오늘 리뷰할 논문은 ULMFiT 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문리뷰] Universal Language Model Fine-tuning for Text Classification (2018)
- 논문 요약: Universal Language Model Fine-tuning for Text Classification
- Universal Language Model Fine-tuning for Text Classification
Summary
Inductive transfer learning은 CV 분야에 크게 영향을 끼쳤지만 NLP는 여전히 task-specific modifications과 밑바닥에서부터의 training을 필요로 한다. 논문은 NLP의 아무 task에나 적용할 수 있는 학습법인 Universal Language Model Fine-tuning (ULMFiT)을 제안하며 language model을 fine-tuning하는 핵심 기술을 소개한다. 6 text classification task에 SOTA를 달성한다.
NLP 연구는 대부분 transductive transfer에 초점을 맞춘다. inductive transfer의 경우 (모델의 first layer만 target하는 간단한 transfer 기술인) pretrained word embeddings을 fine-tuning하는 것이 많이 쓰인다. 여러 tasks로부터의 embedding을 concatenate하는 최근 방법들도 여전히 main task model을 밑바닥에서부터 학습하고 pretrained embeddings을 fixed parameters로 취급해 그들의 유용성을 제한한다.
pre-training의 이점의 관점에서 모델의 남은 parameters를 randomly initializing하는 것보다 더 잘 해야 한다. 그러나 fine-tuning을 통한 inductive transfer는 NLP에서 성공적이지 못해 왔다. Dai and Le (2015)가 먼저 language model (LM)을 fine-tuning하는 것을 제안했지만 좋은 성능을 위해서는 수백만의 in-domain documents을 요구해서 응용성이 제한된다.
논문은 LM fine-tuning 아이디어 자체가 아니라 어떻게 효과적으로 학습시키는지에 대한 지식 부족이 넓은 적용을 저해함을 보인다. LM은 작은 데이터셋에 overfit되고 classifier와 함께 fine-tune될 시 심각한 forgetting을 겪었다. CV와 달리 NLP 모델들은 일반적으로 더 얕으므로 다른 fine-tuning 방법을 요구한다.
이 문제를 해결하고 아무 NLP task에나 robust inductive transfer learning을 가능하게 하는 새로운 방법 Universal Language
Model Fine-tuning (ULMFiT)을 제안한다. ImageNet models을 fine-tuning하는 것과 비슷한데, (tuned dropout hyperparameters을 제외하면 동일한 hyperparameters를 가지는) 동일한 3-layer LSTM architecture는 6 text classification tasks에서 highly engineered models와 transfer learning approaches을 능가한다. IMDb에서 100 labeled examples을 가지고 ULMFiT는 10배의 데이터를 가지고 밑바닥에서부터 학습한 것과 동등한 성능을 보이고 50k unlabeled examples를 가지고는 100배 많은 데이터로 밑바닥에서 학습한 것과 동등한 성능을 보인다.
논문의 기여는 다음과 같다.
- 아무 NLP task에서나 CV-like transfer learning를 달성하는 데 사용할 수 있는 방법인 Universal Language Model Fine-tuning (ULMFiT)을 제안한다.
- fine-tuning 중 기존 지식을 유지하고 끔찍한 forgetting을 피하는 새로운 기술인 discriminative fine-tuning, slanted triangular learning rates와 gradual unfreezing을 제안한다.
- 6가지 대표적인 text classification datasets에서 대부분 18-24%의 error deduction을 가지고 SOTA를 능가한다.
- 우리 방법이 몹시 sample-efficient transfer learning을 가능하게 함을 보이고 광범위한 ablation analysis을 수행한다.
