오늘 리뷰할 논문은 differentiable neural computer, DNC 논문이다.
Summary
인공신경망은 외부 메모리가 없기 때문에 variables/data structures를 표현하거나 긴 시간동안 데이터를 저장할 능력이 부족하다. 논문은 컴퓨터의 random-access memory와 비슷하게 external memory matrix에 읽고 쓸 수 있는 신경망인 DNC를 소개한다. DNC는 컴퓨터처럼 복잡한 data structure를 표현하고 조작할 수 있으며 그러는 법을 인공신경망처럼 데이터로부터 학습할 수 있다. 전체 시스템이 미분가능하기 때문에 gradient descent를 사용해 end-to-end로 학습될 수 있다.
지도학습되었을 때, DNC가 NLP의 reasoning과 inference problems를 모방하는 synthetic questions에 성공적으로 답변할 수 있다는 것을 보인다. DNC는 두 점 사이 최단 경로를 찾을 수도 있고 randomly generated graphs 내에서 missing links를 추론하고 transport networks나 family trees 같은 특정 그래프로 일반화할 수 있다. 강화학습되었을 때 DNC는 moving blocks puzzle을 완성할 수도 있다. 이러한 결과들은 DNC가 external read-write memory가 없는 평범한 neural network는 불가능한 complex, structured tasks를 해결할 능력이 있음을 입증한다.
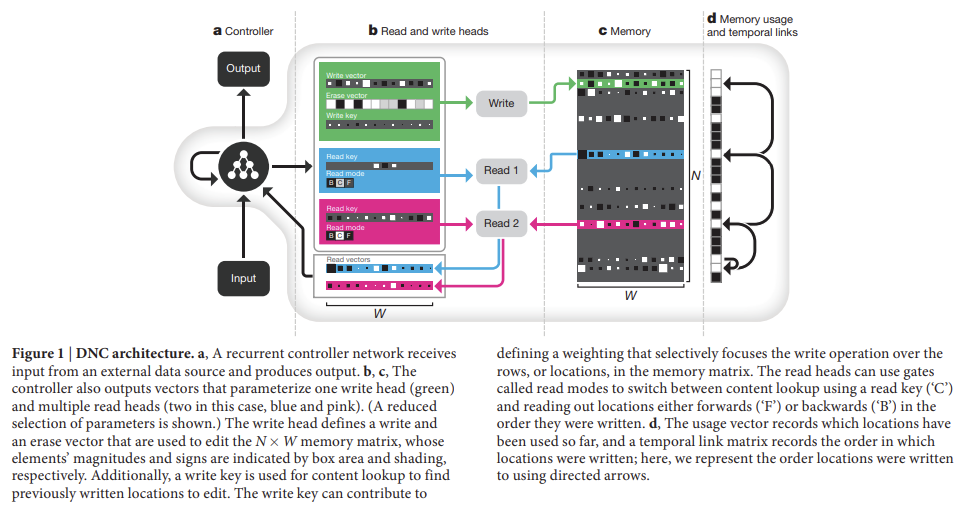
DNC의 초기 형태인 NTM은 비슷한 구조를 가지지만 memory access methods가 더 제한적이다. 컴퓨터는 memory contents에 접근하기 위해 unique address를 사용하지만 DNC는 N × W memory matrix M 내의 N rows(=locations)에 대한 distributions을 정의하기 위해 differentiable attention mechanisms를 사용한다. 아 distributions는 weightings라고 불리고 각 location이 read/write operation에 얼마나 참여하는지(involve)를 나타낸다. memory M에 대한(over) read weighting 에 의해 반환된 read vector r은 memory locations에 대한(over) weighted sum이다. 이며 ‘·’는 모든 j= 1, …, W를 의미한다. 비슷하게 write operation은 write weighting 를 사용해 erase vector e를 가지고 지우고 그 다음 write vector v를 추가한다. 즉 이다. weightings를 결정하고 적용하는 functional units는 read/write heads라고 불린다.
heads는 세 가지 다른 형태의 differentiable attention를 사용한다. 첫째는 content lookup이고 controller가 구한 key vector가 memory 내 각 location의 content와 similarity measure(논문은 cosine similarity를 사용)를 기준으로 비교된다. similarity scores는 read/write head가 사용할 weightings를 결정한다. 중요한 점은 memory location의 content와 일부만 match하는 key도 여전히 그 location을 강하게 attend하는 데 사용된다는 것이다. 이는 pattern completion의 형태를 가능하게 해서 memory location을 읽어 복원한 value가 key 내에 존재하지 않는 추가적인 정보까지 포함하게 한다. 한 주소의 content가 다른 주소들로의 reference를 효과적으로 encode할 수 있기 때문에 key-value retrieval는 외부 메모리 내의 associative data structures를 찾는 데(navigate) 훌륭한 메커니즘을 제공한다.
