데이터 전처리(Data Preprocessing)
- 데이터를 모델을 학습시키는데 더 좋은 형식으로 가공하는 것
- Feature Scaling : 데이터 크기 조정
- Sampling : 클래스 불균형 문제 해결
- Dimensionality Reduction : 차원 축소
데이터의 종류
- 수치형(numerical) 데이터: 나이, 수입, 인구수 등
- 범주형(categorical) 데이터: 혈액형, 색상, 성별 등
대부분의 머신러닝 알고리즘은 입력 변수가 수치형 데이터여야 한다.
- 범주형 데이터의 경우 수치형 데이터로 변환한다.
Feature Scaling
- 입력 변수(feature)들의 크기를 조정하는 방법
- 경사 하강법을 좀 더 빨리할 수 있도록 돕는다.
min-max normalization
- 데이터의 최소, 최대를 이용하여 데이터내의 변수의 크기를 0과 1 사이로 조정한다.
- : 가공 전 데이터, : 가공 후 데이터, : 각각 데이터의 최솟값, 최댓값
단점: 이상점(Outlier)에 취약하다.
표준화(Standardization)
- 평균(Mean, ):
- 표준편차(Standard Deviation):
- : 가공 전 데이터, : 가공 후 데이터
Feature Scaling과 경사 하강법
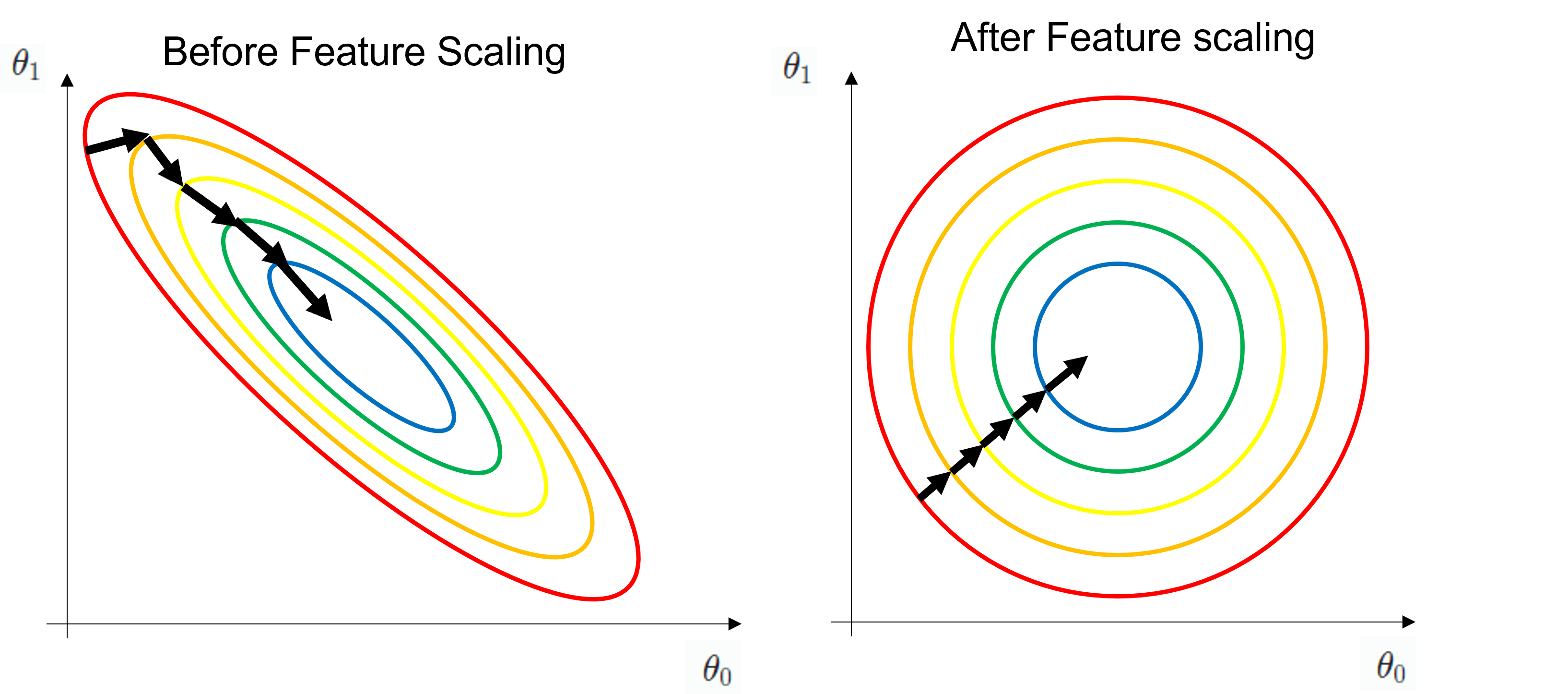
- 특정 지점에서 경사가 가장 급하게 감소하는 방향은 수직 방향이다.