논문은 NLP에 대한 가장 일반적인 inductive transfer learning setting에 관심이 있다. static source task 와 아무 target task 가 주어질 때(), 의 성능을 향상하고 싶다. Language modeling은 (NLP에서의 ImageNet 대응으로서) 이상적인 soruce task다. 또 pre-trained LM은 쉽게 target task의 특이점에 정응할 수 있어 성능을 향상시킨다. LM은 다른 많은 NLP tasks에서 유용한 hypothesis space H을 추론한다.
large general-domain corpus에 LM을 pretrain하고 새로운 기법을 사용해 target task에 fine-tune하는 ULMFiT을 제안한다. 다음 실용적인 기준들을 만족한다는 점에서 이 방법은 universal하다. 1. document size, number, label type이 다양한 tasks에 걸쳐 작동한다. 2. 단일한 architecture와 training process를 사용한다. 3. custom feature engineering이나 preprocessing을 요구하지 않는다. 4. 추가적인 in-domain documents나 labels을 요구하지 않는다.
실험에선 (다양한 tuned dropout hyperparameters를 가진) SOTA LM인 AWD-LSTM와 일반적인 LSTM을 사용한다.
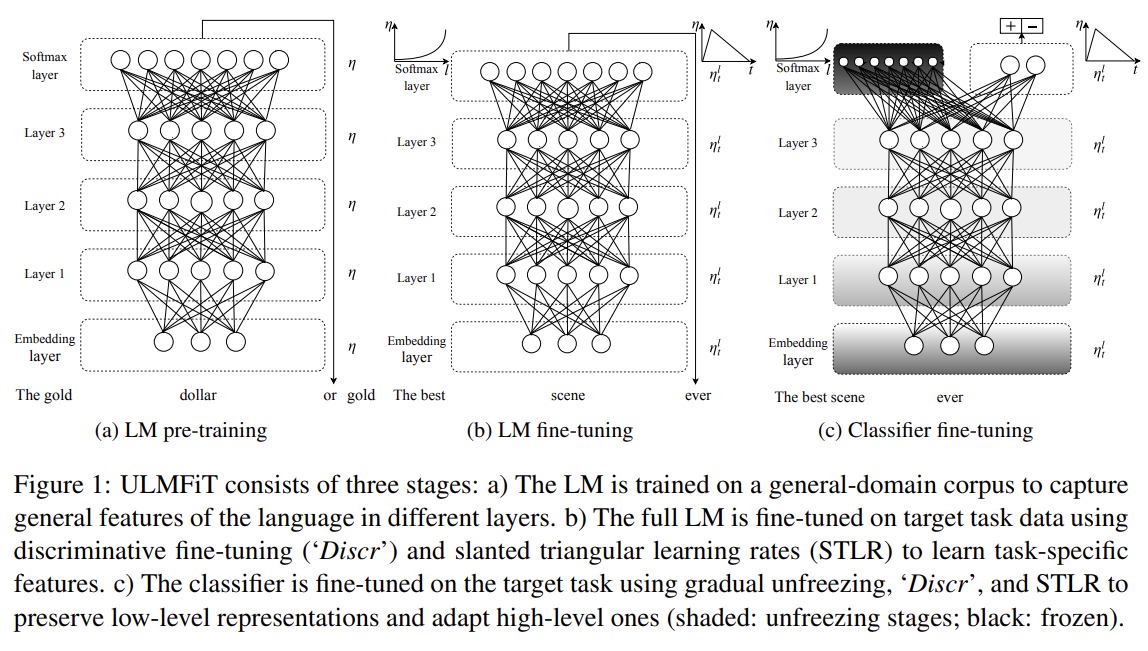
Fig 1과 같이 ULMFiT는 3단계로 구성된다. a) General-domain LM pretraining, b) target task LM fine-tuning, c) target task classifier fine-tuning이다.
- General-domain LM pretraining
language에 대한 ImageNet-like corpus은 커야 하고 language의 일반적인 특징들을 포착해야 한다. LM을 Wikitext-103에 pretrain한다. pretraining을 작은 datasets을 가진 tasks에 가장 유익하고 심지어 100 labeled examples을 가지고도 일반화가 가능하게 해준다. 이 단계가 가장 비싸지만 한 번만 수행되면 되며 downstream models의 성능과 수렴을 향상시킨다.