두 번째 attention mechanism은 N × N temporal link matrix L 내의 consecutively written locations 간 transitions를 기록한다. i가 j 다음에 적힌 location이면 L[i,j]는 1에 가깝고 아니면 0에 가깝다. weighting w에 대해 operation Lw는 w에 강조된 locations 이후에 쓰인 locations를 향해(forwards) focus를 옮긴다. 반대로 는 focus를 반대로(backwards) 옮긴다. 이는 DNC가 적은 순서대로 sequences를 복원할 수 있는 능력을 갖추게 하며 인접한 time-steps에서 연속적인 writes가 일어나지 않았어도 그렇다.
attention의 세 번째 형태는 writing을 위한 memory를 할당한다. 각 location의 'usage'는 0~1 사이의 수로 표현되며 unused locations를 가려내는(picks out) weighting은 write head로 전달된다. usage는 각 write와 함께 증가하고 각 read 후에 감소한다. 이는 controller가 더이상 필요하지 않은 memory를 재할당할 수 있게 한다. 이 allocation mechanism은 memory의 size나 content와 독립적이며, 따라서 DNC는 one size of memory를 사용해 task를 해결하도록 학습된 이후 나중에 retraining 없이 larger memory로 업그레이드될 수 있다. 이론적으로 DNC는 어떤 location의 minimum usage가 특정 threshold를 넘을 때마다 자동으로 locations의 수를 증가시킴으로써 unbounded external memory를 사용할 수 있다.
attention mechanisms의 디자인은 computational considerations에서 동기부여를 받았다. content lookup은 associative data structures의 형성을 가능하게 하고 temporal links는 input sequences의 sequential retrieval을 가능하게 하며 allocation은 write heads에게 unused locations를 제공한다. 그런데 DNC의 memory mechanism과 포유류 해마의 기능적 능력 간에 흥미로운 유사점이 있다. DNC memory modification은 빠르고 one-shot으로 가능한데, 이는 hippocampal CA3와 CA1 synapses의 associative long-term potentiation와 닮았다. neurogenesis를 돕는 영역인 hippocampal dentate gyrus는 representational sparsity를 증가시켜 memory 용량을 늘린다고 알려졌는데, usagebased memory allocation와 sparse weightings가 비슷한 기능을 DNC에 제공한다. temporal context model에 의해 처리되는 hippocampus-dependent phenomenon인 Human ‘free recall’ experiments은 temporal links의 형성과 비슷하다.
실험은 Synthetic question answering experiments, Graph experiments, Block puzzle experiments로 세 종류를 한다.
- Synthetic question answering experiments
DNC를 다른 neural network와 비교하기 위해 bAbI dataset을 고려했다. 데이터셋은 short ‘story’ snippets와 story에서 추론할 수 있는 question, answer로 구성된다. 모든 20 question types에 공동으로 학습된 single DNC가 3.8%의 mean test error rate of 3.8%와 2종류의 문제에서 (>5% error로 정의된) task failure를 달성했다. 기존의 jointly trained result의 SOTA는 7.5% mean error와 6 failed tasks였다. DNC는 LSTM이나 NTM보다 잘 작동했다.
