오늘 리뷰할 논문은 YOLOv4 논문이다.
다음 포스트를 먼저 보면 도움이 될 것이다.
- YOLO v4 논문(YOLOv4: Optimal Speed and Accuracy of Object Detection) 리뷰
- YOLOv4:Optimal Speed and Accuracy of Object Detectionf Review
- [YOLOv4 리뷰] Optimal Speed and Accuracy of Object Detection (arXiv 20)
Summary
CNN 정확도를 향상시키는 여러 방법 중 일부는 모델/문제/데이터셋에 특이적이지만 batch normalization이나 residual connection 같은 일부는 대부분 모델/문제/데이터셋에 적용 가능하다. 논문은 그런 universal feature로 Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT), Mish-activation를 사용한다. WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, CmBN, DropBlock regularization, CIoU loss 중 일부를 조합해 SOTA를 달성한다.
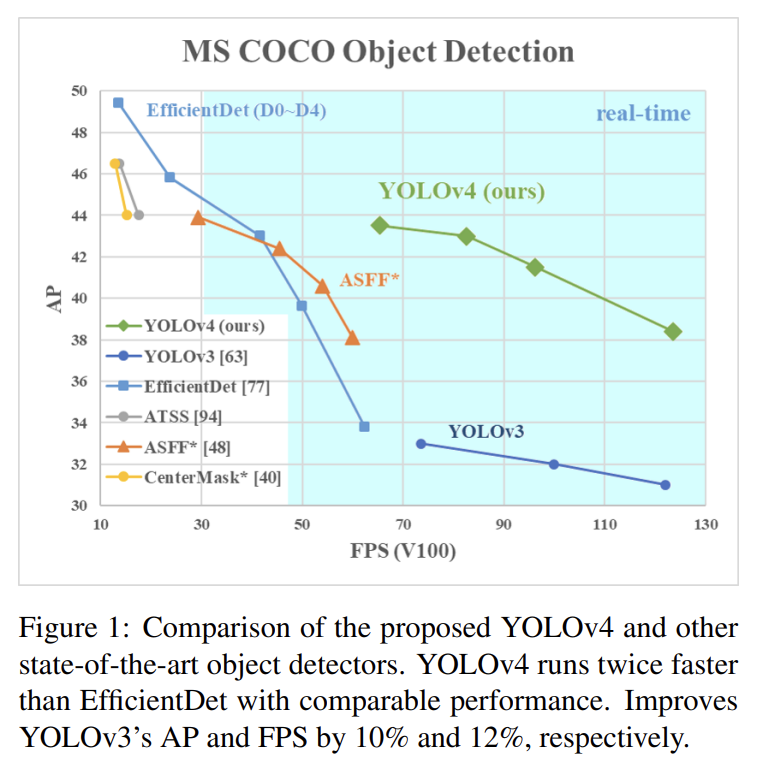
논문은 학습에 conventional GPU 1개만 필요하고 실시간으로 작동할 수 있는 CNN을 만들고자 한다. 논문의 주요 목표는 낮은 computation volume theoretical indicator (BFLOP)보다는 production systems 내에서 object detector의 빠른 속도와 parallel computations을 위한 최적화다.
논문의 기여는 다음과 같다.
- 효율적이고 강력한 object detection model을 개발한다. 모든 사람이 1080 Ti나 2080 Ti GPU 를 사용해 아주 빠르고 정확한 object detector를 학습할 수 있다.
- detector training 중 object detection의 SOTA Bag-of-Freebies와 Bag-of-Specials 방법들의 영향을 입증한다.
- CBN, PAN, SAM을 포함하는 SOTA 방법들을 수정하여 single GPU training에 적합하게 효율적으로 만든다.
