세션 셋팅 및 설치
!pip install pyspark==3.0.1 py4j==0.10.9 - 파이스파크, 파이포차바 설치
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Titanic Binary Classification example") \
.getOrCreate()- 세션 네임 정해주고 만들어줌
타이타닉 생존 예측 모델 만들기
데이터 불러오기
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/titanic.csv- 타이타닉 데이터 다운받기
data = spark.read.csv('./titanic.csv', header=True, inferSchema=True)
data.printSchema()
- 데이터 csv를 읽어옴
- 스키마를 살펴봄
data.show()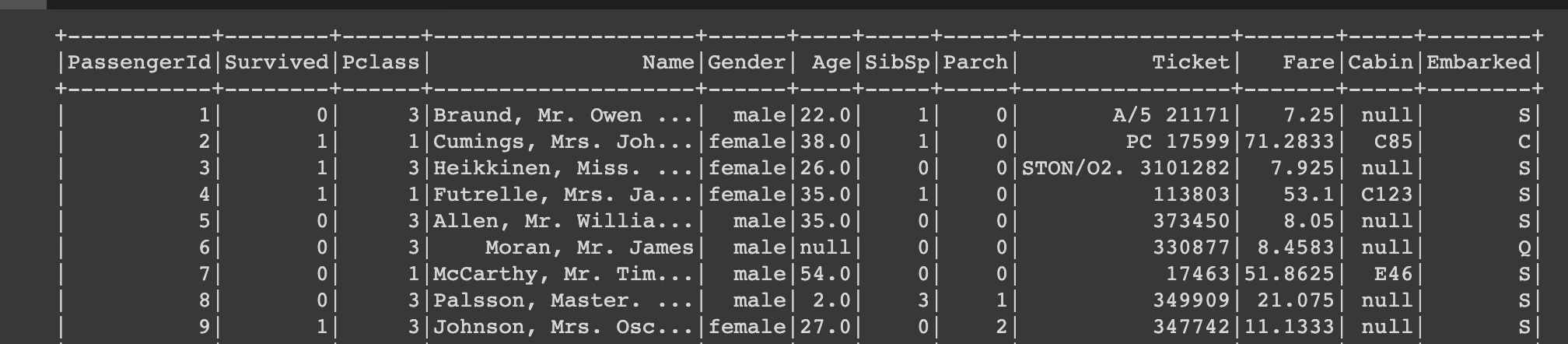
- 데이터 상세 정보를 볼 수 있음
data.select(['*']).describe().show()
- 각 컬럼별 수치정보들을 알 수 있음
- 과도하게 높거나 낮은 수치로 평균값이 치우친건 아닌지
- 분포도가 어떻게 나타나는지를 살펴볼 수 있음
데이터 클렌징
비어있는 곳 평균값으로 채우기
from pyspark.ml.feature import Imputer
imputer = Imputer(strategy='mean', inputCols=['Age'], outputCols=['AgeImputed'])
imputer_model = imputer.fit(final_data)
final_data = imputer_model.transform(final_data)- Imputer를 사용해 평균값으로 Age 컬럼에 있는 널값을 채워 AgeImputed 컬럼으로 복사해줌
final_data.select("Age", "AgeImputed").show()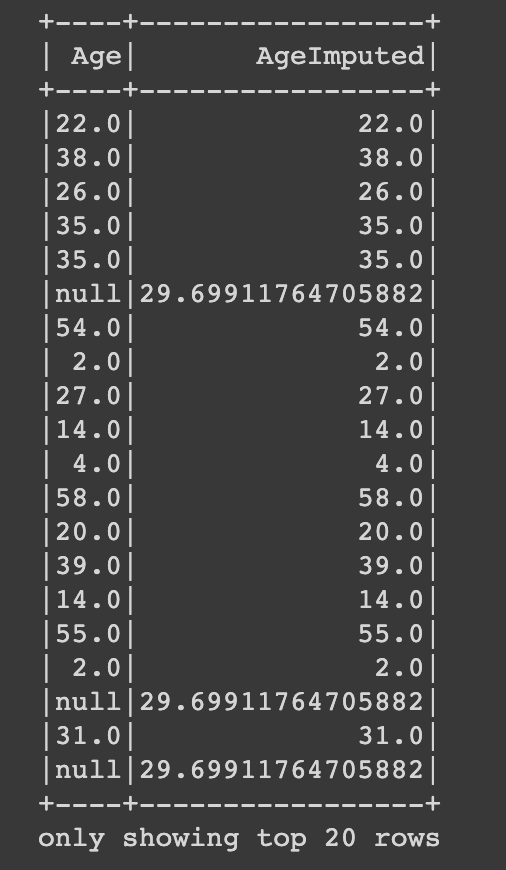
- null 값이 평균값으로 채워진걸 알 수 있음
스트링 정보를 숫자화하기
from pyspark.ml.feature import StringIndexer
gender_indexer = StringIndexer(inputCol='Gender', outputCol='GenderIndexed')
gender_indexer_model = gender_indexer.fit(final_data)
