들어가기 전
『자바의 신 3판』 을 읽고 내용 정리 및 공부한 내용을 정리한 글입니다.
서적: 자바의 신 3판 구입처
내용 정리
Thread
Thread라는 단어의 사전적인 의미는 실타래를 의미한다. 쓰레드를 하나 생성하면 하나의 실 줄기가 추가되고, 해당 쓰레드가 종료되면 그 실이 끊겨버렸다고 생각하면 조금 더 이해가 쉬울 것이다.
프로세스와 쓰레드
- 하나의 프로세스 내에는 여러 쓰레드가 수행된다.
- 어떤 프로세스든 간에 쓰레드가 하나 이상 수행된다.
- 여러 프로세스가 공유하는 하나의 쓰레드가 수행되는 일은 절대 없다.
자바의 쓰레드
java 명령어를 사용하여 클래스를 실행시키면 적어도 하나의 JVM이 시작된다. 보통 이렇게 JVM이 시작되면 자바 프로세스가 시작한다.
자바 프로세스가 시작되면 main() 메소드가 수행되면서 하나의 쓰레드가 시작되는 것이다.
만약 많은 쓰레드가 필요하다면, 이 main() 메소드에서 쓰레드를 생성해 주면 된다.
자바를 사용하여 웹을 제공할 때에는 Tomcat과 같은 WAS(Web Application Server)를 사용한다. 이 WAS도 똑같이 main() 메소드에서 생성한 쓰레드들이 수행되는 것이다.
💡 아무런 쓰레드를 생성하지 않아도 JVM을 관리하기 위한 여러 쓰레드가 존재한다. 예를 들면 자바의 쓰레기 객체를 청소하는 GC 관련 쓰레드가 여기에 속한다.
쓰레드를 만든 이유
메모리 관점에서
프로세스가 하나 시작하려면 많은 자원이 필요하다. 만약 하나의 작업을 동시에 수행하려고 할 때 여러 개의 프로세스를 띄워서 실행하면 각각 메모리를 할당하여 주어야만 한다.
JVM은 기본적으로 아무 옵션 없이 실행하면 OS 마다 다르지만, 적어도 32MB~64MB의 물리 메모리를 점유한다.
그에 반해서, 쓰레드를 하나 추가하면 1MB 이내의 메모리를 점유한다. 그래서 쓰레드를 “경량 프로세스-lightweight process”라고도 부른다.
속도 면에서
대부분의 작업은 단일 쓰레드로 실행하는 것보다는 다중 쓰레드로 실행하는 것이 더 빠른 시간에 결과를 제공해준다.
정리
보다 빠른 처리를 할 필요가 있을 때, 쓰레드를 사용하면 보다 빠른 계산을 처리할 수도 있다.
Runnable 인터페이스와 Thread 클래스
쓰레드를 생성하는 것은 크게 두 가지의 방법이 있다.
- Runnable 인터페이스를 사용
- Thread 클래스를 사용
- Thread 클래스는 Runnable 인터페이스를 구현한 클래스이다.
Runnable 인터페이스와 Thread 클래스는 모두 java.lang 패키지에 있다. 따라서, 이 인터페이스나 클래스를 사용할 때에는 별도로 import할 필요가 없다.
Runnable 인터페이스
Runnable 인터페이스에 선언되어 있는 메소드는 단 하나다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| void | run() | 쓰레드가 시작되면 수행되는 메소드 |
start() 와 run()
두 방식 모두 객체를 생성하는 부분은 별다른 차이가 없다.
- 쓰레드가 수행되는 우리가 구현하는 메소드는 run() 메소드다.
- 쓰레드를 시작하는 메소드는 start() 이다.
- 자바에서 알아서
run()메소드를 수행하도록 되어 있다.
- 자바에서 알아서
- Runnable 인터페이스를 구현하거나 Thread 클래스를 확장할 때에는
run()메소드를 시작점으로 작성해야만 한다.
Runnable 인터페이스 구현 예제
Runnable 인터페이스를 구현한 클래스는 쓰레드로 바로 시작할 수는 없다. 따라서, Thread 크래스의 생성자에 해당 객체를 추가하여 시작해 주어야만 한다.
public class RunnableSample implements Runnable{
public void run() {
System.out.println("This is RunnableSample's run() method.");
}
}public static void main(String[] args) {
RunnableSample runnable=new RunnableSample();
new Thread(runnable).start();
}Thread 클래스 확장 예제
Thread 클래스 객체에 바로 start() 메소트를 호출할 수 있다.
public class ThreadSample extends Thread{
public void run() {
System.out.println("This is ThreadSample's run() method.");
}
}public static void main(String[] args) {
ThreadSample thread=new ThreadSample();
thread.start();
}방식이 두 가지인 이유
자바에서는 하나의 클래스만 확장할 수 있다.
