오늘 리뷰할 논문은 multimodal 2017년 survey다. multimodal machine learning 기법을 여러 갈래로 분류한 리뷰 논문이다.
포스트는 리뷰보다는 메모하는 식이다.
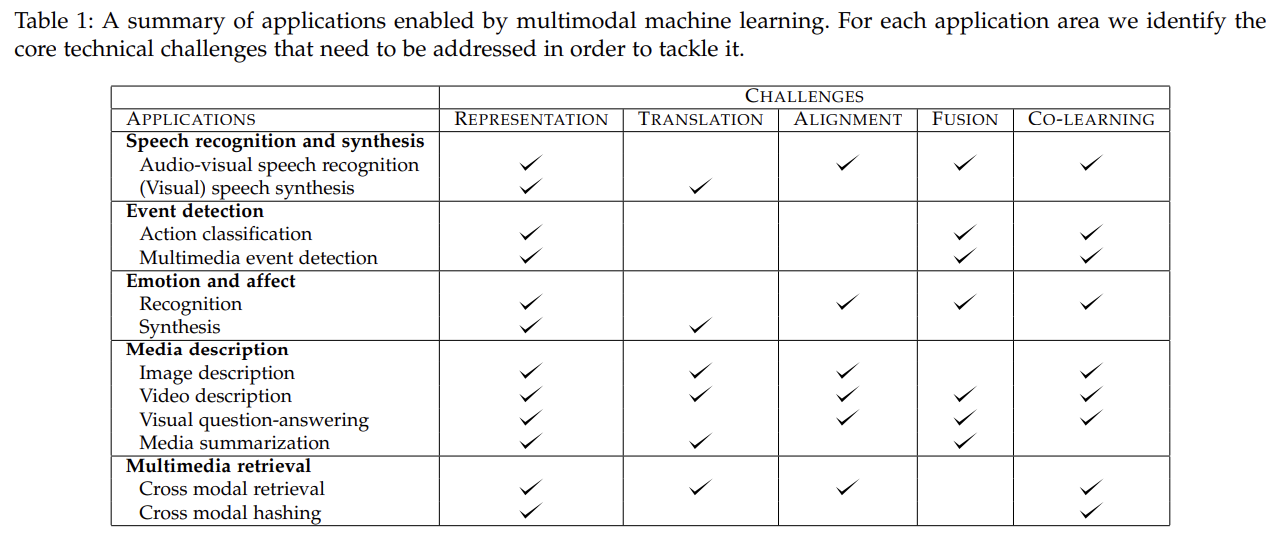
In this paper we identify and explore five core technical challenges (and related sub-challenges) surrounding multimodal machine learning.

- MULTIMODAL REPRESENTATIONS
Bengio et al. [18] identify a number of properties for good representations: smoothness, temporal and spatial coherence, sparsity, and natural clustering amongst others. Srivastava and Salakhutdinov [198] identify additional desirable properties for multimodal representations: similarity in the representation space should reflect the similarity of the corresponding concepts, the representation should be easy to obtain even in the absence of some modalities, and finally, it should be possible to fill-in missing modalities given the observed ones.
To help understand the breadth of work, we propose two categories of multimodal representation: joint and coordinated. Joint representations combine the unimodal signals into the same representation space, while coordinated representations process unimodal signals separately, but enforce certain similarity constraints on them to bring them to what we term a coordinated space.
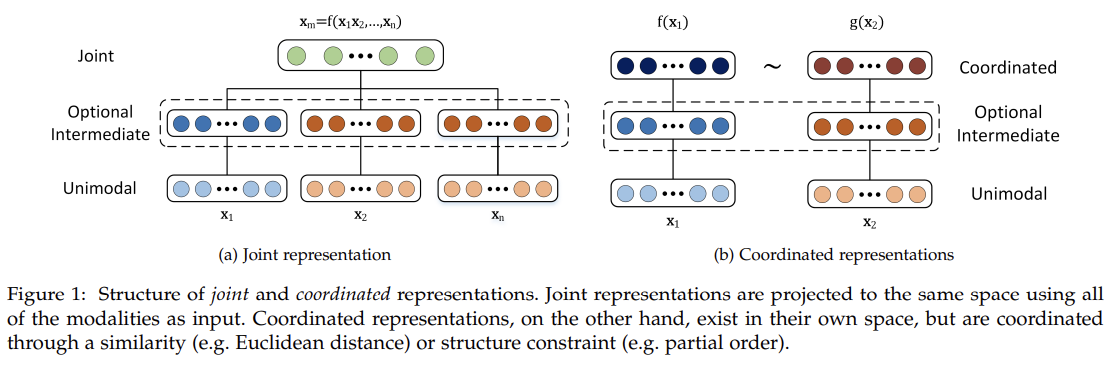
- Joint Representations
Joint representations are mostly (but not exclusively) used in tasks where multimodal data is present both during training and inference steps. The simplest example of a joint representation is a concatenation of individual modality features (also referred to as early fusion [50]).
joint representation을 얻는 방법으로는 neural networks와 Probabilistic graphical models이 있다.
