오늘 리뷰할 논문은 YOLOv2 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [YOLOv2 리뷰] YOLO9000: Better, Faster, Stronger (CVPR 17)
- YOLO v2 논문(YOLO9000:Better, Faster, Stronger) 리뷰
Summary
논문은 9000 object categories를 넘게 감지할 수 있는 SOTA real-time object detection system인 YOLO9000을 소개한다. 먼저 YOLO에 다양한 개선을 통해 YOLOv2를 만들어 PASCAL VOC와 COCO 같은 표준 detection task에서 SOTA를 달성한다. 새로운 multi-scale training method을 사용해 YOLOv2는 varying sizes에서 작동할 수 있으며 speed와 accuracy 사이 쉬운 tradeoff를 제공한다. 마지막으로 object detection과 classification에 공동으로 학습하는 방법을 제안한다. 이 방법을 통해 COCO detection dataset과 ImageNet classification dataset에 YOLO9000을 동시에 학습한다. 우리의 joint training은 labelled detection data가 없는 object classes에 대한 detections을 예측하게 해준다.
논문은 대량의 classification data를 활용해 detection system의 영역으로 확장할 방법을 제안한다. 논문의 방법은 object classification의 hierarchical view를 사용해 별개의 datasets을 함께 결합한다. 또 object detectors가 detection과 classification data 둘 다에 학습하게 하는 joint training algorithm을 제안한다. 이는 정확하게 objects를 localize하기 위해 labeled detection images를 leverage하는 한편 vocabulary와 robustness를 향상시키기 위해 classification images를 사용한다.
YOLO는 SOTA systems에 비해 여러 단점을 겪는다. Fast R-CNN에 비해 YOLO는 상당한 수의 localization errors을 만든다. 또 YOLO는 region proposal-based methods에 비해 recall이 작다. 따라서 classification accuracy는 유지하면서 recall과 localization을 향상하는 것에 집중한다.
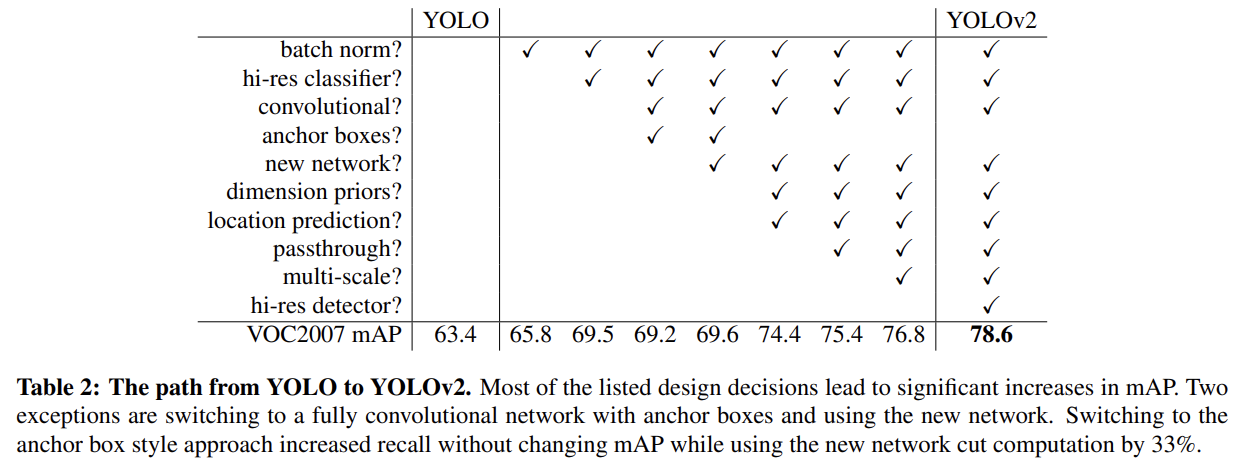
YOLOv2가 더 정확하지만 여전히 빠르길 원한다. network를 scaling up하는 대신 simplify하고 representation을 배우기 쉽게 만든다. YOLO의 성능을 향상시키기 위해 기존 연구들의 아이디어와 우리만의 새로운 개념을 적용한다.