만약 어떤 클래스가 다른 클래스를 extends를 사용해 확장해야 하는 상황인데, 쓰레드로 구현해야 한다. 게다가 그 부모 클래스는 Thread를 확장하지 않았다.
이렇게 자바에서 Thread 클래스를 확장 받아야만 쓰레드로 구현할 수 있는데, 다중 상속이 불가능하므로 해당 클래스를 쓰레드로 만들 수 없다.
하지만, 인터페이스는 여러 개의 인터페이스를 구현해도 전혀 문제가 발생하지 않는다. 따라서, 이런 경우에는 Runnable 인터페이스를 구현해서 사용하면 된다.
- 쓰레드 클래스가 다른 클래스를 확장할 필요가 있을 경우에는 Runnable 인터페이스를 구현
- 그렇지 않은 경우에는 쓰레드 클래스를 사용
쓰레드와 실행 순서
그동안 우리는 지금까지 모든 프로그램을 순차적으로(sequential하게) 실행했다. 반드시 한 줄의 코드가 있으면, 그 줄의 실행이 끝날 때까지 기다렸다가 다음 줄이 실행된다.
하지만, 쓰레드를 구현할 때 start() 메소드를 호출하면, 쓰레드 클래스에 있는 run() 메소드의 내용이 끝나든, 끝나지 않든 간에 쓰레드를 시작한 메소드에서는 그 다음 줄에 있는 코드를 실행한다. 즉, 여러 쓰레드를 실행시켰을 경우 순서는 보장되지 않는다.
쓰레드가 끝나는 시점
run() 메소드가 종료되면 끝난다.
만약 run() 메소드가 끝나지 않으면, 우리가 실행한 어플리케이션은 끝나지 않는다. 단, 데몬 쓰레드 여부는 여기서 예외다.
정말 끝나지 않았는지를 확인하는 방법도 있다.
Thread 클래스
생성자
Thread 클래스는 다음과 같이 8개의 생성자가 있다.
| 생성자 | 설명 |
|---|---|
| Thread() | 새로운 쓰레드를 생성한다. |
| Thread(Runnable target) | 매개 변수로 받은 target 객체의 run() 메소드를 수행하는 쓰레드를 생성한다. |
| Thread(Runnable target, String name) | 매개 변수로 받은 target 객체의 run() 메소드를 수행하고, name이라는 이름을 갖는 쓰레드를 생성한다. |
| Thread(String name) | name이라는 이름을 갖는 쓰레드를 생성한다. |
| Thread(ThreadGroup group, Runnable target) | 매개 변수로 받은 group의 쓰레드 그룹에 속하는 target 객체의 run() 메소드를 수행하는 쓰레드를 생성한다. |
| Thread(ThreadGroup group, Runnable target, String name) | 매개 변수로 받은 group의 쓰레드 그룹에 속하는 target 객체의 run() 메소드를 수행하고, name 이라는 이름을 갖는 쓰레드를 생성한다. |
| Thread(ThreadGroup group, Runnable target, String name, long stackSize) | 매개 변수로 받은 group의 쓰레드 그룹에 속하는 target 객체의 run() 메소드를 수행하는 쓰레드를 생성한다. 단, 해당 쓰레드의 스택의 크기는 stackSize 만큼만 가능하다. |
| Thread(ThreadGroup group, String name) | 매개 변수로 받은 group의 쓰레드 그룹에 속하는 name이라는 이름을 갖는 쓰레드를 생성한다. |
💡 Java API 21버전을 보면, 생성자가 하나 더 있다.
책에서는 Java 8버전으로 설명하고 있어서, 최신 버전이 궁금하면 따로 찾아보는게 좋을 거 같다.
쓰레드의 이름
모든 쓰레드는 이름이 있다. 만약 아무런 이름을 지정하지 않으면, 그 쓰레드의 이름은 “Thread-n”이다. 여기서 n은 쓰레드가 생성된 순서에 따라 증가한다.
개발자가 쓰레드 이름을 지정한다면 해당 쓰레드는 별도의 이름을 가지게 된다. 만약 쓰레드 이름이 겹친다고 해도 예외나 에러가 발생하지는 않는다.