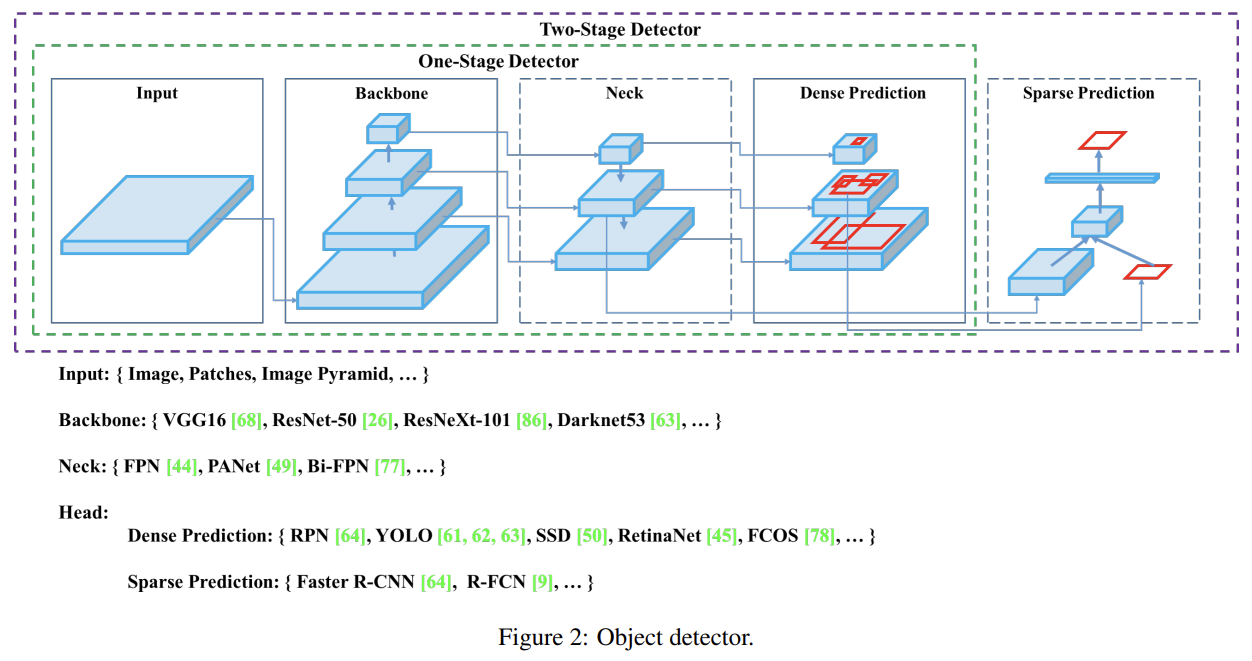
(Related work가 survey처럼 되어 있어서 부분부분 생략하겠다)
연구자들은 inference cost를 증가시키지 않고 더 좋은 정확도를 얻는 training method를 개발한다. 이렇게 training strategy만 바꾸거나 training cost만 증가시키는 방법을 “bag of freebies”라고 부른다. 그 중 하나가 data augmentation이다.
다른 bag of freebies 방법은 데이터셋 내 semantic distribution가 bias를 가질 때 사용된다. 서로 다른 classes 간 데이터 불균형이 존재하는 문제는 two-stage object detector에서 hard negative example mining [72]이나 online hard example mining [67]으로 흔히 해결된다. 그러나 example mining method은 one-stage object detector에 적용이 불가능한데, one-stage object detector는 dense prediction architecture에 속하기 때문이다. 따라서 Lin et al. [45]은 classes 간 데이터 불균형을 다루기 위해 focal loss를 제안했다. 또 다른 중요한 문제는 one-hot hard representation을 가지고는 서로 다른 categories 사이 연관성(association)의 정도(degree)의 관계를 표현하기 힘들다는 것이다. 이 resentation scheme은 흔히 labeling을 실행할 때 사용된다. label smoothing [73]은 hard label을 soft label로 전환해 model을 robust하게 한다.
