오늘 리뷰할 논문은 Facebook의 RetinaNet 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- Focal Loss for Dense Object Detection 리뷰
- [논문리뷰] RetinaNet: Focal Loss for Dense Object Detection
- RetinaNet 논문(Focal Loss for Dense Object Detection) 리뷰
Summary
최근 가장 높은 정확도의 object detectors는 R-CNN에 의해 유행한 two-stage 방식에 기반한다. 여기서 classifier는 sparse set of candidate object locations에 적용된다. 반면 regular, dense sampling of possible object locations에 적용되는 one-stage detectors는 더 빠르고 간단하지만 정확도는 two-stage보다 뒤처진다. 논문은 이것이 왜 그런가 조사하고 dense detectors의 training 중 극심한 foreground-background class imbalance가 핵심적인 문제임을 발견했다. 논문은 standard cross entropy loss를 well-classified examples에 할당된 loss를 down-weight하는 식으로 개조함으로써 class 불균형을 해소하기를 제안한다. 새로운 Focal Loss는 sparse set of hard examples에 학습하도록 집중하고 대량의 easy negatives가 training 중 detector를 압도하지 않게 방지한다. Focal loss의 효과를 평가하기 위해 간단한 dense detector인 RetinaNet을 만들었다. focal loss를 가지고 학습했을 때 RetinaNet은 기존 one-stage detectors의 속도에 맞먹으면서 모든 현존하는 SOTA two-stage detectors의 정확도를 능가한다.
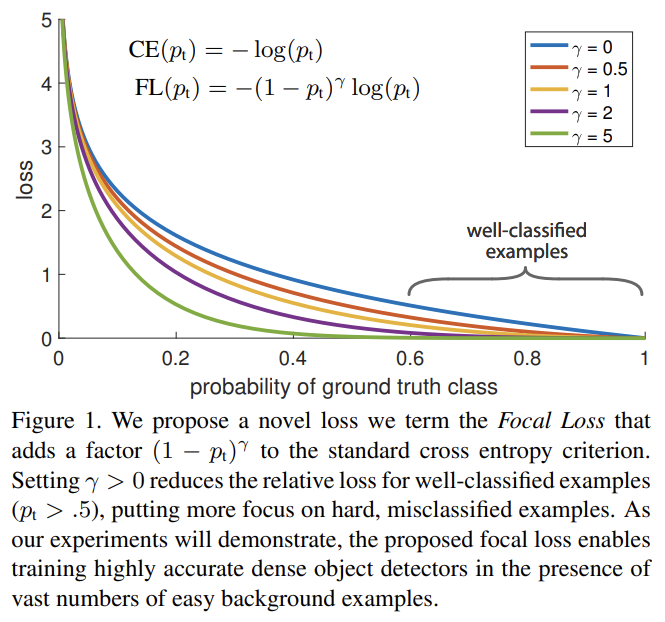
논문이 제안하는 새로운 loss는 dynamically scaled cross entropy loss이며 correct class 내 confidence가 증가할수록 scaling factor가 0으로 줄어든다. 직관적으로, scaling factor는 자동으로 training 중 easy examples의 기여를 down-weight하고 hard examples에 집중한다. 실험 결과 focal loss는 기존 SOTA one-stage detector들이 사용하던 대안인 sampling heuristics이나 hard example mining을 능가한다. focal loss의 정확한 형태가 중요한 게 아니라 다른 instantiation도 비슷한 결과를 달성할 수 있음을 보인다.