ThreadGroup
어떤 쓰레드를 생성할 때 쓰레드를 묶어 놓을 수 있다. 그게 바로 ThreadGroup이다.
이렇게 쓰레드의 그룹을 묶으면 ThreadGroup 클래스에서 제공하는 여러 메소드를 통해서 각종 정보를 얻을 수 있다.
StackSize
stackSize라는 값은 스택의 크기를 이야기한다. 쓰레드에서 얼마나 많은 메소드를 호출하는지, 얼마나 많은 쓰레드가 동시에 처리되는지는 JVM이 실행되는 OS의 플랫폼에 따라서 매우 다르다. 경우에 따라서는 이 값이 무시될 수도 있다.
💡 Stack
여기서 말하는 스택은 Collection의 Stack 클래스가 아니다.
자바 프로세스가 시작되면 실행 데이터 공간(Runtime data area)이 구성된다. 이 공간 중 하나가 스택이라는 공간이며, 쓰레드가 생성될 때마다 별도의 스택이 할당된다.
자세한 내용은 자바 언어 스펙 문서를 참고할 것.
생성자 사용하기
쓰레드의 이름 지정
쓰레드의 이름을 “ThreadName”으로 지정하는 코드이다. 이렇게 사용하면 Thread(String name) 을 호출한 것과 동일한 효과를 보게 된다.
public class NameThread extends Thread {
public NameThread() {
super("ThreadName");
}
}다만, 이렇게 지정할 경우 이 쓰레드 객체를 몇 십개를 만들어도 모두 “ThreadName”이라는 동일한 이름을 가지게 된다.
이러한 단점을 피하고 싶다면 생성자를 다음과 같이 변경하면 된다.
public class NameThread extends Thread {
public NameThread(String name) {
super(name);
}
}쓰레드 시작 시 값 전달
쓰레드를 실행할 때에는 run() 메소드가 진입점이고, 쓰레드를 시작시킬 때에는 start() 메소드를 호출해야 한다. 그리고 이 메소드들에는 매개 변수가 없다.
만약 쓰레드를 시작할 때 어떤 값을 전달하고 싶다면 생성자를 통해 값을 받아야 한다.
다음은 쓰레드 객체를 생성할 때 매개 변수를 받고, 인스턴스 변수로 사용는 예제이다.
public class NameCalcThread extends Thread {
private int calcNumber;
public NameCalcThread (String name,int calcNumber) {
super(name);
this.calcNumber=calcNumber;
}
public void run() {
calcNumber++;
}
}이렇게 사용하면, calcNumber 라는 값을 동적으로 지정하여 쓰레드를 시작할 수 있다.
Thread 클래스의 주요 메소드
sleep() 메소드
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| static void | sleep(long millis) | 매개 변수로 넘어온 시간(1/1000초)만큼 대기한다. |
| static void | sleep(long millis, int nanos) | 첫 번째 매개 변수로 넘어온 시간(1/1000초) + 두 번째 매개 변수로 넘어온 시간(1/1000000000초)만큼 대기한다. |
Thread에 있는 static 메소드는 대부분 해당 쓰레드를 위해서 존재하는 것이 아니라, JVM에 있는 쓰레드를 관리하기 위한 용도로 사용된다.
물론 예외도 있다. 그 예외 중 하나가 이 절에서 살펴볼 sleep() 메소드다. 이 장의 앞 부분에서 데몬 쓰레드를 제외한, run() 메소드가 끝나지 않으면 애플리케이션은 끝나지 않는다고 했다.
다음과 같이 While(true) 로 선언하면 이 while문은 내부에서 break를 호출하거나, 예외를 발생시키지 않는 한 멈추지 않는다.
public class EndlessThread extends Thread {
public void run() {
while(true) {
try {
System.out.println(System.currentTimeMillis());
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}현재 시간을 밀리초 단위로 출력하고, Thread 클래스의 sleep() 메소드를 static하게 호출하여 1초간 멈춘다. 이렇게 되면, 이 프로그램은 우리가 Ctrl+c 를 누를 때까지 1초에 한 번씩 현재 시간을 밀리초 단위로 계속 출력한다.
그리고, sleep() 메소드는 InterruptedException을 던질 수도 있다고 선언되어 있으므로 try-catch로 묶어 주어야만 한다.
