import numpy as np
# 가상의 데이터 셋 생성
np.random.seed(1)
data={
'A':np.random.randint(1,6,10),
'B':np.random.randint(1,6,10),
'C':np.random.randint(1,6,10),
}
df=pd.DataFrame(data)
print(df)
# 일원 분산 분석 수행
from scipy.stats import f_oneway
f_stat,p_val=f_oneway(df['A'],df['B'],df['C'])
print('One-way ANOVA')
print('=============')
print(f'F-statistic: {f_stat:.4f}')
print(f'p-value: {p_val:.4f}')
alpha=0.05
if p_val<alpha:
print("귀무 가설 기각")
else:
print("귀무 가설 채택")출력
A B C
0 4 2 5
1 5 3 2
2 1 5 2
3 2 3 1
4 4 5 2
5 1 4 2
6 1 5 2
7 2 3 2
8 5 5 1
9 5 3 5
One-way ANOVA
=============
F-statistic: 2.2966
p-value: 0.1199
귀무 가설 채택- F-통계량은 2.2966이고 이에 해당하는 p-value는 0.1199이다
- 일원 분산 분석에서는 귀무 가설이 "모든 그룹의 평균이 같다" 는 것임
- p-vale가 유의 수준보다 작으면 귀무 가설을 기각하고 그렇지 않으면 귀무 가설을 채택함
- 즉, 세 그룹 간에는 유의미한 차이가 없음
lab11
이원 분산 분석(Two-way ANOVA)
- 두 가지 요인에 따른 평균 값의 차이를 비교하는 방법
- 각 요인은 두 개 이상의 수준을 가질 수 있으며 요인 간 상호작용 여부도 검정할 수 있음
- 각각의 요인과 상호작요의 효과를 검정하기 위해 F-검정을 사용
F-검정은 분산 분석을 실시한 후 각 집단 간 평균 차이가 크게 나탔는지 여부를 검정
이원 분산 분석이 필요한 이유
다중 변수 간의 영향 파악
- 두 개 이상의 변수가 종속 변수에 영향을 미칠 때 각 변수의 영향을 분리하여 파악함
상호작용 효과 파악
- 특정 광고가 성별과 연령에 따라 상품 구매 행동에 미치는 영향을 분석 할 때 성별과 연령 간의 상호작용 효과를 파악하여 성별과 연령별로 광고 전략을 조정할 수 있음
분석 정확도 향상
- 두 개 이상의 변수가 종속 변수에 영향을 미치는 경우 각 변수의 영향을 분리하여 분석함으로써 분석의 정확도를 높일 수 있음
import pandas as pd
import seaborn as sns
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# 데이터 불러오기
titanic_df=pd.read_csv('../data/Titanic_data.csv')
# 이원 분산 분석 모델 생성
model=ols('Survived~C(Sex)+C(Pclass)+C(Sex):C(Pclass)',titanic_df).fit()
# 분산 분석 실행
annova_results =anova_lm(model,typ=2)
#시각화
sns.catplot(x='Sex',y='Survived',hue='Pclass',data=titanic_df,kind='bar')출력
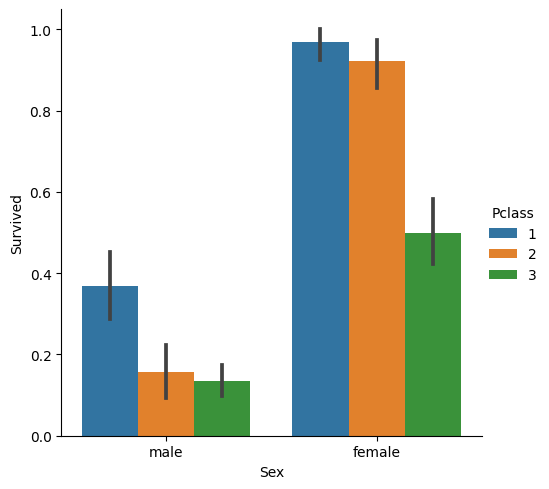
- 성별을 X축으로 생존 여부를 y축으로 객실 클래스(Pclass)를 색상(hue)으로 구분하여 각 그룹의 평균값을 막대 그래프로 시각화함
교호작용 효과