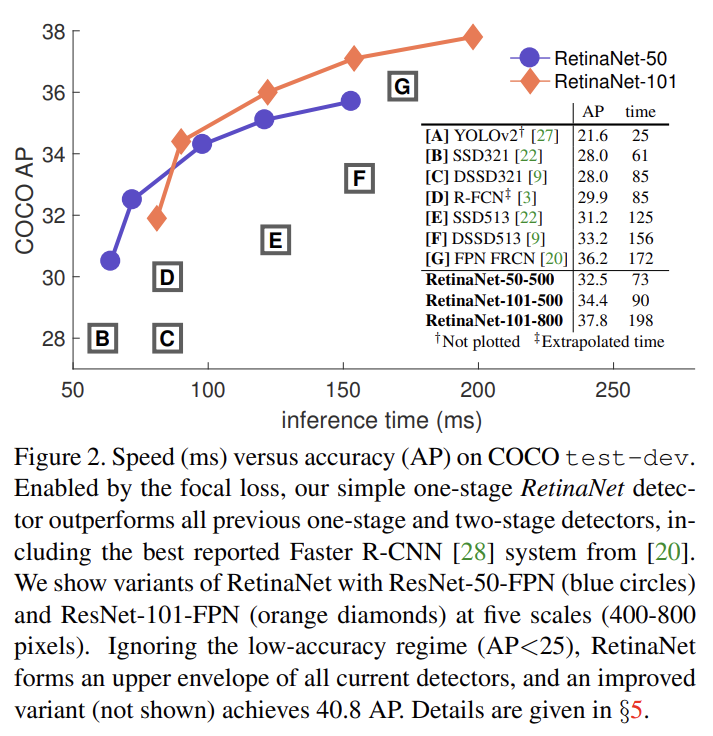
focal loss의 효과를 입증하기 위해 디자인한 간단한 one-stage detector인 RetinaNet은 효율적인 in-network feature pyramid와 anchor boxes 사용을 특징으로 삼는다.
Focal Loss는 training 중 foreground와 background classes 간에 극단적인 불균형이 있는(예컨대 1:1000) one-stage object detection을 다루기 위해 디자인되었다.
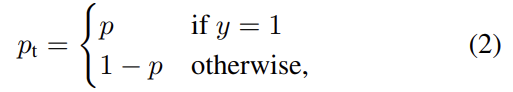
(binary classification에 대한) cross entropy 설명 생략. y ∈ {±1}는 ground-truth class를 의미하고 p ∈ [0, 1]는 label y=1을 가진 class에 대한 모델의 추정 probability다. 표기의 편의를 위해 위와 같이 를 정의한다.
class imbalance를 다루는 흔한 방법은 class 1에 대해 weighting factor α ∈ [0, 1]을 도입하고 class -1에 대해 1−α를 도입하는 것이다. 실제로 α는 inverse class frequency로 설정되거나 (cross validation으로 설정되는) hyperparameter로 취급된다. 표기의 편의를 위해 도 와 같이 정의한다. α-balanced CE loss는 다음과 같다.
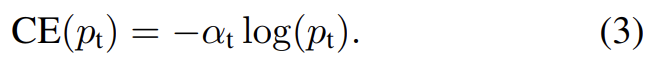
실험이 보여주겠지만 큰 class imbalance는 cross entropy loss를 압도한다. 쉽게 분류된 negatives가 loss의 대다수를 이루고 gradient를 지배한다. α가 positive/negative examples의 중요성을 balance하지만 easy/hard examples를 구분하지는 않는다. 대신 논문은 easy examples을 down-weight하고 hard negatives에 집중하도록 loss function을 바꾼다.
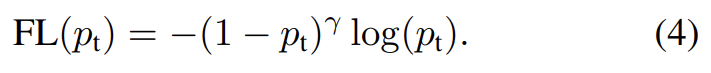
tunable focusing parameter γ ≥ 0를 가진 modulating factor 을 cross entropy loss에 추가한다. focal loss의 2가지 특징에 주목하라. (1) example이 잘못 분류되었고(misclassified) p_t가 작다면 modulating factor는 1에 가깝고 loss는 영향받지 않는다. pt → 1에 가까워지면 factor은 0으로 향하고 well-classified examples에 대한 loss는 down-weight된다. (2) focusing parameter γ가 easy examples가 down-weight되는 rate를 부드럽게 조정한다. γ = 0이면 FL은 CE와 동일하고 γ가 증가하면 modulating factor의 영향도 증가한다(실험에서 γ = 2가 가장 잘 작동함을 찾았다).
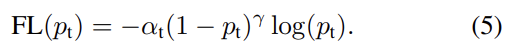
실제로는 focal loss의 α-balanced variant을 사용한다. non-α-balanced form보다 약간 더 향상된 정확도를 보이므로 실험에서 이 형태를 적용한다. 마지막으로 loss layer의 구현이 p 연산을 위한 sigmoid operation과 loss computation을 결합해 greater numerical stability를 낳음을 언급한다.