EndlessThread 클래스를 실행시켜보면 main() 메소드의 수행이 끝나더라도, main() 메소드나 다른 메소드에서 시작한 쓰레드가 종료하지 않으면 해당 자바 프로세스가 끝나지 않는 것을 확인할 수 있다.
속성을 확인하고 지정하는 메소드
Thread 클래스의 주요 메소드는 크게 둘로 나눌 수 있다.
- 쓰레드의 속성을 확인하고, 지정하기 위한 메소드
- 쓰레드의 상태를 통제하기 위한 메소드
먼저, 속성을 확인하고 지정하는 메소드는 다음과 같다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| void | run() | 우리가 구현해야 하는 메소드이다. |
| long | getId() | 쓰레드의 고유 id를 리턴한다. JVM에서 자동으로 생성해준다. |
| String | getName() | 쓰레드의 이름을 리턴한다. |
| void | setName(String name) | 쓰레드의 이름을 지정한다. |
| int | getPriority() | 쓰레드의 우선 순위를 확인한다. |
| void | setPriority(int newPriority) | 쓰레드의 우선 순위를 지정한다. |
| boolean | isDaemon() | 쓰레드가 데몬인지 확인한다. |
| void | setDaemon(boolean on) | 쓰레드를 데몬으로 설정할지 아닌지를 설정한다. |
| StackTraceElement[] | getStackTrace() | 쓰레드의 스택 정보를 확인한다. |
| Thread.State | getState() | 쓰레드의 상태를 확인한다. |
| ThreadGroup | getThreadGroup() | 쓰레드의 그룹을 확인한다. |
쓰레드의 우선 순위(Priority)
쓰레드의 우선 순위라는 것은 말 그대로, 대기하고 있는 상황에서 더 먼저 수행할 수 있는 순위를 말한다. 우선 순위의 기본값은 5이다.
쓰레드 API를 잘 살펴보면 다음과 같이 우선 순위와 관계 있는 3개의 상수가 있다.
| 상수 | 값 및 설명 |
|---|---|
| MAX_PRIORITY | 가장 높은 우선 순위이며, 그 값은 10이다. |
| NORM_PRIORITY | 일반 쓰레드의 우선 순위이며, 그 값은 5다 |
| MIN_PRIORITY | 가장 낮은 우선 순위이며, 그 값은 1이다. |
만약 우선 순위를 정할 일이 있다면, 숫자로 정하는 것보다는 이 상수를 이용할 것을 권장한다.
하지만 마음대로 우선 순위를 정했다가는 잘못해서 장애로 연결 될 수 있으므로, 대부분 이 값은 기본값으로 사용하는 것을 권장한다.
Daemon Thread
데몬 쓰레드가 아닌 사용자 쓰레드는 JVM이 해당 쓰레드가 끝날 때까지 기다린다.
즉, 어떤 쓰레드를 데몬으로 지정하면, 그 쓰레드가 수행되고 있든, 수행되지 않고 있든 상관없이 JVM이 끝날 수 있다.
- 해당 쓰레드가 시작되기(start() 메소드가 호출되기) 전에 쓰레드 객체를 데몬 쓰레드로 지정해야만 그 쓰레드가 데몬 쓰레드로 인식된다.
- 쓰레드가 시작한 다음에는 데몬으로 지정할 수 없다.
- 데몬 쓰레드는 해당 쓰레드가 종료되지 않아도 다른 실행중인 일반 쓰레드가 없다면 멈춰 버린다.
데몬 쓰레드를 사용하는 이유
예를 들어, 모니터링하는 쓰레드를 별도로 띄워 모니터링하다가 주요 쓰레드가 종료되면 관련된 모니터링 쓰레드가 종료되어야 프로세스가 종료될 수 있다.
그런데, 모니터링 쓰레드를 데몬 쓰레드로 만들지 않으면 프로세스가 종료될 수 없게 된다.
이렇게 부가적인 작업을 수행하는 쓰레드를 선언할 때 데몬 쓰레드를 만든다.
Synchronized
이 단어는 자바의 예약어 중 하나로, 쓰레드와 뗄 수 없는 관계다.
앞에서 “쓰레드에 안전하다(Thread safe)”라고 이야기가 나왔었다. 이렇게 어떤 클래스나 메소드가 쓰레드에 안전하려면, Synchronized를 사용해야만 한다.
쓰레드에 안전하다
여러 쓰레드가 한 객체에 선언된 메소드에 접근하여 데이터를 처리하려고 할 때, 동시에 연산을 수행하여 값이 꼬이는 경우가 발생할 수 있다.