- Batch Normalization
BN은 수렴을 크게 향상시키는 한편 다른 형태의 regularization의 필요를 제거한다. BN을 YOLO 내 모든 convolutional layers에 추가함으로써 mAP가 2% 넘게 향상된다. BN은 또한 모델을 regularize하게 돕는다. BN을 통해 모델에서 overfitting 없이 dropout을 제거할 수 있다.
- High Resolution Classifier
모든 SOTA detection 방법들은 ImageNet에 pretrain된 classifier을 사용한다. 대부분 classifiers는 256 × 256보다 작은 input image에 작동한다. original YOLO는 classifier network를 224 × 224에 학습시키고 detection을 위해 448로 해상도를 증가시킨다. 이는 네트워크가 object detection 학습으로 전환하고 동시에 새로운 input resolution으로 적응해야 한다는 것이다.
YOLOv2의 경우 classification network를 ImageNet에 10 epochs 동안 full 448 × 448 resolution로 finetune한다. 이는 network가 higher resolution input에 더 잘 작동하도록 filters를 적용할 시간을 준다. 그 다음 네트워크를 detection에 finetune한다. 이 high resolution classification network는 mAP을 거의 4% 향상시킨다.
- Convolutional With Anchor Boxes
YOLO는 convolutional feature extractor 꼭대기에 fully connected layers를 직접 사용해 bounding boxes의 좌표를 예측한다. Faster R-CNN은 좌표를 직접 계산하는 대신 hand-picked priors를 사용해 bounding boxes을 예측한다. Faster R-CNN 내 region proposal network (RPN)은 convolutional layers만 사용해 anchor boxes에 대한 offsets와 confidences를 예측한다. prediction layer가 convolutional하기 때문에 RPN은 feature map 내 모든 location에서 offsets을 예측한다. 좌표 대신 offsets을 예측하는 것은 문제를 간단화하고 네트워크가 학습하기 쉽게 만든다.
YOLO에서 fully connected layers를 제거하고 bounding boxes을 예측하기 위해 anchor boxes를 사용한다. 먼저 네트워크의 convolutional layers의 output을 더 큰 해상도로 만들기 위해 pooling layer 하나를 제거한다. 또 네트워크가 448×448 대신 416 input images에 작동하도록 줄인다(shrink). 이는 feature map 내 locations이 홀수라서 유일한 center cell을 가지기를 원하기 때문이다. objects는 (특히 큰 objects는) 이미지의 중앙을 차지하는 경향이 있기 때문에 이런 objects를 예측하는 데 (인근 4 locations보다는) 중앙에 단일 location을 가지는 편이 좋다. YOLO의 convolutional layers은 image를 32배로 downsample하므로 416의 input image를 사용하면 13 × 13의 output feature map을 얻는다.
anchor boxes 방식으로 변경하면 우리는 class prediction mechanism을 spatial location에서 분리하고 대신 모든 anchor boxes에 대한 class와 objectness를 예측한다. YOLO를 따라 objectness prediction는 여전히 ground truth의 IoU를 예측하고 제안된 box와 class predictions은 (object가 있다고 가정할 때) 그 class의 conditional probability을 예측한다.
anchor boxes를 사용하면 정확도가 약간 하락한다. YOLO는 이미지당 98 boxes밖에 예측 못하지만 anchor boxes를 사용하면 1000개 넘게 예측한다. anchor boxes를 사용하면 mAP이 하락하지만 recall이 향상된다.