마지막 bag of freebies는 Bounding Box (BBox) regression의 objective function이다. 전통적인 object detector는 보통 Mean Square Error (MSE)를 사용해 좌표나 (anchor-based method의 경우) offset을 직접 regress했다. 그러나 BBOX의 각 point의 좌표값을 직접 추정하는 것은 이 points를 독립적인 변수로 간주하는 것이며, object 그 자체의 integrity를 고려하지 않는 것이다. 이 문제를 더 잘 처리하기 위해 최근엔 predicted BBox area와 ground truth BBox area의 coverage를 고려하는 IoU loss를 사용한다.
inference cost을 약간 증가시키지만 object detection 정확도를 상당히 향상시키는 plugin modules과 post-processing methods을 “bag of specials”라고 부른다. 일반적으로 말해서 plugin modules는 receptive field를 확대하거나 attention mechanism을 도입하거나 g feature integration capability를 강화하는 등 모델 내 특정 attributes를 향상시키는 것이고 post-processing은 model prediction results을 가리기(screen) 위한 방법이다.
receptive field를 확대하기 위한 일반적인 modules는 SPP [25], ASPP [5], RFB [47]이다. object detection에 흔히 사용되는 attention module은 channel-wise attention과 point-wise attention으로 구분되고 각각 Squeeze-and-Excitation (SE) [29]와 Spatial Attention Module (SAM) [85]이 대표적이다.
feature integration의 경우 low-level physical feature를 high-level semantic feature에 통합하기 위해 초기에는 skip connection [51]이나 hyper-column [22]을 사용했다. FPN 같은 multi-scale prediction methods가 유행한 이후 서로 다른 feature pyramid를 통합하는 많은 lightweight modules이 제안되었다.
많은 추가적인 연산량을 유발하지 않으면서 gradient가 더 효과적으로 전파되는 좋은 activation function도 연구가 되어왔다. ReLU 이래 LReLU [54], PReLU [24], ReLU6 [28], Scaled Exponential Linear Unit (SELU) [35], Swish [59], hard-Swish [27], Mish [55] 등이 gradient vanish problem을 해결하기 위해 제안되었다.
deep-learning-based object detection에서 흔히 사용되는 post-processing method는 NMS이다. (중략) 위의 post-processing methods는 captured image features를 직접 참조하며, 차후의 anchor-free method의 발달에서 post-processing은 더이상 필요하지 않다.
목표는 low computation volume theoretical indicator (BFLOP)보다는 production systems 내에서 빠른 operating speed와 parallel computations을 위한 optimization이다. real-time neural network의 2가지 옵션을 제안한다.

- Selection of architecture
목표는 input network resolution, convolutional layer 수, parameter 수 (), layer outputs (filters)의 수 사이 최적의 균형을 찾는 것이다. 다음 목표는 receptive field를 증가시키기 위한 additional blocks를 선택하고 다른 detector levels에 대한 여러 backbone levels 중에서 가장 좋은 parameter aggregation 방법을(예컨대 FPN, PAN, ASFF, BiFPN) 선택하는 것이다.
classification에 최적인 reference model이 항상 detector에도 최적인 것은 아니다. classifier와 대조적으로 detector는 다음을 요구한다.

이론적으로 larger receptive field size을 가지고(많은 convolutional layers 3 × 3을 가진) parameters 수가 많은 모델이 backbone으로 적합하다고 가정할 수 있다. 이론적 정당화와 많은 실험이 CSPDarknet53 neural network가 detector를 위한 backbone으로 최적의 모델임을 보여준다.

다양한 크기를 가진 receptive field의 효과는 다음과 같다.

CSPDarknet53에 SPP block을 추가하는데 이는 receptive field를 상당히 증가시키고 가장 중요한 context features를 분리시키고 network operation speed가 거의 감소하지 않기 때문이다. YOLOv3에서 사용한 FPN 대신 PANet을 (서로 다른 detector levels에 대한 여러 backbone levels로부터) parameter aggregation 방법으로 사용한다.
최종적으로 CSPDarknet53 backbone, SPP additional module, PANet path-aggregation neck, YOLOv3 (anchor based) head를 YOLOv4의 architecture로 선택한다.
- Selection of BoF and BoS
object detection training을 향상시키기 위해 CNN은 보통 다음을 사용한다.

