분류 문제에서는 각 결괏값에 숫자 값을 지정해준다.
예: 꽃의 색이 빨강, 노랑, 보라 -> 빨강: 0, 노랑: 1, 보라: 2
선형 회귀는 이상점(Outlier)에 취약하기 때문에 분류 문제에서는 잘 사용되지 않는다.
로지스틱 회귀(Logistic Regression)
- 지도학습 - 회귀 • 분류
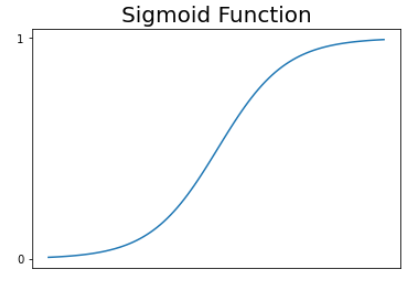
- 데이터에 잘 맞는 시그모이드 함수(Sigmoid Function)를 찾는다.
- 보통 S(x)가 0.5보다 큰지 작은지로 분류한다.
- 로지스틱 회귀는 주로 분류에 사용되지만 시그모이드 함수의 값이 0과 1 사이의 연속적인 값이기 때문에 로지스틱 회귀 라고 부른다.
S(x)=1+e−x1
시그모이드 함수의 특성:
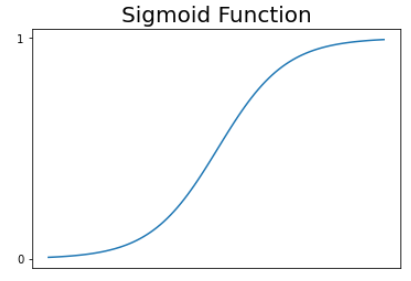
- 0<=S(x)<=1
-> 값이 0과 1 사이이기 때문에 분류에 적합하다.
로지스틱 회귀 가설 함수
gθ(x)=θTx -> S(θTx)=hθ(x)=1+e−θTx1
- 1차 함수 gθ(x)는 치역이 실수 전체이다.
- gθ(x)를 시그모이드 함수를 통해 0<=hθ(x)<=1이 되도록 한다. (결과 범위를 제한한다.)
- θ가 가설 함수에 미치는 영향: x축 이동, 기울기 변화 등
로지스틱 가설 함수의 의미:
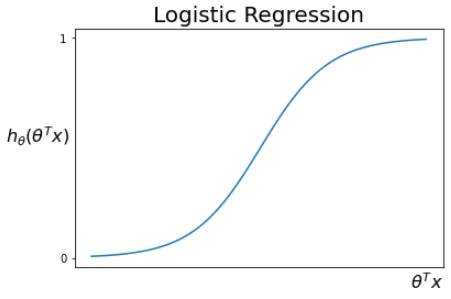
- 통과를 1, 실패를 0으로 했을 때 hθ(x)=0.8이면 통과할 확률이 80%라는 뜻이다.
- 따라서 0.5를 기준으로 통과, 실패를 분류할 수 있다.
- 시그모이드 함수에 θTx(선형 회귀의 가설 함수)가 변수로 들어가기 때문에 선형 회귀에 한 단계가 추가된 방법이라고 생각할 수도 있다.