- Dimension Clusters
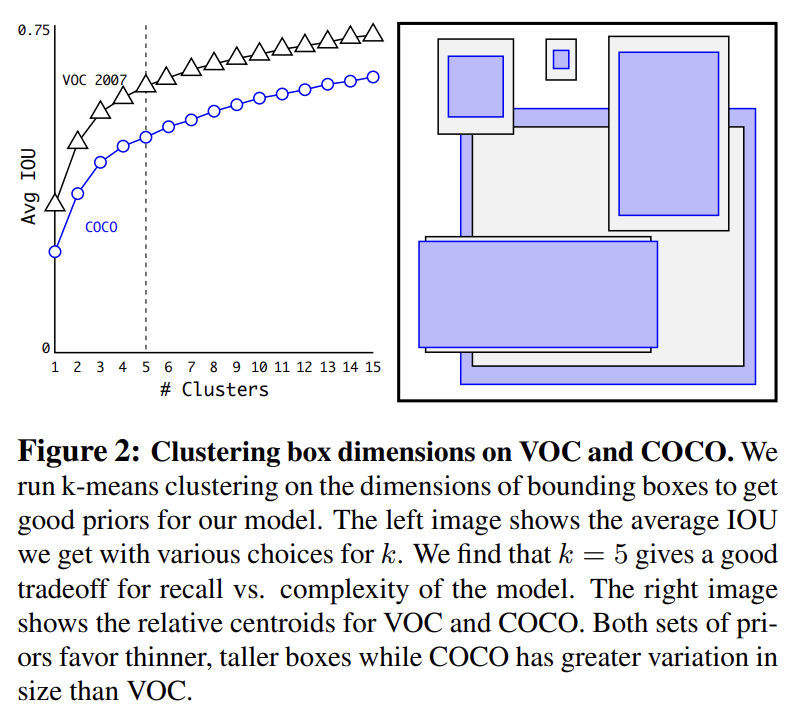
YOLO에 anchor boxes을 사용할 때 2가지 문제가 있다. 첫째는 box dimensions가 hand picked라는 점이다. 네트워크가 시작할 더 좋은 prior을 선택하면 네트워크가 좋은 detection을 예측하도록 학습하기 더 쉽다. 수동으로 prior을 선택하는 대신 자동으로 좋은 priors을 찾도록 training set bounding boxes에 k-means clustering을 실행한다. Euclidean distance와 함께 standard k-means를 사용하면 larger boxes가 smaller boxes보다 error를 더 생성한다. 그러나 우리가 원하는 것은 box 크기와 무관하게 좋은 IOU scores을 이끌어내는 priors이다. 따라서 다음과 같은 distance metric을 사용한다.
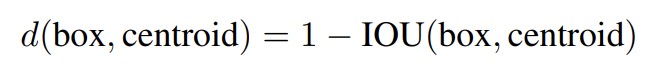
다양한 k 값에 k-means를 실행하여 closest centroid를 가진 average IOU를 Fig 2에 표시한다. model complexity와 높은 recall 사이 좋은 tradeoff로 k=5를 선택했다. cluster centroids는 hand-picked anchor boxes에 비해 상당히 다르다. short, wide boxes가 적고 tall, thin boxes가 많다.
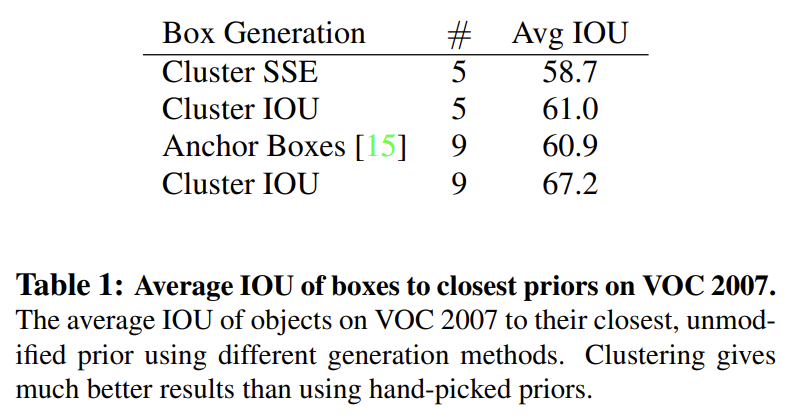
Tab 1에서 논문의 clustering strategy와 가장 가까운 prior와 hand-picked anchor boxes의 평균 IOU를 비교한다. 5 priors만으로도 centroids는 9 anchor boxes와 비슷하게 수행한다. 9 centroids를 사용하면 IOU가 더 높아진다. 이는 bounding box를 생성하기 위해 k-means를 사용하는 것이 더 좋은 representation을 만들고 task 학습을 쉽게 만듬을 나타낸다.