activation function의 경우 PReLU와 SELU는 학습이 어렵고 ReLU6는 quantization network를 위해 특이적으로 디자인되었기 때문에 이들은 후보에서 제외한다. regularization의 경우 DropBlock을 발표한 사람이 다른 방법과 많이 비교해서 많이 이겼기 때문에 DropBlock을 선택했다. normalization의 경우 하나의 GPU만 사용하는 training strategy에 집중하기 때문에 syncBN은 고려하지 않는다.
- Additional improvements
디자인한 detector가 single GPU training에 더 적합하기 위해 추가적으로 다음과 같이 개선했다.

Mosaic는 4 training images를 섞는 새로운 data augmentation 방법이다. 따라서 (CutMix는 2 input images만 섞는 반면) 4개 다른 contexts가 섞인다. 이는 일반적인 context 바깥의 objects의 detection을 가능하게 한다. 추가로 batch normalization은 각 layer에서 4개 다른 images로부터 activation statistics를 계산한다. 이는 큰 mini-batch size에 대한 필요를 상당히 감소시킨다.
Self-Adversarial Training (SAT)는 2 forward backward stages에서 작동하는 새로운 data augmentation 기술이다. 첫 단계에서 네트워크는 network weights 대신 original image를 변경한다. 이를 통해 네트워크는 스스로에게 adversarial attack을 실행하고 image에 desired object가 없다는 기만(deception)을 생성하기 위해 original image를 변경한다. 두 번째 단계에서 네트워크는 평범한 방식으로 이 수정된 image에서 object를 감지하도록 학습된다.
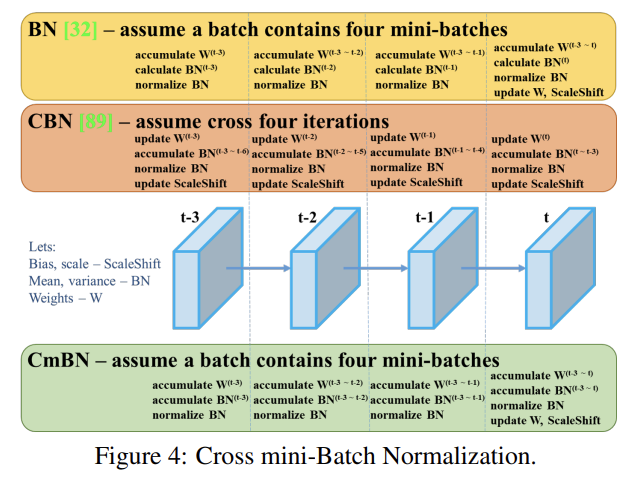
Fig 4에서 볼 수 있듯 Cross mini-Batch Normalization (CmBN)은 CBN modified version을 나타낸다. 이는 single batch 내의 mini-batches 사이에서만 statistics를 수집한다.
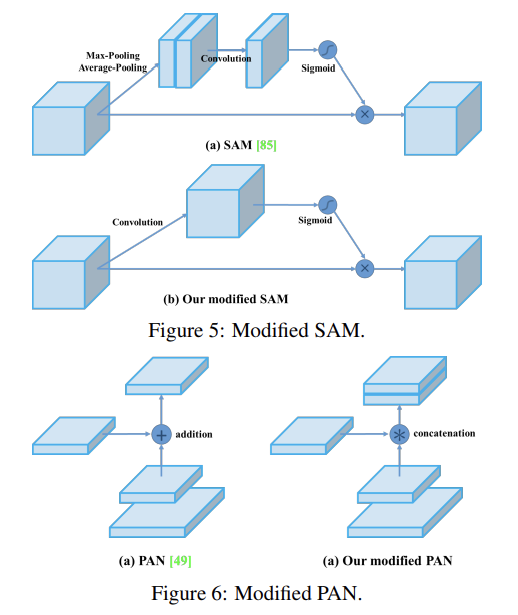
Fig 5, Fig 6에 나와있듯 SAM을 spatial-wise attention에서 point-wise attention으로 수정하고 PAN의 shortcut connection을 concatenation으로 대체한다.