Binary classification models는 y = −1인지 1인지 동일한 probability로 출력하도록 디폴트로 초기화되었다. 그런 초기화와 class imbalance의 영향 아래에서 frequent class로 인한 loss가 전체 loss를 지배하고 학습 초기에 instability를 초래할 수 있다. 이를 위해 rare class (foreground)에 대해 model이 추정한 p 값에 대한 'prior' 개념을 start of training에서 도입한다. prior를 π로 표기하며, rare class의 examples에 대해 모델이 추정한 p가 낮도록(예컨대 0.01) 설정한다. 이는 loss function이 아니라 model initialization의 변경임에 주의하라. 이는 heavy class imbalance에서 FL과 CE 모두에 대해 training stability를 향상시켰다.
Two-stage detectors는 α-balancing나 focal loss를 사용하지 않고 CE로 학습된다. 그들은 대신 (1) two-stage cascade와 (2) biased minibatch sampling을 사용해 class 불균형을 다룬다. first cascade stage는 거의 무한한 possible object locations의 집합을 1~2000으로 줄여주는 object proposal mechanism이다. selected proposals는 랜덤이 아니며 true object locations에 상응해 많은 easy negatives을 대부분 제거한다. second stage를 학습할 때는 예컨대 1:3 비율로 positive와 negative examples을 보유한 minibatches를 구성하기 위해 biased sampling이 일반적으로 사용된다. 이 비율은 sampling을 통해 구현된 내재적인 α-balancing factor와 같다. 논문의 focal loss는 loss function을 통해 곧장 one-stage detection system에 이런 mechanisms을 다루도록 디자인되었다.
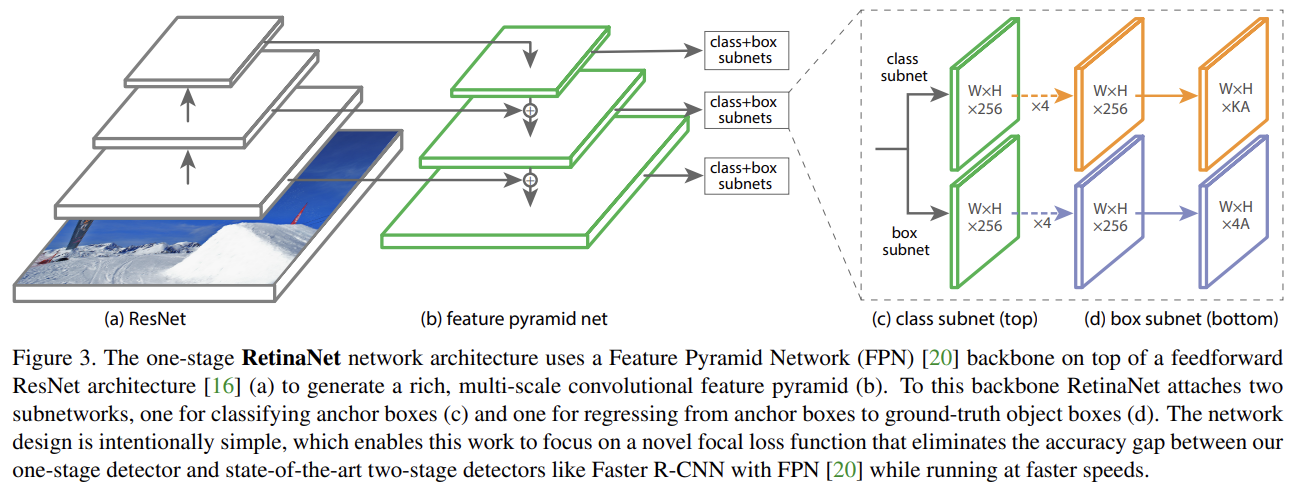
RetinaNet은 backbone network와 2 task-specific subnetworks로 구성된 단일한 unified network다. backbone은 전체 input image에 대한 convolutional feature map을 연산하는 off-the-self convolutional network이다. 첫번째 subnet은 backbone의 output에 convolutional object classification을 수행한다. 두번째 subnet은 convolutional bounding box regression을 수행한다. Fig 3에서 볼 수 있듯 두 subnetworks는 특히 one-stage, dense detection을 위해 제안된 간단한 디자인이다. RetinaNet의 각 요소는 다음과 같다.
- Feature Pyramid Network Backbone
backbone으로 Feature Pyramid Network (FPN)를 적용한다. FPN은 single resolution input image로부터 풍부한 multi-scale feature pyramid를 구성하도록 top-down pathway와 lateral connections를 가지고 일반적인 CNN을 확장한다. pyramid의 각 level은 다른 scale에서 사물을 감지하는 데 사용될 수 있다.