- 두 개 이상의 독립 변수가 종속 변수에 영향을 미칠 때, 이들 독립 변수들간의 상호작용이 종속 변수에 영향을 미치는 것
- 하나의 변수만 고려하는 것이 아니라 여러 변수 간의 조합이 종속 변수에 영향을 미침
ex) 성별과 교육 수준이라는 두가지 독립 변수가 있는 경우 교호 작용 효과를 고려하지 않으면 성별과 교육 수준이 각각 종속 변수에 영향을 미친다고 해석 할 수 있음. 그러나 실제로는 성별과 교육 수준이 조합된 경우에만 종속 변수에 영향을 미치는 경우가 있을 수 있음
- 따라서 교호작용 효과를 고려하지 않으면 결과가 왜곡됨 - 교호작용 효과를 분석하는 방법으로는 일반적으로 상호작용 항을 추가하는 것이 있음, 상호작용 항은 두 독립 변수의 곱으로 나타낼 수 있으며 회귀 분석 등의 통계 분석에서 자주 사용됨
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 셋 load
titanic=sns.load_dataset('titanic')
print(titanic)
# pointplot 생성
sns.pointplot(x='sex',y='survived',hue='pclass',data=titanic)
plt.legend(title='Pclass',loc='best')
plt.title('Survived Rate by Sex and Pclass')출력
survived pclass sex age sibsp parch fare embarked class \
0 0 3 male 22.0 1 0 7.2500 S Third
1 1 1 female 38.0 1 0 71.2833 C First
2 1 3 female 26.0 0 0 7.9250 S Third
3 1 1 female 35.0 1 0 53.1000 S First
4 0 3 male 35.0 0 0 8.0500 S Third
.. ... ... ... ... ... ... ... ... ...
886 0 2 male 27.0 0 0 13.0000 S Second
887 1 1 female 19.0 0 0 30.0000 S First
888 0 3 female NaN 1 2 23.4500 S Third
889 1 1 male 26.0 0 0 30.0000 C First
890 0 3 male 32.0 0 0 7.7500 Q Third
who adult_male deck embark_town alive alone
0 man True NaN Southampton no False
1 woman False C Cherbourg yes False
2 woman False NaN Southampton yes True
3 woman False C Southampton yes False
4 man True NaN Southampton no True
.. ... ... ... ... ... ...
886 man True NaN Southampton no True
887 woman False B Southampton yes True
888 woman False NaN Southampton no False
889 man True C Cherbourg yes True
890 man True NaN Queenstown no True
[891 rows x 15 columns]Text(0.5, 1.0, 'Survived Rate by Sex and Pclass')
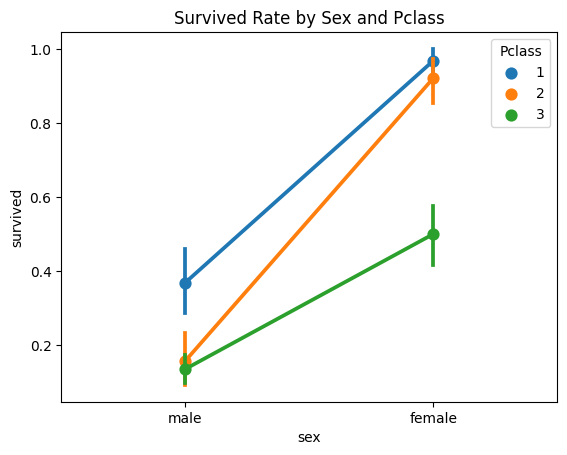
- 여성이 남성보다 생존율이 높다는 것과 1등급 객실에 탑승한 여성의 생존율이 가장 높음
