EDÅ
-
Calculate statistics
-
Make figures
- trends, anomalies, patterns or relationships
-
Inform modeling choices
-
Find areas of data
Examine the Distribution of the Target Column
-
Prediction of Target
-
0: the loan was repaid on time
-
1: Indicating the client had payment difficulties
-
-
Examine the number of loans
#How many 0 and 1
app_train['TARGET'].value_counts()
#It is too imbalanced class
#Graph
app_train['TARGET'].astype(int).plot.hist();
#Almostly, the loans were paid on time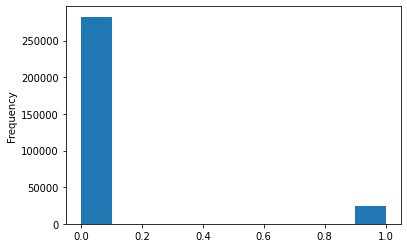
Need to sophisticated machine learning models for Reflecting this imbalance by weighting the classes of the data
Examine Missing Values
The number and percentage of missing values in each column
#Function to calculate missing values by column #Funct
def missing_values_table(df):
#Total missing values
mis_val = df.isnull().sum()
#Percentage of missing values
mis_val_percent = 100 * df.isnull().sum() / len(df)
#Make a table with the results
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
#Rename the columns
mis_val_table_ren_columns = mis_val_table.rename(columns = {0 : 'Missing Values', 1 : '% of Total Values'})
#Sort the table by percentage of missing descending
mis_val_table_ren_columns = mis_val_table_ren_columns[mis_val_table_ren_columns.iloc[:,1] != 0].sort_values('% of Total Values', ascending=False).round(1)
#Print some summary information
print(mis_val)
print(mis_val_percent)
print("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
#Return the dataframe with missing information
return mis_val_table_ren_columns#Missing values statistics
missing_values = missing_values_table(app_train)
missing_values.head(20)
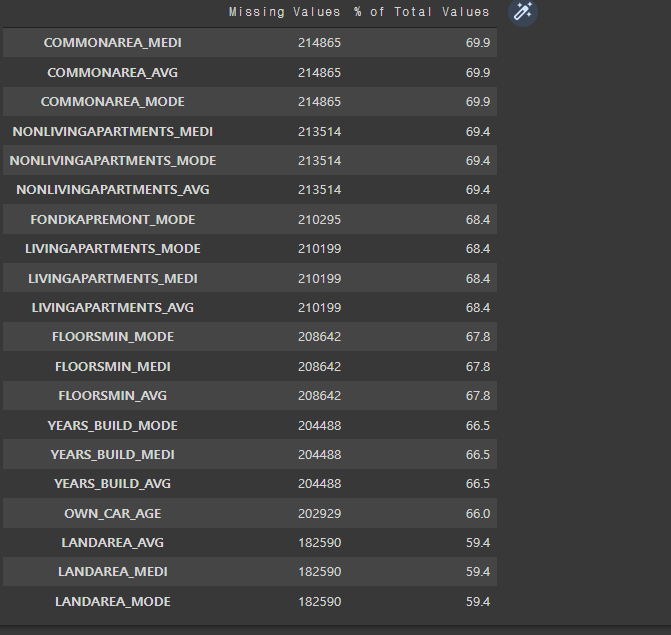
How to use these values
-
Be bulit machine learning models by missing values
-
Use XGBoost
- handle missing values with no need for imputation
-
Drop columns: high percentage of missing values
Column Types
-
The number of columns of each data type
-
Numeric variables(discrete or continuous)
-
int64
-
float64
-
-
Categorical features
- Object columns (like string)
#Number of each type of column
app_train.dtypes.value_counts()
#Number of unique classes in each object column
app_train.select_dtypes('object').apply(pd.Series.nunique, axis=0)
#Most of the categorical variables have small number of unique entries
#We wil need to find a way to deal with these categorical variables!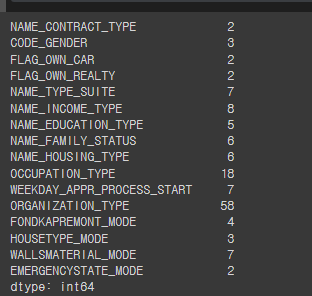

성장을 도울 아카이빙 블로그