FPN 논문을 따라 FPN을 ResNet architecture 꼭대기에 짓는다. level P3~P7을 가진 pyramid를 건설했다. l은 pyramid level을 나타내며 은 input보다 배 낮은 resolution을 가진다. 원본 논문처럼 모든 pyramid levels는 C = 256 channels을 가진다.
- Anchors
FPN 논문의 RPN variant 내의 것들과 유사한 translation-invariant anchor boxes을 사용했다. anchors는 pyramid levels P3~P7에서 ~의 영역을 가졌다. FPN 논문처럼 각 pyramid level에서 3가지 aspect ratios {1:2, 1:1, 2:1}의 anchors을 사용했다. FPN 논문보다 denser scale coverage를 위해 각 level에서 3 aspect ratio anchors에 sizes 를 적용했다. 즉 level 당 A = 9 anchors가 있고 이들은 levels에 걸쳐 scale range 32 - 813 pixels를 cover한다.
각 anchor에 classification targets의 length K one-hot vector와 box regression targets의 4-vector가 할당된다. K는 object classes의 수다. RPN [28]로부터의 assignment rule을 사용하지만 multiclass detection을 위해 (조정된 thresholds와 함께) 변경되었다. 구체적으로 anchors은 intersection-over-union (IoU) threshold 0.5를 사용해 ground-truth object boxes에 할당되었고 IoU가 [0, 0.4) 사이에 있으면 background에 할당되었다. 각 anchor이 최대 1개의 object box에 할당되므로 length K label vector 내 상응하는 entry를 1로, 모든 나머지 entries를 0으로 설정했다. overlap이 [0.4, 0.5) 내라서 anchor이 할당되지 않았다면 training 중 anchor는 무시된다. Box regression targets는 각 anchor와 anchor가 할당된 object box 사이 offset으로 연산되며 assignment가 없으면 생략된다.
- Classification Subnet
classification subnet은 각 A anchors와 K object classes에 대해 각 spatial position에서 object presence의 확률을 예측한다. 이 subnet은 각 FPN layer에 부착된 작은 FCN이다. subnet의 parameters는 모든 pyramid levels에 걸쳐 공유된다. 디자인은 간단하다. 주어진 pyramid level에서 C channels을 가진 input feature map을 받아 subnet은 각각이 C filters를 가지며 ReLU activations이 뒤따르는 4 3×3 conv layers를 적용하며, KA filters를 가진 3×3 conv layer가 뒤따른다. 마지막으로 spatial location 당 KA binary predictions을 출력하기 위해 sigmoid activations이 부착된다. 대부분 실험에서 C = 256와 A = 9를 사용한다.
RPN과 달리 object classification subnet은 더 깊고 3×3 convs만 사용하고 box regression subnet과 parameters를 공유하지 않는다. 이러한 higher-level design decisions이 특정 hyperparmeter 값보다 중요했다.
- Box Regression Subnet
각 anchor box에서 근처 ground-truth object로의 offset을 regress하기 위해 각 pyramid level에서 object classification subnet과 평행하게 다른 작은 FCN을 부착한다. box regression subnet의 디자인은 classification subnet와 동일한데 spatial location 당 4A linear outputs로 끝난다는 것만 다르다. spatial location 당 각 A anchors에 대해 이 4 outputs는 anchor와 ground-truth box 사이 상대적인 offset을 예측한다(R-CNN [11]로부터의 standard box parameterization을 사용한다). 최근 연구와 달리 더 적은 parameters를 쓰는 class-agnostic bounding box regressor을 사용하며 이것이 동등하게 효과적이었다. object
classification subnet과 box regression subnet은 공통적인 구조를 공유하지만 parameters는 따로 사용한다.
- Inference
inference는 단순히 image를 네트워크에 통과시키면 된다. 속도 향상을 위해 detector confidence를 0.05에서 thresholding한 후 FPN level 당 최대 1k top-scoring predictions로부터의 box predictions만 decode한다. 모든 level에서의 top predictions는 합쳐지고 threshold 0.5의 non-maximum suppression이 적용되어 final detections을 만든다.
