1. Overview
conditional masked language models를 diffusion language model로 통합한 Diffusion-EAGS 제안.
entropy-adaptive Gibbs sampling, entropy based noise scheduling을 제안.
2. Introduction
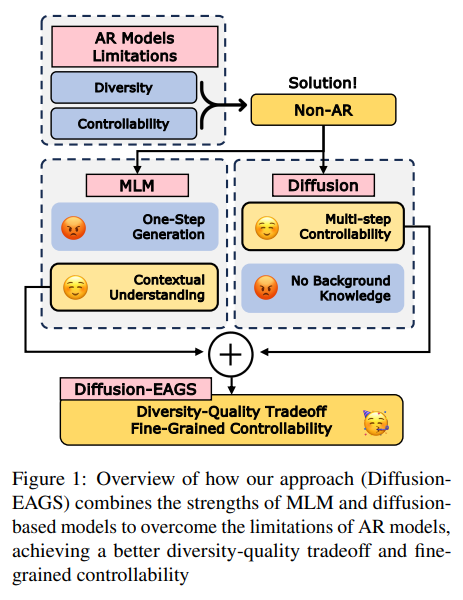
Auto-Regressive Models(ARMs)의 단점 : diversity & controllability (due to left-to-right inductive bias)
rely on first initial tokens, struggle to correct past errors - attention sink
대안 : conditional masked language models (CMLMs), diffusion models
CMLM은 strong contextual understanding을 제공하지만 효과적인 text generation mechanism이 부족하다. diffusion은 fine-grainied control, increased diversity가 장점이지만 degenration, output homogenity가 발생하기도 한다.
이 논문이 제안하는 방식 : Diffusion-EAGS
CMLM을 discrete deiffusion language models(DDLMs)로 통합
diverse, controllable, high-quality conditional generation을 달성하기 위해.
이때 둘을 연결하기 위해 conditional Markov Random Field (cMRF)가 사용된다.
1. Stepwise iterative generation, overcoming the single-step limitations of CMLMs.
2. Stable and diverse conditional text generation, reducing semantic drift in DDLMs.
Diffusion-EAGs는 두 방법을 사용해서 이를 가능하게 한다.
• Entropy-Adaptive Gibbs Sampling (EAGS): A strategy that updates the most uncertain (high-entropy) tokens first at each denoising step, ensuring qualified generation.
• Entropy-based Noise Scheduling (ENS): A training approach that progressively masks tokens based on ascending order of entropy, enabling the model to learn a structured denoising process.
Diffusion-EAGS를 다양한 conditional generation tasks에 baseline models와 비교
3. Related Works
Continuous Diffusion Language Models (Diffusion-LM, DiffuSeq-v1, v2, LD4LG)는 잘 작동하지만 Bansal et al. (2022)는 diffusion이 꼭 stochastic randomness에 지배될 필요는 없다고 주장
D3PM은 discrete restoration-generation 방식 사용, DiffusionBERT는 DDLM에 pre-trained language models 적용, SEDD는 MLM loss에서 영감을 받은 score entropy 사용 등등…
4. Method
MLM & DDLM : D-cMRF
MLM은 single step predict하고 DDLM은 iteratively refine하니 둘을 연관시키기 위해
Diffusion-based Constrained Markov Random Fields (D-cMRF) 제안
-framework that integrates a discrete diffusion process into MLM sequence generation
leveraging an entropy-based sampling
각 step에 high-uncertainty tokens를 선택적으로 update하는 entropy-based sampling strategy 사용 > principled reduction in sequence energy, stable & coherent generation
MLM을 conditional MRF (cMRF)로 이해
energy-based MRF formulation을 따르는 sequence probability
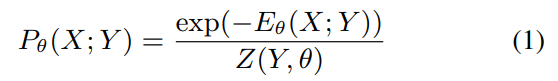
Pθ(X; Y): 조건 Y가 주어졌을 때 시퀀스 X의 확률
Eθ(X; Y): 에너지 함수 (낮을수록 좋은 시퀀스)
Z(Y, θ): 정규화 상수 (모든 확률의 합이 1이 되도록)
energy function
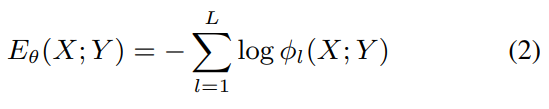
φ_l(X; Y): l번째 위치의 potential 함수 (가능성/적합성)
log-potential function
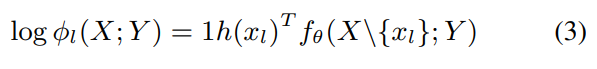
1h(xl): l번째 위치 토큰의 one-hot 벡터
fθ(X{x_l}; Y): MLM logit output
그러면 어떻게 sampling할 것인가?