- Feature Scaling을 통해 손실 함수 에서 들이 손실 함수에 미치는 영향이 서로 같아진다. (일반적으로 의 차수가 큰 의 영향력이 크다.)
- 어느 지점에서 경사 하강법을 시작하더라도 항상 수직 방향으로 이동할 수 있게 되고, 손실이 항상 가장 급하게 감소하여 경사 하강법이 빨라진다.
One-hot Encoding
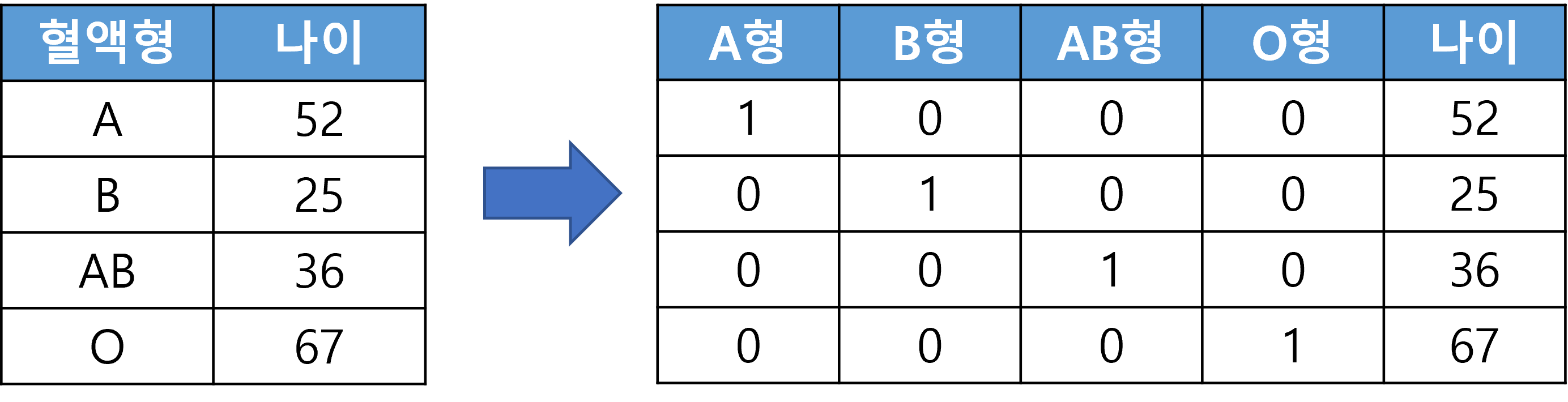
- 범주형 데이터를 수치형 데이터로 변환하는 방법 중 하나
- 클래스의 수만큼 열을 추가하고 데이터가 해당된 클래스만 1, 나머지는 0으로 채운다.
- 범주형 데이터 간의 불필요한 관계(대소 관계)를 만들지 않으면서 수치형 데이터로 바꿀 수 있다.
- 분류가 목적인 수치형 데이터에 대해서도 class가 적다면 적용가능하다.
- 단점: column이 추가되면서 데이터가 커지는 단점이 있다.
범주형 데이터를 굳이 인코딩 하는 이유
범주형 데이터를 단순 수치형 데이터로 변환할 경우 범주형 데이터 간에 불필요하게 크고 작음 이라는 개념이 생겨서 예측에 방해가 될 수 있다.
이 글은 코드잇 강의를 수강하며 정리한 글입니다. 더 자세한 설명은 코드잇을 참고하세요

미래의 개발자입니다!