The most popular approaches for graphical-model based representation are deep Boltzmann machines (DBM) [176], that stack restricted Boltzmann machines (RBM) [81] as building blocks. Similar to neural networks, each successive layer of a DBM is expected to represent the data at a higher level of abstraction.
One of the big advantages of using multimodal DBMs for learning multimodal representations is their generative nature, which allows for an easy way to deal with missing data — even if a whole modality is missing, the model has a natural way to cope. It can also be used to generate samples of one modality in the presence of the other one, or both modalities from the representation. Similar to autoencoders the representation can be trained in an unsupervised manner enabling the use of unlabeled data. The major disadvantage of DBMs is the difficulty of training them — high computational cost, and the need to use approximate variational training methods [198].
- Coordinated Representations
Instead of projecting the modalities together into a joint space, we learn separate representations for each modality but coordinate them through a constraint.
Similarity models minimize the distance between modalities in the coordinated space.
While the above models enforced similarity between representations, structured coordinated space models go beyond that and enforce additional constraints between the modality representations. The type of structure enforced is often based on the application, with different constraints for hashing, cross-modal retrieval, and image captioning.
- TRANSLATION
translating (mapping) from one modality to another. Given an entity in one modality the task is to generate the same entity in a different modality.
A particularly popular problem is visual scene description, also known as image [214] and video captioning [213],
While the approaches to multimodal translation are very broad and are often modality specific, they share a number of unifying factors. We categorize them into two types — example-based, and generative. Example-based models use a dictionary when translating between the modalities. Generative models, on the other hand, construct a model that is able to produce a translation.
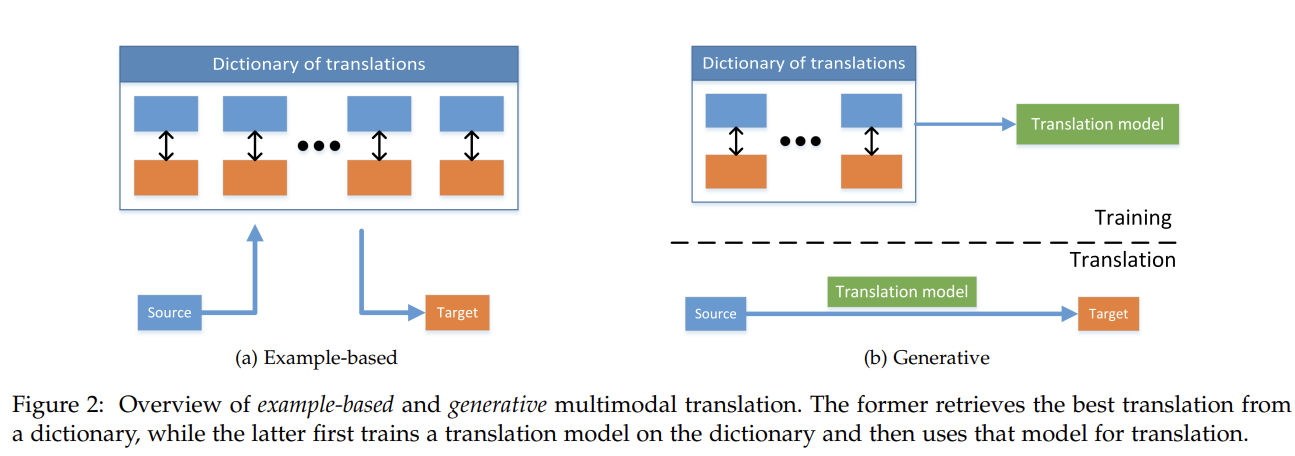
A major challenge facing multimodal translation methods is that they are very difficult to evaluate. Sometimes, as in language translation, multiple answers are correct and deciding which translation is better is often subjective. Fortunately, there are a number of approximate automatic metrics that aid in model evaluation.
Often the ideal way to evaluate a subjective task is through human judgment. That is by having a group of people evaluating each translation.
While human studies are a gold standard for evaluation, a number of automatic alternatives have been proposed for the task of media description: BLEU [160], ROUGE [124], Meteor [48], and CIDEr [211]. These metrics are directly taken from (or are based on) work in machine translation and compute a score that measures the similarity between the generated and ground truth text. However, the use of them has faced a lot of criticism.
These criticisms have led to Hodosh et al. [83] proposing to use retrieval as a proxy for image captioning evaluation, which they argue better reflects human judgments. Instead of generating captions, a retrieval based system ranks the available captions based on their fit to the image, and is then evaluated by assessing if the correct captions are given a high rank.