energy space가 고정이면 Gibbs sampling을 사용할 수 있으나, condition Y가 변하면 E도 변함.
연구 질문: "How should we sample and update the energy?"
diffusion model은 local conditional distributions across time steps의 product로 전체 분포를 표현 > MRF와 probabilistic graphical structure를 공유
P_θ(X; Y)를 각 diffusion step의 denoising function으로 통합
entropy of each token
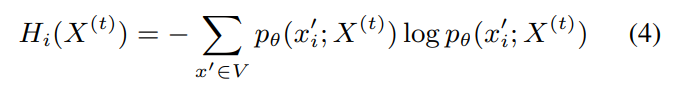
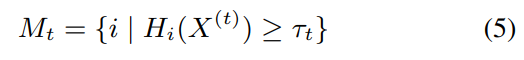
M_t: 시간 t에서 업데이트할 위치들의 집합
τ_t: 시간 t에서의 엔트로피 임계값 (동적으로 조정)
즉 highest uncertainty position에서 update가 일어나도록 한다.
D-cMRF는 generation 중 energy reduction을 보장해서 stable sequence reconstruction을 가능하게 한다 (energy reduction 보장 증명은 section 3.3에)
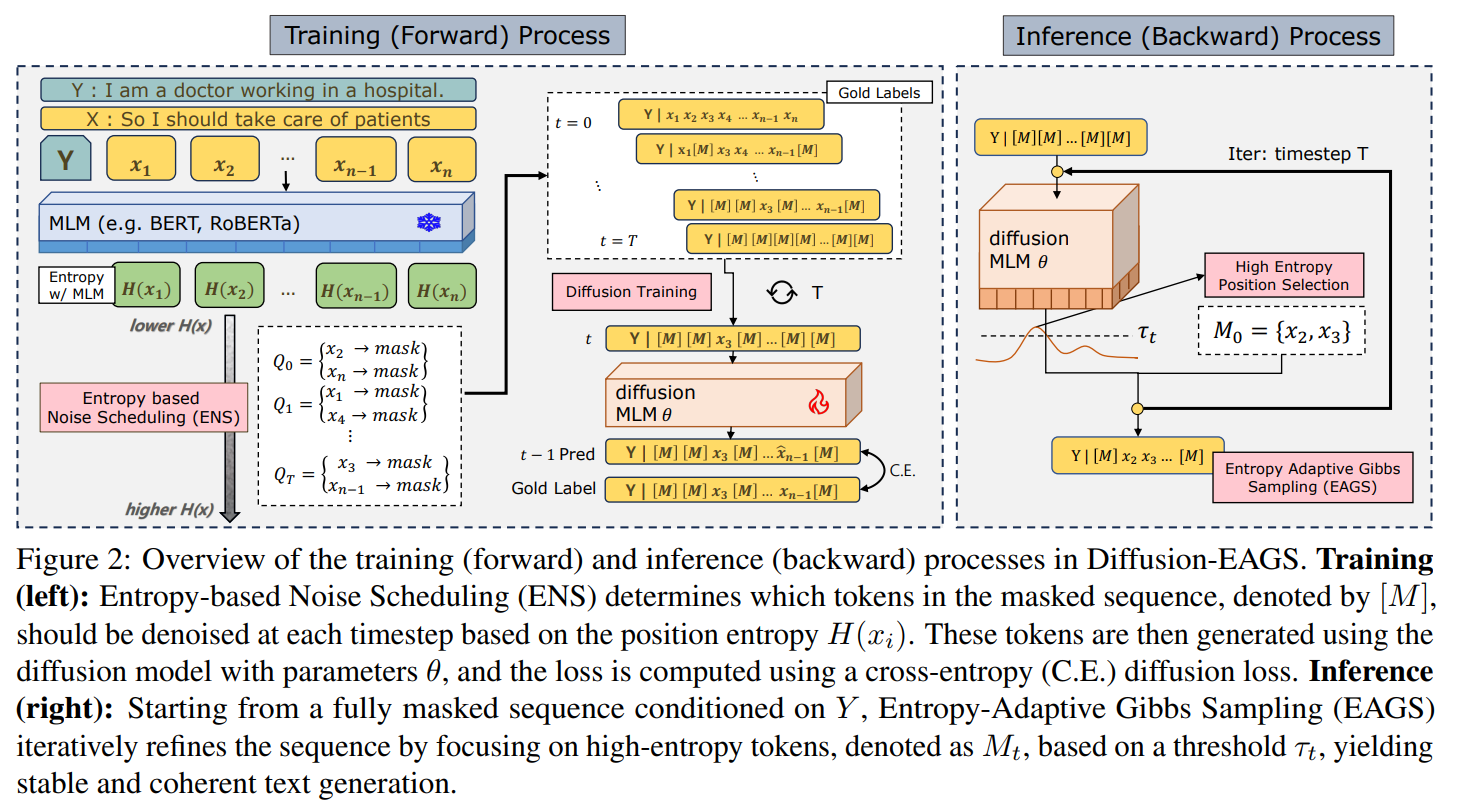
Diffusion-EAGS은 두 핵심 요소 Entropy-Adaptive Gibbs Sampling (EAGS), Entropy-based Noise Scheduling (ENS)을 사용
training 중엔 certainty 기반으로 tokens 선택적 masking, inference 중엔 high-uncertainty tokens을 update해서 fully masked sequence를 반복적으로 정제