결정 경계(Decision Boundary)
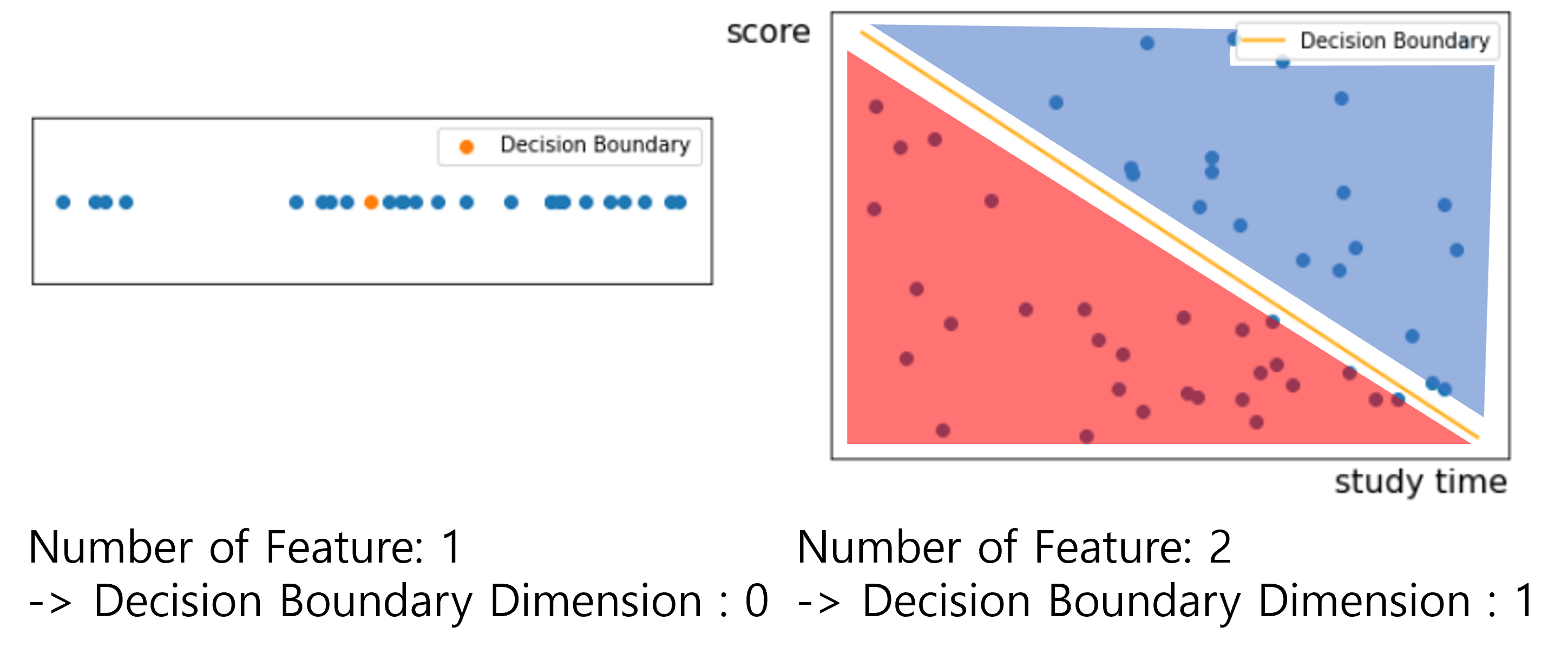
- 분류 문제에서 결과를 나누는 경계를 결정 경계라고 한다.
- N차원을 둘로 나누려면 N-1차원이 필요하다.
- 속성이 1개이면 결정 경계는 0차원
- 속성이 2개이면 결정 경계는 1차원
로그 손실(Log loss / Cross entropy)
logloss(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
아래의 식은 위의 식과 같은 식이지만 보통 위의 방식으로 단위 계단 함수를 사용하여 나타내는 것이 일반적이다.
logloss(hθ(x),y)={−log(hθ(x)) y=1−log(1−hθ(x)) y=0
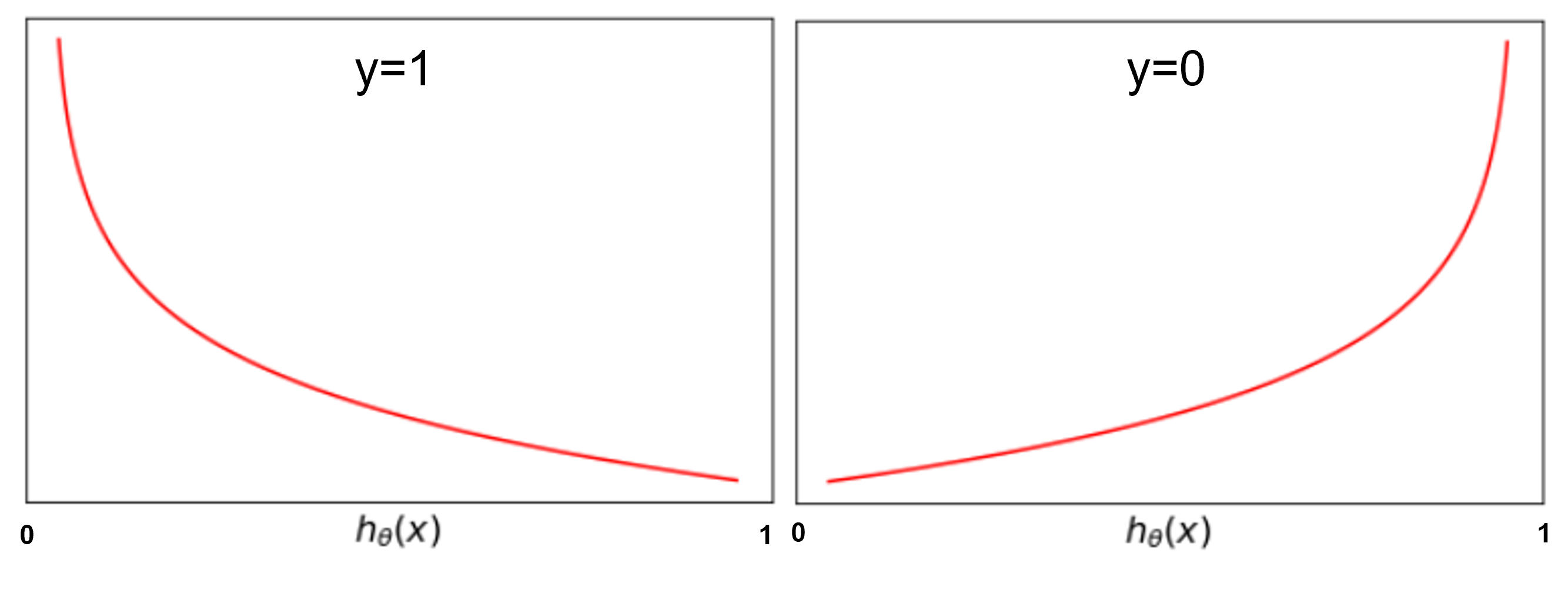
- 손실의 정도를 로그 함수로 나타낸다.
- y=1인 경우 hθ(x)가 1에서 멀어질수록 손실을 키운다.
- y=0인 경우 hθ(x)가 0에서 멀어질수록 손실을 키운다.
로지스틱 회귀에서 MSE(mean squared error)를 사용하지 않는 이유:
- error가 0~1 사이의 값이어서 제곱을 하면 매우 작아 의미가 없어진다.
→ 로그손실 함수를 사용해서 패널티를 키운다.
- 로지스틱 회귀에서 MSE를 사용하면 미분결과가 convex 하지 않아 사용 불가능하다.
로지스틱 회귀 손실 함수
J(θ)=m1i=1∑mlogloss(hθ(x(i)),y(i))
로지스틱 회귀 경사 하강법
θj=θj−α∂θj∂J(θ)=θj=θj−αm1i=1∑m(hθ(x(i))−y(i))⋅xj(i)
