Pytorch를 간단히 다루어본 적이 있는데, 앞으로의 연구에 익숙하게 활용하기 위해 Pytorch 내용을 정리해보려 한다.
대부분의 내용은 유튜브의 '모두를 위한 딥러닝 시즌2'를 참고하였다.
기본적인 딥러닝 내용은 어느 정도 알고있다고 가정하고, PyTorch 실습 내용 위주로 정리해두었다.
간단한 설명이 포함된 실습 자료는 다음 Github를 참조하자.
1. Multivariable Linear Regression
이제까지 살펴본 Simple Linear Regression은 하나의 정보로부터 하나의 예측을 진행하는 간단한 형태의 Linear Regression이었다. 하지만 실제로는 여러 정보가 주어지는, 즉 x_train이 여러 개의 변수인 경우가 많다.
1) Data Definition
이제 x_train은 2차원 행렬 형태를 갖는다.
예를 들어,
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])위와 같은 형태이다. x_train은 5 × 3 형태의 tensor, y_train은 5 by 1 형태의 tensor이다.
2) Hypothesis Function
Hypothesis Function은 예시의 경우 다음과 같이 나타낼 수 있을 것이다.
설명변수가 3개이므로 x_train의 열이 3개가 되고, 위와 같이 각각의 설명변수를 으로 나타낼 수 있다.
하지만, 설명변수가 매우 많아진다면, 표현할 때도 복잡하고, 계산할 때도 매우 복잡해진다.
따라서 행렬을 이용하여 다음과 같이 나타낸다.
예시의 경우 는 1 × 3, 는 3 × 5, 는 1 × 5이다.
이론적으로 구할 때에는 일반적으로 열벡터를 사용하기 때문에 위와 같은 형태를 갖지만, 코딩에서는 일반적으로 Weight의 shape을 ('입력 차원', '출력 차원')으로 구현함에 유의하자.
따라서 'x_train × W' 와 같이 곱해줄 것이고, 크기도 모두 (행, 열이)반대일 것이다.
코딩 시 간단히 matmul 함수를 통해 다음과 같이 표현할 수 있다.
hypothesis = x_train.matmul(W) + bmatmul 함수를 사용하면 더 간결하고, x의 길이가 바뀌어도 코드를 바꿀 필요가 없어지며, 계산 속도도 더 빠르다.
이후 Cost Function, Gradient Descent 과정은 Simple Linear Regression에서와 같다.
결론적으로 학습 데이터와 모델 정의 분만 바뀌는데, 이는 곧 PyTorch의 확장성을 보여준다.
3) Full Code with torch.optim
전체 코드와 결과는 다음과 같다.
# 데이터
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 모델 초기화