- Focal Loss
classification subnet의 output에 대한 loss로 focal loss가 도입된다. γ = 2가 잘 작동하며 RetinaNet은 γ ∈ [0.5, 5]에 강인했다. RetinaNet을 학습할 때 focal loss가 각 sampled image의 모든 ∼100k anchors에 적용되었음에 주목해라. 이는 heuristic sampling (RPN)이나 hard example mining (OHEM, SSD)을 사용해 각 minibatch에 대해 small set of anchors (예컨대 256)을 선택하는 일반적인 방법들과 비교된다. image의 total focal loss은 모든 ∼100k anchors에 대한 focal loss의 합을 ground-truth box에 할당된 anchors의 수로 noramlize한 것이다. 전체 anchor 수가 아니라 할당된 anchor 수로 normalize하는데, 왜냐하면 대부분의 anchors는 easy negatives이고 focal loss 하에 무시할만큼 작은 loss 값을 내기 때문이다. rare class에 할당된 weight인 α도 stable range를 가지지만 γ와 상호작용하므로 둘을 함께 선택하는 것이 필수적이다. 일반적으로 γ가 증가되면 α는 약간 감소되어야 한다(γ = 2일 때는 α = 0.25가 가장 잘 작동했다).
- Initialization
ResNet-50-FPN와 ResNet-101-FPN backbones로 실험했다. base ResNet-50와 ResNet-101 models은 ImageNet1k에 pre-train되었다. FPN을 위해 새로 추가된 layers는 FPN 논문에 따라 초기화되었다. 마지막 놈을 제외한 나머지 모든 새로운 conv layers는 bias b = 0와 σ = 0.01를 가진 Gaussian weight으로 초기화되었다. classification subnet의 final conv layer에 대해서는 bias initialization을 b = − log((1 − π)/π)로 설정했다. π는 start of training에서 모든 anchor이 ∼π의 confidence를 가지고 foreground로 label되어야 함을 명시한다. π 값에 robust하지만 모든 실험에서 π = .01를 사용한다. 