- Direct location prediction
YOLO에 anchor boxes를 사용하는 두 번째 문제점은 (특히 초기 iterations에서의) model instability이다. 대부분 instability는 box에 대한 (x, y) locations을 예측하는 데서 발생한다. region proposal networks에서 네트워크는 값을 예측하며 (x, y) center coordinates는 다음과 같이 계산된다.
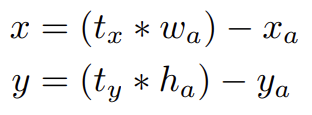
이 식은 제약이 없어서 어떤 location이 box를 예측했는지와 무관하게 anchor box가 image 내 어떤 point에서든 존재할(end up) 수 있다. random initialization을 가지고 model은 sensible offsets을 예측하기 위해 안정화하는 데 오랜 시간이 걸린다.
offsets을 예측하는 대신 YOLO의 방식을 따라 grid cell의 location에 상대적인 location coordinates을 예측한다. 이는 ground truth가 0에서 1 사이에 떨어지도록 bound한다. 네트워크의 예측이 이 범위에 떨어지도록 logistic activation을 사용한다.
네트워크는 output feature map 내 각 cells에서 5 bounding boxes을 예측한다. 각 bounding boxes에 대해 5 coordinates를, 즉 을 예측한다. cell이 image 좌측 위 구석에서 (cx, cy)의 offset에 있고 bounding box prior가 width와 height로 pw, ph을 가진다면 predictions은 다음과 같다.
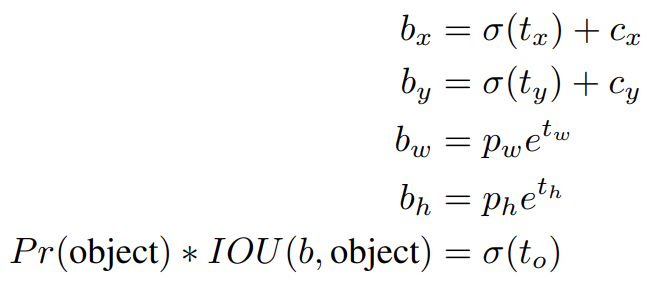
location prediction을 제약하기 때문에 parametrization이 학습하기 더 쉽고 네트워크를 stable하게 만든다.
- Fine-Grained Features
수정된 YOLO는 13 × 13 feature map에 detections을 수행한다. large objects에는 이것이 충분할 수 있지만 더 작은 objects를 localize하는 데는 finer grained features가 유익할 것이다. Faster R-CNN와 SSD은 다양한 resolution을 얻기 위해 다양한 feature maps에 그들의 proposal network를 수행한다. 논문은 다른 접근을 취하며, 단순히 26 × 26 resolution의 earlier layer에서부터 features를 가져오는 passthrough layer를 더한다.
passthrough layer는 (ResNet의 identity mapping과 비슷하게) 인접 features를 (spatial locations 대신) 다른 channels에 stacking함으로써 higher resolution features와 low resolution features을 concatenate한다. 이는 26 × 26 × 512 feature map을 (original features와 concatenate될 수 있는) 13 × 13 × 2048 feature map으로 바꾼다. 우리의 detector는 expanded feature
map 꼭대기에서 작동하며 따라서 fine grained features에 접근할 수 있다.
