1. Abstract
적은 수의 observations에서 일반적인 rule을 추론하는 inductive reasoning에서 여러 hypothesis를 sampling해 가장 좋은 것을 선택하는 방식이 있다. 그러나 IID sampling으로 인해 hypothesis가 redundant하게 생성되어 연산을 낭비시킨다.
논문은 1. temperature 조작으로 diversity를 늘리는 방식은 text degeneration으로 인해 한계가 있음을 밝히고 2. quality를 유지하면서 diversity를 향상시키는 방식 Mixture of Concepts (MoC)을 제안한다.
2. introduction & Method
temperature을 올리면 hypotheses quality가 저하되고 text degeneration 발생률이 증가해서 diversity와 accuracy는 특정 지점까지만 상승하고 포화된다.
논문의 Mixture of Concepts (MoC) 방법은 concept proposal, hypothesis generation 2단계로 이루어진다. concept proposal에선 hypotheses 형성에 도움이 될, 의미적으로 redundant하지 않은 list of K concepts를 sequentially 생성하고 hypothesis generation에선 hypothesis를 생성하는 데 concept를 힌트로 제공한다. 이 방식으로 hypothesis quality를 해치지 않고 의미적으로 다양한 hypotheses를 parallel generation이 가능하다.
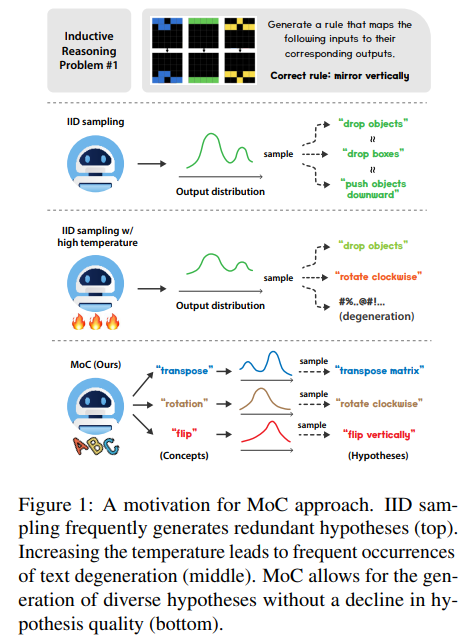
baseline : 최근 inductive reasoning과 Programming-by-Example (PBE) literature의 setup 사용. python function으로 f를 추론하고 그것으로 test output을 구한다. (Qiu et al., 2024; Wang et al., 2024b) 방식처럼 자연어로 f에 대한 hypothesis를 생성하도록 LLM prompting하고 python으로 구현한다. K responses를 sample하고 거기서 python function을 추출해 hypothesis pool을 형성한다. train example을 가장 잘 설명하는 hypothesis를 골라 test example에 적용한다. 그런 hypothesis가 없으면 문제 해결을 실패한 것이며, f가 모든 test case에 성공해야 문제가 해결된 것이다.
문제는 semantically redundant hypotheses가 나올 수 있는 거고 부정확한 게 여러 번 sample되면 연산을 낭비하게 되니 baseline이 문제 해결에 실패했을 때 hypotheses가 얼마나 unique한지 분석한다. GPT-4o mini (gpt-4o-mini-2024-07-18), temperature value of 1을 baseline으로 List Functions dataset (Rule, 2020)에 실험했다. 두 Python hypotheses에 동일한 input을 넣으면 동일한 output이 생성될 때 동일한 hypotheses라고 간주했다.

특히 K가 클 때 대다수가 redundant하다.
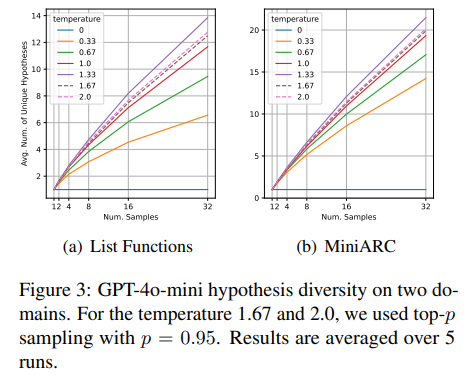
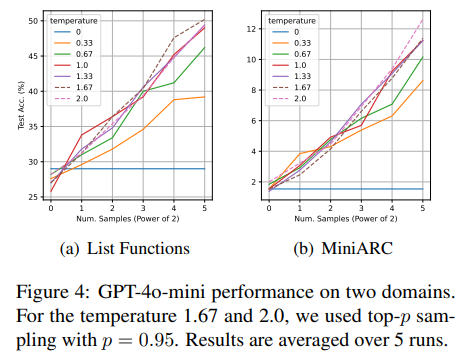
List Functions, MiniARC (Kim et al., 2022) 데이터셋으로 temperature을 변화시킬 때 diversity를 실험했다. 1.67부터 크게 달라지지 않는 현상이 관측된다. accuracy의 경우도 동일하게 1까지만 장점이 있었고 이후로는 비슷했다.
