[kaggle] Linking Writing Processes to Writing Quality
시작 전
이 글은 23. 12. 04 ~ 24. 01. 11 동안 참여한 대회의 회고 기록이다.
부트캠프 진행 중 참가한 대회로 이 주제에 관심있는 분 세 분과 함께 베이스라인을 잡아나갔으며, 마지막 2주간은 팀 오픈 이후 merge 하며 일본인 2명 + 나 포함 한국인 2명으로 팀을 이루어 대회를 진행하였다.
글쓰기 내용에 대한 직접 데이터 없이 키 스트로크 분석으로 낸 수열들로만 이루어진 데이터로 에세이를 평가한다는 부분이 흥미로웠다.
대회 개요
개요 요약
약 5000개의 로그 데이터를 사용하여 글쓰기 프로세스를 분석하고, 에세이 품질을 예측하는 것을 목표로 함

목적
학습자의 글쓰기 행동과 성능 간의 관계를 탐구하며, 최종 결과물에 중점을 두기 보다 글쓰기 프로세스에 주목하여 글쓰기의 자율성과 메타인지를 촉진을 도모함
데이터 이해 및 전처리
그림: 참가자들의 글쓰기 과정 추적 프로그램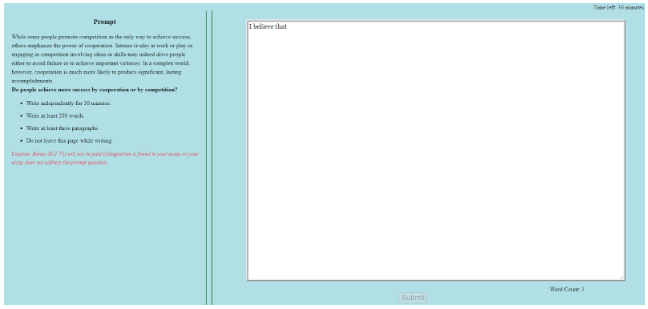
- 참가자들은 SAT 주제에 대해 30분 이내에 논증 에세이를 작성
- 에세이는 최소 200단어, 3개의 문단으로 구성해야 함
- 온라인이나 오프라인 참고 자료 사용 금지
- 글쓰기 도중 2분 이상 활동하지 않거나 새 창으로 이동 시 경고 발생
데이터 소스 및 구조
train_logs.csv(8,405,898 * 11)
* 구두점 및 기타 특수 문자를 제외한 문자 입력은 문자 q로 대체- id: 에세이의 고유 ID
- event_id: 이벤트의 인덱스, 시간 순으로 정렬됨
- down_time: 다운 이벤트의 시간(millisecond)
- up_time: 업 이벤트의 시간(millisecond)
- action_time: 이벤트의 지속 시간(down_time과 up_time의 차이) - activity: 이벤트가 속한 활동의 범주
- Nonproduction: 이벤트가 텍스트를 변경하지 않음 > Input: 이벤트가 에세이에 텍스트를 추가
- Remove/Cut: 이벤트가 에세이에서 텍스트를 제거 > Paste: 이벤트가 붙여넣기로 텍스트를 변경