- Multi-Scale Training
original YOLO는 448 × 448 해상도 input을 쓴다. anchor boxes를 추가함으로써 우리는 해상도를 416×416로 바꿨다. 그러나 모델이 convolutional layer와 pooling layers만 쓰기 때문에 해상도를 그때그때 바꿀 수 있다. YOLOv2가 다양한 크기의 image에 robust하기를 원한다.
input image size을 바꾸는 대신 몇 iterations마다 네트워크를 바꾼다. 10 batches마다 네트워크는 랜덤하게 새로운 image dimension size를 선택한다. 모델이 32배로 downsample하므로 32배수 {320, 352, ..., 608}에서 고른다. 네트워크를 그 dimension으로 resize하고 학습을 재개한다.
네트워크는 다양한 resolution에서 detection을 예측할 수 있다. 네트워크는 작은 크기에서 더 빨리 작동하므로 YOLOv2는 speed와 accuracy 간 쉬운 tradeoff를 제공한다.
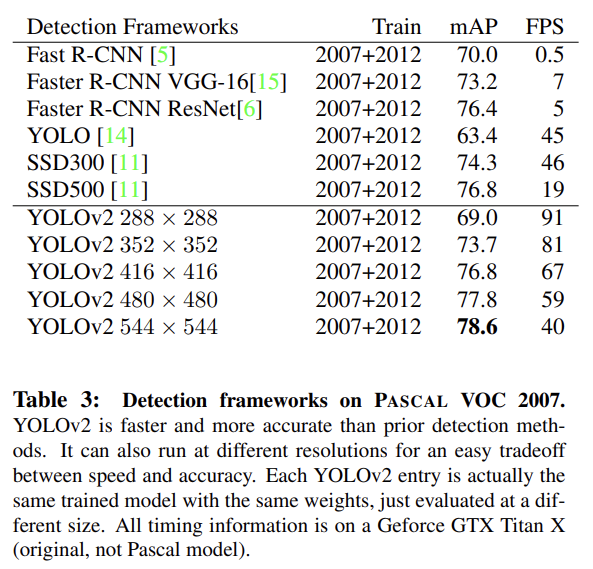
저해상도에서 YOLOv2는 싸고 상당히 정확한 detector로 작동한다. 고해상도에서 YOLOv2는 real-time speeds에서 작동하는 SOTA detector다.
- Further Experiments
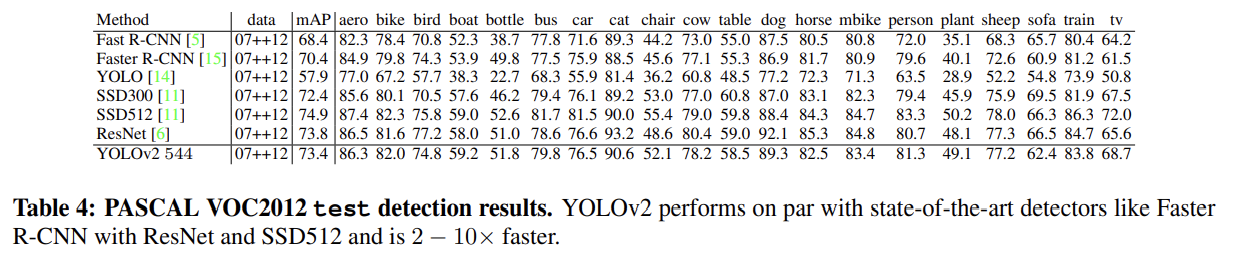
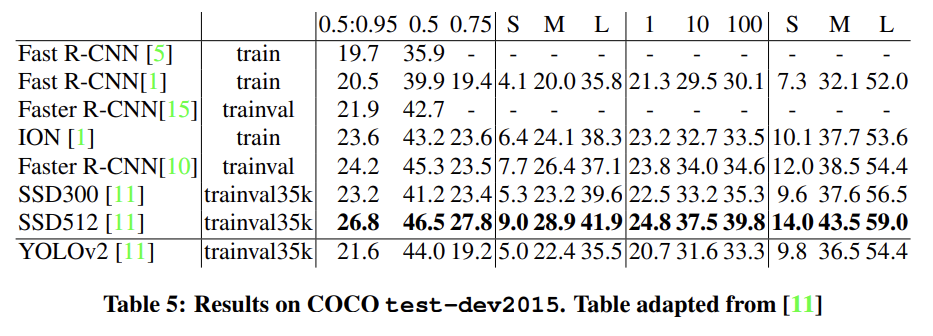
Tab 4, Tab 5는 YOLOv2를 VOC 2012와 COCO에 실험한 결과다.