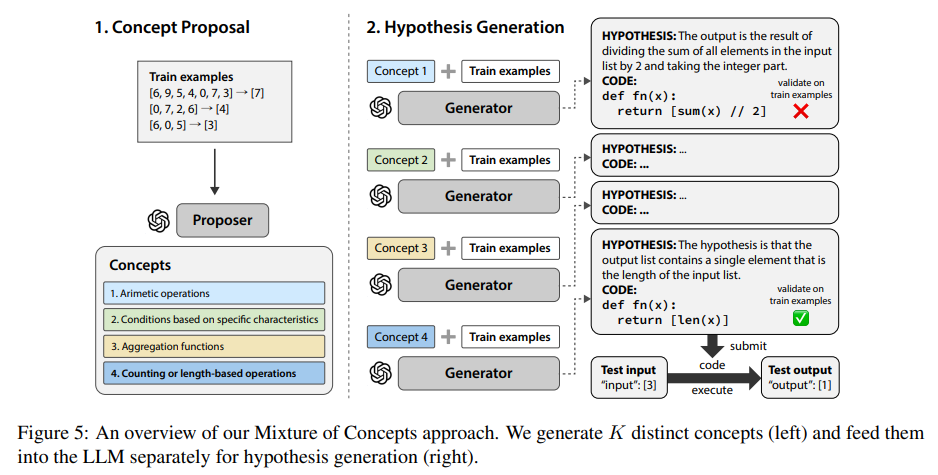
MoC는 concept proposal, hypothesis generation 단계를 거친다.
-
Concept Proposal
AR 특성 덕분에 LLM이 list of items을 생성할 때 items가 거의 redundant하지 않다. 따라서 JSON format으로 K elementary concepts를 생성하고 이를 바탕으로 hypothesis를 만들도록 한다. -
Hypothesis Generation
concepts을 parse해서 LLM에 각각 먹이고 hypothesis를 생성한다. 모든 train examples를 만족하는 hypotheses를 최종으로 선택한다.
3. Experiments & Results

다음 4 datasets에 실험한다.
- List Functions dataset (Rule, 2020) : list transform functions을 추론한다.
- MiniARC (Kim et al., 2022) : Abstraction and Reasoning Corpus (ARC) dataset (Chollet, 2019)의 간단한 버전으로 2D grid를 transform하는 패턴을 찾는 과제다.
- MBPP+ (Liu et al., 2023) : program synthesis dataset MBPP (Austin et al., 2021)를 35배 늘린 것이다. Python programming tasks을 다룬다.
- Playgol-str : real-world string transformations dataset이다.
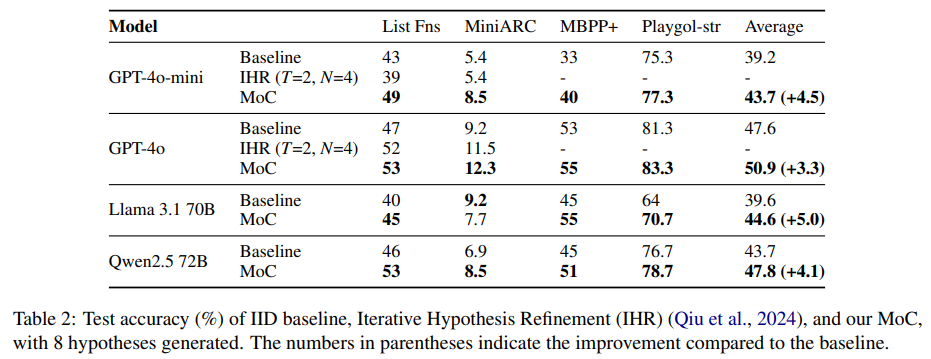
실험은 4개의 LLM 사용, GPT4o-mini (gpt-4o-mini-2024-07-18), GPT-4o (gpt-4o-2024-08-06), Llama-3.1-70B-Instruct, Qwen2.5-72B-Instruct. 분석 결과를 바탕으로 Temperature = 1 사용, K = 8.
Iterative Hypothesis Refinement (IHR) (Qiu et al., 2024)와도 비교했다. IHR은 생성된 hypothesis를 training examples로 검증하고 실패 시 가장 높은 정확도의 hypothesis를 feedback해서 정제하는 방식이다.