- Replace: 이벤트가 텍스트의 일부를 다른 문자열로 교체
- Move From [x1, y1] To [x2, y2]: 텍스트 일부를 이동 - down_event: 키/마우스가 눌릴 때 이벤트의 이름 - up_event: 키/마우스가 해제될 때 이벤트의 이름
- text_change: 이벤트로 인해 변경된 텍스트
- cursor_position: 이벤트 후 텍스트 커서의 문자 인덱스
- word_count: 이벤트 후 에세이의 단어 수
test_logs.csv(6* 11)
- 테스트 데이터로 사용되는 입력 로그 데이터로, train_logs.csv와
동일한 필드를 포함하는 예시 로그 데이터
train_scores.csv(2,471 * 2)
- 에세이의 고유 ID와 에세이가 받은 6점 만점의 점수를 포함하는 학습
데이터의 점수 파일
sample_submission.csv
- test_logs.csv 데이터를 포함하는 실제 평가 시에 사용되는 테스트 세트 데이터
EDA
- action 지속시간, 시작시간 등의 피처에서 이상치 탐지
- 시간을 역행하는 이상치 탐지(1 Case)
- Score 사분위 점수 기준으로 하위 25%, 중위 50%, 상위 25%별 평균값 대체
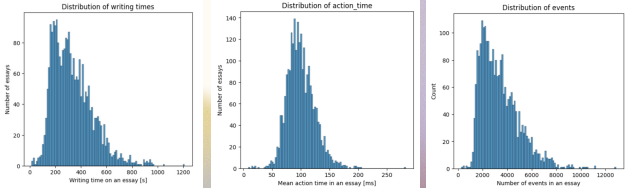
- 데이터 분포가 비대칭한 변수가 많음
- 트리 기반 모델로 학습할 것이기 때문에 스케일링이 필요하지 않다고 판단
- LB와 Train데이터 사이의 분포가 비슷하다는 사실을 발견(Discussion 참조)
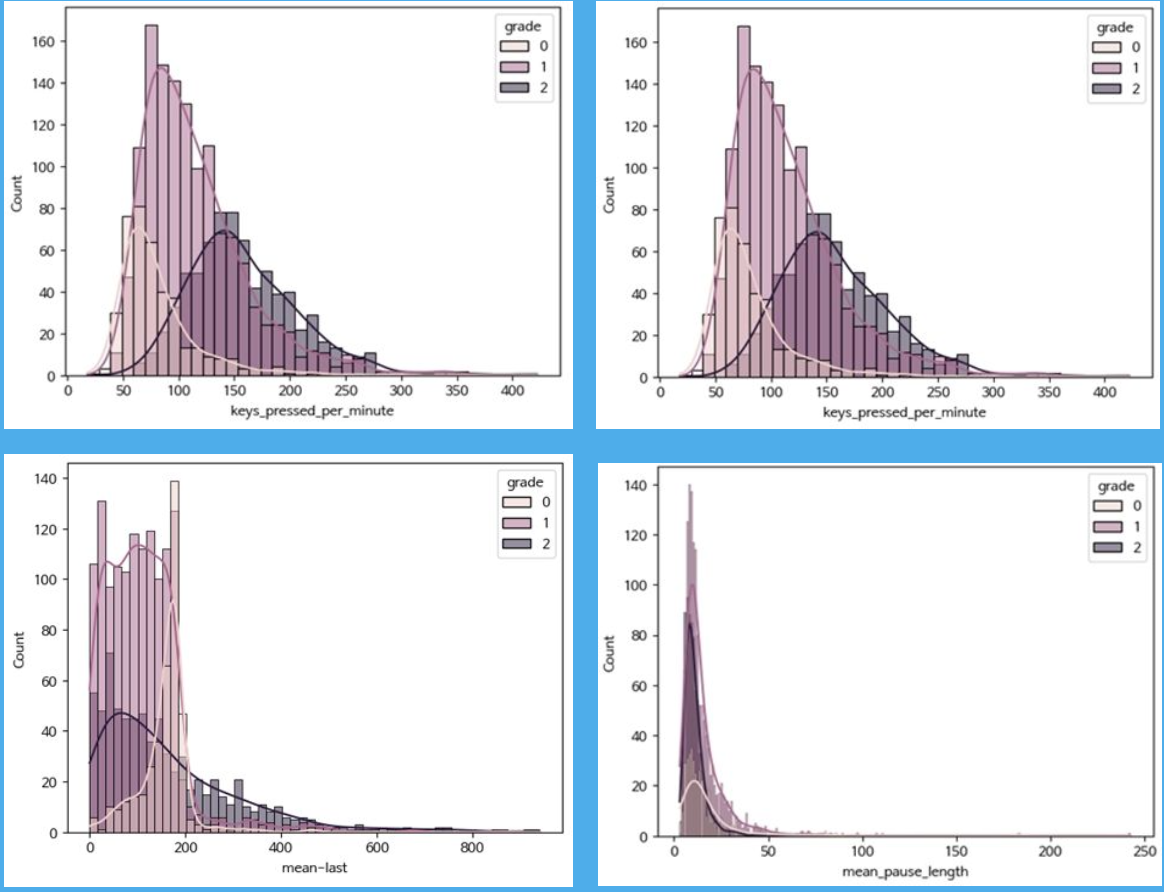
- 글쓰기 점수 상-중-하 grade로 나누어 피쳐 별 패턴 차이 확인
→ 'keys_pressed_per_minute', 'cursor_variance', 'mean_pause_length', 'mean-last(전체 피험자 평균 count word와 피험자 개인의 최종 count word의 차이)’등의 feature에서 grade별 패턴 차이가 나타남
피처 엔지니어링