- Target task LM fine-tuning
pretraining에서 얼마나 다양한 general-domain data을 사용했든 target task의 data는 다른 distribution에서 온다. 따라서 LM을 target task의 data에 fine-tune한다. pretrained general-domain LM가 주어질 때, 이 단계는 LM이 target data의 특이점에만 적응하면 되므로 수렴이 더 빠르고 심지어 작은 dataset에 대해서도 robust LM을 학습하게 해준다. LM을 fine-tuning하는 데 discriminative fine-tuning과 slanted triangular learning rates을 제안한다.
- Discriminative fine-tuning
다른 layers가 다른 종류의 정보를 포착하므로 다른 정도(extent)로 fine-tune되어야 한다. 그러므로 새로운 fine-tuning 방법인 discriminative fine-tuning을 제안한다.
모델의 모든 layers에 동일한 learning rate를 사용하는 대신 discriminative fine-tuning은 각 layer에 다른 learning rates로 tune한다. 경험적으로 먼저 (마지막 layer만 fine-tuning함으로써) 마지막 layer의 learning rate 을 고르고 lower layers에 대해서는 을 사용하면 잘 작동했다.
- Slanted triangular learning rates
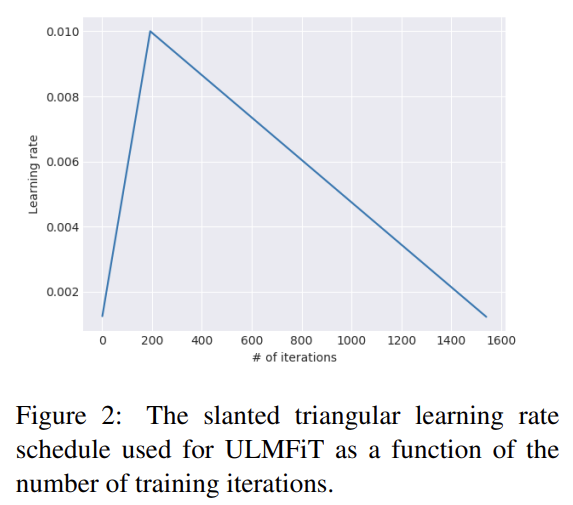
parameters를 task-specific features로 조정할 때 우리는 모델이 training 초기에 parameter space의 적절한 영역으로 빠르게 수렴하고 그 다음 parameters를 개선하길 원한다. training 동안 동일한 learning rate (LR)나 annealed learning rate을 사용하는 것은 이를 달성하기 위한 좋은 방법이 아니다. 대신 slanted triangular learning rates (STLR)을 제안하며, 이는 Fig 2에서 볼 수 있듯 다음 update schedule에 따라 learning rate을 먼저 선형적으로 증가시키고 선형적으로 감소시킨다.
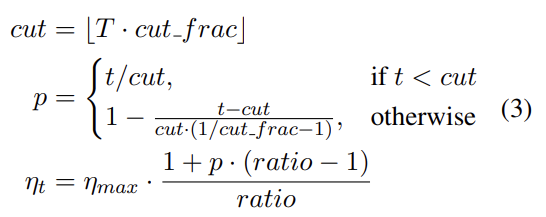
T는 training iteration 횟수, 은 LR을 증가시키는 iterations의 비율(fraction), cut은 LR을 증가에서 감소로 전환하는 iteration 시기, p는 LR을 증가시켰거나 감소시킬 iterations 횟수의 비율, ratio는 lowest LR이 maximum LR 로부터 얼마나 작은지 명시하며, 은 iteration t에서의 learning rate다. 일반적으로 = 0.1, ratio = 32, = 0.01.을 사용한다.
- Target task classifier fine-tuning
마지막으로 classifier을 fine-tuning하기 위해 2가지 추가적인 linear blocks를 가지고 pretrained language model를 늘린다. CV classifiers의 일반적인 관행을 따라 각 block은 batch normalization과 dropout을 사용하며 intermediate layer에 대해 ReLU activations을 가지고 마지막 layer에서 softmax activation이 target classes에 대한 probability distribution을 출력한다. 이 task-specific classifier layers 내의 parameters만 밑바닥에서부터 학습됨에 주의하라. first linear layer은 pooled last hidden layer states를 input으로 받는다.
