1. Abstract
LLM의 in-context learning (ICL) 원리에 대한 연구 결과가 항상 일관적이지는 않다. 논문은 ICL mechanisms을 평가할 framework를 제안하며 ICL이 retrieving internal knowledge와 learning from in-context examples의 조합이라고 주장한다.
논문은 regression task에 집중하는데, 먼저 LLM이 real-world regression problems을 풀 수 있음을 보이고 internal knowledge을 검색하는 정도 vs in-context examples로부터 학습하는 정도를 측정하는 실험 설계한다. 논문은 task에 대한 prior knowledge, in-context 예시에서 제공된 정보의 종류와 풍부함 등의 요소에 따라 두 메커니즘이 어느 정도로 촉진되는지에 대한 분석을 제공한다.
이를 통해 논문은 in-context examples로부터 meta-learning를 활용하는 prompt engineering 방법과 문제에 따른 knowledge retrieval을 촉진하는 방법을 제공한다.
2. Introduction
zero-shot과 ICL이 둘 다 가능한 setting의 경우 ICL이 일관적으로 zero-shot보다 성능이 좋다. (Brown et al., 2020; Liu et al., 2022)
최근 연구는 ICL 원리를 Meta learning, Knowledge retrieval 2가지로 설명한다. Meta learning으로 LLM은 in-context examples에서 unseen pattern을 새로 배우고 새 input에 일반화할 수 있다. 반면 knowledge retrieval의 측면에서 LLM은 in-context examples을 parameter에 저장된 정보를 접근하는 신호로 사용한다.
논문은 ICL이 이 두 극단 사이의 spectrum으로 작동하며 다양한 factor로 조정할 수 있다고 주장한다.

이 관점에서 논문은 evaluation framework를 제안하고 regression problem에 집중해 여러 LLM과 datasets에 comparative study를 한다. 이 framework에선 LLM이 ICL examples을 보고 set of (feature, value) pairs를 바탕으로 output number를 추측하게 한다.
regression task를 사용하는 이유는
1. 기존 ICL meta learning 연구와 정렬이 가능해서 직접 비교와 기존 발견의 확장에 용이하고
2. (Bhattamishra et al., 2024)에 따르면 ICL 능력은 input/output module과 독립적으로 LLM의 중간 layers에 위치하고 있고
3. output space가 복잡해서 LLM에게 challenging하기 때문이다.
논문은 LLM이 realistic datasets에 regression을 수행할 수 있음을 보이고 in-context examples에서 배우는 것에 비해 internal knowledge를 retrieve하는 정도를 측정한다. 그리고 number of (feature, value) pairs, number of in-context examples, prompting strategies에 따라 이 정도가 어떻게 달라지는지 분석한다.
3. Problem Setting
데이터셋 구조: D = {(x₁, y₁), (x₂, y₂), ..., (xₙ, yₙ)}
xᵢ = {(fᵢⱼ, vᵢⱼ)}
xᵢ : (특성명, 값) 쌍들의 집합
fᵢⱼ: 특성명 (feature name)
vᵢⱼ: 특성의 수치값 (numerical value)
yᵢ : 출력의 수치값 (target variable)
학습용 맥락 예시: D의 in-context split에서 m개 예시 선택 {(x₁, y₁), (x₂, y₂), ..., (xₘ, yₘ)} 테스트 쿼리: D의 test split에서 feature pairs of x를 제시하여 답 y 획득
m = 0은 zero-shot setting을 의미한다
Figure 1에서 볼 수 있듯 3개의 prompt configuration + baseline prompt을 사용
Named Features (Configuration a): feature, required target variable 이름을 prompt에 명시한다.
Anonymized Features (Configuration b): feature와 target variable 이름을 “Feature #”, “Output”으로 바꿔 숨긴다. 따라서 LLM이 domain knowledge를 사용할 수 없고 제공된 숫자만 사용할 수 있다.