- 선형 회귀의 경사 하강법과 같지만 hθ(x)가 다르다.
- hθ(x)=1+e−θTx1 (시그모이드 함수)
θ←θ−αm1XT×error
앞서 언급한 것처럼 로지스틱 회귀의 예측결과는 선형회귀 결과를 시그모이드 함수에 대입한 값과 같으므로
- 예측 결과: sigmoid(Xθ)
- error=sigmoid(Xθ)−y
로지스틱 회귀 다중 분류
- 클래스가 3개 이상인 경우
- 각 클래스에 대한 로지스틱 회귀를 진행한 후 확률이 가장 높은 클래스로 예측한다.
예: 클래스가 A,B,C가 있을 때 (hθ(j)(x)는 j번째 클래스일 확률을 구하는 함수)
- A일 확률을 리턴하는 함수 hθ(0)(x) = 0.37
- B일 확률을 리턴하는 함수 hθ(1)(x) = 0.23
- C일 확률을 리턴하는 함수 hθ(2)(x) = 0.62
이면 C로 예측한다.
소프트맥스 함수(Softmax Function)
- 다중 분류시에 각 클래스별 확률을 의미 있는 결과로 변환하기 위해 사용하는 함수이다.
- 확률의 총합은 1인데 위 예시의 경우 확률의 합이 1이 되지 않는다. 따라서 위의 확률을 그대로 사용하기는 힘들다. ← 이러한 경우에 사용된다.
pj=∑k=1Khθ(k)(x)hθ(j)(x) (K는 클래스의 수)
로지스틱 회귀 정규방정식
- 로지스틱 회귀의 손실함수 J(θ)는 convex 함수이지만, J(θ)의 편미분 대상(θ항)들이 선형적이지 않아서 정규방정식 사용이 불가능하다.
이 글은 코드잇 강의를 수강하며 정리한 글입니다. 더 자세한 설명은 코드잇을 참고하세요
코드잇 머신 러닝