W = torch.zeros((3, 1), requires_grad=True)
b = torch.zeros(1, requires_grad_True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1e-5)
nb_epochs = 20
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = x_train.matmul(W) + b
# cost 계산
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('Epoch {:4d}/{} hypothesis: {} Cost: {:.6f}'.format(
epoch, nb_epochs, hypothesis.squeeze().detach(),
cost.item()
))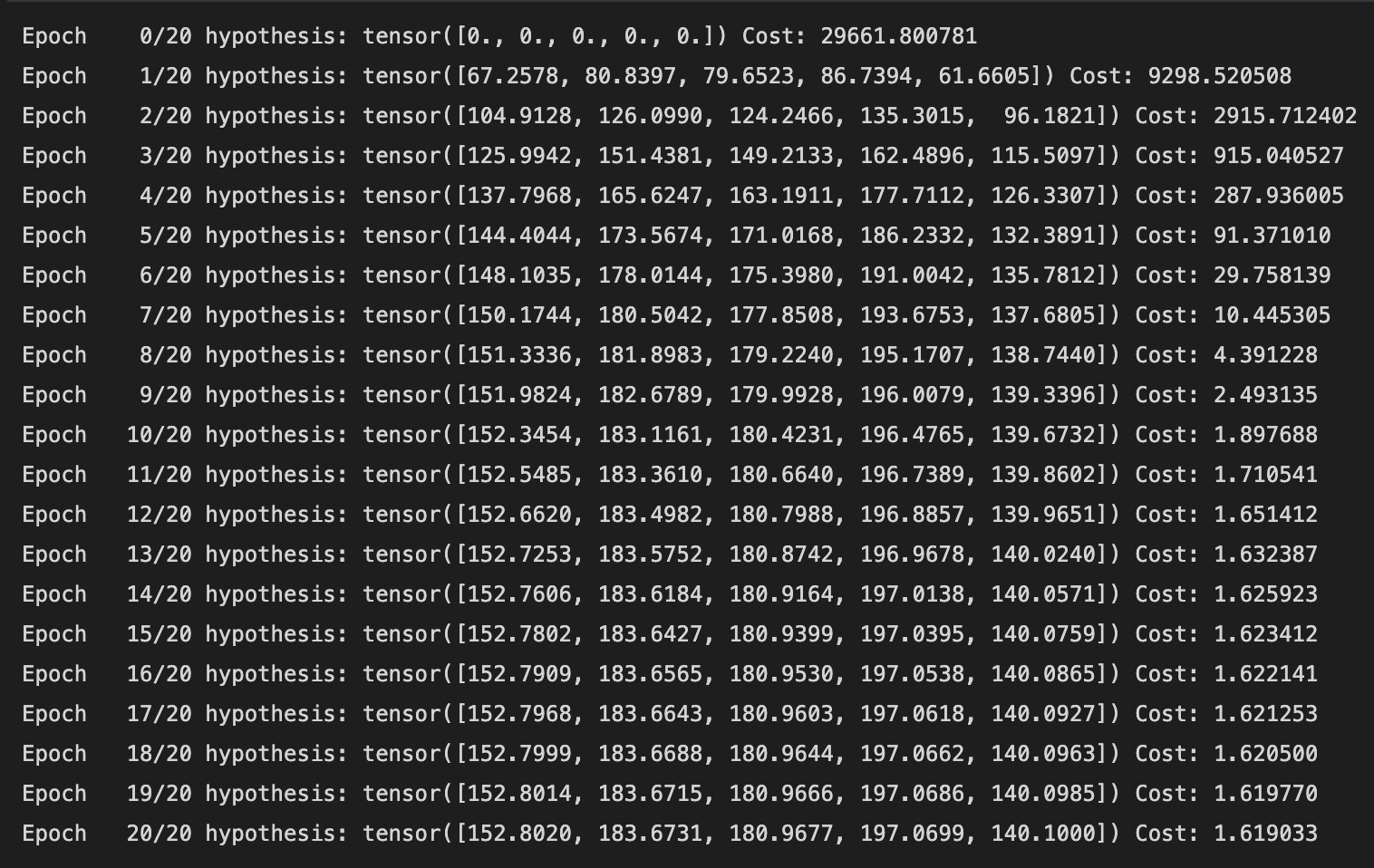
Cost가 점점 작아지고, H(x) 값은 y_train 값에 가까워짐을 볼 수 있다.
4) nn.Module
위와 같이 모델 초기화를 직접 해줄 수도 있지만, 복잡한 task에서 Weight과 Bias를 일일이 선언해 주는 일이 귀찮을 수 있다. 따라서 PyTorch에서는 nn.Module이라는 모듈을 제공한다.
다음 두 코드를 비교해보자.
<직접 모델 초기화>
# 모델 초기화
W = torch.zeros((3, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# H(x) 계산
hypothesis = x_train.matmul(W) + b<nn.Module>
import torch.nn as nn
class MultivariateLinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(3, 1) # 입력차원: 3, 출력차원: 1
def forward(self, x): # Hypothesis 계산
return self.linear(x)
hypothesis = model(x_train)
# gradient 계산은 backward()를 통해 PyTorch가 알아서 해준다!모듈을 사용하려면 간단히 파이썬의 클래스 개념을 숙지하고 있어야 한다. 자세한 내용은 다음 글을 참고하자.
여기서 클래스를 간단하게 설명하자면, 반복되는 함수들을 클래스라는 개념 안에 묶어두어 쉽게 사용하도록 하기 위함이다.
클래스의 개념에서 보자면 위 코드의 마지막줄은 hypothesis라는 객체에 MultivariateLinearRegressionModel이라는 클래스의 인스턴스를 생성하여 할당하는 과정이다.
또한 __init__ 라는 이름의 함수는 클래스의 생성자이다. 생성자란, 객체가 생성될 때 자동으로 호출되는 메서드(함수)를 의미한다.
