Spark
1.[Spark] Spark?
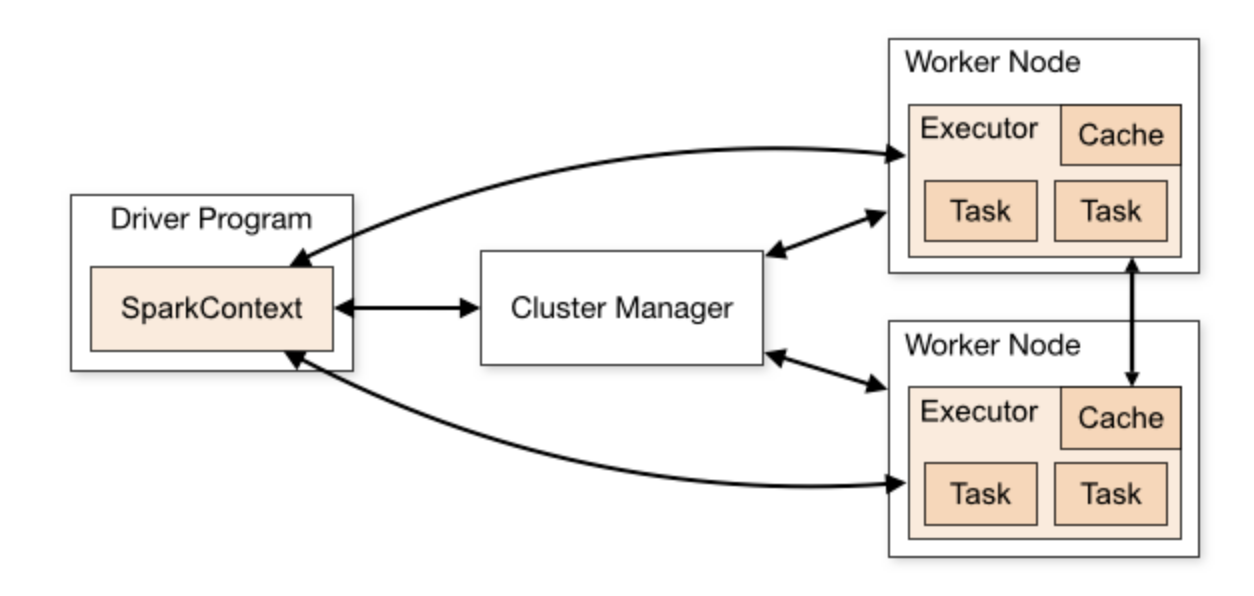
Spark는 기본적으로 메모리 기반메모리가 부족해지면 디스크사용분산 컴퓨터 환경 지원배치 프로그래밍, 스트리밍 프로그래밍, SQL, 머신 러닝, 그래프 분석 등의 서비스 지원드라이버 프로그램의 존재클러스터 매니저를 통해 데이터를 워크노드에 분산시켜줌RDD(Resilie
2.[Spark] 데이터프레임, 데이터셋, RDD

