모수의 통계량
모수(parameter)
모집단의 특성을 나타내는 값으로 알 수 없는 상수인 모수의 값을 추정하기 위해서 모집단으로부터 크기 n인 표본 X1,X2,...Xn을 추출해야한다.
통계량(statistic)
표본들만의 함수로 표현하는 것으로 특정 모수를 추정하기 위해서 표본을 이용하여 만든 함수입니다.

표본분포(sampling distribution)
통계량이 갖는 분포
표본평균의 분포
임의표본(ramdom sample)
크기 n인 표본 X1,X2,...Xn일 때
I) 동일한 분포(동일한 모집단)을 가진다.
II) 서로 독립일 때, X1,X2,...Xn을 임의표본이라고 한다,

따름정리: X1,X2,...Xn이 N(m,시그마제곱)으로부터의 임의 표본이라면,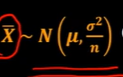
*예시
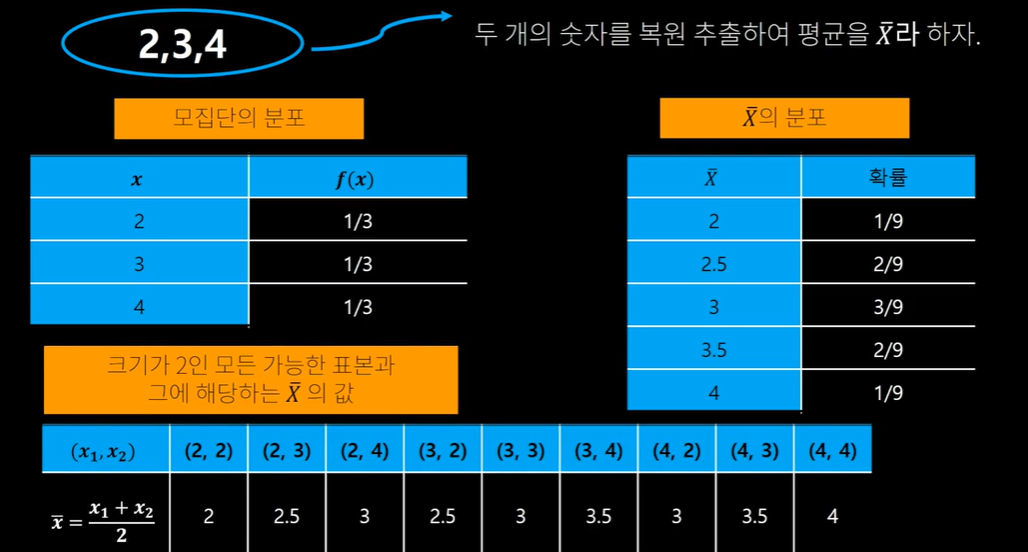
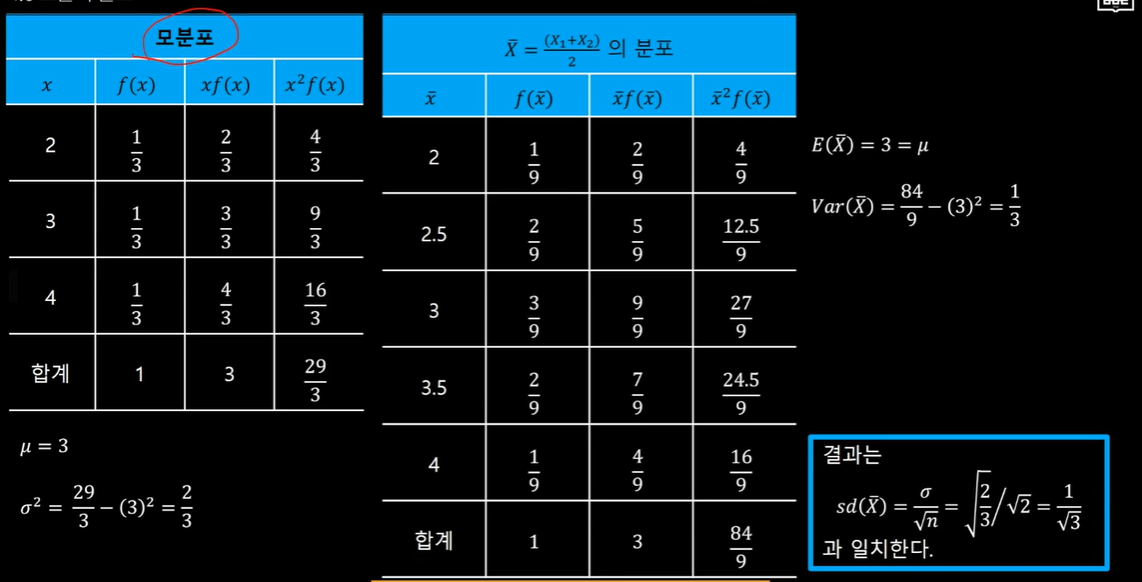
중심극한 정리

