Pytorch를 간단히 다루어본 적이 있는데, 앞으로의 연구에 익숙하게 활용하기 위해 Pytorch 내용을 정리해보려 한다.
대부분의 내용은 유튜브의 '모두를 위한 딥러닝 시즌2'를 참고하였다.
기본적인 딥러닝 내용은 어느 정도 알고있다고 가정하고, PyTorch 실습 내용 위주로 정리해두었다.
간단한 설명이 포함된 실습 자료는 다음 Github를 참조하자.
1. Linear Regression 개요
Linear Regression은 인공지능 뿐만 아니라 통계학에서도 매우 많이 사용되는 기본 개념이다.
일반적인 linear regression은 하나 이상의 설명 변수(explanatory variables)에 의해 선형적인 관계를 갖는 응답을 모델링하는 것이다.
설명 변수가 하나인 경우에는 simple linear regression, 둘 이상인 경우에는 multivariate linear regression이라 한다.
우선 이번 포스팅에서는 simple linear regression에 대해 알아보자.
1) Data Definition
Linear Regression에서 데이터셋은 두 가지로 나뉜다.
- Training Dataset : 모델을 학습시키는 데 사용되는 데이터
- Test Dataset : 모델이 얼마나 잘 작동하는지 확인하는 데이터
PyTorch를 사용한다면 데이터는 'torch.tensor'의 형태를 가질 것이고, simple linear regression인 경우 학습 데이터의 입력은 x_train, 출력은 y_train으로 둘 수 있다.
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])2) Hypothesis
앞서 Linear Regression이란 학습 데이터와 잘 맞는 직선을 찾는 과정이라고 하였다.
이에 따라, 다음과 같은 수식으로 모델을 표현할 수 있다.
Hypothesis를 PyTorch를 사용해서 표현하면 다음과 같다.
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
hypothesis = x_train * W + b여기서, Weight 와 Bias 는 0으로 초기화했으며, requires_grad=True는 학습 과정에 필요한 'gradient'가 필요하다, 즉 해당 변수를 학습시킬 것이라는 것을 명시해주는 과정이다.
또한 torch.zeros의 인자로 1을 전해주면서 tensor의 shape이 1임을 명시해주었다.
3) Compute Loss
와 를 통해 모델은 예측 값을 출력하게 된다. 이때, 모델이 예측한 값과 실제 정답 값이 얼마나 가까운가를 Loss 또는 Cost라 한다.
여러 방법으로 Loss와 Cost를 나타낼 수 있는데, 대표적으로 Mean Squared Error (MSE) 를 많이 사용한다. 수식은 다음과 같다.
코드로는 다음과 같이 나타낸다.
cost = torch.mean((hypothesis - y_train) ** 2)4) Gradient Descent
앞서 Weight와 Bias를 0으로 초기화했었는데, cost를 줄이는 값으로 Weight와 Bias를 반복적으로 업데이트해준다. 이러한 과정을 Optimization(최적화)라 한다. 특히 머신러닝에서 최적하에 많이 사용되는 방식 중에는 Gradient Descent가 있다.
코드를 살펴보자.
optimizer = optim.SGD([W, b], lr=0.01) # Stochastic Gradient Descent
optimizer = zero_grad() # gradient 초기화
cost.backward() # gradient 계산
optimizer.step() # 계산된 gradient 값을 사용하여 W, b 업데이트torch.optim 라이브러리를 사용하여 학습할 Tensor([W, b])와 learning rate를 설정해준다.
5) Full Training Code
전체 학습 과정은 다음과 같다.
