tensorflow 회귀 모델
# Insulin 값이 0보다 큰 값만 사용
df = df[df['Insulin'] > 0].copy()
df.shape
>>>> (394, 9)학습, 예측 데이터
# label_name
label_name = "Insulin"
# train, test 데이터셋을 pandas의 sample을 사용하여 8:2로 나눔
train = df.sample(frac=0.8, random_state=42)
test = df.drop(train.index)
train.shape, test.shape
>>>> ((315, 9), (79, 9))
X_train = train.drop(columns=label_name)
X_test = test.drop(columns=label_name)
y_train = train[label_name]
y_test = test[label_name]
X_train.shape, X_test.shape, y_train.shape, y_test.shape
>>>>
((315, 8), (79, 8), (315,), (79,))딥러닝 레이어
import tensorflow as tf
input_shape = X_train.shape[1]Input-hidden-output layers
# 입력레이어를 Input 레이어로 사용 가능 ->tf.keras.layers.Input(shape=(input_shape))
# 회귀는 출력을 하나로 함 tf.keras.layers.Dense(1)
model = tf.keras.model.Sequential([
tf.keras.layers.Dense(units=128, input_shape=[input_shape]),
tf.keras.layers.Dense(128, activation='selu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1)
])compile
- 손실함수
회귀 : MSE, MAE
optimizer = tf.keras.optimizer.RMSprop(0.001)
model.compile(optimizer=optimizer,
loss=['mae', 'mse'],
metrics=['mae', 'mse'])학습
- epoch 마다 훈련 상태 점검을 위해 EarlyStopping callback 사용함
- 지정된 epoch 횟수 동안 성능 향상이 없으면 자동으로 훈련을 멈춤
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=100)
history = model.fit(X_train, y_train, epochs=1000, verbose=0, callbacks=[early_stop], validation_split=0.2)df_hist = pd.DataFrame(history.history)
df_hist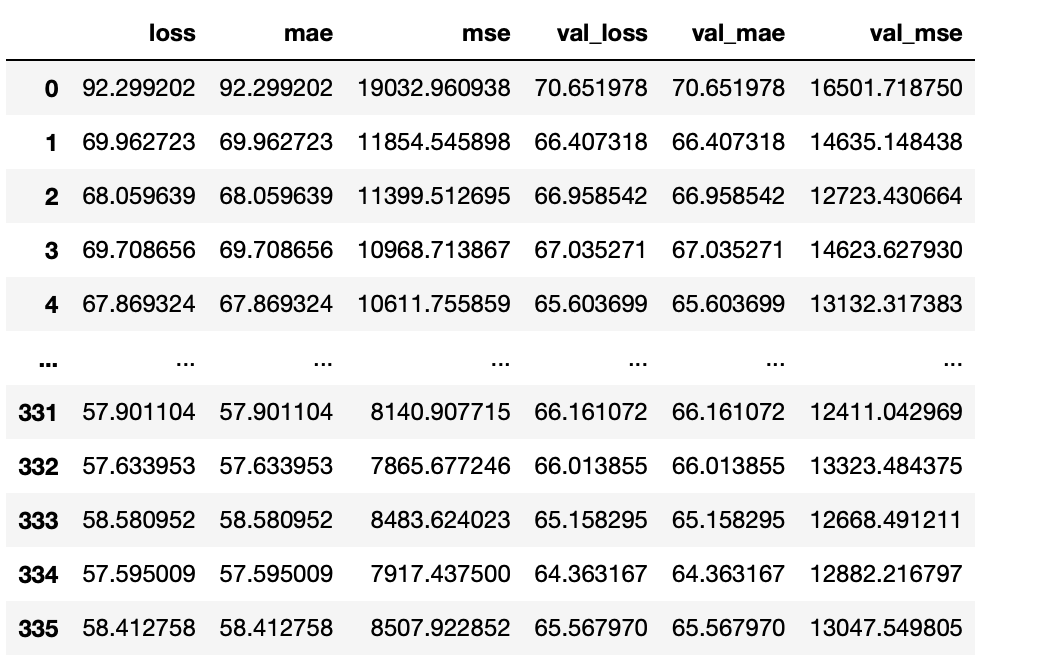
학습결과 시각화
df_hist[['val_mse', 'mse']].plot()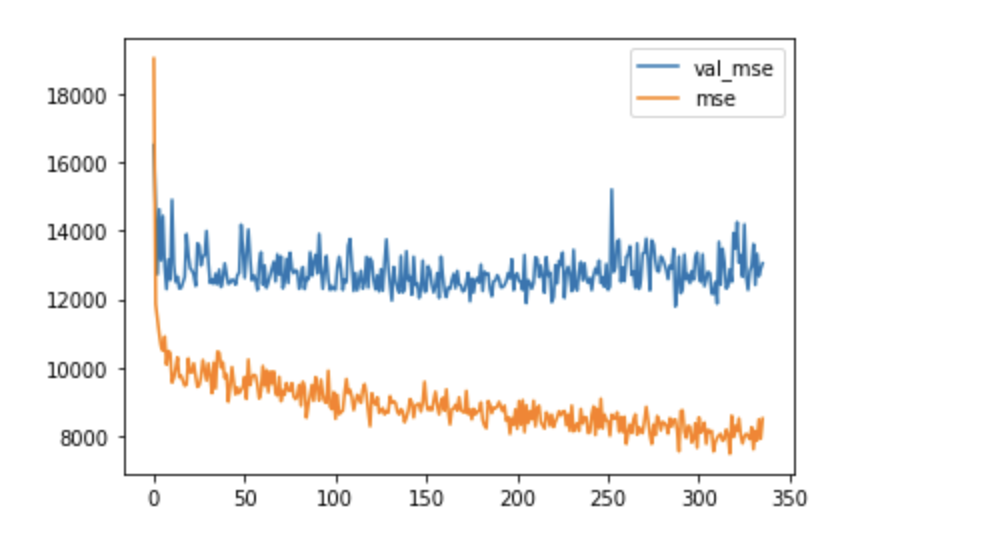
df_hist[['val_loss', 'loss']].plot()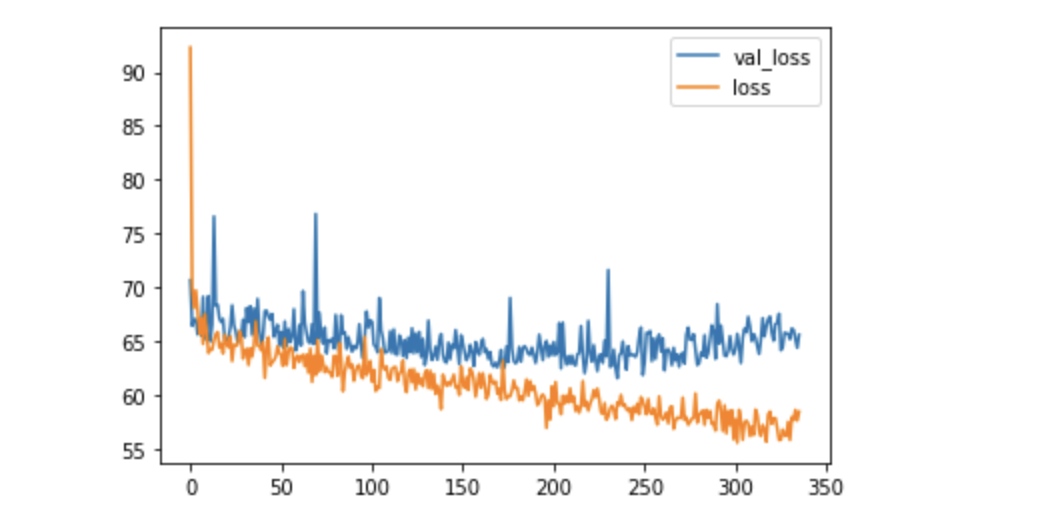
df_hist[['val_mae', 'mae']].plot()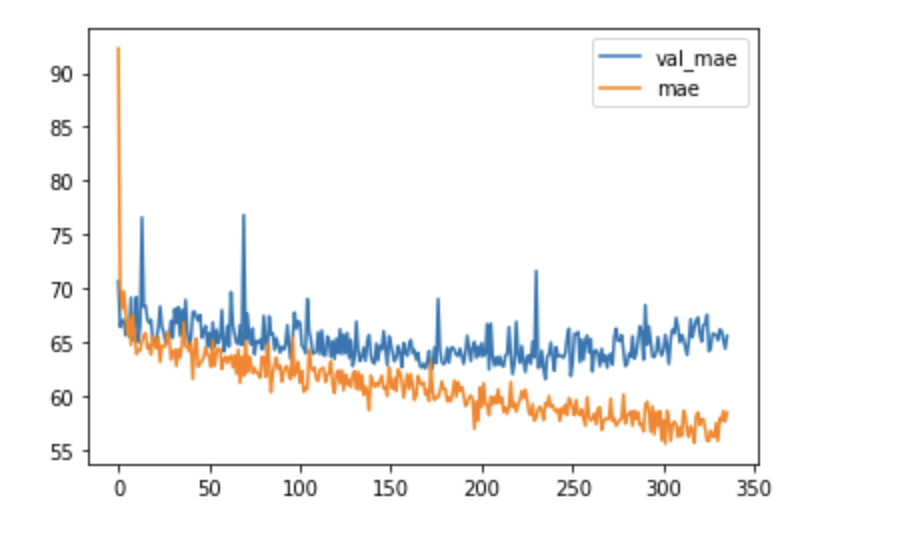
예측
y_pred = model.predict(X_test)
y_pred.shape
>>>>
(79, 1)
# 예측값을 flatten() 사용하여 1차원으로 변환
y_predict = y_pred.flatten()