YOLOv4 세팅은 위와 같다. 여러 training improvement techniques의 효과를 ImageNet (ILSVRC 2012 val) dataset에 classifier의 정확도와 MS COCO (test-dev 2017) dataset에 detector의 정확도로 평가한다.

첫째로 classifier training에서 여러 features의 영향을 연구한다. 구체적으로는 Class label smoothing, data augmentation techniques와 activations의 효과를 연구한다.


Tab 2에서 알 수 있듯 classifier의 정확도는 CutMix와 Mosaic data augmentation, Class label smoothing, Mish activation과 같은 features를 도입함으로써 향상되었다. 결과적으로 classifier training에 대한 BoF-backbone (Bag of Freebies)은 CutMix data augmentation, Mosaic data augmentation과 Class label smoothing을 포함한다. 추가로 (Tab 2, Tab 3에서 알 수 있듯) Mish activation을 상호보완적인 옵션으로 사용한다.
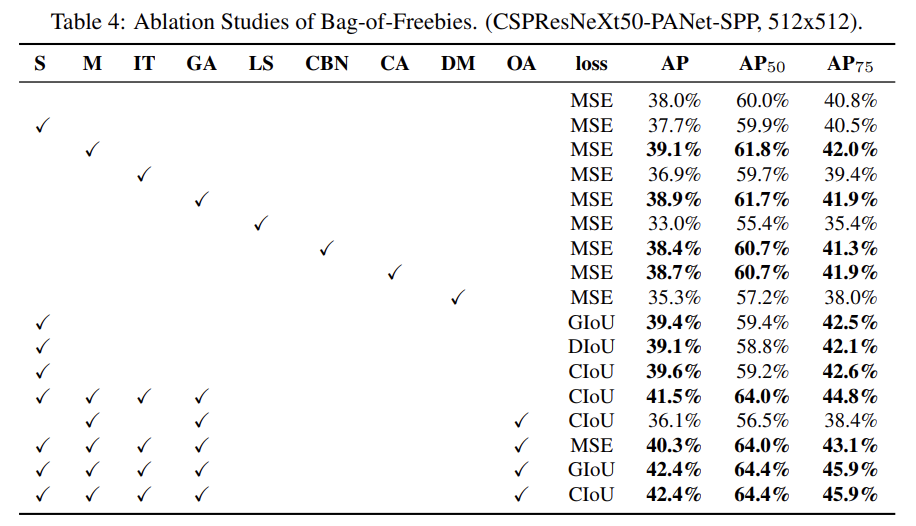
Tab 4는 detector training accuracy에 여러 Bag-of-Freebies (BoF-detector)의 효과를 연구한다. FPS에 영향을 주지 않고 detector 정확도를 증가시키는 여러 features를 연구함으로써 BoF list를 확장한다.

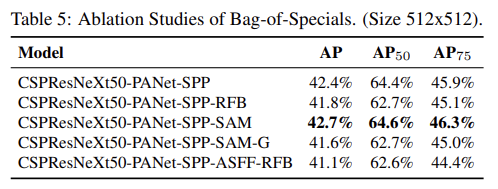
Tab 5에서 볼 수 있듯 추가 연구는 PAN, RFB, SAM, Gaussian YOLO (G), ASFF을 포함하는 여러 Bag-of-Specials (BoS-detector)의 효과를 detector training accuracy에 평가한다. 실험에서 detector는 SPP, PAN, SAM을 사용할 때 최고의 성능을 발휘한다.
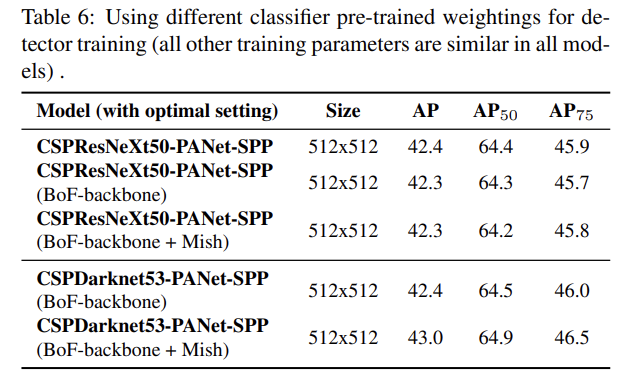
detector accuracy에 여러 backbone models의 효과를 연구한다. classification accuracy가 가장 좋은 모델이 detector accuracy도 최고인 건 아님을 발견했다.