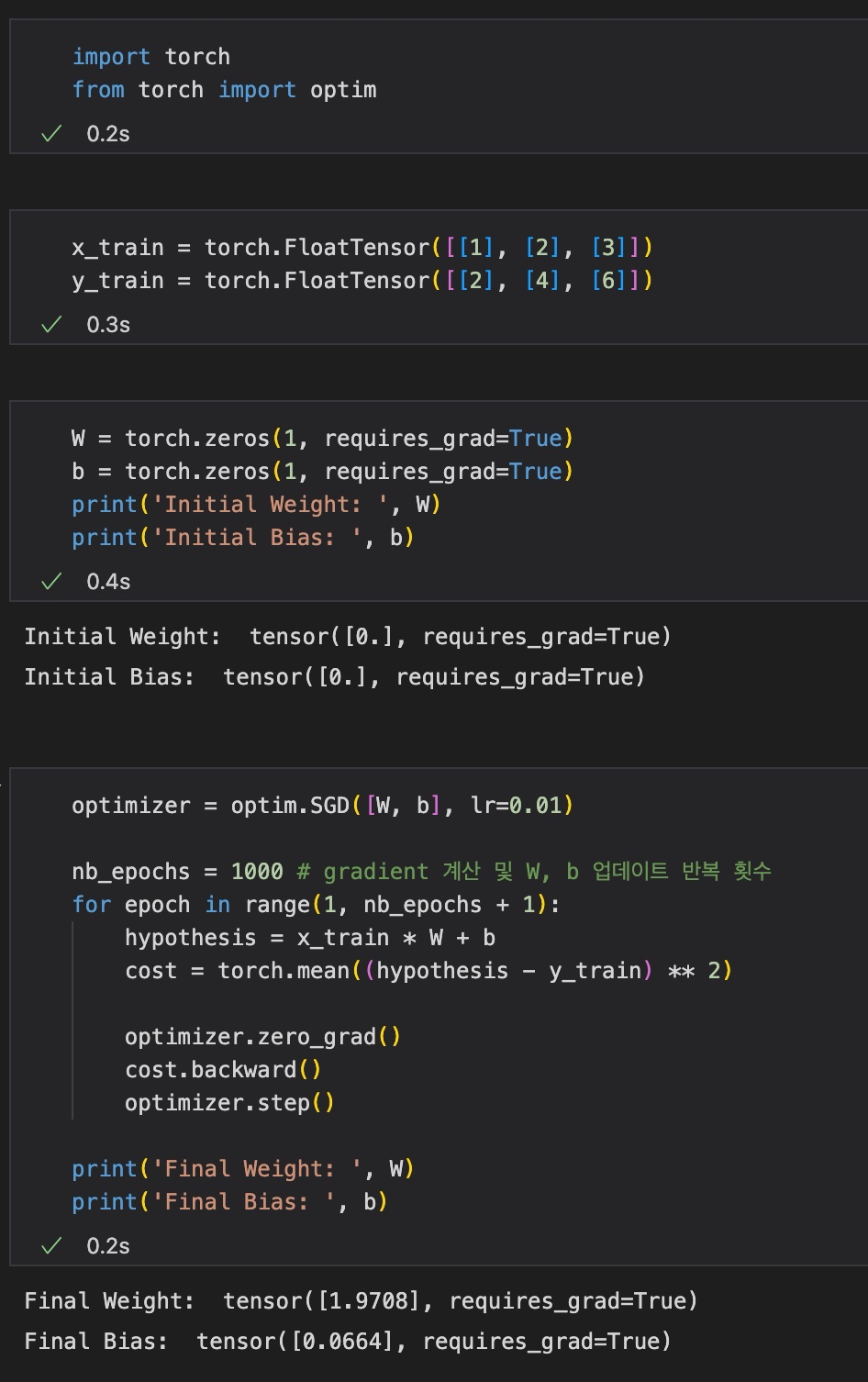
학습 데이터를 살펴보았을 때, x_train의 값 1, 2, 3에 따라 y_train의 값이 2, 4, 6이므로 W는 2, b는 0이 되는 것이 정답일 것이다.
weight와 bias 업데이트를 반복하는 횟수를 1000번으로 지정했을 때 위 결과 사진과 같이 W는 1.9708, b는 0.0664라는 값이 나왔다.
2. Gradient Descent
Gradient Descent에 대해 좀 더 살펴보자.
1) Cost Function과 Gradient
앞서 모델의 예측값과 실제 값 간의 차이를 Cost라 한다고 하였다.
편의를 위해 bias는 고려하지 않고, Weight 만 고려하자.
cost function은 (만약 위에서 소개한 MSE를 사용한다면) 아래와 같이 2차함수 형태가 될 것이다.
위 2차 함수를 W, Cost에 대한 곡선으로 나타내면
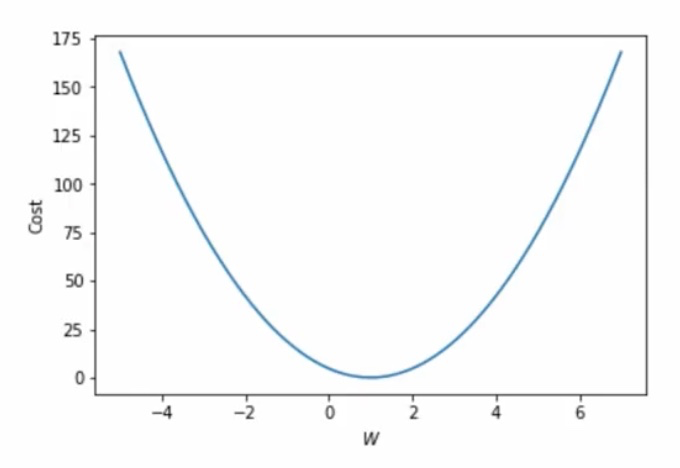
위와 같은 형태일 것이다.
Cost를 낮추는 것이 모델 학습의 목적이므로, 현재 값에서 기울기(Gradient)를 계산하여 W값을 업데이트해줄 것이다.