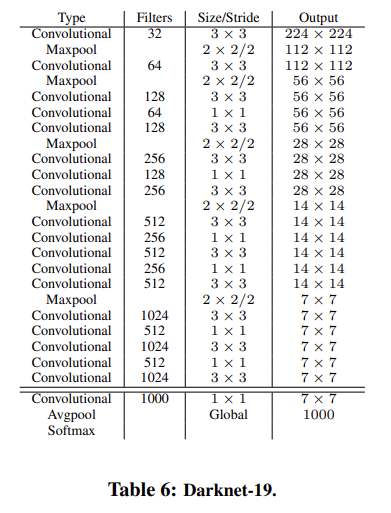
detection이 정확할 뿐 아니라 빠르기를 완한다. YOLO framework는 (VGG-16보다 빠르지만 약간 덜 정확한) Googlenet architecture에 기반한 custom network를 쓴다. 논문은 Darknet-19라고 불리는 새로운 classification model을 YOLOv2의 기반으로 사용한다. (이하 생략)
classification과 detection data에 공동으로 학습하는 mechanism을 제안한다. bounding box coordinate prediction과 objectness 같은 detection-specific information과 어떻게 common objects을 classify하는지 배우기 위해 detection을 위해 label된 images를 사용한다. 감지할 수 있는 categories의 수를 늘리기 위해 class labels만 가진 images를 사용한다.
training 중 detection과 classification datasets로부터의 이미지를 섞는다. 네트워크가 detection에 대해 label된 이미지를 보면 full YOLOv2 loss function에 기반해 역전파하고 classification 이미지를 보면 architecture의 classification-specific parts로부터의 loss만 역전파한다.
이 방식은 몇 가지 문제가 있다. detection datasets은 "dog"나 "boat" 같은 common objects와 general labels만 있는데 classification datasets은 더 넓고 깊은 범위의 labels이 있다. ImageNet은 “Norfolk terrier”, “Yorkshire terrier”, “Bedlington terrier”을 포함해 백 종이 넘는 개가 있다. 양쪽 데이터셋 모두에 학습하고 싶다면 이런 labels을 합치는 일관된 방법이 필요하다.
대부분 classification 방식은 final probability distribution을 계산하기 위해 모든 가능한 categories에 걸쳐 softmax layer를 사용한다. softmax를 사용하는 것은 class들이 상호 간에 배타적임을 가정한다. 이는 데이터셋을 조합할 때 문제가 된다.
대신 상호 배타적이지 않은 데이터셋들을 결합할 때 multi-label model을 사용할 수 있다. 이는 우리가 데이터에 대해 아는 모든 structure를 무시한다.
- Hierarchical classification
ImageNet labels은 WordNet에서 오는데, 이는 그들의 개념과 어떻게 연관되는지를 구조화한 language database다. WordNet은 directed graph로 구조화됐다. 전체 graph structure를 사용하는 대신 ImageNet 개념들로부터의 hierarchical tree를 만들어 문제를 단순화한다.
이 tree를 만들기 위해 ImageNet 내 visual nouns를 조사하고 그들의 path를 WordNet graph를 통해 root node까지, 이 경우에는 "physical object"까지 관찰한다. 먼저 그 path들을 tree에 추가한다. 그 다음 반복적으로 남은 개념들을 조사하여 가능한 적게 tree를 자라게 하는 path들을 추가한다.