이 때, 여기서 말한 ‘한 객체’라는 건 하나의 클래스에서 생성된 여러 개의 객체가 아니라, 동일한 하나의 객체를 말한다.
단, 메소드에서 인스턴스 변수를 수정하려고 할 때에만 이러한 문제가 생긴다. 매개 변수나 메소드에서만 사용하는 지역변수만 다루는 메소드는 전혀 Synchronized로 선언할 필요가 없다.
Synchronized를 사용하는 방법
두 가지 방법으로 사용할 수 있다.
- 메소드 자체를 Synchronized로 선언하는 방법 (Synchronized methods)
- 메소드 내의 특정 문장만 Synchronized로 감싸는 방법 (Synchronized statements)
Synchronized methods
메소드를 Synchronized로 선언하려면 메소드 선언 문에 Synchronized 를 넣어주면 된다.
public Synchronized void plus(int value) {
amount += vale; // amount는 인스턴스 변수다.
}이렇게 선언하면, 동일한 객체의 이 메소드에 2개의 쓰레드가 접근하든, 100개의 쓰레드가 접근하든 가에 한 순간에는 하나의 쓰레드만 이 메소드를 수행하게 된다.
다시 말해, 이 메소드는 동일한 객체를 참조하는 다른 쓰레드에서, 이 메소드를 변경하려고 하면 먼저 들어온 쓰레드가 종료될 때까지 기다린다.
Synchronized statements
Synchronized mehtods 방법은 성능 상 문제점이 발생할 수 있다.
예를 들어 어떤 클래스에 30줄짜리 메소드와 amount라는 인스턴스 변수가 있다고 하자. 그 30줄짜리 메소드의 단 한 줄에서만 amount 변수를 다룬다고 했을 때, 만약 메소드 전체를 Synchronized로 선언하면 나머지 29줄의 처리를 할 때 필요 없는 대기 시간이 발생하게 된다.
이러한 경우에는 메소드 전체를 감싸면 안 되며, amount 변수를 처리하는 부분만 Synchronized 처리를 해주면 된다.
public void plus(int value) {
synchronized(this) {
amount+=value;
}
}
public void minus(int value) {
synchronized(this) {
amount-=value;
}
}이렇게 하면 synchronized(this) 이후에 있는 중괄호 내에 있는 연산만 동시에 여러 쓰레드에서 처리하지 않겠다는 의미다.
Synchronized lock
소괄호 안에 this가 있는 부분에서는 잠금 처리를 하기 위한 객체를 선언한다. 여기서는 그냥 this라고 지정했지만, 일반적으로는 다음과 같이 별도의 객체를 선언하여 사용한다.
Object lock=new Object();
public void plus(int value) {
synchronized(lock) {
amount+=value;
}
}
public void minus(int value) {
synchronized(lock) {
amount-=value;
}
}- synchronized를 사용할 때에는 하나의 객체를 사용하여 블록 내의 문장을 하나의 쓰레드만 수행하도록 할 수 있다.
- 블록에 들어간 쓰레드가 일을 다 처리하고 나오면, 대기하고 있던 다음 쓰레드가 일을 시작할 수 있다.
- 이러한 객체는 하나의 클래스에서 두 개 이상 만들어 사용할 수도 있다.
- 만약 amount 변수와 interest라는 변수가 있을 때, interest 변수를 처리할 때에도 여러 쓰레드에서 접근하면 안 되는 경우
- 이럴 때 만약 lock이라는 하나의 잠금용 객체만을 사용하면 amount 변수를 처리할 때, interest 변수를 처리하려는 부분도 처리를 못하게 된다.
- 따라서, 두 개의 별도의 lock 객체를 사용하면 보다 효율적인 프로그램이 된다.
Synchronized의 유의할 점
같은 객체를 참조할 때만 유효
메소드를 Synchronized할 때에는 같은 객체를 참조할 때에만 유효하다.
CommonCalculate calc1=new CommonCalculate();
ModifyAmountThread thread1=new ModifyAmountThread(calc,true);
CommonCalculate calc2=new CommonCalculate();
ModifyAmountThread thread2=new ModifyAmountThread(calc,true);만약 이렇게 두 개의 쓰레드가 서로 다른 객체를 참조한다면 Synchronized로 선언된 메소드는 같은 객체를 참조하는 것이 아니므로, Synchronized를 안쓰는 것과 동일하다고 보면 된다.