- Graph experiments
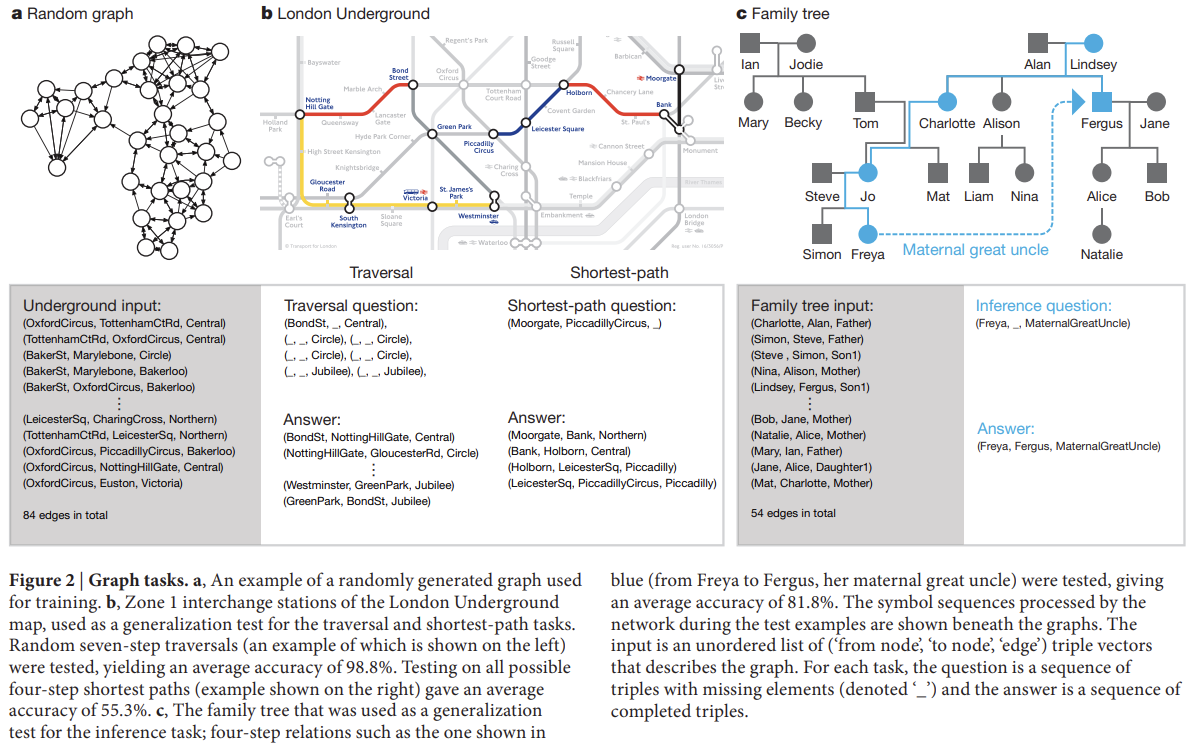
다음 실험은 randomly generated graphs에 synthetic reasoning experiments를 했다. bAbI와 달리 graphs의 edges는 명시적으로 제공되며 각 input vector은 two node labels와 하나의 edge label로 구성된 triple로 명시된다. random labelling과 connectivity를 가지고 training graphs를 생성했으며 세 종류의 query, ‘traversal’, ‘shortest path’, ‘inference’를 정의했다. 점진적으로 증가하는 복잡도를 가진 graphs와 queries를 사용해 curriculum learning으로 훈련한 후 networks는 (retraining 없이) realistic data에 대한 일반화를 테스트하기 위해 two specific graphs, London Underground의 symbolic map과 invented family tree에 테스트했다.
traversal task (Fig. 2b)의 경우 네트워크는 start node를 떠난 후 random walk로 생성된 edges를 따라 도착한 node를 기록하도록 지시됐다. shortest-path task (Fig. 2b)의 경우 random start & end node가 query로 주어졌고 둘 사이 최단 거리에 해당하는 sequence of triples를 반환하도록 요구되었다. 최대 길이 5의 path를 고려했기 때문에 이는 최대 길이가 2인 bAbI 데이터셋의 path-finding task보다 어렵다. inference task (Fig. 2c)의 경우 최대 5 connected edge labels의 sequences에 대한 abbreviation인 400 ‘relation’ labels를 predefine했다. query는 start node와 relation label을 명시한 incomplete triple로 구성되고 요구되는 answer는 relation sequence를 따랐을 때 도착하는 final node였다. relation sequences가 network에 제공되지 않기 때문에 queries와 targets로부터 추론되어야 했다.
benchmark로 DNC를 LSTM과 비교했다. extensive hyper-parameter
search에서 찾은 best LSTM이 심지어 가장 쉬운 traversal task조차 실패했다(정확도 37%). DNC는 final lesson에(inference task를 의미하는 듯) 평균 98.8% 정확도를 달성했다.
