피쳐 추출과 변환
- 피쳐 값들을 모델 훈련에 적합한 형태로 바꾸는 것
Feature Transformer
- 피처 값들은 숫자 필드이어야만 함
- 그렇기에 텍스트 필드(카테고리 값들)를 숫자 필드로 변환해야 함
- 숫자 필드 값의 범위 표준화
- 숫자 필드라고 해도 가능한 값의 범위를 특정 범위로 변환해야함(0부터 1)
- 피쳐 스케일링, 혹은 정규화라고 함
- 비어있는 필드들의 값을 어떻게 채울 것인가?
Feature Extractor
- 기존 피쳐에서 새로운 피쳐를 추출
- TF-IDF, Word2Vec 등 많은 경우 텍스트 데이터를 어떤 형태로 인코딩하는 것이 여기에 해당
피쳐 변환(Feature Transformer)
StringIndexer

-
스트링 데이터를 종류에 맞게 숫자로 변환
-
Scikit-Learn은 sklearn.preprocessing 모듈 아래 여러 인코더 존재
- OneHotEncoder, LabelEncoder, OrdinalEncoder... -
Spark MLlib의 경우 pyspark.ml.feature 모듈 밑에 두 개의 인코더 존재
- StringIndexer, OneHotEncoder -
예시
from pyspark.ml.feature import StringIndexer
gender_indexer = StringIndexer(inputCol="Gender", outputCol="GenderIndexed")
gender_indexer_model = gender_indexer.fit(final_data)
final_data_with_transformed_gender_gender = gender_indexer_model.transform(final_data)Scalar
MinMaxScalar
- 모든 값을 0과 1사이로 스케일, 각 값에서 최소값을 빼고 (최대값-최소값)으로 나눔
StandardScaler
- 각 값에서 평균을 빼고 이를 표준편차로 나눔. 값의 분포가 정규분포를 따르는 경우 사용
Imputer
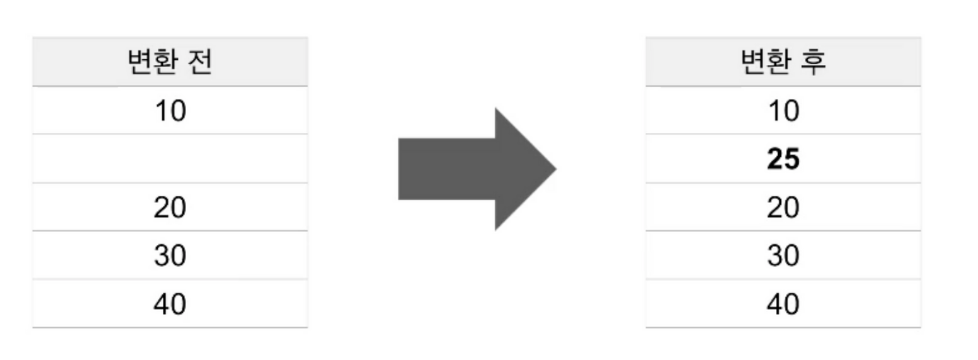
from pyspark.ml.feature import Imputer
imputer = Imputer(strategy='mean, inputCols=['Age'], outputCols=['AgeImputed'])
imputer_model = imputer.fit(final_data)
final_data_age_transformed = imputer_model.transform(final_data)- Imputer 모델을 만들고 Imputer모델로 데이터프레임을 transform

컴퓨터가 좋아