y_predict[:5]
>>>>
array([168.18686 , 120.563324, 55.60412 , 86.8746 , 67.86247 ],
dtype=float32)평가
loss, mae, mse = model.evaluate(X_test, y_test)
print("테스트 세트의 평균 절대 오차: {:5.2f}".format(mae))
print("테스트 세트의 평균 제곱 오차: {:5.2f}".format(mse))
>>>>
- loss: 58.6941 - mae: 58.6941 - mse: 10415.8936
테스트 세트의 평균 절대 오차: 58.69
테스트 세트의 평균 제곱 오차: 10415.89실제값 - 예측값 시각화
sns.jointplot(x=y_test, y=y_predict, kind='reg')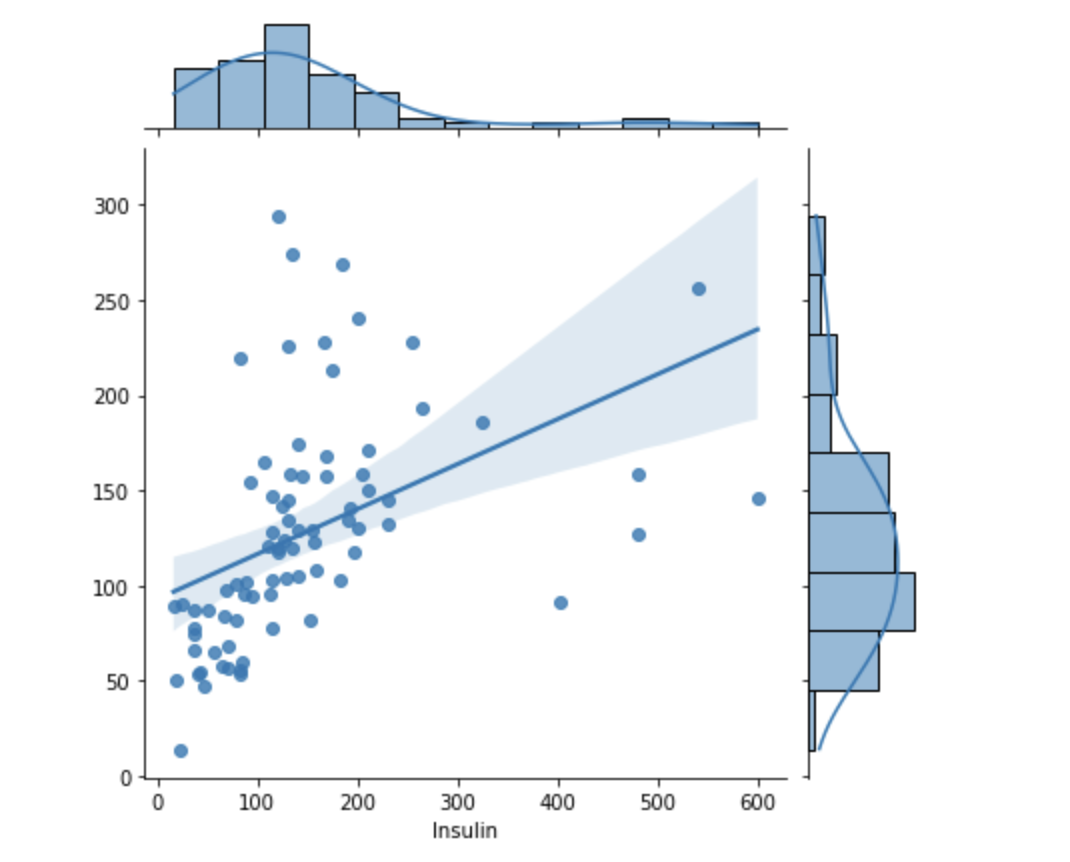
MAE
- 예측값과 실제값의 차이에 대한 절대값의 평균
mae = abs(y_predict - y_test).mean()
mae
>>>> 59.65080715131156MAPE
- (실제값 - 예측값 / 실제값)의 절대값에 대한 평균
mape = abs((y_predict-y_test)/y_predict).mean()
mape
>>>> 0.5017318034318998MSE
- MAE와 비슷해 보이나 제곱을 통해 음수를 양수로 변환함
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_test, y_predict)
mse
>>>> 10439.154403843091RMSE
- MSE 값에 Root를 취함
rmse = mean_squared_error(y_test, y_predict) ** 0.5
rmse
>>>> 102.17218018542567 
Ⓓ🅰️🅣🄰 ♡♥︎