논문 아이디어에 여러모로 지적할 점이 많은데... 메모 겸 정리해보겠다.
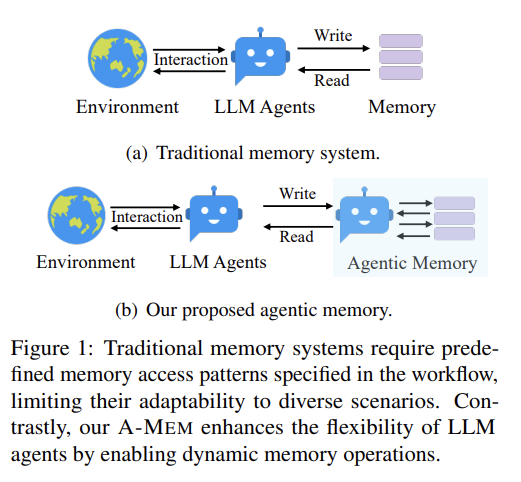
agent를 2개 뒀길래 해마인줄 알았더니 아니었다.
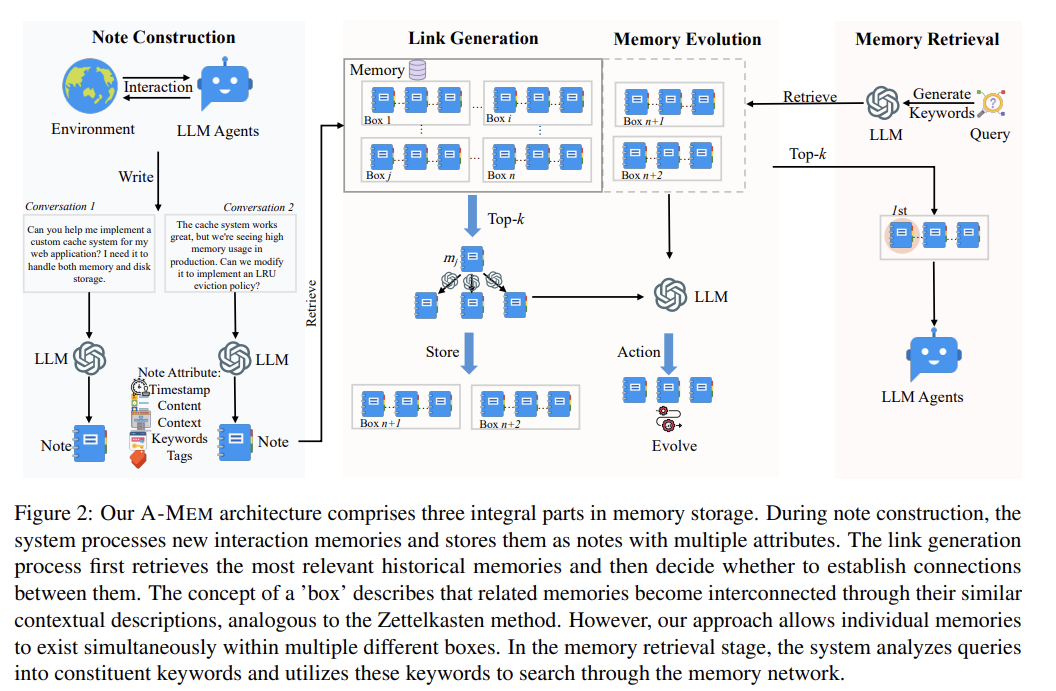
note 만드는 것부터 naive하다. timestamp, keywords, tags 등등이 명시적으로 저장된다. 그리고 결국 RAG의 document처럼 note라는 txt를 만드는거니까 '감각/느낌'으로 기억되는 게 아니라 '동굴 벽화'처럼 상징적 수준에서 저장된다. 일단 여기서부터 글렀다.
When the constrctd memory note mn is added to the system, we first leverage its semantic embedding for similarity-based retrieval. For each existing memory note mj ∈ M, we compute a similarity score:
link generation/query할 때 모든 memory와 similarity를 비교한다. 메모리가 개 많아지면? 일일이 비교해야한다. 뭐 이건 속도 빠르니까 trivial하다고 치자...
box에 대한 내용은 본문에 없는 거 보니 figure 설명하려고 넣은 것 같다.
memory evolution이라며 각 memory의 context, keyword, tag를 일일이 업데이트해야하는 것도 짜친다.
그리고 결국 query로 retrieve한 memory도 prompt로 집어 넣는거라 이건 RAG 같은 방법인 셈이다.
사실상 RAG에서 document(메모리 노트) 생성을 LLM에 맡기고 이때 다양한 attribute와 함께 생성하도록 해서 retrieve 퀄리티만 더 높인 것 아닌가? 딱히 혁신적인 것도 아니고 방식도 조악한 것 같다.