Randomized Ground Truth (Configuration c): feature 명을 유지하지만 ground truth values를 Gaussian 분포로 랜덤하게 생성한 숫자로 바꾼다. 이는 LLM이 제공된 ground truth에서 실제로 얼마나 배우는지를 실험할 수 있게 한다.
Direct Question Answering (Direct QA): LLM baseline을 설정하기 위한 것으로, in-context examples 없이(m=0) named features를 주고 target variable을 예측하게 한다. 이때 output scope을 정의하기 위해 instruction에 데이터셋의 mean, standard deviation 정보를 제공해준다.
각 prompt는 task instruction, in-context examples (sample regression task input-outputs), query의 3가지로 구성된다.
모델은 LLaMA 3 70B (AI@Meta, 2024), GPT3.5 (Brown et al., 2020), GPT4 (OpenAI, 2023)을 사용했다.
비교를 위해 classical machine learning 기술 중 Ridge regression (Hoerl and Kennard, 1970), RandomForest model (Breiman, 2001)도 사용했다.
각 데이터셋에 대해 다음 factors의 조합으로 LLM을 테스트했다.
1. prompt configurations (Named Feature, Anonymized Features, Randomized Ground Truth, Direct QA)
2. number of in-context examples (0, 10, 30, 100)
3. number of (feature, value) pairs (1, 2, 3)
feature은 중요도 순서로 정렬해서 첫 번째만 쓰는 경우를 F1, 첫 두 개를 쓰는 경우를 F2, 세 개 다 쓰는 경우를 F3로 칭한다.
evaluation metric은 Mean Squared Error (MSE)을 사용했다. coefficient of determination R2, Mean Absolute Error (MAE)도 기록했다.
4. Experiments
3개의 regression 데이터셋을 선택했고 features의 중요도를 RandomForest로 계산해 가장 중요한 3개 features를 선택했다.
- Admission Chance : 인도 학생들의 대학원 입학 확률 예측. 3 features의 상관관계가 높고, 인도 학생 데이터라 LLM 훈련 데이터에 있을 가능성이 낮다.
- Insurance Cost : 미국 개인 연간 의료비 예측. 첫 번째 feature(흡연 여부)이 압도적으로 중요.
- Used Car Prices : 2019년 중고 토요타/마세라티 차량 가격 예측, 처음 두 특성이 가장 영향력 있음.
가장 중요한 features를 선택하도록 datasets을 전처리했고, 100 instances를 가진 in-context subset과 300 instances를 가진 test subset으로 split했다.
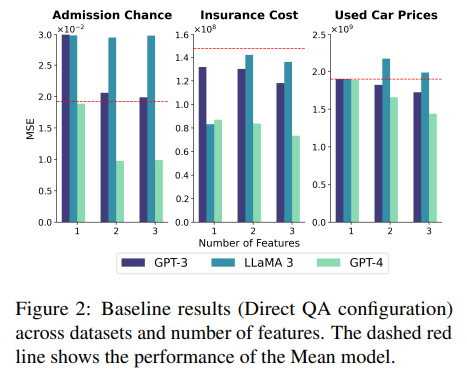
baseline 구축을 위해 in-context examples 없이 오직 knowledge retrieval만 이용한 LLM의 성능을 평가했다. Figure 2는 Direct QA prompt를 사용한 결과이며 추가적인 features가 일반적으로 성능을 향상시킴을 보여준다. 하지만 features 활용이 feature importance와 직접적인 상관관계는 없었다. Admission Chance가 가장 성능이 나빴고 이는 앞선 추측(인도 학생 데이터라 LLM 훈련 데이터에 있을 가능성이 낮다)과 일치한다.