객체를 서로 다른 쓰레드에서 공유할 때 사용
Synchronized는 여러 쓰레드에서 하나의 객체에 있는 인스턴스 변수를 동시에 처리할 때 발생할 수 있는 문제를 해결하기 위해서 필요한 것이다.
즉, 인스턴스 변수가 선언되어 있다고 하더라도, 변수가 선언되어 있는 객체를 다른 쓰레드에서 공유할 일이 전혀 없다면 Synchronized 예약어를 사용할 이유가 전혀 없다.
StringBuilder와 StringBuffer
앞서, StringBuffer는 쓰레드에 안전하고, StringBuilder는 쓰레드에 안전하지 않다고 이야기했다. 이를 좀 더 상세히 이야기해보자면 다음과 같다.
- StringBuffer는 Synchronized 블록으로 주요 데이터 처리 부분을 감싸 두었다.
- StringBuilder는 Synchronized를 사용하지 않았다.
따라서, StringBuffer는 하나의 문자열 객체를 여러 쓰레드에서 공유하는 경우에만 사용하고, StringBuilder는 여러 쓰레드에서 공유할 일이 없을 때 사용하면 된다.
쓰레드를 통제하는 메소드들
여러 가지 이유로 쓰레드를 통제해야 하는 경우가 있을 수 있다. 쓰레드의 상태를 통제하는 메소드는 다음과 같다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| Thread.State | getState() | 쓰레드의 상태를 확인한다. |
| void | join() | 수행중인 쓰레드가 중지할 때까지 대기한다. |
| void | join(long millis) | 매개 변수에 지정된 시간만큼 (1/1000초) 대기한다. |
| void | join(long millis, int nanos) | 첫 번째 매개 변수에 지정된 시간(1/1000초) + 두 번째 매개 변수에 지정된 시간(1/1000000000초)만큼 대기한다. |
| void | interrupt() | 수행중인 쓰레드에 중지 요청을 한다. |
State 클래스 (Enum)
자바의 Thread 클래스에는 State라는 enum 클래스가 있다. 이 클래스는 public static으로 선언되어 있으므로, “Thread.State.상수”로 사용할 수 있다.
State 클래스에 선언되어 있는 상수들의 목록은 다음과 같다.
| 상태 | 의미 |
|---|---|
| NEW | 쓰레드 객체는 생성되었지만, 아직 시작되지는 않은 상태 |
| RUNNABLE | 쓰레드가 실행중인 상태 |