GPT-4o: IHR도 좋은 성능, 하지만 MoC가 여전히 우수
GPT-4o-mini: IHR이 baseline보다 못함, MoC는 일관된 개선
MoC: 모델 성능에 관계없이 일관된 향상
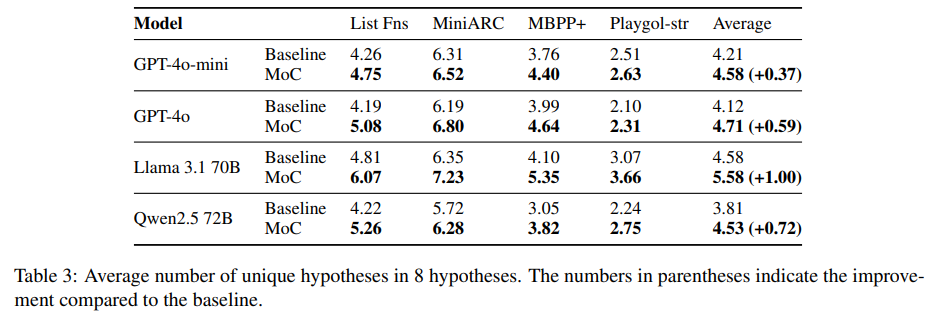
MOC는 diversity 또한 증가시켰다.
4. Discussion
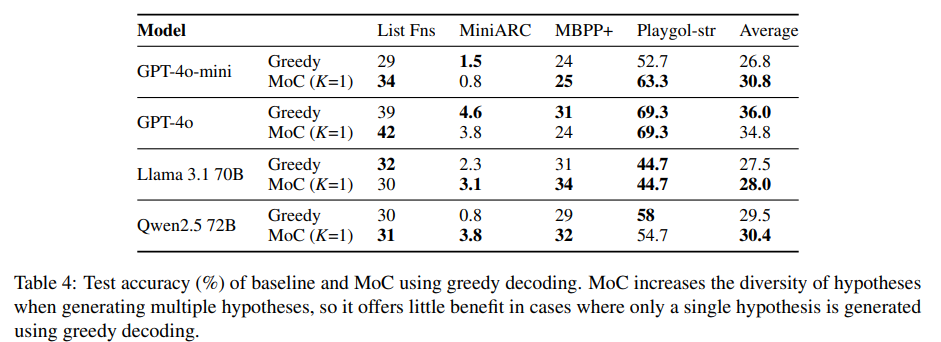
- Does the benefit of MoC arise from hypothesis diversity or from an improvement in reasoning?
중간 단계를 통해 LLM의 reasoning 능력을 향상시킨다는 점에서 CoT와 유사. reasoning ability의 이점을 hypothesis diversity와 구분하기 위해 temperature을 0으로 두고 하나의 hypothesis만 생성해 accuracy 향상이 있는지 확인했다. 그러나 일관된 개선이 없었고, MoC의 이점은 주로 가설 다양성 증가에서 기인한다고 볼 수 있다.
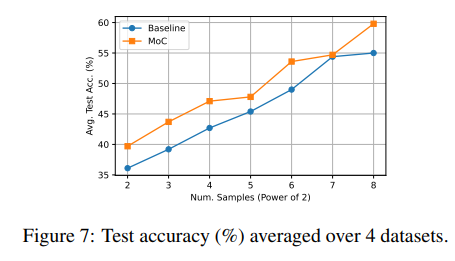
- What impact does scaling compute have on the MoC?
baseline, MoC 모두 K 증가 시 성능 개선, MoC가 절반의 가설로 baseline과 유사한 성능 달성
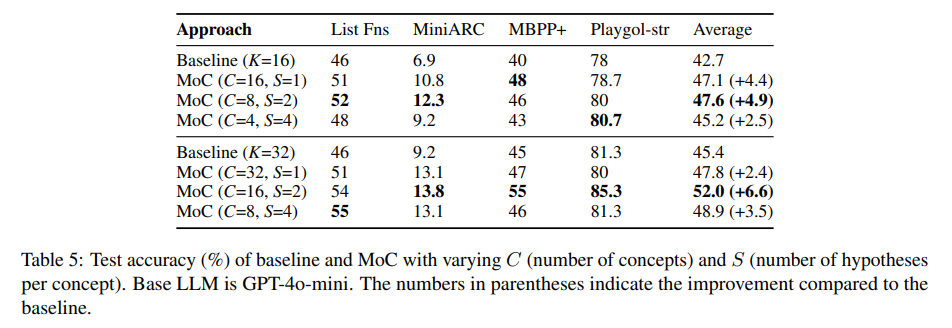
- What impact does generating multiple hypotheses per concept have on performance?
총 hypothesis 수 (C x S)를 일정하게 유지하면서 concept 수(C), concept 당 hypothesis 수(S)를 변화시켜 실험. concept 당 2 hypotheses를 생성하는 게 좋았다. balancing이 optimal performance에 중요하다.