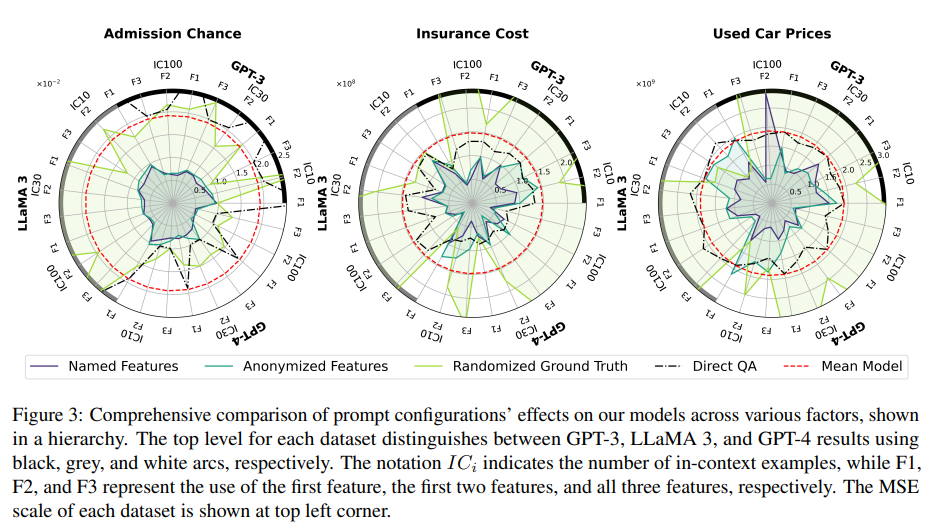
Learning/Knowledge Retrieval 상호작용을 실험했다. Randomized Ground Truth prompt가 가장 나쁜 결과를 보였다. 이는 LLM의 internal knowledge와 주어진 data pattern이 모순되는 상황이다. in-context examples이 많아질수록 부정적인 영향이 커졌다. 이는 LLM이 output variable을 실제로 학습에 활용함을 증명하며 in-context examples을 늘릴수록 knowledge retrieval에서 learning으로 스펙트럼이 이동함을 보여준다.
Named Features prompt와 Anonymized Features prompt 결과를 비교하면 두 패러다임을 조합하는 것의 힘을 알 수 있다. Anonymized Features prompt는 Direct QA나 Mean model보다 좋은 성능을 보인다. Named Features prompt는 feature 이름을 제공하여 Anonymized Features prompt보다 일관되게 성능이 뛰어나다. 이는 LLM이 in-context example을 통한 learning과 features 이름을 단서로 사용한 knowledge retrieval을 모두 활용함을 보여준다.
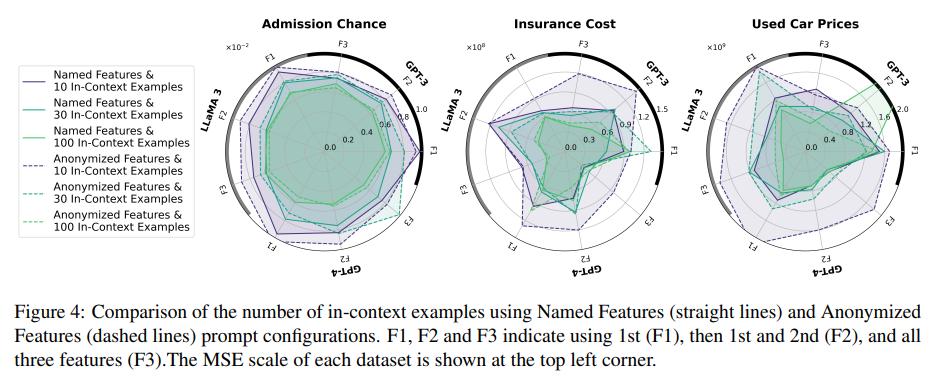
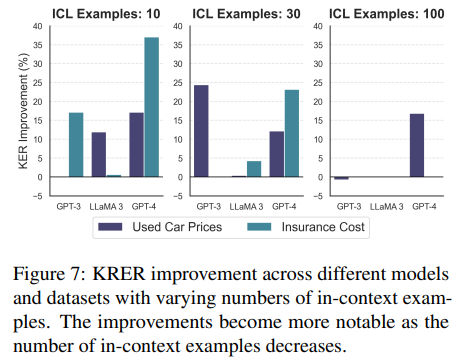
일반적으로 in-context examples 수가 많아질수록 성능이 향상될 거라 기대하지만, Figure 3에서 볼 수 있듯 output이 random일 때는 성능이 악화됐다. Figure 4는 in-context examples 수가 적을 때 Anonymized Feature prompt보다 Named Feature prompt가 더 성능이 좋음을 보여준다. 이는 task-specific information(feautre 명 같은)을 제공함으로써 learning에서 knowledge retrieval로 spectrum을 이동시켜 필요한 in-context examples을 감소할 수 있다는 것을 보여준다.