최종 결과는 WordTree인데, visual concepts의 hierarchical model이다. WordTree를 가지고 classification을 수행하기 위해 모든 node에서 그 synset이 주어졌을 때 그 synset의 각 하의어(hyponym)의 확률에 대해 conditional probabilities을 예측한다. 예를 들어 “terrier” node에선 다음과 같이 예측한다.

특정 node에 대한 absolute probability를 계산하고 싶으면 단순히 tree를 통해 root node까지 path를 따르고 conditional probabilities에 곱하면 된다. 그러니 사진이 Norfolk terrier인지 알고 싶으면 다음을 계산하면 된다.

classification 목적을 위해 image가 object를 포함한다고 가정한다. 즉 Pr(physical object) = 1.
이 방법을 검증하기 위해 1000 class ImageNet을 사용해 만든 WordTree에 Darknet-19 model을 학습시킨다.
training 중 ground truth labels을 tree를 따라 전파한다. 그래서 이미지가 "Norfolk terrier"로 label됐으면 "dog"와 "mammal"로도 label된다. conditional probabilities를 연산하기 위해 모델은 1369 values의 vector을 예측하고 Fig 5처럼 같은 개념의 하의어인 모든 synsets에 대한 softmax를 계산한다.
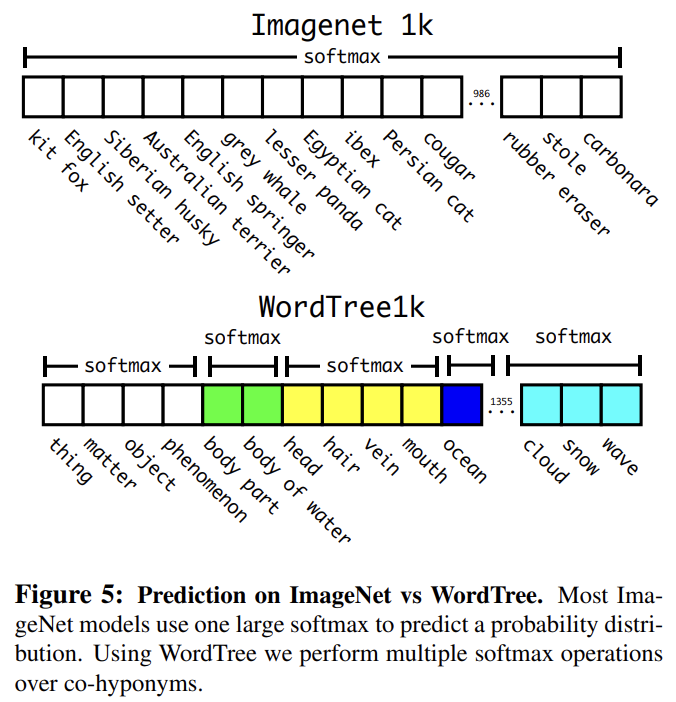
369 additional concepts을 추가하고 네트워크가 tree structure를 예측하게 했음에도 불구하고 정확도는 미미하게 떨어진다. 이 방식으로 classification을 수행하는 것은 몇 가지 장점도 있다. 새로운 또는 unknown object categories에 대한 성능이 적절하게(gracefully) 하락한다. 예를 들어 사진을 보고 개인 건 아는데 품종을 모르겠다면 여전히 높은 confidence로 “dog”을 예측하겠지만 하의어 간에 더 낮은 confidence로 흩어진다.
이 형식은 detection에도 작동한다. 이제 모든 image가 object를 가진다고 가정하는 대신 Pr(physical object)의 값을 주기 위해 YOLOv2의 objectness predictor을 사용한다. detector는 bounding box와 tree of probabilities를 예측한다. tree를 아래로 횡단하며 갈림길(split)마다 가장 높은 confidence path를 선택하고 특정 threshold에 도달하면 그 object class를 예측한다.
