LongMem 모델.
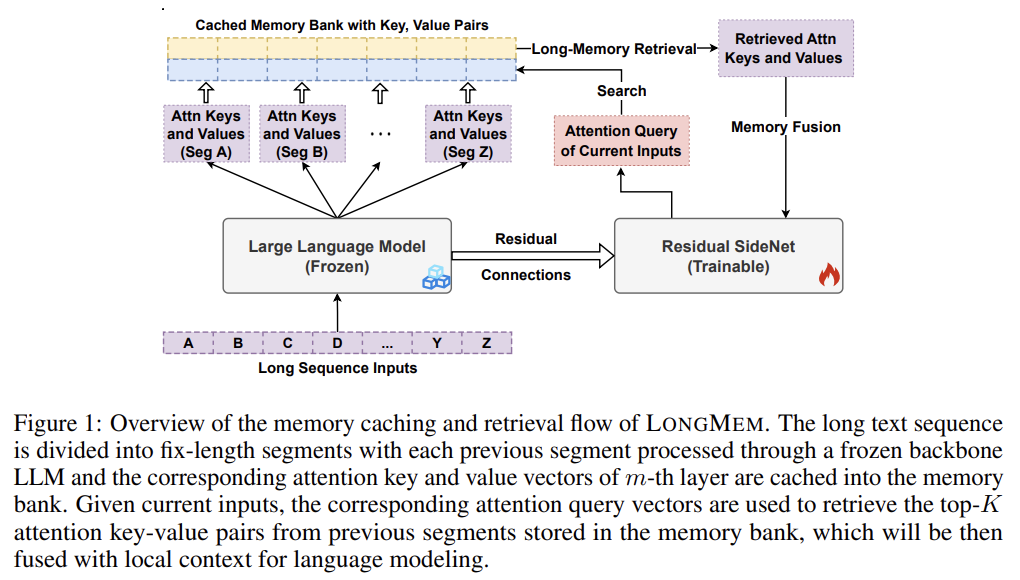
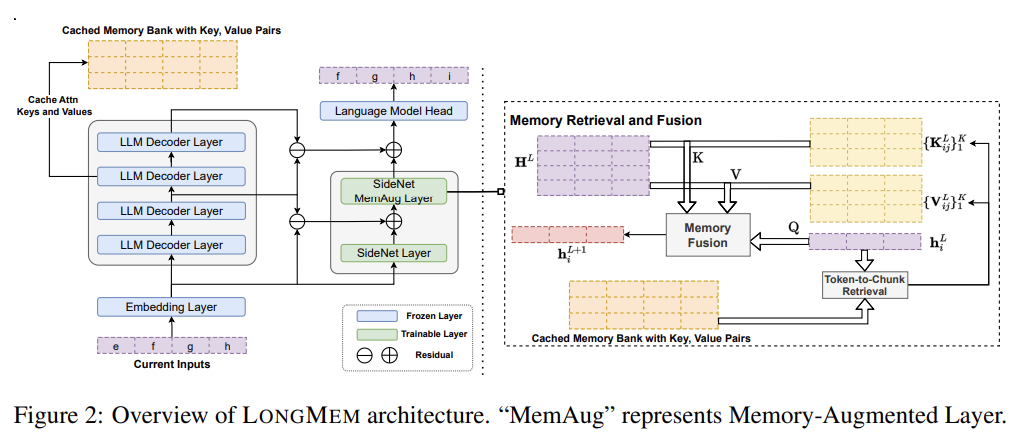
frozen backbone LLM, SideNet, and Cache Memory Bank 3개 구조로 이루어짐.
frozen LLM 처리하면서 최근 M개 input의 각 LLM layer에서 K, V 값을 bank에 저장. retrieval and fusion 끝나면 가장 오래된 값을 현재 값으로 바꿔서 최신화함. (이 부분에서 무작정 가장 오래된 걸 지우는 게 아니라 중요도 score이 가장 낮은 걸 잊는 구현이 더 좋지 않을까?)
LLM에서 처리 끝나면 SideNet은 최종 hidden state랑 중간 hidden state들, 그리고 bank에서 얻은 과거 key-value cache를 가지고 memory-augmented representations를 계산하는데, 구체적으로는 L-1개의 일반적인 transformer layer를 거친 후 1개의 special memory augmentation layer를 통과한다. memory augmentation layer는 cache한 top-K relevant key-value pairs도 사용하는데 이건 token-based memory retrieval module를 사용해 얻어진 것이다. 최종 token probability는 softmax()로 계산하고 W는 frozen output embedding weight shared by both the backbone LLM and SideNet이다.

한편 memory bank에선 최신 M개 토큰에 대한 KV를 csz 개씩 묶어서 chunk 단위로 관리한다. query 검색할 때도 가장 similarity 높은 개별 top-K token이 뽑히는 게 아니라 K/csz개 그룹(chunk)이 뽑혀서 총 K개 token의 KV를 얻는다.
아주 깔끔한 방식은 아닌 것 같긴한데 어차피 이 KV 결과들을 가지고 다시 attention 하니까 결과적으론 효과가 있는 듯하다.