'self'는 생성되는 객체이고, 위의 경우 객체는 linear라는 객체 변수를 갖게 된다.
그리고, 클래스 간에 상속을 할 수도 있다. 위의 클래스 정의 부분을 해석하자면 'MultivariateLinearRegressionModel이라는 클래스가 nn.Module이라는 클래스를 상속함'을 뜻한다.
이는 nn.Module 클래스의 기능을 MultivariateLinearRegressionModel 클래스에서 사용할 수 있음을 말한다.
super()는 부모 클래스의 메소드를 호출하기 위해 사용한다. 즉, super()자체가 부모 클래스를 의미한다고 볼 수 있다.
따라서 'super().__init__()' 부분은 nn.Module 클래스의 속성 및 메소드를 가져오는 부분이다. 만약 부모 클래스에 전달할 input이 있다면 __init__()의 인자로 써주면 된다.
얼핏 보기에는 모듈을 사용하는 것이 더 길고 복잡하지 않은가 하고 생각할 수 있지만, nn.Module을 사용하여 클래스를 생성해줌으로써 인공신경망 모델을 편하게 만들 수 있다.
nn.Linear에 입력 차원, 출력 차원만 알려주고, forward 함수에서 hypothesis 계산을 어떻게 할지만 알려주면 된다.
5) torch.nn.functional
또한, PyTorch에서는 'torch.nn.functional' 라이브러리를 통해 다양한 cost function을 제공해준다.
예를 들어, MSE loss function을 사용하려면, 다음과 같이 간단히 사용할 수 있다.
import torch.nn.functional as F
# cost 계산
cost = F.mse_loss(prediction, y_train)6) Full Code
최종 코드와 결과는 다음과 같다.
import torch
from torch import optim
import torch.nn as nn
import torch.nn.functional as F
class MultivariateLinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(3, 1) # 입력차원: 3, 출력차원: 1