해당 논문에 기재된 다수의 피쳐들이 이미 여러 공유 노트북들에 구현 완료된 상태
1) Kaggle Competition 공유 노트북 코드, 베이스라인 참고
2) 기타 자료로 부터 추출한 피쳐
[논문1] Uncovering the Writing Process through Keystroke Analyses : 주요 지표 참고
[논문2] A Case Study with Deceptive Reviews and Essays
3) 최종 추가한 피쳐
피쳐 엔지니어링
- 글쓰기 활동(예: 입력, 삭제)의 빈도
- 키보드 및 마우스 이벤트(예: 스페이스, 백스페이스)의 빈도
- 텍스트 변경(예: 문자 추가 또는 삭제)의 빈도
- 구두점의 사용 빈도
- 입력된 단어의 수와 길이에 대한 통계
- 시간 기반 특성, 커서 위치 변화, 단어 수 변화, 통계적 요약, 비율 계산
- 글의 유창성: 전체 피험자 word_count 평균과 최종 제출 시점의 word_count의 차이
- 작성 시간대별 피쳐 차이 확인: 글 작성 시간을 3등분한 후, feature들을 작성 시간 초반(early), 작성 시간 후반(final) 으로 나누어 추가로 생성(feature, feature_early, feature_final)
등등
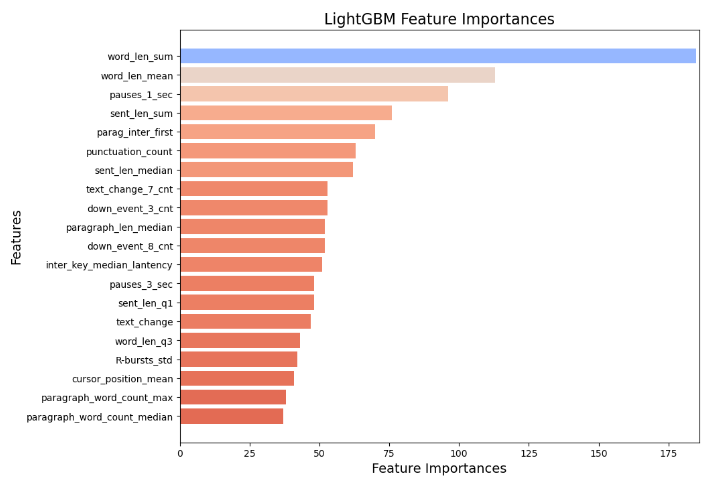
6가지 Feature Selection 수행
피쳐 엔지니어링
- Pearson Correlation: 두 변수 간의 선형 관계를 측정
- Variance Inflation Factor(VIF): 다중 공선성을 평가
- Step Forward Selection: 특성을 하나씩 추가하면서 모델의 성능을 측정하고 최상의 특성
조합을 찾는 방법
- Backward elimination: 가장 덜 중요한 특성을 하나씩 제거하면서 모델의 성능을 측정,
최적의 특성 집합을 찾을 때까지 반복 - Recursive Feature elimination: 모델을 훈련하고 중요도가 낮은 특성을 반복적으로 제거
- Embedded Method: 모델 훈련 과정에서 특성 선택을 수행하는 방법
작은 점수 차이로 나타나는 rmse의 특징 고려,