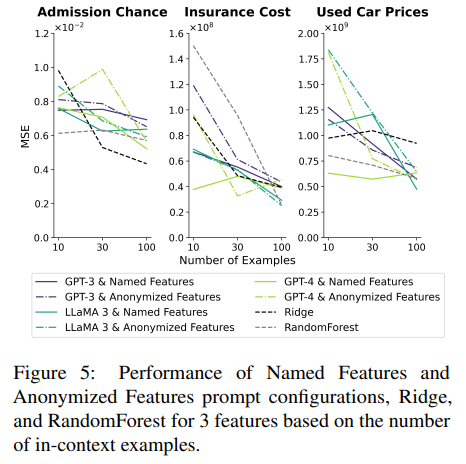
Figure 5는 Named Features prompt가 여러 in-context examples 수 세팅에서 Anonymized Features prompt뿐 아니라 traditional ML models보다 뛰어남을 보여준다. examples 수가 적을수록 성능이 더 뛰어났다. 이는 LLM의 knowledge retrieval 능력을 보여주며 이것이 LLM을 data-efficient하게, 즉 few-shot learner로 만들어준다. 하지만 이 장점은 low-data regime에 적용되며 LLM의 training/execution cost는 고려하지 않은 것이다. 충분한 데이터(100 examples)가 주어졌을 때 모든 모델은 성능이 수렴한다.
in-context examples 수와 달리 features 수는 learning과 knowledge retrieval을 모두 향상시킨다. 추가적인 feature가 제공될수록 LLM은 features와 outputs관계를 더 잘 배울 수 있고 관련된 지식도 retrieve할 수 있다.
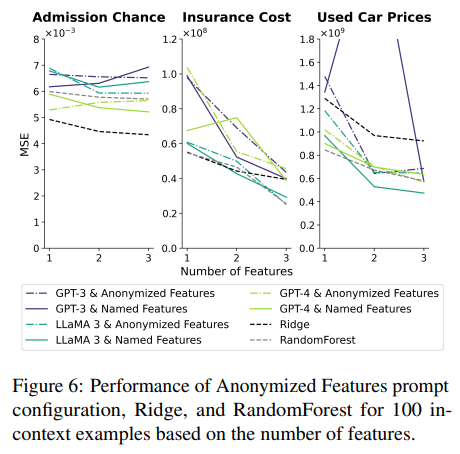
learning에만 의존하는 Anonymized Features prompt는 features 추가에 따라 일관적으로 성능이 향상된다. 예시 100개를 제공하는 세팅에서 feature을 추가하면 성능이 향상되거나 최적에 근접한 성능을 유지한다. 성능 향상은 traditional ML 모델보다 LLM에서 더 두드러졌다. 그런데 feature 이름이 가려졌고 수치만 주어졌는데 LLM 성능이 feature importance와 상관관계가 없었다는 점에서 LLM이 숫자 조합을 기억하고 있어서 성능이 향상된 것이 아닌가하는 data contamination 추측이 제기됐다. 실제로 LLM이 학습하지 못했을 Admission Chance dataset에선 이 현상이 발생하지 않았다.