def forward(self, x): # Hypothesis 계산
return self.linear(x)
# 데이터
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 모델 초기화
model = MultivariateLinearRegressionModel()
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=1e-5) # model의 파라미터!
nb_epochs = 20
for epoch in range(nb_epochs + 1):
# H(x) 계산
Hypothesis = model(x_train)
# cost 계산
cost = F.mse_loss(Hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('Epoch {:4d}/{} hypothesis: {} Cost: {:.6f}'.format(
epoch, nb_epochs, hypothesis.squeeze().detach(), cost.item()
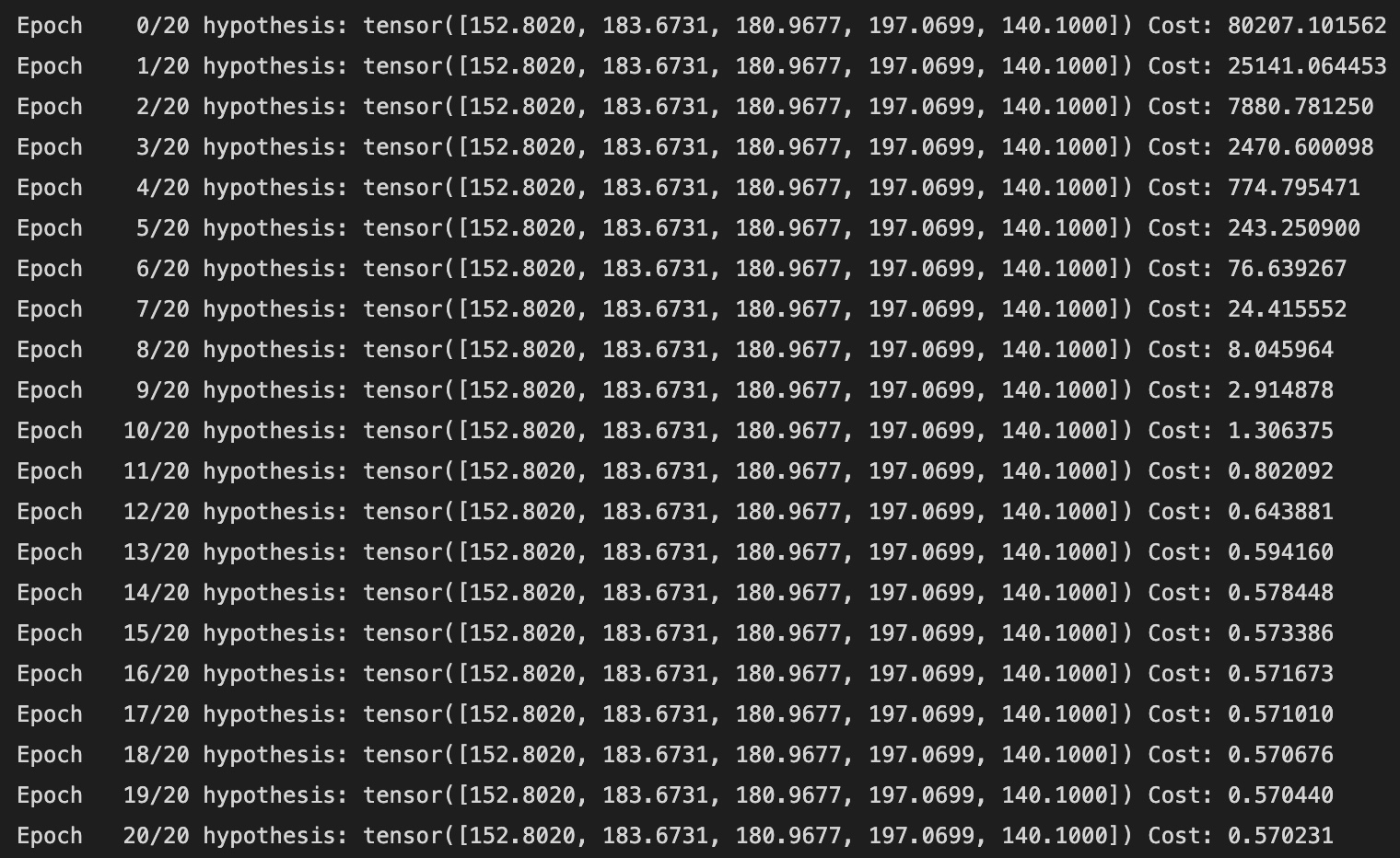
))
2. Loading Data
지금까지는 적은 양의 데이터(빠른 시간 내에 입력이 가능한 데이터)를 갖고 학습을 진행했다.
하지만 딥러닝에서는 엄청나게 많은 양의 데이터를 사용한다. (대부분 데이터셋은 적어도 수십만 개의 데이터를 제공한다.)
이를 위해 PyTorch에서는 Data를 어떻게 다루는지 알아보자.
1) Minibatch Gradient Descent
데이터가 많다는 것은 모델이 견고하고 완성된 예측을 할 수 있으므로 좋은 일이다.
하지만 이러한 엄청난 양의 데이터를 한 번에 학습시키는 것은 거의 불가능하다. 속도가 너무 느리거나 하드웨어적으로 메모리에 다 저장할 수 없을 수 있기 때문이다.
따라서 복잡한 머신러닝 모델에서는 Minibatch Gradient Descent라는 방법을 통해 데이터를 일부로 나누어서 학습한다.
전체 데이터를 Minibatch라는 균일한 적은 양의 데이터로 나누어서 학습을 진행하는 것이다.