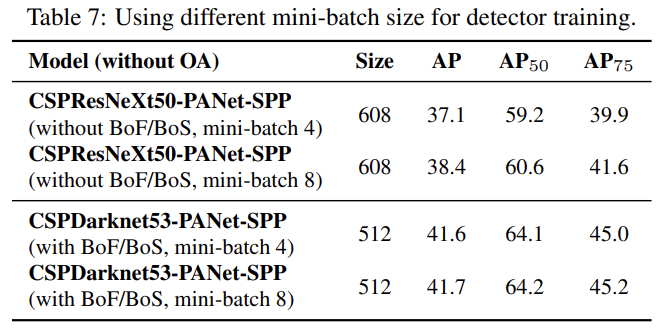
서로 다른 mini-batch sizes로 학습된 models의 결과를 분석했다. BoF와 BoS training strategies를 추가한 후 mini-batch size는 detector 성능에 거의 영향을 끼치지 못했다. 이는 BoF와 BoS 도입 이후 학습에 더이상 비싼 GPU가 필요하지 않다는 것이다.
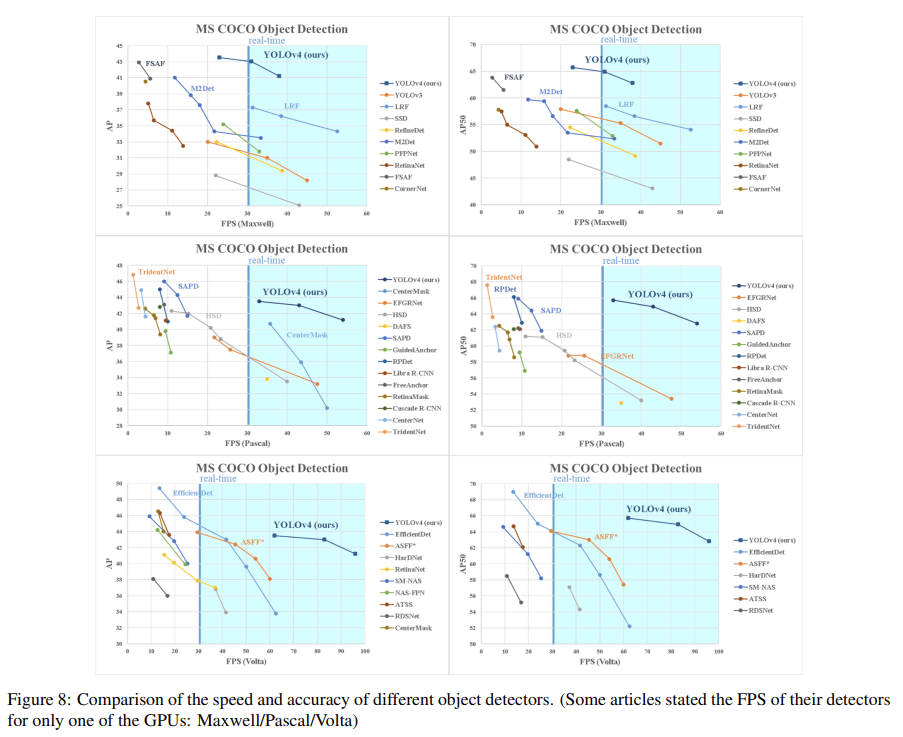
Fig 8은 다른 SOTA object detectors와 비교한 결과다.
Strengths
- 기발한 아이디어를 냈다기 보다는 기존의 여러 기술들을 조합해서 가장 빠르고 정확하면서 단일 GPU로 학습할 수 있는 모델을 만들었다.
여러 기술을 소개하고 시험해서 약간 survey 논문 같은 느낌이 들었다.