Spark 세션을 만드는 것이 Spark 프로그램의 시작appName을 통해 세션의 이름을 정하고.config를 통해 세션에 적용할 세부적인 옵션을 다룸.getOrCreate() 는 appName을 보고 기존에 같은 내용이 있으면 get 하고 없으면 create해줌로우
3.[Spark] 데이터프레임 생성
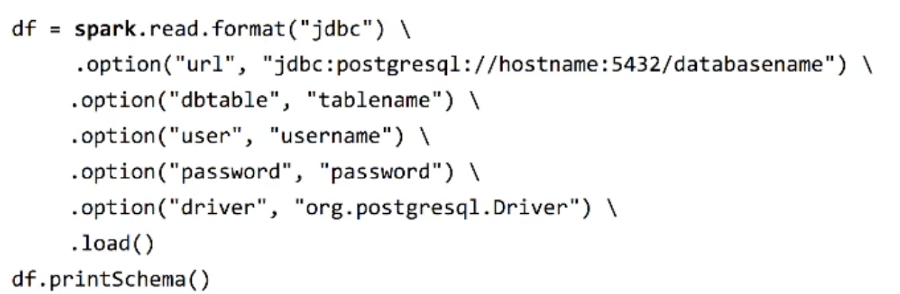
RDD를 변환해서 생성: RDD의 toDF 함수 사용SQL 쿼리를 기반으로 생성\- tablename 자리에 SELECT 문도 사용 가능외부 데이터를 로딩해 생성\- createDataFramepostgresql 데이터를 가져와서 각 옵션을 통해 데이터 프레임을 로드해
4.[Spark] colab에서 스파크 세션 열기
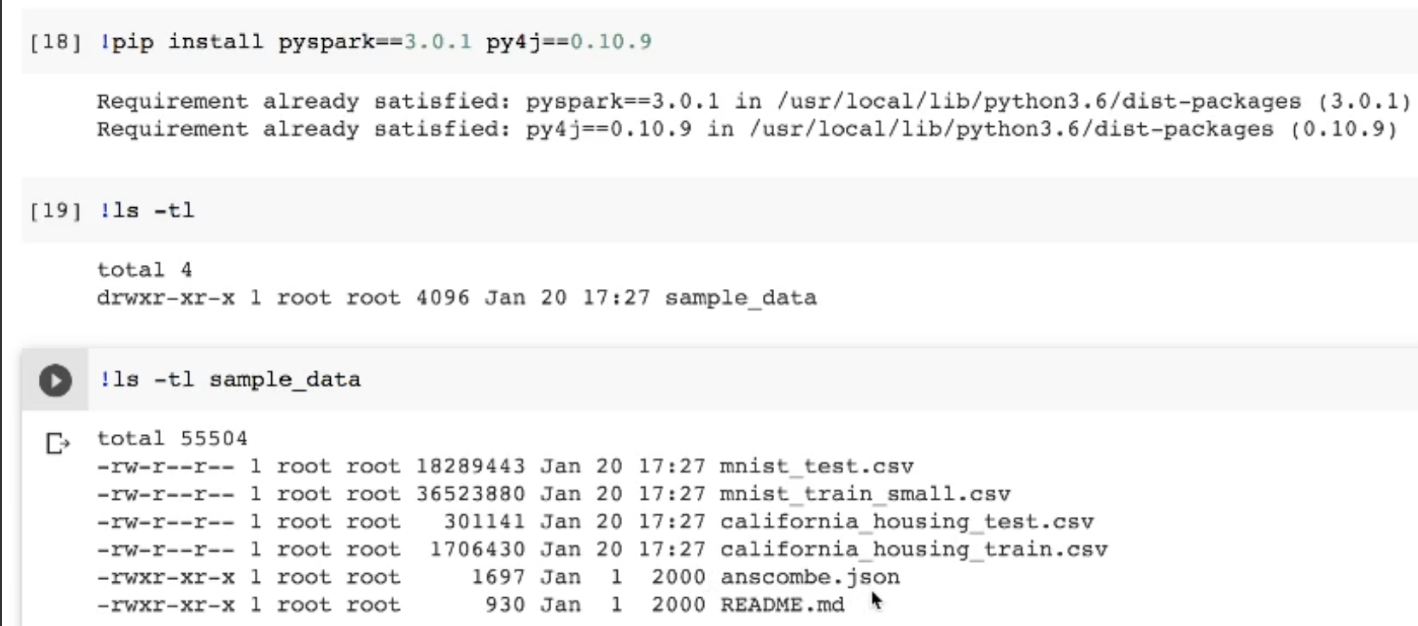
pyspark,py4j를 설치해줌설치 후 로컬스토리지 확인하면 샘플데이터가 설치됨기본적으로 깔리는 csv 들이 있음마스터에 local\[\*]은 코어를 얼마나 사용할지 설정\* 표시를 두면 전부를 사용하는 것, 숫자를 지정하면 숫자만큼의 코어를 사용하겠다는 설정앱네임을
5.[Spark] Spark Mlib

Classfication, Regression, Clustering, Collaborative Filtering, Dimensionality, Reduction 등딥러닝 분야는 아직 약함spark.mlib가 RDD기반spark.ml은 데이터프레임 기반spark.mlib
6.[Spark] Spark를 이용한 보스턴 주택 가격 예측 모델 제작

파이썬 스파크를 위해 pyspark 설치해주고자바가상머신상 오브젝트를 사용하기 위해 py4j 설치해줌(파이썬 for JAVA)앱네임을 설정해 세션을 설치만들어진 세션 정보 트레이닝할 정보가 담긴 csv를 다운받음다운받은 csv 잘 위치하는지 확인다운받은 csv를 spa
7.[Spark] Spark를 이용해 타이타닉 생존 예측 모델 만들기

파이스파크, 파이포차바 설치세션 네임 정해주고 만들어줌타이타닉 데이터 다운받기데이터 csv를 읽어옴스키마를 살펴봄데이터 상세 정보를 볼 수 있음각 컬럼별 수치정보들을 알 수 있음과도하게 높거나 낮은 수치로 평균값이 치우친건 아닌지분포도가 어떻게 나타나는지를 살펴볼 수
8.[Spark] Spark MLlib 피쳐 변환