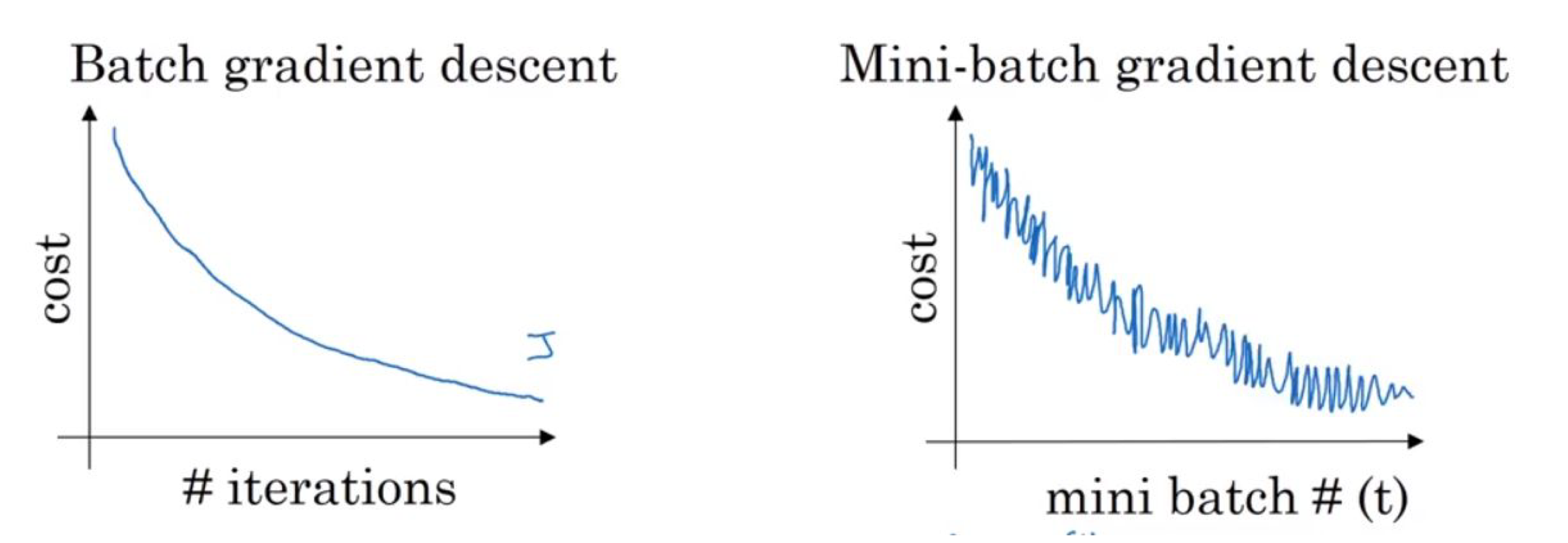
이러한 방법을 사용할 경우, cost를 계산할 때마다 모든 데이터를 쓰지 않기 때문에 각 업데이트 당 계산할 cost의 양이 줄어들어 업데이트 속도가 빨라진다.
하지만 전체 데이터를 쓰지 않아 잘못된 방향으로 업데이트가 진행될 수도 있다. 이에 따라 위 그림과 같이 Batch GD에 비해 거칠게 업데이트가 진행된다.
2) 'Dataset' module
데이터 샘플을 처리하는 코드는 유지보스가 어려울 수 있다. 더 나은 readability와 modularity를 위해 데이터셋 코드를 모델 학습 코드로부터 분리하는 것이 이상적이다.
PyTorch는 이를 위해 torch.utils.data.Dataset과 torch.utils.data.DataLoader라는 데이터를 다루는 모듈을 제공해준다.
이를 통해 미리 준비된 데이터셋 뿐만 아니라, 가지고 있는 데이터를 사용할 수 있도록 해준다.
간단히 Dataset은 sample, label을 저장하고, DataLoader는 Dataset을 샘플에 쉽게 접근할 수 있도록 iterable 객체로 랩핑해준다.
'torch.utils.data.Dataset'부터 알아보자.
커스텀 데이터셋을 만들 때, 아래와 같은 2가지 magic method를 구현해야 한다.
- __len__() : 데이터셋의 총 데이터 수 반환
- __getitem__() : 어떤 인덱스 idx를 받았을 때, 그에 상응하는 입출력 데이터를 반환
코드는 다음과 같이 작성한다.
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self):
self.x_data = [[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]]
self.y_data = [[152], [185], [180], [196], [142]]
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
dataset = CustomDataset()3) 'DataLoader' module
'torch.utils.data.DataLoader'라는 모듈을 사용한다.
DataLoader의 인스턴스를 만들기 위해서는 다음 두 가지 변수를 지정해야 한다.
- dataset : 위에서 만든 dataset이다.
- batch_size : 각 minibatch의 크기 (일반적으로 2의 제곱수로 설정한다.)
통상적으로 많이 사용하는 옵션은 'shuffle'이 있다. shuffle을 True로 지정할 시 Epoch마다 데이터셋을 섞어서 데이터가 학습되는 순서를 바꾸어준다.
DataLoader를 사용하면 Dataset이 iterable 객체가 되어, minibatch의 인덱스와 데이터에 쉽게 접근할 수 있게 된다.