- Concat pooling
text classification tasks 내의 신호는 보통 적은 단어 내에 있고 document 내 어디에서나 일어날 수 있다. input documents가 수백 개의 단어로 구성되기 때문에 모델의 last hidden state만 고려하면 정보가 손실될 수 있다. 그러므로 document의 last time step 에서의 hidden state를 GPU 메모리가 허락하는 한 가능한 많은 time steps 에서의 hidden states의 max-pooled representation과 mean-pooled representation와 concatenate한다.
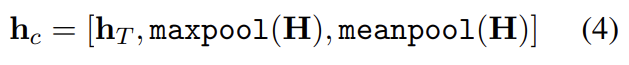
[]는 concatenation이다.
- Gradual unfreezing
target classifier을 fine-tuning하는 것이 transfer learning method에서 가장 중요한 부분이다. 너무 aggressive한 fine-tuning은 끔찍한 forgetting을 초래하여 language modeling을 통해 포착한 정보의 이점을 없앤다. 너무 조심스러운 fine-tuning은 느린 수렴과 그로 인한 overfitting을 초래한다. classifier을 fine-tuning하기 위해 논문은 gradual unfreezing을 제안한다.
모든 layers를 한 번에 fine-tuning하는 대신 마지막 layer에서 시작해(마지막 layer가 가장 적은 general knowledge를 지니므로) 점진적으로 모델을 녹이는(unfreeze) 방법을 제안한다. 먼저 last layer를 unfreeze하고 한 epoch만큼 모든 unfrozen layers를 fine-tune한다. 그 다음 next lower frozen layer를 녹이고 모든 layers가 수렴할 때까지 반복한다.
- BPTT for Text Classification (BPT3C)
LM은 large input sequences에 대해 기울기 전파를 가능하게 하기 위해 BPTT for Text Classification (BPT3C)을 가지고 학습된다. large documents에 classifier를 fine-tuning하는 것을 가능하게 만들기 위해 BPTT for Text Classification (BPT3C)을 제안한다. document를 size b의 fixed-length batches로 분할한다. 각 batch의 초기에서 모델은 previous batch의 final state로 초기화된다. mean pooling과 max pooling을 위해 hidden states를 기록한다. gradients는 hidden states가 final prediction에 기여한 batches에게 역전파된다. 실제로는 variable length backpropagation sequences (Merity et al., 2017a)을 사용한다.
- Bidirectional language model
기존 연구와 비슷하게 unidirectional language model을 fine-tuning하는 데 국한되지 않는다. 모든 실험에서 forward와 backward LM을 둘 다 pretrain한다. BPT3C를 사용해 각 language model에 대한 classifier을 독립적으로 fine-tune하고 classifier predictions을 평균 낸다.
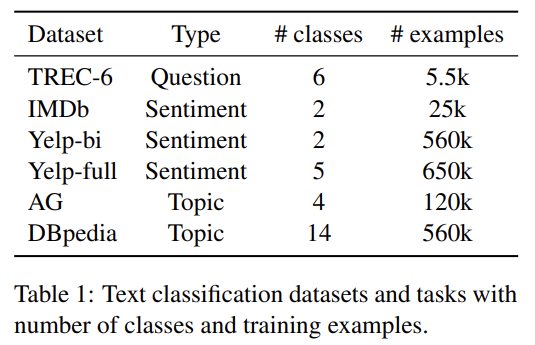
3가지 일반적인 text classification task인 sentiment analysis, question classification, topic classification의 사례로써 6가지 dataset에 ULMFiT를 평가한다.
선행연구(Johnson and Zhang, 2017; McCann et al., 2017)와 동일한 pre-processing을 사용한다. 추가로 language model이 classification에 관련될 수도 있는 측면을 포착하게 하기 위해 upper-case words, elongation, repetition에 special token을 추가했다.
(hyperparameter 설명 생략)
각 task에 대해 SOTA와 비교한다. IMDb와 TREC-6 데이터셋의 경우 CoVe와 비교하고 AG, Yelp, DBpedia 데이터셋의 경우 Johnson and Zhang (2017)의 SOTA text categorization와 비교한다.