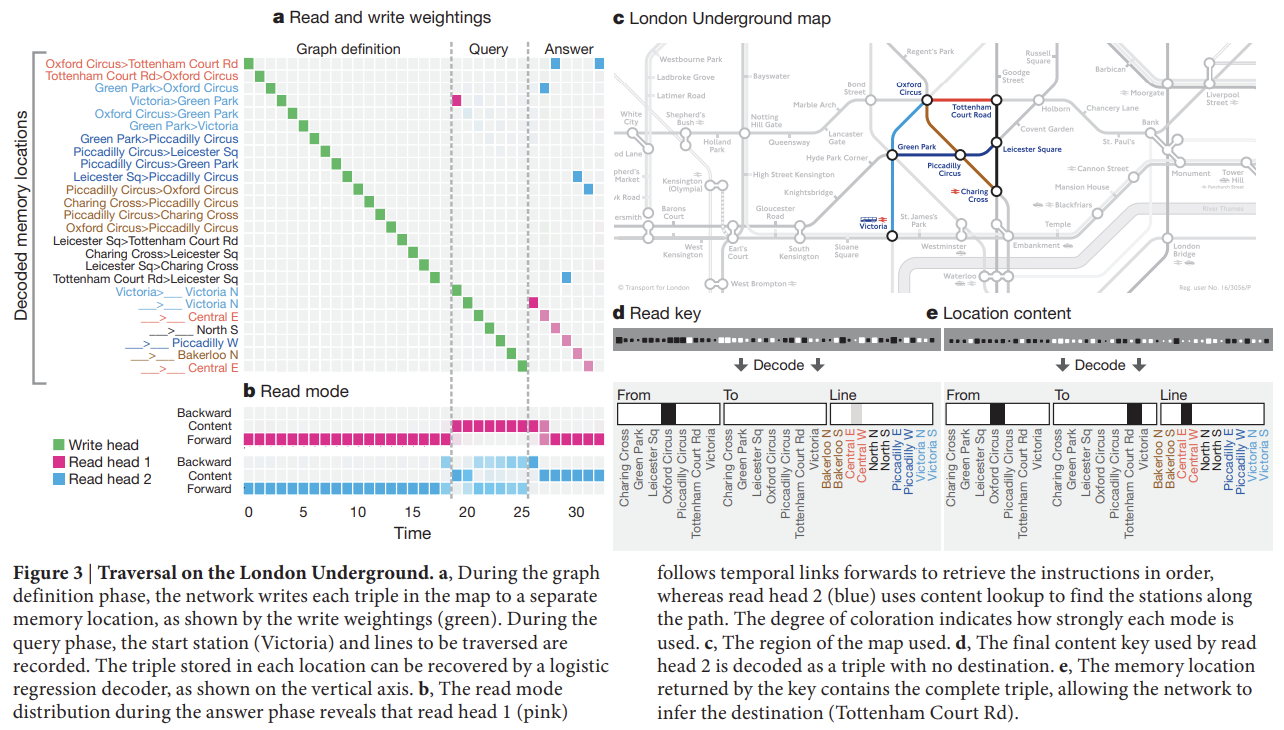
Fig 3은 London Underground map을 저장하고 traverse하기 위한 DNC의 memory allocation, content lookup, temporal linkage의 사용을 보여준다. shortest-path에 학습된 DNC의 시각화는 DNC가 start node와 end node에서부터 발산해 connecting path가 발견될 때까지 links를 점진적으로 탐험했음을 제안한다.
