Encoding Categorical Variables
머신러닝 모델은 범주형 변수를 이용하면 학습을 시킬 수 없습니다.(단, LightGBM같은 모델 제외, LGBM,CatBoost논문 읽기)
이런 이유로, 범주형 변수를 이산 변수로 바꾸는 encoding과정을 거쳐야합니다.
Encoding
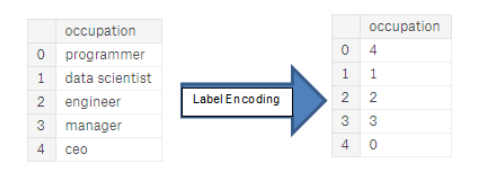
- Label encoding
상수를 통해서 범주형 변수 안에 있는 각각의 유니크한 범주를 지정합니다.(새로운 컬럼이 생기지 않습니다.)
카테고리가 2개일 때 자주 사용
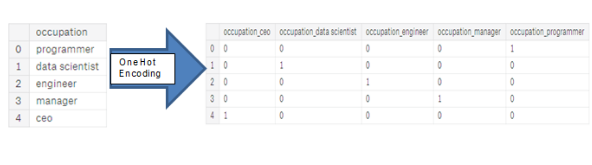
- One-hot encoding
각 범주형 변수안에 있는 유니크한 목록들을 위해서 칼럼을 다시 만듭니다.
1: 기존 칼럼에 있던 것
0: 새로운 컬럼에서 생긴 것
이산형 변수로 변하는 수가 라벨 인코딩보다 적기에 더 많이 쓰이고 있다. (카테고리가 3개 이상)
Code1
#Create a label encoder object
le = LabelEncoder()
le_count = 0
#Iterate through the columns
for col in app_train:
if app_train[col].dtype == 'object':
#If 2 or fewer unique categories
if len(list(app_train[col].unique())) <= 2:
#Train on the training data
le.fit(app_train[col])
# Transform both training and testing data
app_train[col] = le.transform(app_train[col])
app_test[col] = le.transform(app_test[col])
# Keep track of how many columns were label encoded
le_count +=1
print('%d columns were label encoded.' % le_count) #3 columns were label encoded.#one-hot encoding of categorical variables
app_train = pd.get_dummies(app_train)
app_test = pd.get_dummies(app_test)
print('Training Features shape: ', app_train.shape) #Training Features shape: (307511, 243)
print('Testing Features shape: ', app_test.shape) #Testing Features shape: (48744, 239)Aligning Training and Testing Data
훈련과 테스트 데이터셋에 같은 특징(columns)을 갖는 것들이 필요하다.
One-hot encoding는 훈련 데이터 안에서 더 많은 칼럼을 갖습니다. 왜냐하면, 테스트 데이터에 없는 것도 포함이 되기 때문입니다.
Align이라는 데이터 프레임을 이용하면 테스트 데이터 안에 없지만 훈련 데이터에 있는 데이터를 제거합니다.
먼저, 훈련 데이터에서 타깃 컬럼을 뽑습니다.
그리고나서, axis=1기준으로 align시도합니다.
위의 과정이 우리가 익히 들었던 차원 축소 과정입니다
train_labels = app_train['TARGET']
#Align the training and testing data, keep only columns present in both dataframes
app_train, app_test = app_train.align(app_test, join = 'inner', axis = 1)
#Add the target back in
app_train['TARGET'] = train_labels
print('Training Features shape: ', app_train.shape) #Training Features shape: (307511, 240)
print('Testing Features shape:', app_test.shape) #Testing Features shape: (48744, 239)
#기존과 비교했을 때 차원(컬럼)만 축소되고 열은 유지
성장을 도울 아카이빙 블로그