final_data = gender_indexer_model.transform(final_data)- StringIndexer는 선택한 컬럼에 있는 수치들을 보고 단순히 종류들을 수치화 하는 도구
- 수치의 높낮이가 실제 중요도를 나타내지 않음
- 현재 남, 여 이진 분류에 사용하기 때문에 크게 지장 없음
final_data.select("Gender", "GenderIndexed").show()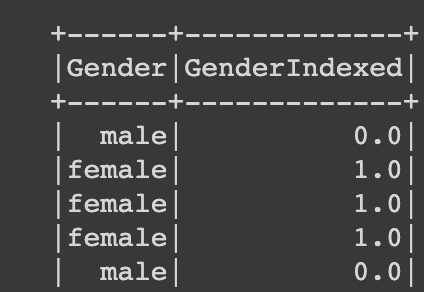
- 성별이 1과 0으로 구분됐음
피쳐 벡터 만들기
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=['Pclass', 'SibSp', 'Parch', 'Fare', 'AgeImputed', 'GenderIndexed'], outputCol='features')
data_vec = assembler.transform(final_data)- 필요 없는 컬럼을 제외한 컬럼을 모아 벡터화 시키고 테이블에 추가해줌
훈련용, 테스트용 데이터 나누고 사용할 모델 지정
train, test = data_vec.randomSplit([0.7, 0.3])
from pyspark.ml.classification import LogisticRegression
algo = LogisticRegression(featuresCol="features", labelCol="Survived")
model = algo.fit(train)- 7:3 으로 훈련, 테스트 셋을 나눠주고
- 로지스틱회귀 알고리즘을 적용해 모델을 학습시킴
모델 성능 측정
predictions = model.transform(test)
predictions.select(['Survived','prediction', 'probability']).show()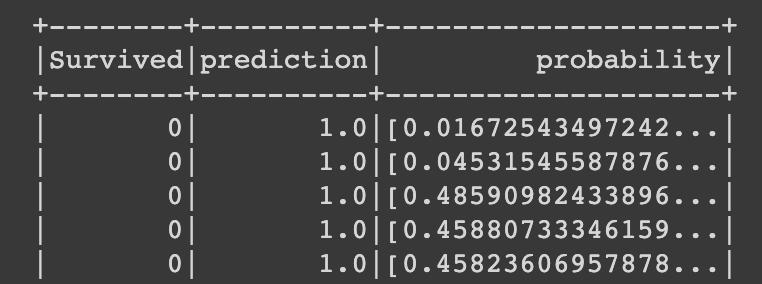
- 테스트를 통한 예측정보를 만들어주고 실제 결과값을 비교
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(labelCol='Survived', metricName='areaUnderROC')
evaluator.evaluate(predictions)- 이진분류 평가 계산기를 활용해 정확도를 예측할 수 있음

컴퓨터가 좋아