| BLOCKED | 쓰레드가 실행 중지 상태이며, 모니터 락(monitor lock)이 풀리기를 기다리는 상태 |
| WAITING | 쓰레드가 대기 중인 상태 |
| TIMED_WAITING | 특정 시간만큼 쓰레드가 대기중인 상태 |
| TERMINATED | 쓰레드가 종료된 상태 |
쓰레드의 상태
어떤 쓰레드이건 간에 “NEW → 상태 → TERMMINATED”의 라이프 사이클을 갖는다. 여기서 “상태”에 해당하는 것은 NEW와 TERMINATIED를 제외한 모든 다른 상태를 의미한다.
아래 그림 출처: http://www.uml-diagrams.org/state-machine-diagrams-examples.html
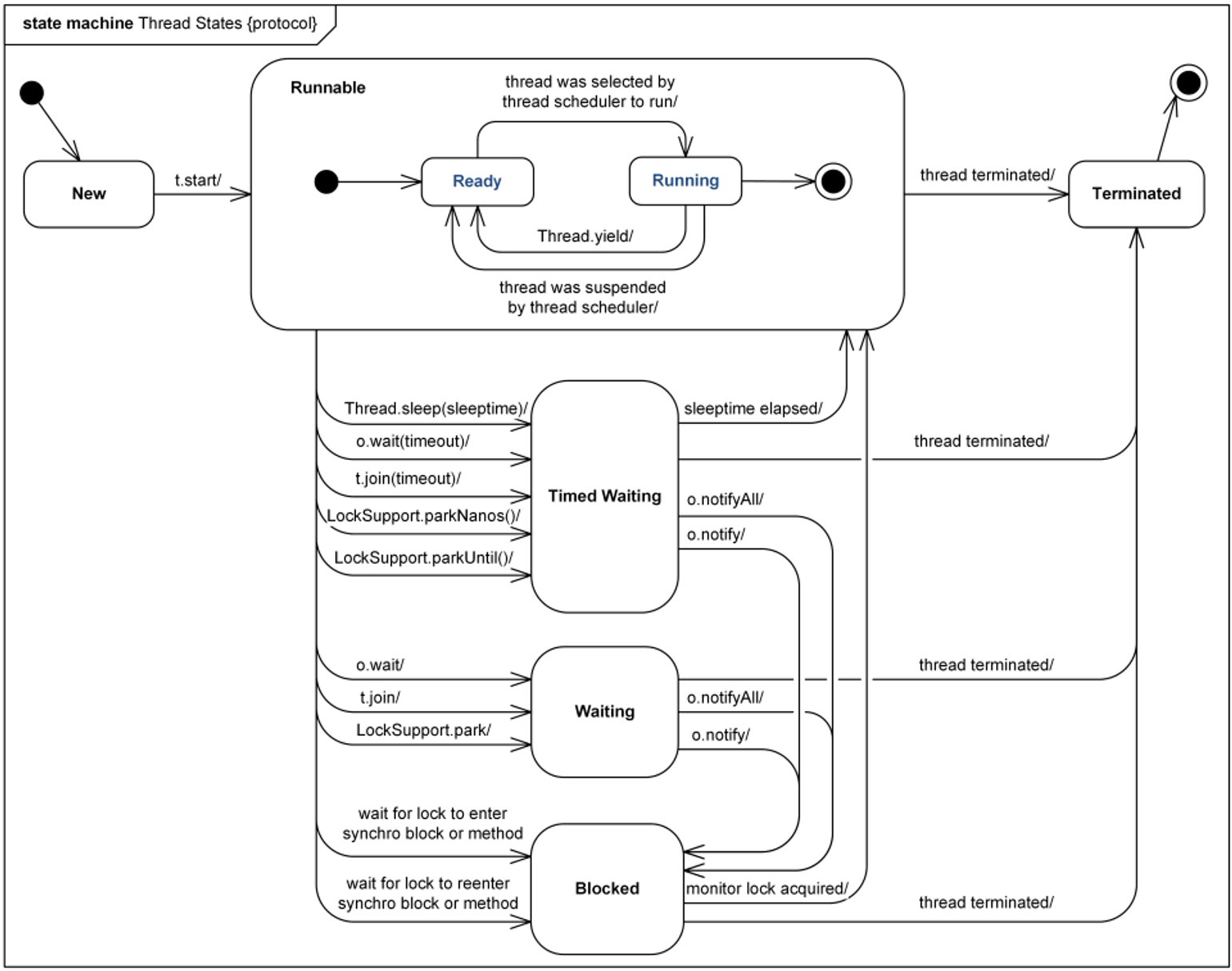
위 그림을 보면 어떤 메소드가 호출되면 해당 상태로 전환되는지를 한 눈에 볼 수 있다.
-
New: 쓰레드 객체가 생성
-
Runnable: 쓰레드가 실행 중
- 쓰레드 스케줄러에 의해 쓰레드가 수행하도록 지정되었을 경우, Ready → Running 상태로 전환된다.
-
Timed Waiting
sleep(timeout), wait(timeout), join(timeout) 등의 메소드로 일정 시간 동안 대기 중인 상태
-
Waiting
wait(), join() 등의 메소드로 대기 중인 상태
-
Blocked
Synchro 블록이나 메소드에 들어가기를 기다린다.
-
Terminated : 쓰레드 종료
join() 메소드
이 메소드는 해당 쓰레드가 종료될 때까지 기다린다.
- 매개 변수가 없는 join() 메소드는 해당 쓰레드가 끝날 때까지 무한대로 대기한다.
- 만약 특정 시간만큼만 기다리고 싶다면, join() 메소드의 매개 변수에 기다리고 싶은 시간을 지정하면 된다.
- 이 시간은 밀리초 단위로 지정한다.
- 매개 변수값을 0으로 지정하면 join() 메소드를 사용하는 것과 동일하게 무한정 기다리게 된다.
- 더 세밀하게 지정하고 싶다면, 매개 변수가 두 개인 join() 메소드를 사용하면 된다.
- 매개 변수가 두 개인 join() 메소드의 첫 번째 매개 변수는 밀리초 단위이며, 두 번째 매개 변수는 나노초 단위이다.
- 두 번째 매개 변수는 1 밀리초 이하의 시간, 즉 1~999,999까지만 지정하면 된다.
- 만약, 첫 번째 매개 변수가 음수이거나, 두 번째 매개 변수가 1~999,999 사이의 값이 아니라면 IllegalArgumentException이라는 예외가 발생하게 된다.