Inference Process: EAGS
M_t 구성: 엔트로피 내림차순으로 토큰 순위 매기기, 즉 더 불확실한 위치 선택

Training Process: ENS
생성 시에는 높은 엔트로피부터 복원하므로 훈련 시에는 그 역순으로 낮은 엔트로피부터 masking, masking은 denoising matrix Q로 관리

M은 vocab size면서 [MASK] token의 index. qmm은 m번째 token이 그대로 m번째 토큰일 확률, 즉 [MASK]되지 않을 경우. qmM은 m번째 token이 가장 entropy가 낮아 [MASK]로 변환할 확률.
loss는 traditional diffusion loss (Ho et al., 2020b)에서 MSE를 Cross Entropy로 바꿈
5. experiments & results & analysis
RocStories (Mostafazadeh et al., 2016), Paradetox (Logacheva 381 et al., 2022) 데이터셋 사용
Diffusion-EAGS의 MLM으로 RoBERTa-base (Liu et al., 2020) 사용, 이와 크기 비슷한 4 카테고리 baseline 사용
ARMs - GPT-2, GPT-3.5-turbogpt-3.5-turbo
CMLMs - CMLM-Mask-Predict (Ghazvininejad et al., 2019a), DisCo-Easy-First (Kasai et al., 2020)
CDLMs - DiffuSeq (Gong et al., 2023a), LD4LG (Lovelace et al., 2023), DI NOISER (Ye et al., 2024).
