포스팅은 총 3편으로 나눠 올릴 예정입니다.
- SRGAN 논문 리뷰 1. 네트워크 구조
- SRGAN 논문 리뷰 2. 손실함수
- SRGAN 구현 및 코드
서론
Super Resolution은 저화질 이미지를 고화질로 변환하는 작업입니다. 과거에는 딥러닝을 이용한 Super Resolution이 많은 계산량과 시간 소요로 인해 외면받아 왔지만 SRCNN을 시작으로 딥러닝을 활용한 Super Resolution 작업이 크게 곽광받기 시작했습니다. (SRCNN의 논문에 리뷰와 구현도 포스팅 예정입니다!) SRGAN은 SRCNN에서 GAN 네트워크와 VGG 네트워크를 이용한 Feature Map 개념이 더해져 SRCNN 보다 만족스러운 결과물을 보여줍니다.
포스팅은 총 2으로 나눠 올릴 예정입니다.
SRGAN 논문 리뷰 1. 네트워크 구조
SRGAN 논문 리뷰 2. 손실함수
1. 네트워크 구조
먼저 네트워크 구조에 대해 설명 드리겠습니다. SRGAN은 GAN(Generative Adversarial Networks) 구조의 네트워크로 일반적인 GAN 네트워크와 생성기(Generative Network), 판별기(Discriminator Network) 2가지로 이뤄져 있습니다.
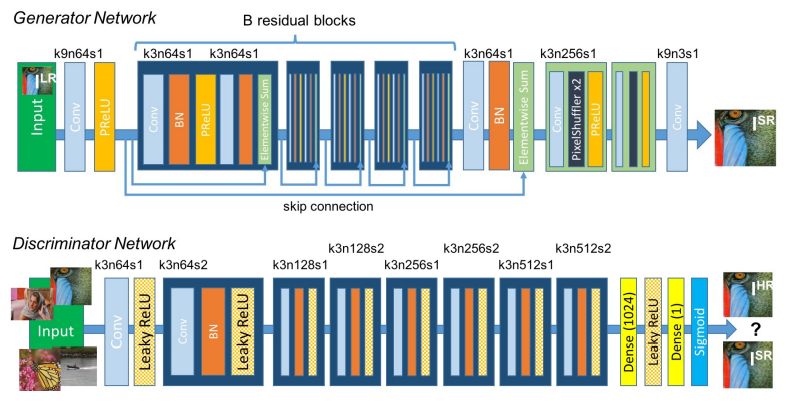
2. 생성기 (Generative Network)
SRGAN의 Generative Network는 일반적인 GAN의 Generative Network와는 몇가지 차이가 있습니다. 일반적인 GAN에선 입력으로 노이즈를 받는다면 SRGAN에서는 저화질로 변환된 LR(Low-Resoltion) 이미지를 입력으로 받고 고화질로 변환된 이미지를 출력하게 학습됩니다. 입력으로 받은 이미지는 크게 패턴인식, 사이즈 업스케일, 이미지 생성에 해당하는 3단계의 과정을 거치게 됩니다. (주의: 해당 3단계는 보다 쉬운 이해를 위한 임의로 설정한 단계입니다.)
단계 1. 패턴인식

패턴인식의 위 그림의 빨간 영역에 해당합니다. 패턴 인식 단계에서는 이미지의 특징을 추출하고 화질 개선을 위한 이미지 분석과 연산이 이뤄지게 됩니다 때문에 1단계에서 대부분의 연산이 수행됩니다. 1단계 패턴인식 단계를 거친 후에는 2 단계의 이미지 업스케일을 통과하게 되는데 이를 통해 연산량을 최소화 할 수 있습니다. 만약 업스케일이 먼저 일어 난다면 이미지의 사이즈가 거친만큼 연산량도 함께 증가하게 됩니다.
우선 입력된 이미지는 크기 9인 64개의 2D CNN 커널과 PReLU를 통과하게 됩니다. 통과 후 총 5개의 같은 형태의 Residual Block을 통과하게 됩니다. Residual Blockd은 2개의 2D CNN 층으로 이뤄져 있습니다. 각각의 CNN은 Batch Normalization을 통과하게 되고 첫번째 CNN층의 경우 PReLU층을 통과하게 됩니다. 이때 두번째 CNN 층에서는 PReLU대신 입력 데이터를 Elementwise Sum을 진행하여 잔차(Residual)에 대한 학습을 진행합니다. 이와 같은 Residual Block은 모델의 학습 과정을 단순화 해주고 깊은 층의 경우 Gradient Vanishing 문제를 효과적으로 해결해 주기도 합니다. (이해 관해 더 자세하게 이해하고 싶은 분들은 ResNet에 대해 찾아보시길 추천합니다.) 5개의 Residual Block을 연달아 통과한 후에 2D CNN, Batch Normalization, Elementwise Sum을 연달아 수행합니다.
