오늘 리뷰할 논문은 self-supervised multimodal learning (SSML)에 관한 survey 논문이다.
포스트는 리뷰보다는 메모 형식이다.
In this survey, we review SSML algorithms and their applications. We decompose the various methods along three orthogonal axes: objective functions, data alignment, and model architectures.
Based on the pretext tasks, we classify the training objectives into instance discrimination, clustering, and masked prediction categories.
pretext task : self-supervised learning에서 일부러 구실을 만들어 푸는 문제
In the multimodal context, the term self-supervision has been used to refer to at least four situations: (1) Labelfree learning from multimodal data that is automatically paired – such as movies with video and audio tracks [23], or images and depth data from RGBD cameras [24]. (2) Learning from multimodal data where one modality has been manually annotated, or two modalities have been manually paired, but this annotation has already been created for a different purpose, and can thus be considered free for the purpose of SSML pretraining. For example, matching image-caption pairs crawled from the web, as used by the seminal CLIP [11], is actually an example of supervised metric-learning [25], [26] where the pairing is the supervision. However, because both the modalities and the pairing are all freely available at scale, it is often described as self-supervised. Such uncurated incidentally created data is often lower-quality and noisier than purposecreated and curated datasets such as COCO [22] and Visual Genome [27]. (3) Learning from high-quality purpose annotated multimodal data (e.g., manually captioned images in the COCO [22]), but with self-supervised style objectives, e.g., Pixel-BERT [28]. (4) Finally, there are ‘self-supervised’ methods that use a mix of free and manually annotated multimodal data [29], [30].
- Instance Discrimination
In unimodal learning, instance discrimination (ID) treats each instance in the raw data as a separate class, and the model is trained to differentiate between different instances. In the context of multimodal learning, instance discrimination often aims to determine whether samples from two input modalities are from the same instance, i.e., paired. By doing so, it attempts to align the representation space of the paired modalities while pushing the representation space of different instance pairs further apart. There are two types of instance discrimination objectives: contrastive and matching prediction, depending on how the input is sampled.
Contrastive methods typically use corresponding samples from two modalities as positive example pairs and noncorresponding samples as negative pairs. These pairs are then used to train a model to accurately distinguish positive and negative pairs using contrastive training objectives
Contrastive learning has also shown great potential for scaling up to larger models and datasets. CLIP [11] achieves strong zero-shot performance when pretraining on a large dataset of 400 million image-language pairs, by simply predicting the pairing.
Matching prediction, also known as alignment prediction, aims to predict whether a pair of samples from two input modalities are matched (positive pair) or not (negative pair). For example, if a piece of text corresponds to an image’s caption. A key difference between contrastive learning and matching prediction is that in a mini-batch, the former calculates the similarity between a positive pair and all of the other negative pairs, while the latter labels individual tuples as positive or negative.
- Clustering
Clustering methods assume that applying end-to-end trained clustering will lead to the grouping of the data by semantically salient characteristics. In practice, these methods iteratively predict the cluster assignments of the encoded representation, and use these predictions, also known as pseudo labels, as supervision signals to update the feature representation. Multimodal clustering provides the opportunity to learn multimodal representations and also improve conventional clustering by using each modality’s pseudolabels to supervise the other
- Masked Prediction
The masked prediction task can be either performed in an auto-encoding (similar to BERT [101]) or an auto-regressive approach (similar to GPT [102]).
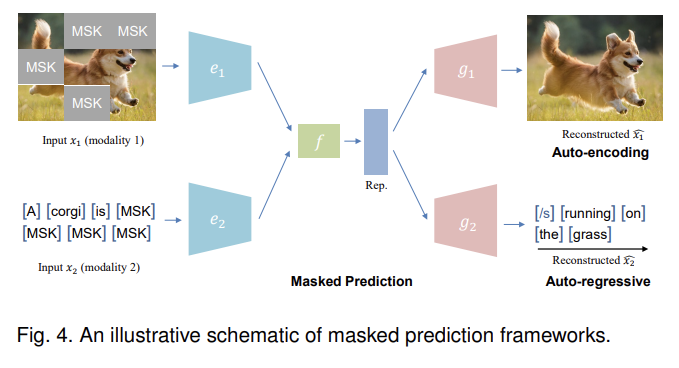
Auto-encoding based masked prediction objectives are comparatively more widely adopted for multimodal learning than auto-regressive based methods. One reason for this is that AE-based objectives are faster to train than AR-based methods, because AR-based methods generate output one at a time, which is especially important when pretraining on large-scale datasets. Also, AE-based methods can better utilize the surrounding (bidirectional) information to enhance cross-modal interactions. Nonetheless, AR-based methods have the advantage of enhancing generation ability, which is beneficial for generative downstream tasks such as image synthesis or captioning.
- Hybrid
The combination of contrastive and clustering objectives can be beneficial. As mentioned earlier, contrastive objectives may suffer from false negatives by ignoring semantic similarity between samples. On the other hand, the clustering objective takes semantic similarity into account by grouping semantically similar samples into the same cluster.
- ALIGNMENT OF DATA
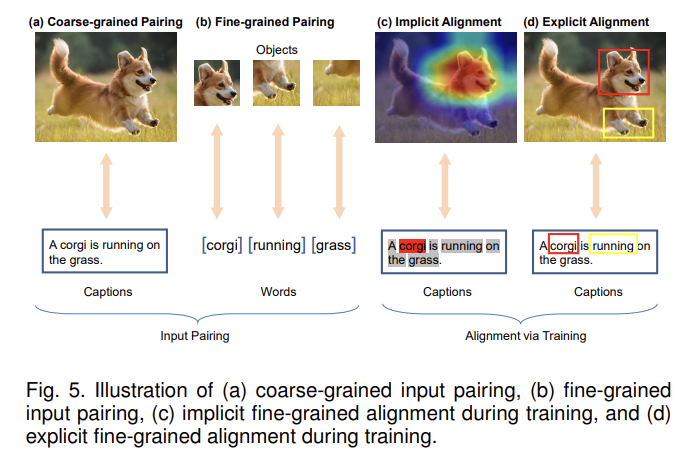
Pairing, or alignment, of data between modalities can be established at both coarse and fine-grained levels Fig. 5 (a)(b). Such pairing is often assumed as an input by SSML algorithms, but can also be inferred as a byproduct of learning Fig. 5 (c)(d)

The Walgreenslistens survey is a customer satisfaction survey conducted by Walgreens, a popular pharmacy store. It aims to gather feedback from customers about their shopping experience at Walgreens. The survey typically includes questions about the store's cleanliness, staff behavior, product availability, and overall customer satisfaction. You can also get a chance to win a $3000 money reward through Walgreens Listens Survey at https://www.walgreensreceiptsurvey.co/.