DDLMs - DiffusionBERT (He et al., 2022), AR-Diffusion (Wu et al., 2023), SEDD (Lou et al., 2024)
Quality metrics : GPT-2 Large와 GPT-2 XL 기반 Perplexity (PPL), training/generated output 사이 style consistency 평가를 위한 MAUVE (Pillutla et al., 2021), 문법 평가를 위한 SOME (Yoshimura et al., 2020), 인간 평가자들의 주관적 품질 평가인 Mean Opinion Score (MOS), plausibility 측정을 위한 LLM-c (Lin and Chen, 2023)
Diversity metrics : automatic frequency-based metric n-gram Vendi Score(VS n-gram) (Friedman and Di eng, 2023), a neural network–based semantic metric SimCSE Vendi Score (VS emb), human evaluation score MOS
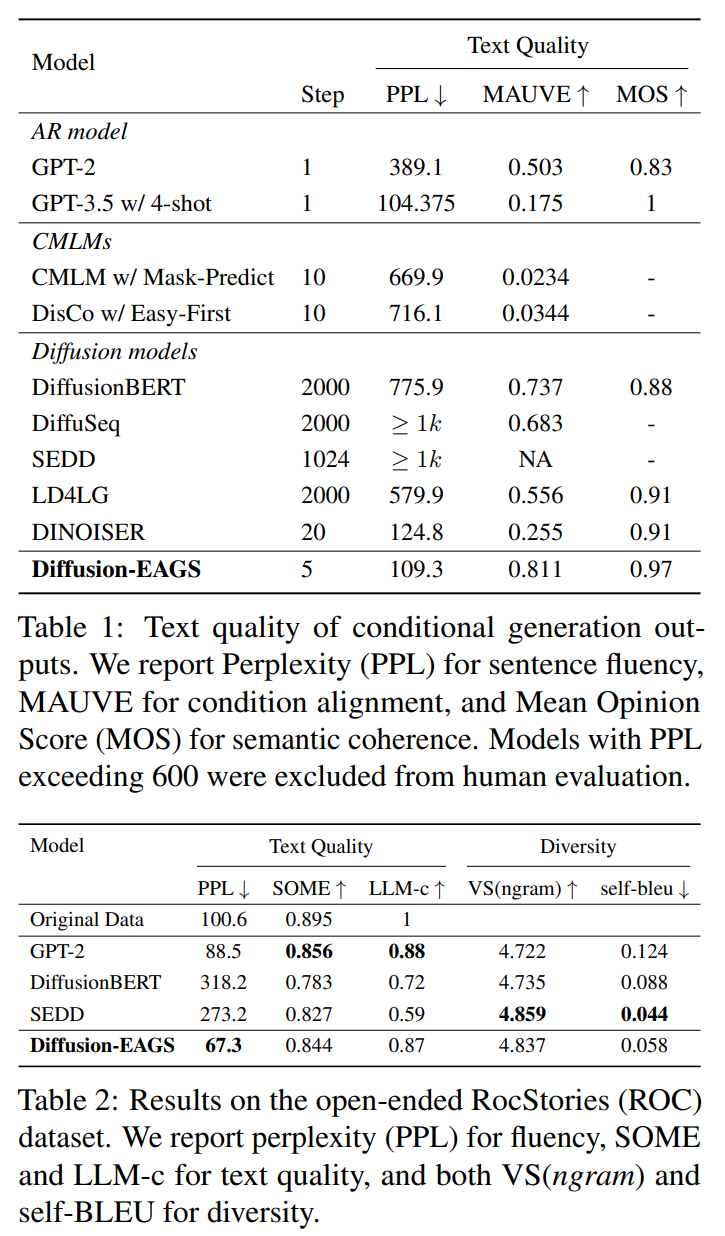
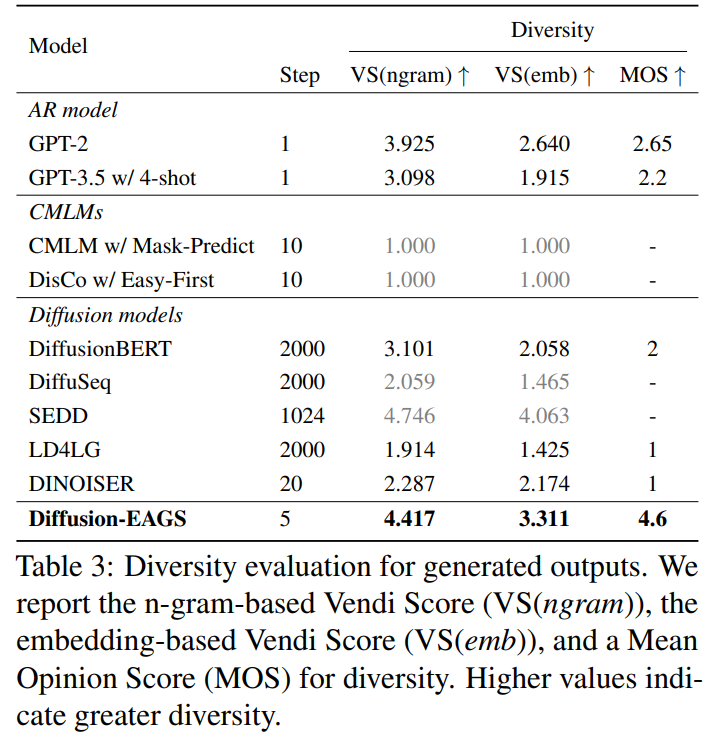
text quality (table 1, table 2), diversity (table 3) 모두 좋다.
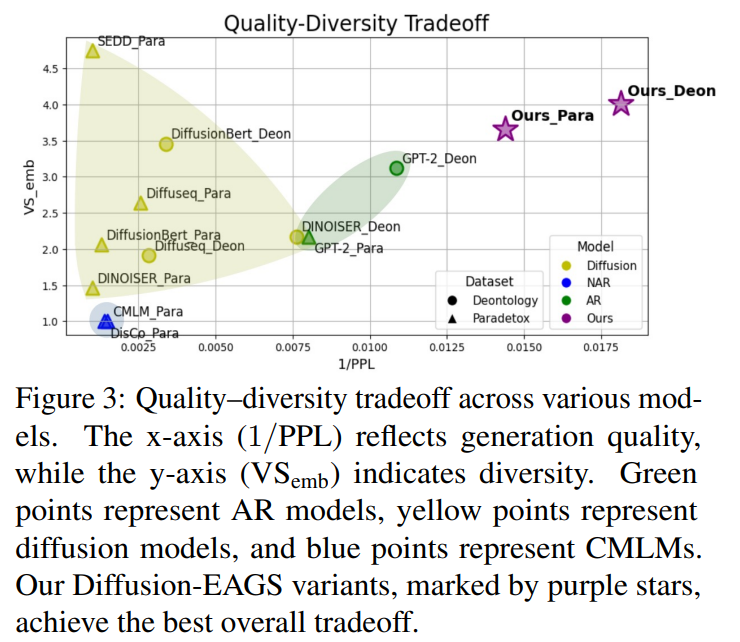
quality-diversity tradeoff 비교. 논문의 방식이 가장 뛰어났다.

또 AR 모델과 달리 Diffusion EAGS는 원하는 position에 특정 keyword가 나타나도록 고정할 수 있다. 키워드는 고정하고 나머지 부분만 MASK 처리해서 생성하면 된다.