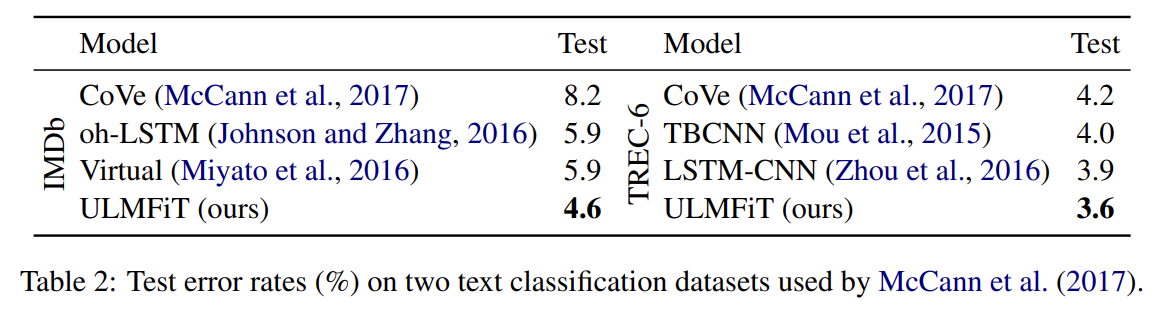
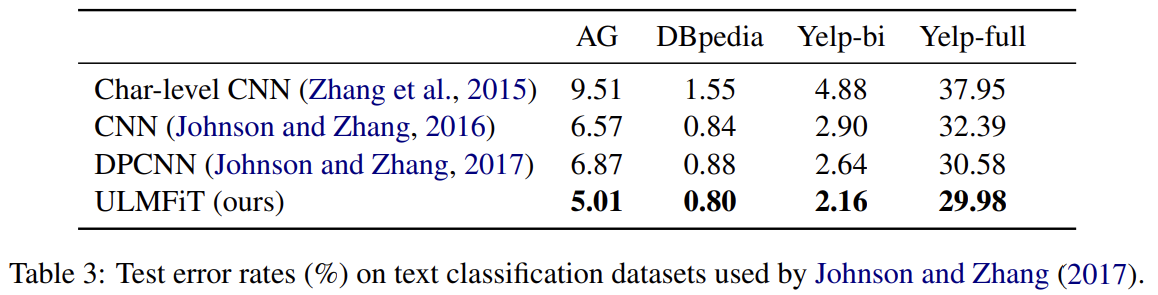
실험 결과 설명은 생략한다.
대표로 IMDb, TREC6, AG 데이터셋에 분석과 ablation을 수행한다.
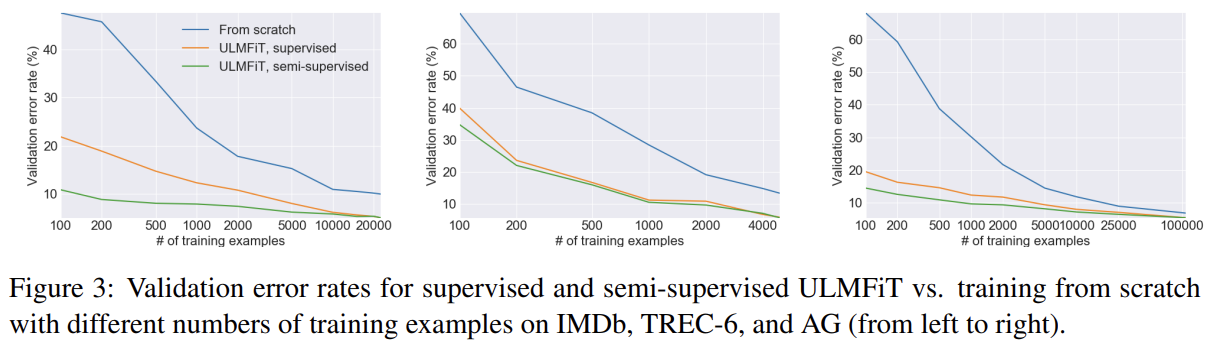
transfer learning의 한 장점은 적은 수의 label을 가진 task를 위해 모델을 학습할 수 있다는 것이다. ULMFiT를 2가지 세팅에서, LM fine-tuning에 labeled examples만 사용된 세팅과(‘supervised’) 모든 task data가 LM fine-tune에 사용 가능한 세팅(‘semi-supervised’)에서 평가했다.