- Block puzzle experiments
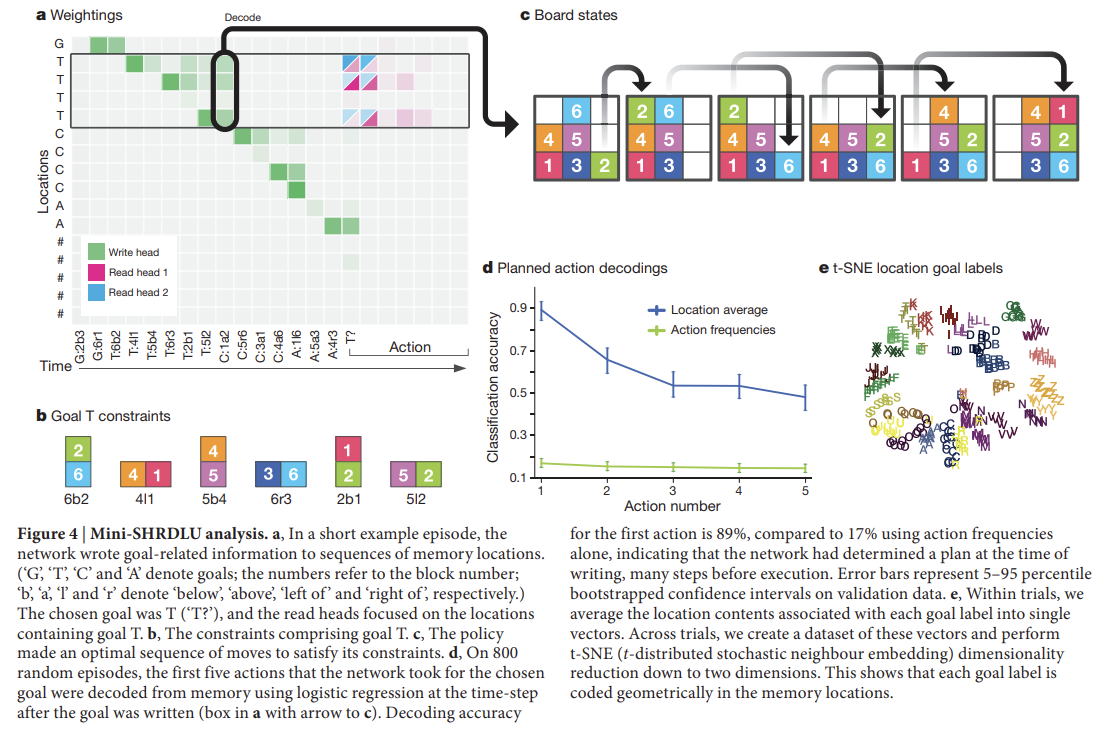
다음으로 logical planning tasks을 위해 memory를 사용하는 능력을 확인했다. 이를 위해 Winograd’s SHRDLU에서 영감을 받아 block puzzle game을 만들었다. 지도학습을 했던 앞선 실험들과 달리 여기서는 강화학습을 했다. Mini-SHRDLU라고 이름붙인 환경은 grid board에 set of numbered blocks가 있고 agent는 input으로 board의 view를 받아 column의 top block을 다른 column의 stack의 꼭대기에 옮길 수 있다. 모든 episode마다 start board configuration과 몇 가지 가능한 goals을 생성했다. single-letter label로 identify된 goal은 (time-step 당 하나의 constraint에 trasmit된 adjacent block pairs에 대한) 몇 가지 개별적인 constraints로 구성되어 있다. 예를 들어 Fig 4b, c를 보면 goal 'T'는 “block 6 below 2; block 4 left of 1; …”를 의미한다. 모든 goal이 주어진 후, 랜덤으로 single goal label이 선택되어 agent는 그 goal을 만족하게 cue된다.
Fig 4a를 보면 DNC는 goals를 locations에 iteratively 적는 것으로 memory에 instructions을 저장한다. goal이 작성된 순간에 (실행 전에 많은 steps가 필요하지만) first action이 memory에서 decode될 수 있었다. 이는 DNC가 행동하기 전에 결정을 memory에 작성함을 나타낸다. 따라서 놀랍게도 DNC는 계획을 만들도록 학습한 것이다. graph tasks에서와 마찬가지로 학습은 board의 block 수와 goal의 constraints, goal의 수, solution을 찾기 위해 필요한 최소 행동 횟수를 점진적으로 증가시키는 커리큘럼을 따랐다. DNC는 이번에도 LSTM보다 잘 작동했다.
(Methods 설명 생략. NTM이랑 비슷한 듯?)
Strengths
- NTM을 발전시켰다. usage를 통해 필요없는 memory를 재할당할 수 있게 했고 temporal link matrix를 도입해 input sequence를 복원할 수 있고 연속적이지 않은(non-contiguous) 메모리 접근 시 문제를 해결했다.
- graph 실험과 block puzzle 실험에서 학습할 때 난이도를 점진적으로 증가시키는 학습법이 신기했다. (지도학습인데 무작위로 학습할 수 있어야 하는 것 아닌가? 직관적으로는 이쪽이 더 학습이 수월할 것 같기는 한데.)
Weaknesses
- 실험과 모델이 비교적 작은 scale이라 real-world data에 적용하기는 더 연구가 필요한 것 같다.
NTM을 읽고도 느낀 점이지만 개인적으로 memory를 접근하는 attention 방식이 좀 naive한 것 같다. 메모리 접근에 transformer를 사용한 방식도 있다던데 다음엔 그 논문을 찾아서 읽어보고 싶다.
또 별개로 memory가 있으면 모델이 generalization이 어렵고 memoization에 더 취약해지지 않을까?
