chain of thoguth 시 중간 thinking step 길이를 제한하는(prompt로 지시해서) 간단한 방법이다.
논문이 굉장히 짧고(6p) 간단하다. 아이디어 먼저 선점하려고 급하게 후다닥 날림으로 쓴 거 아닐까 싶다.
이전에 흥미롭게 읽은 "Training large language models to reason in a continuous latent space" 논문이 언급된다.
Hao et al. (2024) proposes Coconut to train LLMs to perform reasoning in a continuous latent space rather than in the traditional natural language space using the final hidden state of the LLM to represent the reasoning process. While Coconut reduces latency and computational cost, it suffers from reduced accuracy in complex tasks, such as GSM8k. Additionally, it loses the interpretability of natural language reasoning and cannot be applied to black-box models like GPT and Claude.
Concise Thoughts (CCoT) (Nayab et al., 2024) and token-budgetaware LLM reasoning (TALE) (Han et al., 2024). 도 읽어볼만 할듯

(따로 학습도 없이 prompt만으로) prompt에서 thinking step마다 최대 5 words만 사용하도록 지시해서 약간의 성능 하락과 생성되는 토큰 수, latency를 trade했다.
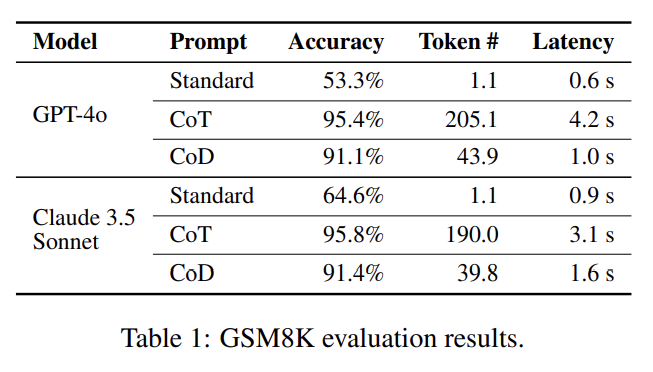

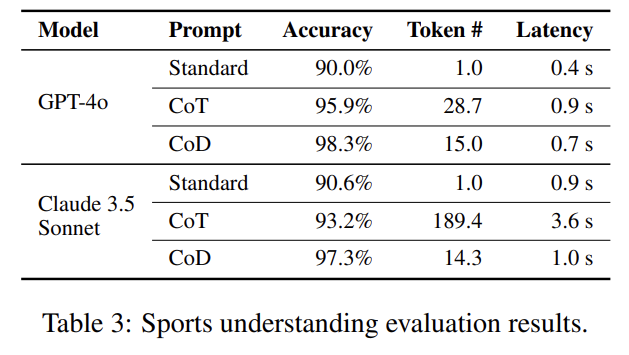
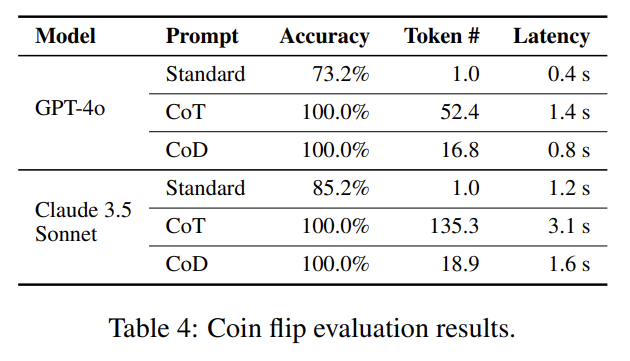
위 table에서 보듯이 GPT, Claude에 실험했고 arithmetic reasoning (table 1), commonsense reasoning (table 2, 3), symbolic reasoning (table 4) 모두 효과적이다.
아주 단순한 방법이고 training이 아니라 prompting하는 거라 gpt, claude 같은 blackbox model에도 쉽게 적용할 수 있는 장점이 있다. 사소한 성능 하락에 비해 token#/latency 이득이 큰 것 같다. 교환비가 좋다.
이 논문이 함의하는 바는 굳이 word token을 만들어내지 않더라도 이미 latent space 상에서 문제 해결이 잘 수행되고 있고, (상징계적인) sentence를 만들어내면 불필요한(덜 중요한) token까지도 생성되니 attention 시 비효율이 발생한다는 의미 아닐까?
또 5단어로 생각해라고 제한할 수 있는 게 신기하다. 인간도 그건 안 되지 않나? 5단어 문장을 '정제'해서 '발화'할 수만 있고. 이건 LLM이 토큰화한 문장은(중간의 think step이든 output이든) 이미 정제된 발화이고 내적 사고는 latent하게 따로 존재한다는 걸 의미하는 게 아닐까?