단계 2. 사이즈 업스케일
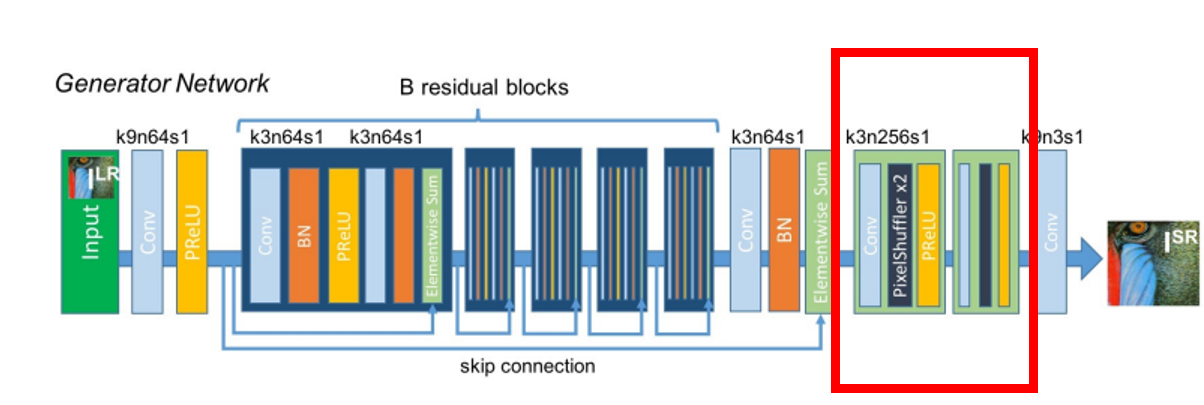
사이즈 업스케일은 2개의 동일한 블록으로 이뤄져 있습니다. 각각의 블록은 데이터의 높이, 넓이를 2배씩 증가 시키는 작업을 진행하게 됩니다. 일반적인 CNN 연산에서는 데이터의 높이와 넓이가 증가되지 않지만 해당 논문에서는 4가지의 필터를 1가지로 묶어 2*2의 사이즈로 만들어주는 Pixel Shuffler를 진행했습니다.
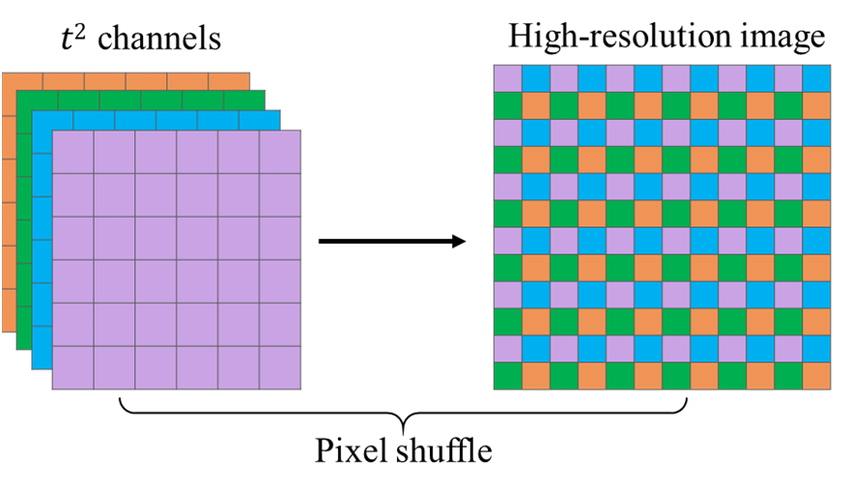
이 작업을 통해 (W, H, 256)의 데이터를 (2W, 2H, 64)의 사이즈로 변환해 줍니다. 따라서 해당 블록 거칠 때 마다 이미지의 넓이, 높이가 2배씩 증가하게 됩니다. 논문에서는 이 과정을 2번 진행하므로 높이, 넓이가 4배 씩 증가하게 됩니다.