4) Full Code with Dataset and DataLoader
Dataset과 DataLoader를 이용한 전체 코드와 결과를 살펴보자.
import torch
from torch import optim
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# Dataset
class CustomDataset(Dataset):
def __init__(self):
self.x_data = [[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]]
self.y_data = [[152], [185], [180], [196], [142]]
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
dataset = CustomDataset()
# DataLoader
dataloader = DataLoader(
dataset,
batch_size=2,
shuffle=True
)
class MultivariateLinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(3, 1) # 입력차원: 3, 출력차원: 1
def forward(self, x): # Hypothesis 계산
return self.linear(x)
# 모델 초기화
model = MultivariateLinearRegressionModel()
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=1e-5) # model의 파라미터!
nb_epochs = 20
for epoch in range(nb_epochs + 1):
for batch_idx, samples in enumerate(dataloader):
x_train, y_train = samples
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('Epoch {:4d}/{} Batch: {}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, batch_idx+1, len(dataloader), cost.item()
))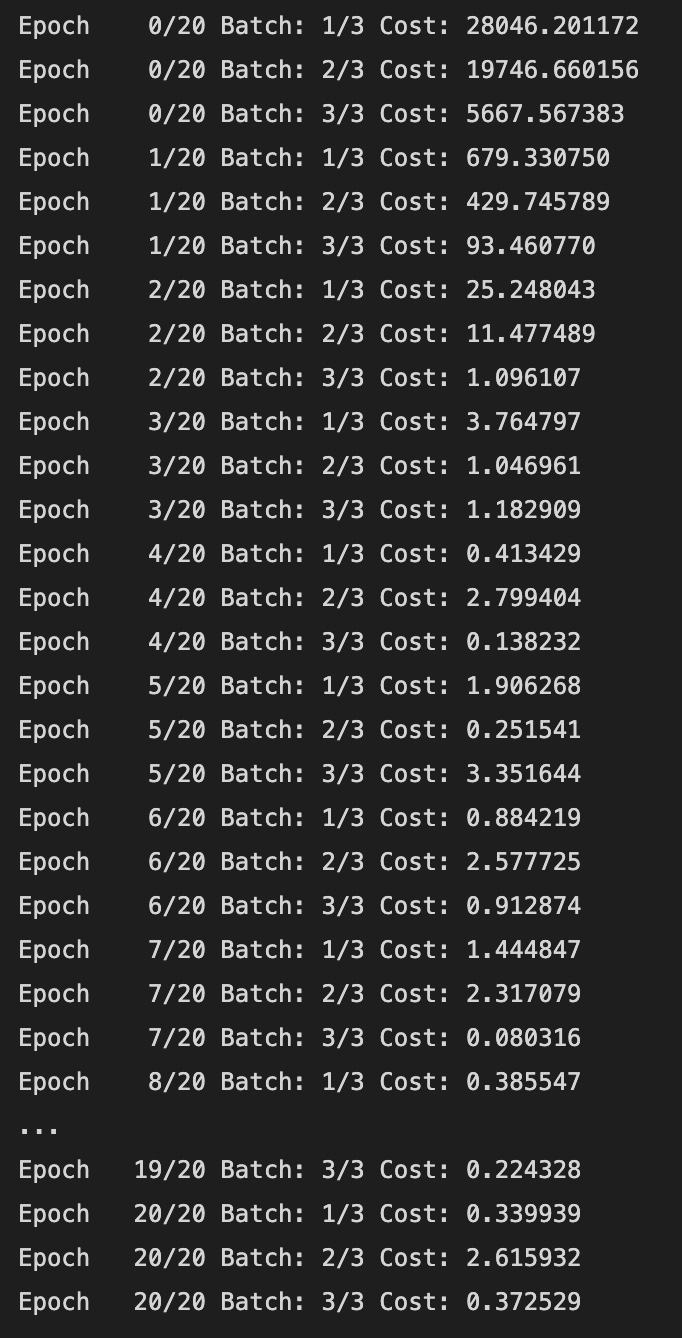
enumerate(dataloader)를 통해 iterable 객체인 dataloader에서 minibatch 인덱스와 데이터를 받아오고, len(dataloader)는 한 epoch 당 minibatch가 몇 개인지를 알려준다.