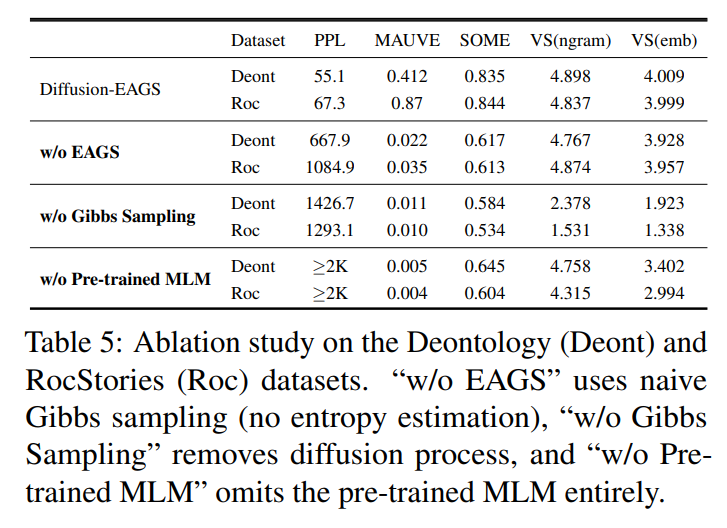
ablation study도 수행했다.
w/o EAGS : text quality 감소, traditional CMLMs와 유사한 degenerated results 생성
w/o Gibbs Sampling : reduction in overall performance, increased PPL, reduced diversity scores
w/o pre-trained MLM : degenerated outputs
6. Conclusions & Discussions
T5로 실험했을 때 GPT-2 fine-tuning보다 성능 향상이 없었다고 함. 아마 T5의 generation이 inital decoder tokens에 강하게 의존하기 때문이 아닐까 추측. encoder-decoder models을 diffusion process에 통합하는 미래 연구가 필요.
limitations
text generation task에 집중해서 text classification task에도 유효할지 검증을 못했다.
AR 모델과의 통합도 미탐구했다.
pre-trained models의 편향이 전파될 수 있지만, 최근 연구는 data-balancing 전략들이 이 문제를 해결할 수 있다고 한다.
대소문자나 구두점 같은 사소한 decoding error가 있다.
7. 개인적인 의견
엔트로피를 기반해서 일종의 greedy choice를 해서 update하는 듯한데 greedy한 게 장점도 있을 수 있고, 단점도 있을 수 있다고 생각한다. 업데이트할 위치를 선택할 때도 greedy 말고 sampling/stochastic 방법이 가능하지 않을까? 이것도 실험했으면 좋았을 것 같다.
-> 문장의 완성도가 문제.
energy가 낮아지는 게 보장되어서 좋다.
현재 실험에서 maximum length를 64 tokens로 두었는데 너무 작다고 생각한다. 물론 데이터가 작아서 큰 window를 사용할 필요는 없지만 scaling이 가능한지 의문이 든다. 논문에서는
"Note that our primary goal is to investigate the architecture's capabilities;
any baseline approach in the direction of scalability or bypassing
the architecture's limitations goes beyond our research scope"
라고 scalability가 연구 목적은 아니라고 해명하기는 한다.
-> max length 512. diffusion scalability는 이전 연구에서 증명됨. related works.
training/inference가 완전히 대칭적이지는 않은 듯하다. inference의 맨 처음 단계에선 (keyword를 박아두지 않았다면) 모든 위치가 [MASK]되어 있는데 이러면 어디서부터 업데이트할지 알 수 없고, 임의의 위치에서 시작해야한다.
한 번 mask에서 token으로 denoising되면 그 token을 다시 refine하지는 않는다. 그런데 가장 불확실한 걸 먼저 선택해서 generate하는데, 이러면 attention sink랑 같은 문제 아닌가? 시작부터 불확실한 게 확정되는 바람에 mask를 없앨수록 초반의 불확실성을 보정하지 못하는 것 아닌가? mask를 하나씩 지우고 mask 사라지면 그대로 확정시키는게 아니라 생성된 토큰도 불확실성이 크면 재정제하는 방식을 써야하지 않을까? training도 해당 방법에 대칭적이도록 수정하고.
-> continuous에선 그렇게 한다. AR에 비해 continuous 쓸 이유가 없다. 하위호환.
text > mask로 변환하는 pretrained model이 없다. bert는 mask > text. 연구문제.
