오늘 리뷰할 논문은 YOLOv3 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
Summary
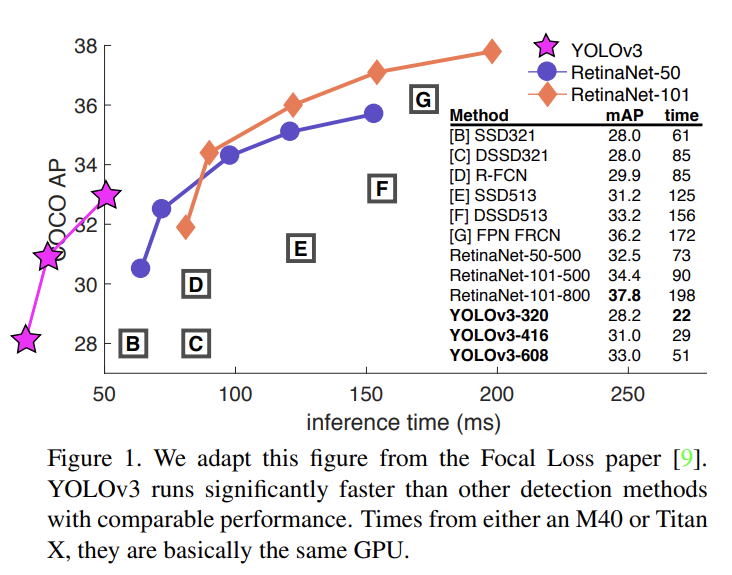
논문은 YOLO를 발전시켰다. 저번(YOLOv2)보다 약간 크지만 더 정확하고 여전히 빠르다. 320 × 320에서 YOLOv3는 SSD처럼 정확하지만 3배 빠르다. old .5 IOU mAP detection metric으로는 RetinaNet과 비슷한 성능이지만 3.8배 빠르다.
YOLO9000을 따라 YOLOv3는 dimension clusters를 anchor boxes로 삼아 bounding boxes를 예측한다. 네트워크는 각 bounding box에 대해 4개의 좌표 tx, ty, tw, th를 예측한다. cell이 image의 좌상단 구석에서 (cx, cy)만큼 offset이고 bounding box prior이 pw, ph의 width, height을 가진다면 predictions은 다음과 같다.
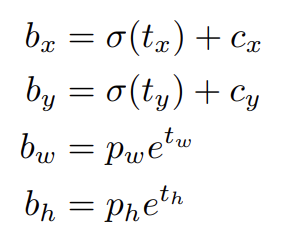
training 중 squared error loss의 합을 사용한다. 어떤 좌표 예측에 대한 ground truth가 라고 하면 gradient는 (truth box에서 계산한) ground truth value 빼기 예측값, 즉 가 된다. ground truth value는 위의 식들을 뒤집어(invert) 쉽게 계산할 수 있다.
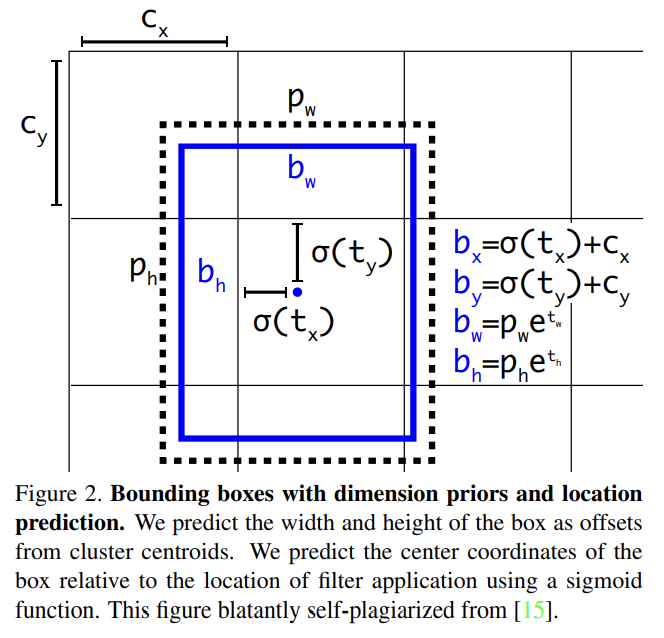
YOLOv3는 logistic regression을 사용해 각 bounding box에 대한 objectness score를 예측한다. bounding box prior가 다른 어떤 bounding box prior보다 ground truth object를 더 많이 overlap한다면 objectness score은 1이 되어야 한다. 어떤 bounding box prior가 최고는 아니지만 ground truth object를 특정 threshold보다 더 overlap한다면 [17]을 따라 그 prediction을 무시한다. [17]과 달리 YOLOv3는 각 ground truth object에 하나의 bounding box prior만 할당한다. bounding box prior가 ground truth object에 할당되지 않는다면 이는 coordinate나 class predictions에 대한 loss를 생성하지 않고 objectness에 대한 loss만 초래한다.