단계 3. 이미지 생성
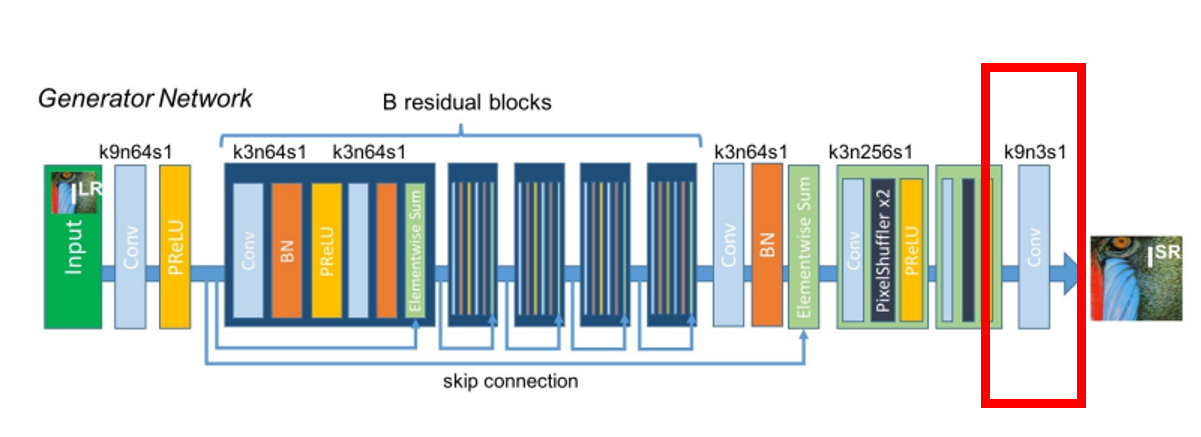
마지막 단계는 아주 간단합니다. 크기가 9 인 3개의 커널로 이뤄진 CNN층 한개로 이뤄져 있습니다. 우리가 목표로하는 이미지 출력은 RGB를 가진 3채널의 데이터로 해당 층의 3개의 커널과 연산을 통해 전단계에서 여러가지로 나눠져 있던 채널을 RGB에 해당하는 3가지 채널로 압축하는 과정을 담당합니다. 해당 층에서는 어떤 활성함수도 사용되지 않습니다.
3. 판별기 (Discriminator Network)
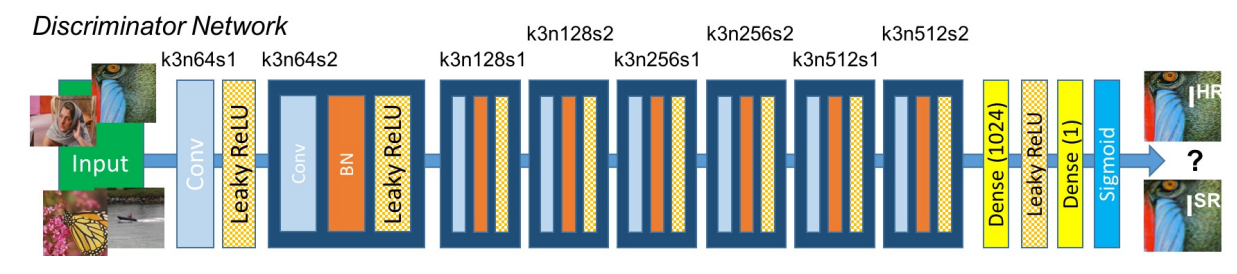
SRGAN에서 판별기의 구조는 일반적인 Image Classification Network와 크게 다르지 않습니다. 특이한 점이라면 Max Pooling을 사용하지 않았다는 점 입니다. 아무래도 고해상도 이미지의 판별을 목표로 하기 때문에 Max Polling을 통해 이미지의 사이즈를 줄이지 않았습니다. 활성함수는 ReLU를 개선했다고 알려진 Leaky ReLU를 활용했습니다. CNN, Batch Normalization, Leaky ReLU로 이뤄진 CNN 블록을 7번 통과하고 Sigmoid를 통해 원본(HR) 인지, 네트워크에 의해 생성된 고해상도 이미지(SR)인지 판별을 진행하게 됩니다. 이때 원본의 경우 출력으로 1을, 네트워크에 의해 생성된 가짜 고해상도 이미지일 경우 0을 출력하도록 학습합니다.
논문
Ledig, Christian, et al. "Photo-realistic single image super-resolution using a generative adversarial network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
https://arxiv.org/abs/1609.04802
제가 미숙해 틀린 부분이나 놓친 부분이 있을 수 있습니다. 잘못 되거나 부족한 부분은 언제든 댓글로 남겨주세요!