Gradient는 다음과 같이 나타낸다.
2) Gradient Descent
Gradient Descent 방법에서는 W를 다음과 같이 업데이트한다.
여기서 (\alpha)는 learning rate이고, cost 값을 줄이는 방향으로 업데이트해야 하므로 gradient와 learning rate값의 곱 만큼 빼주어야 한다.
Gradient Descent 과정을 코드로 나타내면 다음과 같다.
gradient = 2 * torch.mean((W * x_train - y_train) * x_train)
lr = 0.1
W -= lr * gradient3) Full Code (with Gradient Descent)
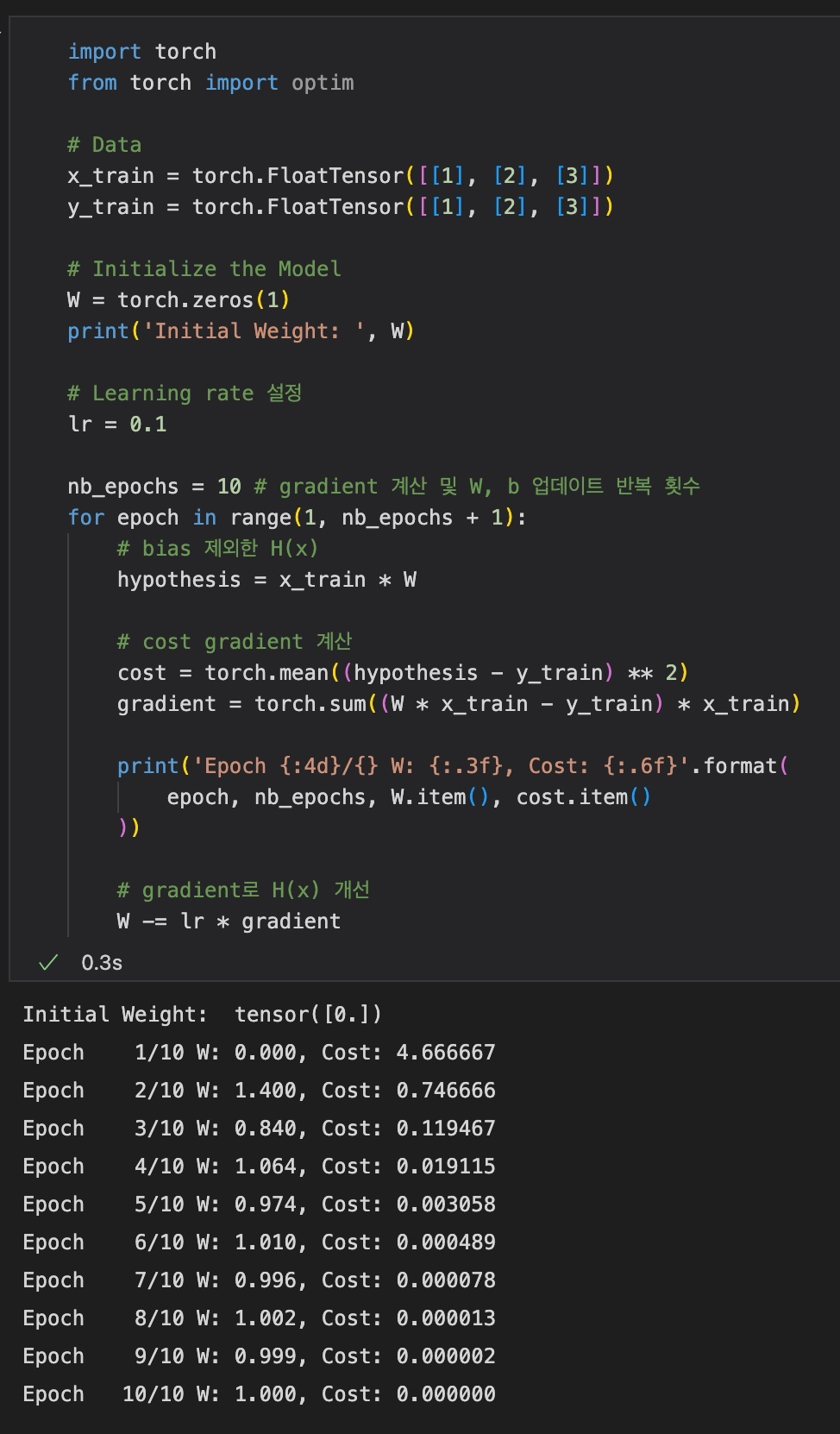
결과에서는 직접 gradient를 계산했지만, torch.optim 라이브러리를 통해 쉽게 gradient descent를 구현할 수 있다. (1-5의 Full Training Code 참조)