- ALIGNMENT
We define multimodal alignment as finding relationships and correspondences between sub-components of instances from two or more modalities.
We categorize multimodal alignment into two types – implicit and explicit. In explicit alignment, we are explicitly interested in aligning sub-components between modalities, e.g., aligning recipe steps with the corresponding instructional video [131]. Implicit alignment is used as an intermediate (often latent) step for another task, e.g., image retrieval based on text description can include an alignment step between words and image regions [99].
- FUSION
In technical terms, multimodal fusion is the concept of integrating information from multiple modalities with the goal of predicting an outcome measure: a class (e.g., happy vs. sad) through classification, or a continuous value (e.g., positivity of sentiment) through regression.
The interest in multimodal fusion arises from three main benefits it can provide. First, having access to multiple modalities that observe the same phenomenon may allow for more robust predictions. This has been especially explored and exploited by the AVSR community [163]. Second, having access to multiple modalities might allow us to capture complementary information — something that is not visible in individual modalities on their own. Third, a multimodal system can still operate when one of the modalities is missing, for example recognizing emotions from the visual signal when the person is not speaking [50].
We classify multimodal fusion into two main categories: model-agnostic approaches (Section 6.1) that are not directly dependent on a specific machine learning method; and model-based (Section 6.2) approaches that explicitly address fusion in their construction — such as kernel-based approaches, graphical models, and neural networks.
- CO-LEARNING
aiding the modeling of a (resource poor) modality by exploiting knowledge from another (resource rich) modality. It is particularly relevant when one of the modalities has limited resources — lack of annotated data, noisy input, and unreliable labels. We call this challenge colearning as most often the helper modality is used only during model training and is not used during test time. We identify three types of co-learning approaches based on their training resources: parallel, non-parallel, and hybrid.
Parallel-data approaches require training datasets where the observations from one modality are directly linked to the observations from other modalities. In other words, when the multimodal observations are from the same instances, such as in an audio-visual speech dataset where the video and speech samples are from the same speaker. In contrast, nonparallel data approaches do not require direct links between observations from different modalities. These approaches usually achieve co-learning by using overlap in terms of categories. For example, in zero shot learning when the conventional visual object recognition dataset is expanded with a second text-only dataset from Wikipedia to improve the generalization of visual object recognition. In the hybrid data setting the modalities are bridged through a shared modality or a dataset.
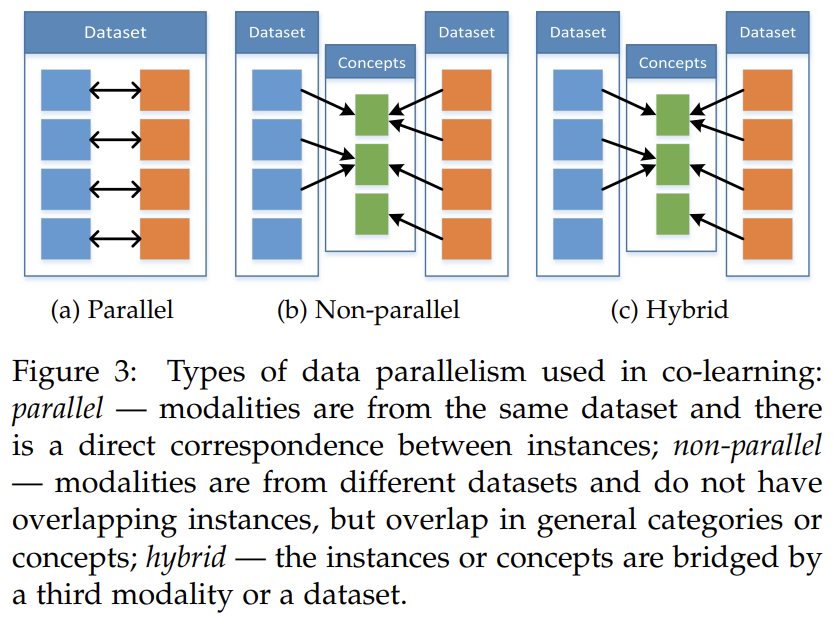
Multimodal co-learning allows for one modality to influence the training of another, exploiting the complementary information across modalities. It is important to note that co-learning is task independent and could be used to create better fusion, translation, and alignment models. This challenge is exemplified by algorithms such as co-training, multimodal representation learning, conceptual grounding, and zero shot learning (ZSL) and has found many applications in visual classification, action recognition, audio-visual speech recognition, and semantic similarity estimation.

The WalgreensListens survey is a customer satisfaction survey provided by Walgreens. It aims to gather feedback from customers regarding their shopping experience. The survey can be accessed at https://www.walgreensreceiptsurvey.co/start-survey/ and typically takes 5-10 minutes to complete. After finishing the survey everyone will get a chance to win a $3000 money reward.