표본의 크기가 클수록 X바의 분포는 더 정규 분포 가까이에 수렴하기에 표본의 크기가 25보다 클 경우 중심극한정리를 이용할 수 있다
x=floor(runif(2500,0,10)); x
# 0부터 9까지의 정수를 균일분포로 2,500개 생성
hist(x)

mean(x) # E(X) = 4.5와 유사함
[1] 4.5588sd(x) # s.d.(X)= 2.87와 유사함
[1] 2.877126y = array (x, c(500,5)) ;y
# 2,500개의 정수를 크기가 5인 벡터 500개를 생성xbar = apply(y,1,mean); xbar
# 크기 5인 표본에서 표본평균을 구하여 500개의 표본평균 생성 hist(xbar)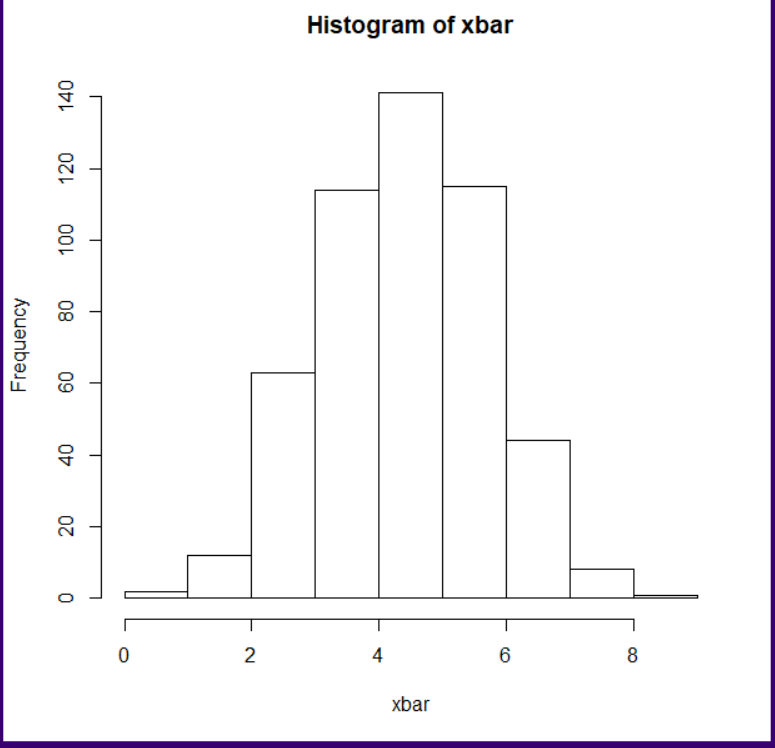
mean(xbar) # 표본평균의 기댓값으로 E(X) = 4.5와 유사함
[1] 4.516sd(xbar) # 표본평균의 표준편차로서 s.d.(X) /√(5 )= 1.28와 유사함
[1] 1.283401이항분포의 정규근사화(normal approximation to the binomial)

*예제

x <- rnorm(20, 5, 3); x

qqnorm(x)

성장을 도울 아카이빙 블로그