IMDb와 AG에서 supervised ULMFiT는 100 labeled data로 각각 10배, 20배 많은 데이터로 밑바닥에서 학습할 때와 비슷한 성능을 보여 general-domain LM pretraining의 이점을 입증했다. 100 labeled examples에 unlabeled examples (50k for IMDb, 100k for AG)도 허락하면 각각 50배, 100배 많은 데이터를 활용한 것과 동등했다. TREC-6의 경우 ULMFiT가 밑바닥에서 시작하는 것보다 상당히 성능을 향상시키지만 examples가 더 짧고 적기 때문에 supervised와 semi-supervised ULMFiT는 성능이 비슷했다.
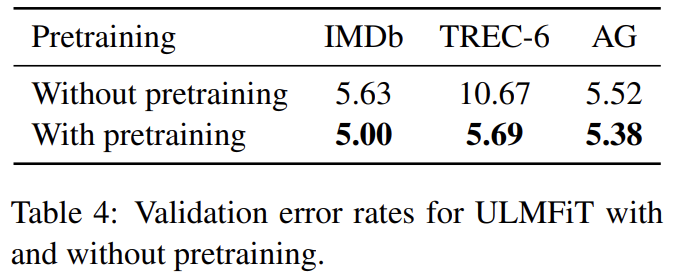
WikiText-103에 pretraining 한 것과 안한 것을 비교한다.
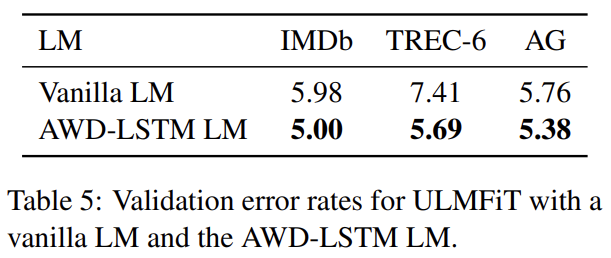
적절한 LM 선택의 중요성을 알기 위해 (dropout 없이 동일한 hyperparameters를 가지는) vanilla LM을 (tuned dropout parameters을 가진) AWD-LSTM LM와 비교한다. 논문의 fine-tuning techniques을 사용하면 일반적인 LM도 larger datasets에 좋은 성능을 낸다. 더 작은 TREC-6의 경우 dropout 없는 vanilla LM은 overfitting의 위험이 따라서 성능이 하락한다.
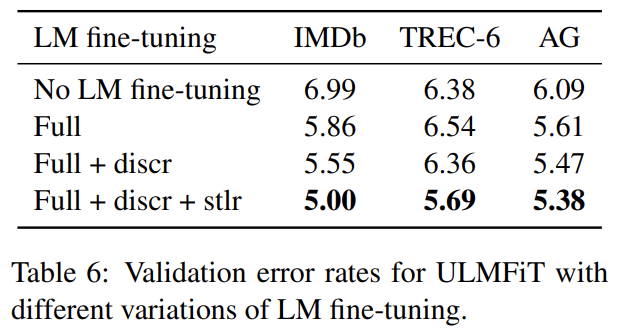
no finetuning과 가장 흔히 사용되는 fine-tuning 방법인 full model (Erhan et al., 2010) (‘Full’)과 discriminative fine-tuning (‘Discr’), slanted triangular learning rates (‘Stlr’)을 가지고 fine-tuning하는 것을 비교한다. Discr와 Stlr은 3 데이터셋 모두에서 성능을 향상시키고 크기가 작아 일반적인 fine-tuning이 유용하지 않은 TREC-6에서는 필수적이다.