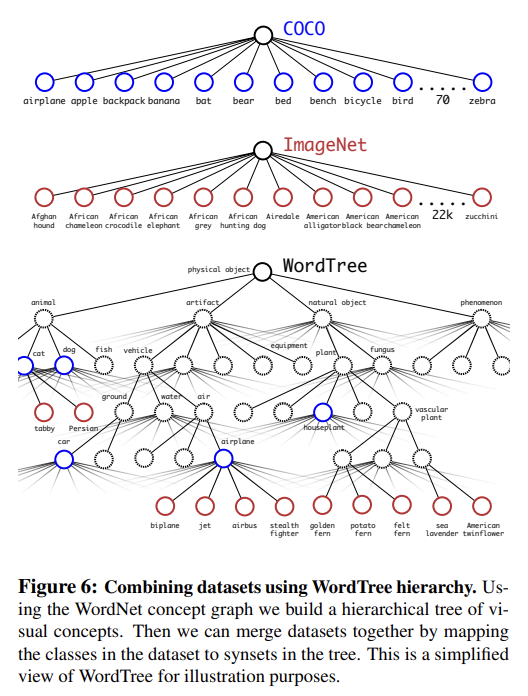
여러 dataset을 결합하기 위해 WordTree를 사용할 수도 있다. 단순히 datasets 내 categories를 tree 내 synsets에 map하면 된다.
WordTree을 사용해 datasets을 결합할 수 있으니 classification과 detection에 우리의 joint model을 훈련시킬 수 있다. extremely large scale detector를 학습하고 싶으므로 COCO detection dataset과 full ImageNet release로부터의 top 9000 classes를 사용해 combined dataset을 창조한다. 또 ImageNet detection challenge로부터의 classes도 추가한다. 상응하는 WordTree는 9418 classes을 가진다. ImageNet이 훨씬 큰 데이터셋이므로 COCO를 oversampling해서 ImageNet이 4배만 더 크도록 balance한다.
이 데이터셋을 사용해 YOLO9000를 학습시킨다. output size를 제한하기 위해 5개 대신 3 priors만으로 base YOLOv2 architecture를 사용한다. detection image를 보면 평범하게 loss를 역전파한다. classification loss의 경우, label의 상응하는, 그리고 상위의 loss를 역전파한다.
classification image를 볼 때는 classification loss만 역전파한다. 이를 위해 우리는 단순히 그 class에 대한 highest probability를 예측하는 bounding box를 찾고 그것의 predicted tree에만 loss를 계산한다. 또 predicted box가 ground truth label와 최소한 0.3 IOU만큼 overlap한다고 가정하고 이 가정에 기반해 objectness loss를 역전파한다.
ImageNet에 YOLO9000의 성능을 분석할 때 새로운 종의 동물은 잘 배우지만 옷이나 도구 같은 categories를 학습하는 데는 난항을 겪음을 알 수 있다. 이는 COCO의 동물에서 objectness predictions을 잘 일반화하지만 역으로 옷에 대한 bounding box label는 아무 것도 없기 때문이다.
Strengths
- YOLO의 정확도와 속도를 모두 개선했다.
- WordTree라는 hierarchical tree를 통해 classification 데이터셋과 detection 데이터셋을 모두 사용하는 아이디어가 인상적이었다.
Weaknesses
- anchor boxes의 크기를 임의로 정한 게 아니라 training set bounding boxes에 k-means clustering해서 정했는데 이건 치팅 아닌가? 그 데이터셋에 적합하게 만들 뿐인 것 같다.
- 사물이 보통 이미지 중간에 있어서 image feature가 홀수가 되도록 해상도를 설정하는것도 특이적인 꼼수 같아서 마음에 들지 않았다.
- WordTree가 흥미롭긴 한데, naive한 시도인 것 같다. 데이터셋 간 불균형도 해소하지 못한다.