점수를 올리기 위한 다양한 방법 적용(post processing-calibrati on, label smoothing , seed tuning 등)
모델 개발 및 튜닝
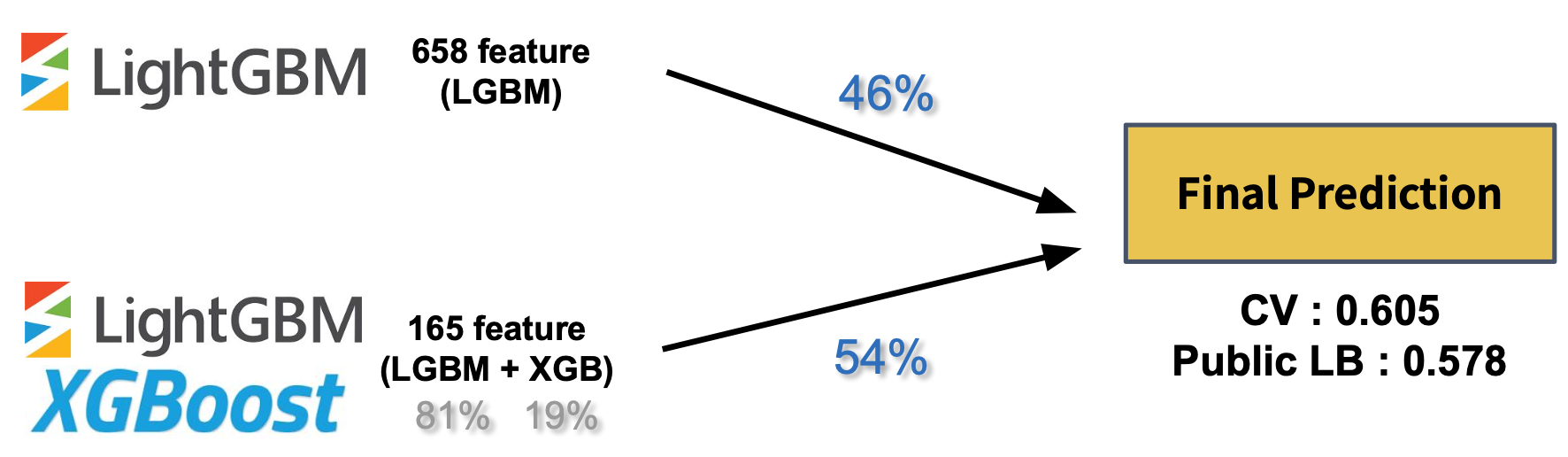
초기 베이스라인 잡을 때의 접근 방식 Public LB: 0.578
- 여기다 neural network 적용 + 타이핑 속도 정규화 관련 피처 20여개 + 중복키 삭제 + 마지막 수정비율 관련 + 커서 이동등 30여개 피처 추가
최종 서브미션 접근 방식 Public LB: 0.576
하이퍼파라미터 최적화
optuna 이용
- Objective 함수 정의
: 최적화할 함수 정의. 모델을 생성하고, Stratified K-Fold 교차 검증을 사용하여 평가한 후, 평균 성능 점수를 반환 - 하이퍼파라미터 공간 정의
: Optuna를 사용하여 튜닝할 하이퍼파라미터의 범위와 타입을 정의 - Optuna Study 생성 및 최적화 실행
: 정의한 목적 함수를 여러 번 호출하여 최적의 하이퍼파라미터를 탐색 - 결과 분석
: 최적화가 끝나면, Optuna는 최적의 하이퍼파라미터 세트와 그 때의 성능 점수 확인. 이후 시각화 도구를 이용하여 하이퍼파라미터의 중요도와 각 하이퍼파라미터가 모델 성능에 미치는 영향들 분석 실시.
모델 평가 및 검증
라벨 불균형 처리
- Stratified kfold를 쓰지만 0.5~6.0 양극으로 치닫을 수록 데이터가 매우 적어짐,
- 전통적인 오버샘플링 방식인
- 0.5, 1점 등 하여 특징을 찾아볼 예정 반대의 경우도 마찬가지)
오버피팅 핸들링
- 대다수 방법론에서 오버피팅 발생 (특성 선택, early stopping, 파라미터 튜닝 등)
- 특히 cv 검증에서 early stopping을 보수적으로 가야한다는 것을 알게됨
* cv에서 early stopping은 지나치게 낙관적인 cv 점수 유발 가능 (LB에서 성능 안좋은 이유)
1) 고정된 estimators 사용
2) nested CV 사용
결론

초기 스타트 나쁘지않았지만 (public 리더보드 상에선 ㅠㅠ)

야무지게 shake up 당해버림 ㅠㅠ
회고