피쳐 값들을 모델 훈련에 적합한 형태로 바꾸는 것피처 값들은 숫자 필드이어야만 함그렇기에 텍스트 필드(카테고리 값들)를 숫자 필드로 변환해야 함숫자 필드 값의 범위 표준화숫자 필드라고 해도 가능한 값의 범위를 특정 범위로 변환해야함(0부터 1)피쳐 스케일링, 혹은 정규
9.[Spark] Spark MLlib ML Pipeline
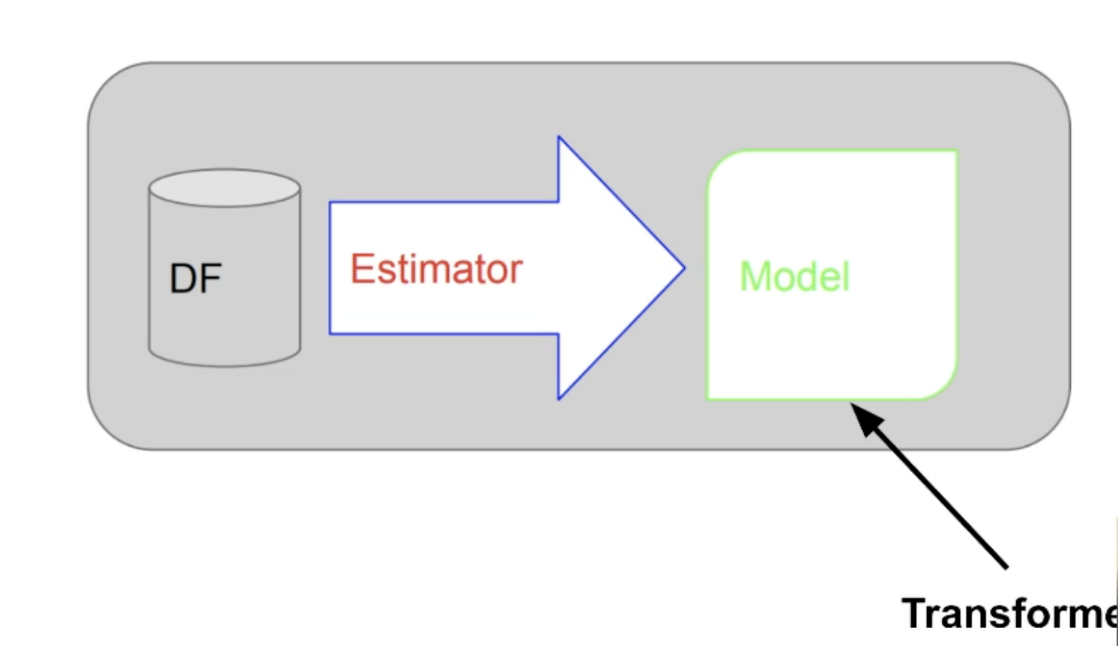
트레이닝 셋의 관리가 안됨모델 훈련 방법이 기록이 안됨모델 훈련에 많은 시간 소요모델 훈련이 자동화가 안된 경우 매번 각 스텝들을 노트북 등에서 일일히 수행에러가 발생할 여지가 많음(휴먼오류?)앞서 언급한 문제들 중 2, 3번을 해결가능자동화를 통해 에러 소지를 줄이고
10.[Spark] ML Pipeline
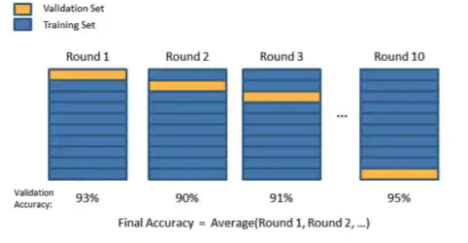
하나씩 테스트? 다수를 동시 테스트?교차검증, 홀드 아웃 등 스파크에서 제공하는 테스트 방법으로 테스트파이프라인이 다수를 동시에 테스트 하는 것을 수월하게 해줌교차 검증: CrossValidator훈련/테스트셋 나누기: TrainValidationSplithttps&#
11.[Spark] ML Pipeline 만들기
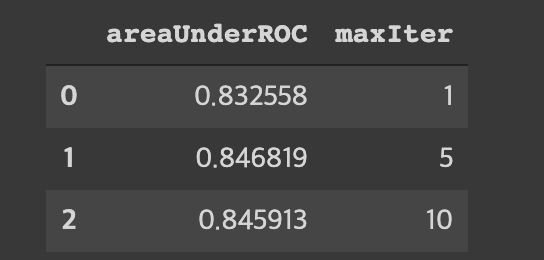
전처리에 사용했던 피처 관련 라이브러리를 스테이지에 어레이 형태로 모아줌파이프라인에 사용할 알고리즘 모델도 어레이에 넣어줌스파크가 제공하는 파이프라인에 모아둔 어레이를 스테이지 인자로 넘겨줌훈련에 사용할 컬럼들을 골라주고 트레인, 테스트셋 만들어줌만든 파이프라인에 트레