각 box는 multilabel classification을 사용해 bounding box가 포함할 수도 있는 classes를 예측한다. softmax는 사용하지 않는데, 좋은 성능에 불필요하다는 것을 발견했기 때문이다. 대신 단순히 independent logistic classifiers를 사용한다. training 중 class prediction을 위해 binary cross-entropy loss를 사용한다.
이런 형식은 Open Images Dataset [7] 같은 더 복잡한 domain으로 넘어갈 때 도움이 된다. 이 데이터셋에는 많은 overlapping labels이 있다. softmax는 각 box가 정확히 한 class만 가진다고 가정하고 이는 자주 사실이 아니다. multilabel 방식이 데이터를 더 잘 model한다.
YOLOv3는 3가지 다른 scale에서 box를 예측한다. YOLOv3는 feature pyramid networks와 비슷한 개념을 사용해 그 scales에서 features를 추출한다. base feature extractor에서 여러 convolutional layers를 추가한다. 마지막 layer는 bounding box, objectness, class predictions를 encoding하는 3-d tensor를 예측한다. COCO에의 실험에서 각 scale 당 3 boxes를 예측하므로 tensor는 N × N × [3 ∗ (4 + 1 + 80)]이다(4 bounding box offsets, 1 objectness prediction, 80 class predictions).
그 다음 이전 2 layers에서의 feature map을 받아 2배로 upsample한다. 또 네트워크 초기에서 feature map을 받아 upsampled features와 concatenate한다. 이는 upsampled features에서 더 의미있는 semantic 정보를, earlier feature map에서 finer-grained 정보를 허용한다. 그 다음 combined feature map을 처리하기 위해 몇 convolutional layers를 더 추가하고 최종적으로 크기가 2배인 비슷한 tensor를 예측한다.
마지막 scale에 대한 box를 예측하기 위해 한 번 더 비슷한 디자인을 수행한다. 따라서 3번째 scale에 대한 예측은 모든 이전 계산과 네트워크 초기의 fine-grained features에서 득을 본다.
bounding box priors를 결정하기 위해 여전히 k-means clustering를 사용한다. 임의로 9 clusters와 3 scales를 선택했고 clusters를 scales 간에 공평하게 분배했다. COCO에서 9 clusters는 (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116 × 90),(156 × 198),(373 × 326)와 같다.
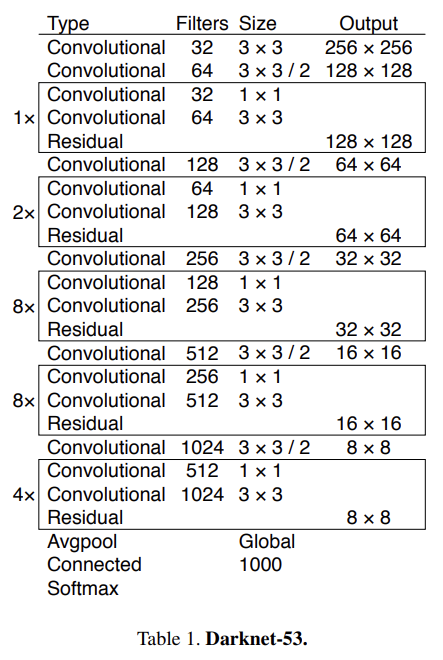
feature extraction에는 새로운 network를 쓴다. YOLOv2에서 사용된 Darknet-19와 residual network의 혼합이다. 네트워크는 연속적인 3 × 3과 1 × 1 convolutional layers을 사용하지만 shortcut connections도 있고 상당히 더 크다. 53 convolutional layers가 있으므로 Darknet-53이라고 부른다.
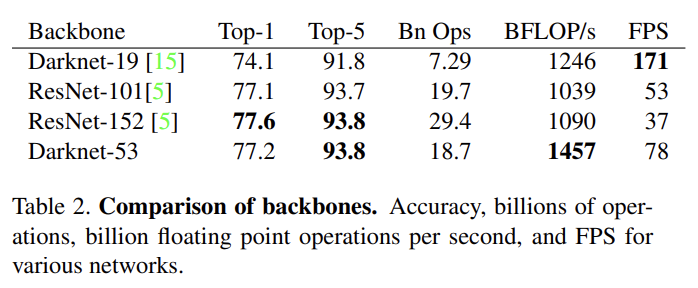
이 네트워크는 Darknet-19보다 강력하지만 ResNet-101이나 ResNet-152보다 효율적이다. Darknet-53은 SOTA classifiers와 동등한 성능을 보이지만 floating point operation이 더 적고 더 빠르다. Darknet-53은 ResNet-101보다 성능이 좋고 1.5배 빠르다. ResNet-152와 성능이 비슷하고 2배 빠르다.