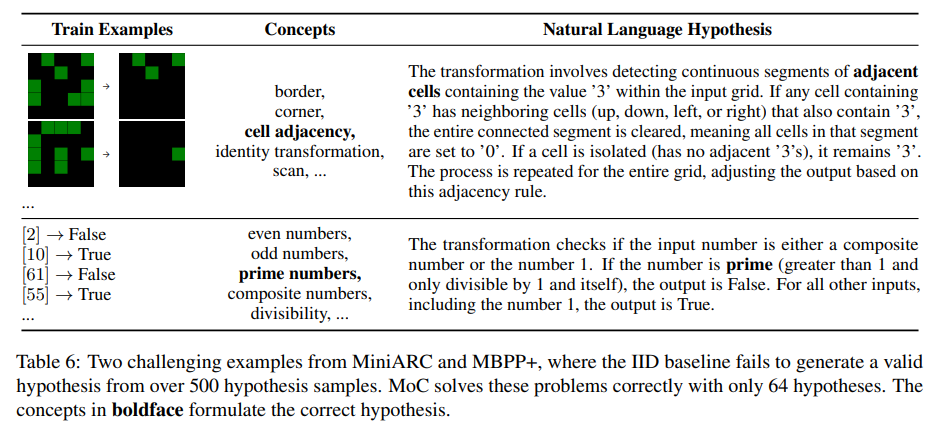
- Does MoC assist in solving highly challenging problems beyond improving efficiency?
IID baseline으로 500회 시도해도 해결 안 되는 문제를 MoC는 K=64로 성공한다.
5. Related Work
LLM 이전에 neural networks는 program search를 가이드하기 위해 사용됐지만 domain-specific languages(DSLs)에 제한되었다.
automatic inductive reasoning에서 LLM은 2가지 패러다임으로 활용, directly predict하거나 hypotheses를 형성해서 test inputs에 적용하거나. 후자의 분야에서 Iterative refinement가 인기있지만 sequential해서 inference를 늦춘다. LLM이 self-correct 능력이 떨어진다는 연구도 있어 (Huang et al., 2024) refinement가 IID samples을 더 뽑는 것보다 큰 장점이 없다.
inference time에 LLM의 reasoning 능력을 향상시키는 다양한 방법이 연구되고 있다. Yao et al. (2023); Lanchantin et al. (2023)은 복잡한 문제 해결을 위해 iterative generate-and-self-reflect approach을 사용하고 Kumar et al. (2024)은 LLM의 self-correction capabilities를 보여주고 Zhou et al. (2024)는 input prompots paraphrasing이 reasoning 능력을 향상시킴을 보여준다. 또 많은 연구가 효율적인 search를 위해 response diversity를 증가시키는 방법을 제안한다.
6. Limitations
hypothesis 생성 이전에 concept proposal을 해야해서 추가적인 연산이 필요하고, IID sampling보다 더 많은 token을 encode해야한다. 하지만 이는 refinement/summarization-based 방식에 비하면 적은 overhead다.
실제 사람의 inductive reasoning은 훨씬 더 복잡하다. 사람은 concepts을 변형시키고 여러 concepts을 다양한 방식으로 구성한다.
LLM safety에 diversity가 영향을 미치는지 연구되지 않았다.
7. 개인적인 생각
일종의 ensemble 기법.
문제 해결에 있어 diversity의 한계는 당연한 일이라고 생각한다. 1+1을 계산하라고 할 때 32개의 서로 다른 방법을 생각할 수 있을까? 그런 점에서 diversity 실험 결과를 해석하는 데 주의가 필요할 것 같다.
어떤 concept는 아주 포괄적이라 여러 hypothesis가 나올 수 있는데 어떤 concept는 아주 narrow해서 deterministic한 hypothesis가 나오는 경우도 있지 않을까? 전자는 많이 생성할수록 좋고 후자는 하나만 생성하면 되는데 이런 concept 간 불균형이 있는 경우를 처리할 수 없는 점은 아쉽다. 예를 들어 Figure 5에서 arithmetic operations은 다양한 방식이 있을 수 있을거 같은데 counting or length based operations은 몇 개 없지 않을까?
-> rich/deterministic 분류하는 것도 일이라 차라리 더 샘플링하는게 효율적일 수 있다.
실패 경험을 활용할 수 없는 점이 아쉽다. CoT 같은 경우는 concept 1로 실패했으면 다른 concept을 탐색해서 새로운 concept 2를 활용하는 식으로 할 수 있을 텐데, 이건 concept이 parallel하다보니 다른 case가 실패했을 경우 문제 해결에 그 경험을 활용할 수 없다. concept를 나눠서 parallel하게 실행하되, 문제 해결에 실패했다면 기존 실패 사례를 묶어서 다음 단계에 새로 전달한다면 성능 향상이 있지 않을까?
-> 데이터셋에서 비슷한 다른 문제도 있을 수 있고. LLM이 self-correction/repair을 못함. repair은 첫 시도에 편향돼서 더 다양하게 안됨. attention sink.