Named Feature prompt에선 전반적으로 성능이 향상됐지만 Anonymized Features prompt만큼 일관적이지 않았다. 이는 feature 수가 증가할수록 learning보다 knowledge retrieval의 비중이 더 커짐을 보여준다.
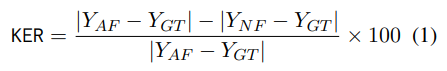
정량 분석을 위해 Knowledge Effect Ratio (KER)라는 지표를 도입하며, 이는 knowledge (named features) 추가로 인한 오류 감소율을 의미한다.
Y_AF : Anonymized Features의 prediction
Y_NF : Named Features의 prediction
Y_GT : Ground Truth
각 데이터셋과 factor 조합별로 KER을 계산했고, outlier의 영향을 줄이기 위해 중간값(median)을 선택했다. 예상대로 Admission Chance 데이터셋에서 거의 모든 factor 조합에서 KER이 near zero 값을 보였고, 이는 LLM이 이 데이터셋에 knowledge retrieval 효과가 없음을 입증한다. LLM이 지식을 보유중인 다른 데이터셋에서는 계속 성능 향상이 보였고, 앞선 실험 결과들처럼 in-context examples가 적을 때 효과가 더 두드러졌다.
5. Discussion
ICL 메커니즘을 이해하고 조작하는 것은 실용적 응용과 효과적인 프롬프트 엔지니어링에 매우 가치가 있다. in-context examples 증가는 learning을 장려하고 더 많은 features는 knowledge retrieval을 촉진한다. 이런 혜택들은 해당 메커니즘에 개선의 여지가 있을 때만 나타난다. 예를 들어 예시가 100개를 넘어가도 더 도움이 되지 않는다.
의미 있는 features 수와 in-context examples 수 사이 최적의 균형이 중요하다. 전자를 증가시키고 후자를 감소시키면 resource efficiency, mitigiating data bias 등의 장점이 있다. 역으로 전자를 감소시키고 후자를 증가시키면 모델이 learning에 집중해서 unfamiliar task를 다루는 데 유리하다.
이 연구는 LLM이 low-data regime에서 pre-trained knowledge를 활용하여 classical ML보다 data 효율적일 수 있음을 보인다. 하지만 학습과 배포에 연산 리소스는 더 필요하다.
feature importance와 무관한 성능 향상이 존재했고, 이는 numerical level에서도 data contamination이 발생함을 시사한다.
Direct QA prompt에서 3개의 features 제공 순서를 변형하여(6 permutation) 실험했을 때 LLM의 성능이 비슷했다. 반면 Anonymized Features에서 label 값으로 10개/100개의 in-context examples을 정렬했을 때는 모두 성능 저하가 발생했다. 이는 LLM의 sorting pattern 감지 능력으로 인해 LLM이 feature간 관계보다 sorted label pattern을 우선시하기 때문으로 추측된다. 따라서 example 순서는 랜덤으로 두는 것이 좋다.
6. 개인적인 평
learning, knowledge retrieval의 비율을 컨트롤하려는 시도가 흥미롭다.
그런데 LLM이 숫자에 강하지 않다고 생각되는데 regression task에 국한시킨 점이 아쉽다. 특히 feature 수 조작의 경우에는 일반적인 in-context learning 상황으로 확장시키는 데 제한이 있을 것 같다.
random gaussian 값으로 output을 변형한 오염된 세팅을 만들어서 LLM이 실제로 learning을 활용하는 것을 보이는 prompt setting이 인상적이다.
LLM이 학습하지 않았을 것 같은 데이터셋을 활용해 knowledge retrieval을 못함을 보이는 게 흥미로웠다. KER은 LLM이 특정 데이터셋을 학습에 사용했는지, memorizing을 하고 있는지 검증하는 데 사용할 수 있을 것 같다.
in-context learning 시 example 제공 순서도 중요하다는 점을 배웠다.