여전히 hard negative mining 없이 full images에 학습한다. multi-scale training, 많은 data augmentation, batch normalization을 사용한다.
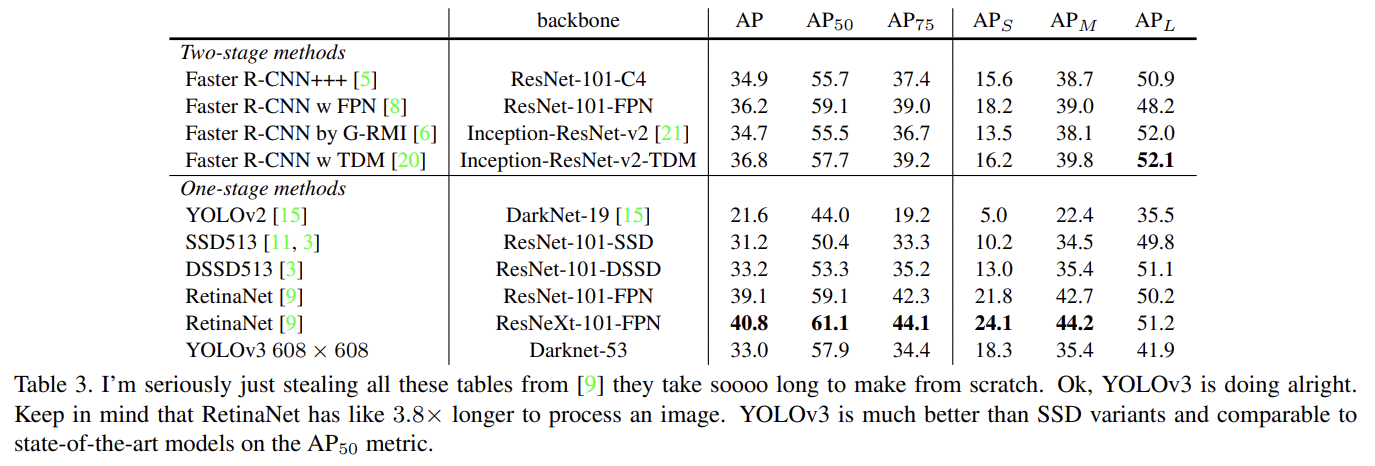
YOLOv3는 COCO의 mAP에서 SSD variants와 성능이 비슷하지만 3배 빠르다. 그러나 이 metric으로는 RetinaNet 같은 모델보다는 여전히 뒤떨어진다. 하지만 “old” detection metric, 즉 IOU= .5에서 mAP (표에서는 )을 보면 YOLOv3는 아주 강하다. RetinaNet과 비슷하고 SSD를 뛰어넘는다. 그러나 IOU threshold가 증가할수록 성능이 상당히 떨어지는 것은 YOLOv3가 boxes를 object와 완벽하게 align하지 못함을 나타낸다.
과거에 YOLO는 작은 object를 힘겨워했다. 그러나 이제는 경향이 반대다. 새로운 multi-scale predictions을 가진 YOLOv3는 상대적으로 높은 을 가진다. 그러나 medium, larger size objects에는 비교적 성능이 낮다.
다음과 같이 여러 가지를 시도했지만 먹히지 않는 것들이 많았다.
- Anchor box x, y offset predictions
linear activation을 사용해 x, y offset을 box width나 height의 배수로 예측하는 일반적인 anchor box prediction mechanism을 시도했다. 이는 model stability를 하락시켰다.
- Linear x, y predictions instead of logistic
logistic activation 대신 곧장 x, y offset을 예측하기 위해 linear activation을 사용해 봤다. 이는 mAP을 하락시켰다.
- Focal loss
focal loss를 사용해도 mAP이 하락했다. YOLOv3는 독립적인 objectness predictions와 conditional class predictions을 하기 때문에 focal loss가 해결하려는 문제에 이미 robust할지도 모른다.
- Dual IOU thresholds and truth assignment
Faster R-CNN은 training 중에 2개의 IOU threshold를 사용한다. 예측이 ground truth를 .7 이상 overlap하면 positive example이고 [.3−.7]면 무시되고 .3보다 낮으면 negative example이다. 비슷한 전략을 사용해봤지만 좋은 결과를 얻지 못했다.
Strengths
- softmax 대신 binary cross entropy loss로 multi-label classification을 수행했다.
- 속도와 성능이 발전했다. 특히 다른 모델에 비교했을 때 성능은 비슷하게 좋지만 속도가 두드러진다.
Weaknesses
- 결론 부분에서 해명하기는 하지만 구 metric을 사용해 성능을 입증한 것이 찝찝하긴 했다.
분량이 4페이지인데다 글이 논문 스타일이 아니고 트위터에 글 쓰듯 구어체와 농담이 많아서 신기했다. 이렇게 써도 되는 거냐??