앞서 설명했듯 이 initialization은 training의 first iteration에서 대량의 background anchors가 크고 destabilizing loss 값을 생성하는 것을 예방한다.
(Optimization 생략)
COCO benchmark에 bounding box detection track을 실험한다.
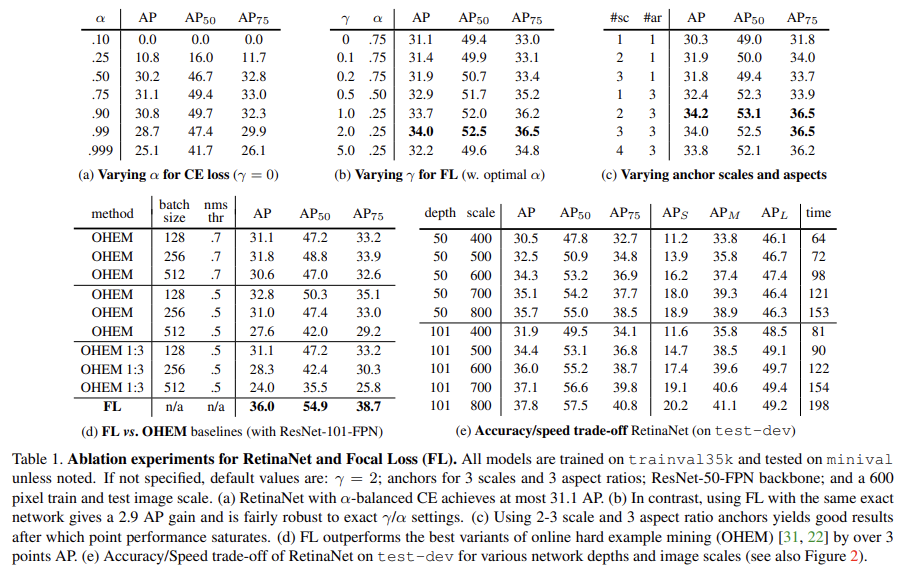
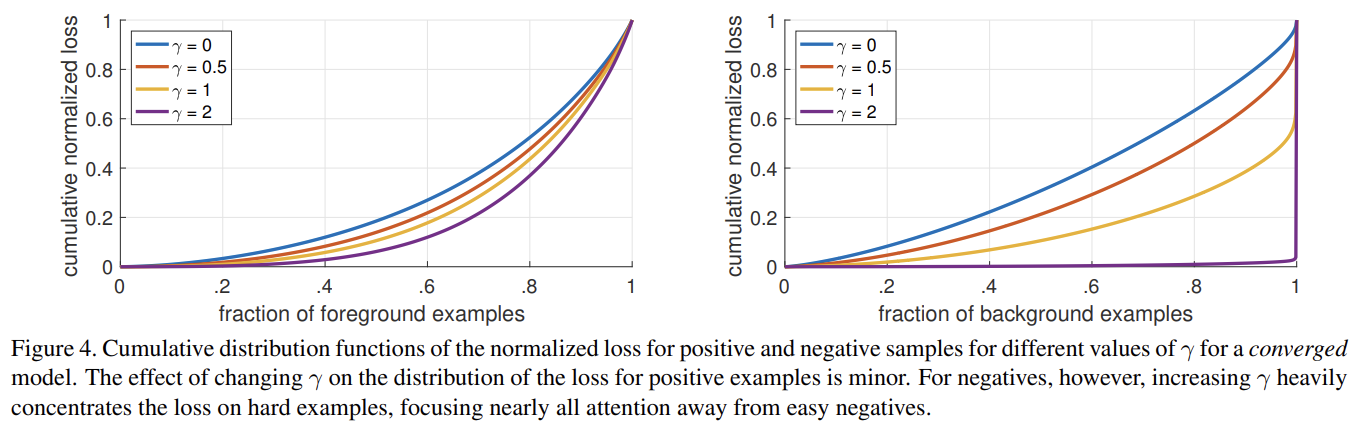
Fig 4는 positive와 negative samples에 대한 Cumulative distribution functions (CDF)을 보여준다. positive samples를 보면 CDF가 서로 다른 γ 값에서 비슷하게 보인다. 그러나 negative samples에서 γ의 효과는 극적으로 다르다. γ = 0일 때 positive와 negative CDF는 비슷하다. 그러나 γ가 증가할수록 hard negative examples에 더 많은 가중치가 집중된다. 디폴트 세팅인 γ = 2일 때 사실 대부분의 loss가 samples의 작은 일부에서 온다. 이렇듯 FL은 easy negatives의 효과를 효과적으로 무시하여 hard negative examples에 모든 관심을 집중할 수 있다.
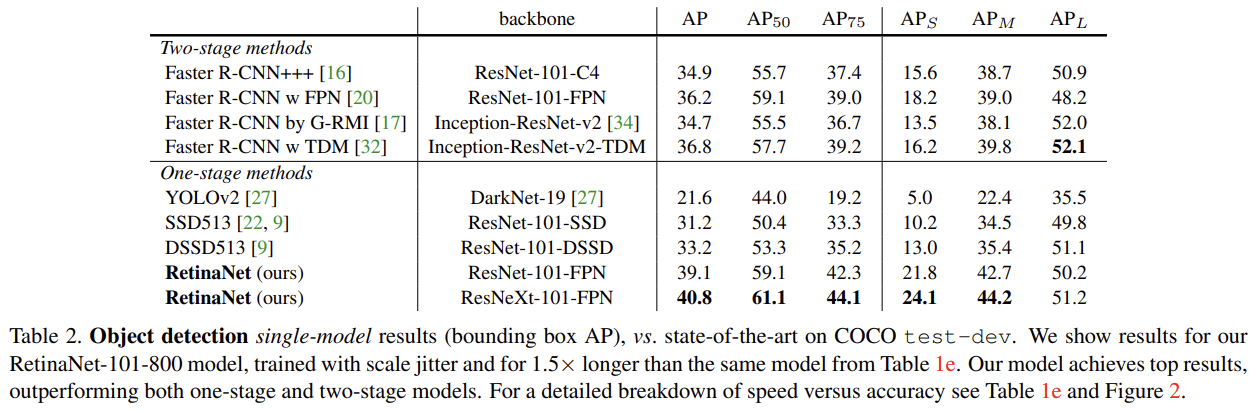
COCO dataset의 test-dev results에 RetinaNet을 SOTA와 비교한다.
Strengths
- focal loss를 통해 class imbalance를 해소할 수 있다. easy negative를 무시하고 hard negative의 loss를 강화해 잘못으로부터 배우는 능력을 강화한 점이 인상적이었다. 2 stage detector에서 하듯이 번거롭게 two-stage cascade나 biased minibatch sampling을 요구하지 않아 간단하다. 아이디어가 직관적이고 간단하고 강력하다.
focal loss라는 아이디어가 굉장히 좋았다. 좋은 논문이다.