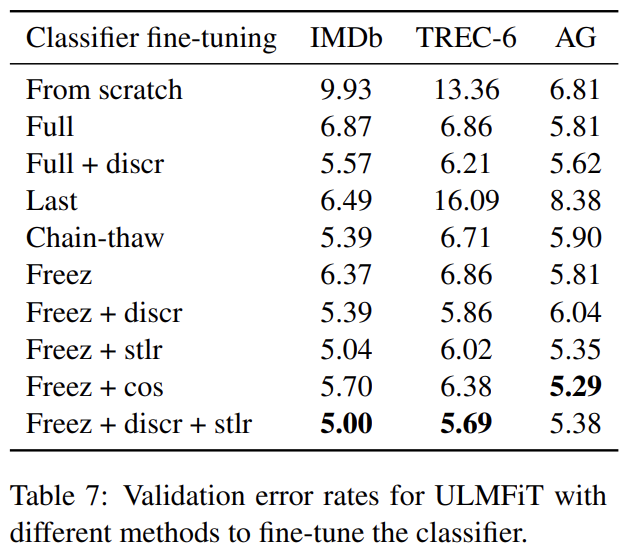
밑바닥에서 학습하는 것과 full model을 fine-tuning하는 것('Full')과 last layer만 fine-tuning하는 것('Last')과 'Chain-thaw'와 gradual unfreezing (‘Freez’)을 비교한다. discriminative fine-tuning (‘Discr’)와 slanted triangular learning rates (‘Stlr’)의 중요성도 평가한다. 후자를 aggressive cosine annealing schedule (‘Cos’)와 비교한다.
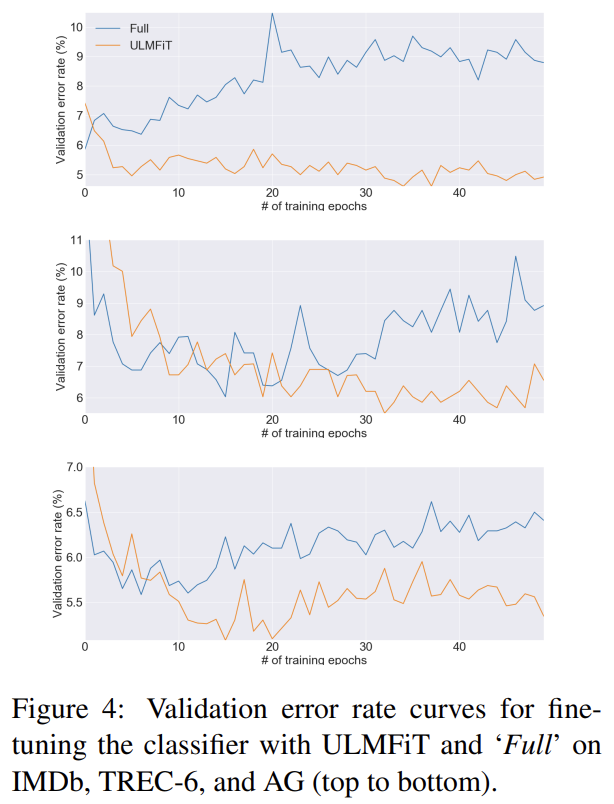
fine-tuning 행동 방식을 이해하기 위해 ULMFiT와 'Full'로 fine-tune된 classifier의 validation error를 비교한다. 모든 데이터셋에서 full model이 학습 초기에 더 낮은 error를 내지만 model이 overfit하고 pretraining을 통한 지식이 잊히기 시작하면서 error가 증가한다. 반면 ULMFiT는 더 안정적이고 forgetting을 겪지 않아 성능이 유지되거나 향상된다.
forward와 backwards LM-classifier의 예측을 ensemble하는 것은 약간의 성능 향상이 있었다.
Strengths
- discriminative fine-tuning을 통해 learning rate를 layer마다 따로 설정하고 slanted triangular learning rates로 learning rate를 스케쥴링 했으며 gradual unfreezing으로 layer를 점진적으로 녹여 fine-tuning을 했다. fine-tuning이 더 안정적이고 forgetting을 피할 수 있었다. 특히 작은 데이터셋에서 효과가 두드러졌다.