만약 1분간 기다리고 싶다면 다음과 같이 사용한다.
thread.join(60000);0.002000003초 만큼만 기다리고 싶다면, 다음과 같이 사용한다
thread.join(2, 3);interrupt() 메소드
interrupt() 메소드는 현재 수행 중인 쓰레드를 InterruptedException을 발생시키면서 중단시킨다.
이 예외는 앞서 sleep()과 join() 메소드에서 발생한다고 했던 예외다. 즉, sleep()과 join() 메소드와 같이 대기 상태를 만드는 메소드가 호출되었을 때에는 interrupt() 메소드를 호출할 수 있다.
만약 쓰레드가 시작하기 전이나, 종료된 상태에 interrupt() 메소드를 호출하는 상황에서는 예외나 에러 없이 그냥 다음 문장으로 넘어간다.
추가로, 자바의 Thread에는 stop()이라는 메소드가 있다. 이 stop() 메소드는 안전상의 이유로 deprecated 되었으며, 이 메소드를 사용하면 안 된다. 그러므로, interrupt() 메소드를 사용하여 쓰레드를 멈추어야 한다.
이 메소들 외의 Thread 클래스에 선언되어 있는 상태 확인을 위한 메소드
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| void | checkAccess() | 현재 수행중인 쓰레드가 해당 쓰레드를 수정할 수 있는 권한이 있는지를 확인한다. 만약 권한이 없다면 SecurityException이라는 예외를 발생시킨다. |
| boolean | isAlive() | 쓰레드가 살아 있는지를 확인한다. 해당 쓰레드의 run() 메소드가 종료되었는지 안 되었는지를 확인하는 것이다. |
| boolean | isInterrupted() | run() 메소드가 정상적으로 종료되지 않고, interrupt() 메소드의 호출을 통해서 종료되었는지를 확인하는 데 사용한다. |
| static boolean | interrupted() | 현재 쓰레드가 중지되었는지를 확인한다. |
interrupted() 메소드는 static 메소드이므로, 현재 쓰레드가 종료되었는지를 확인할 때 사용한다.
isInterrupted() 메소드는 다른 쓰레드에서 확인할 때 사용되고, interrupted() 메소드는 본인의 쓰레드를 확인할 때 사용된다는 점이 다르다.
Thread 클래스의 주요 static 메소드
JVM에서 사용되는 쓰레드의 상태들을 확인하기 위해서는 Thread 클래스의 static 메소드들을 알아야만 한다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| static int | activeCount() | 현재 쓰레드가 속한 쓰레드 그룹의 쓰레드 중 살아있는 쓰레드의 개수를 리턴한다. |
| static Thread | currentThread() | 현재 수행 중인 쓰레드의 객체를 리턴한다. |
| static void | dumpStack() | 콘솔 창에 현재 쓰레드의 스택 정보를 호출한다. |
Object 클래스에 선언된 쓰레드와 관련있는 메소드들
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| void | wait() | 다른 쓰레드가 Object 객체에 대한 notify() 메소드나 notifyAll() 메소드를 호출할 때까지 현재 쓰레드가 대기하고 있도록 한다. |
| void | wait(long timeout) | wait() 메소드와 동일한 기능을 제공하며, 매개 변수에 지정한 밀리초만큼만 대기한다. |
| void | wait(long timeout, int nanos) | wait() 메소드와 동일한 기능을 제공한다. 이 메소드는 보다 자세한 밀리초+나노초 만큼만 대기한다. |
| void | notify() | Object 객체의 모니터에 대기하고 있는 단일 쓰레드를 깨운다. |
| void | notifyAll() | Object 객체의 모니터에 대기하고 있는 모든 쓰레드를 깨운다. |
wait() 메소드
wait() 메소드를 사용하면 쓰레드가 대기 상태가 되며, notify()나 notifyAll() 메소드를 사용하면 쓰레드의 대기 상태가 해제된다.
wait() 메소드가 호출되면 쓰레드의 상태는 WAITING 상태가 된다. 누군가 이 쓰레드를 깨워 줘야만 WAITING 상태에서 풀린다. interrupt() 메소드를 호출하여 대기 상태에서 풀려날 수도 있겠지만, notify() 메소드를 호출해서 풀어야 InterruptedException도 발생하지 않고, wait() 이후의 문장도 정상적으로 수행하게 된다.
notify() 메소드
notify() 메소드를 호출하면 먼저 대기하고 있는 것부터 그 상태를 풀어준다.
만약 monitor 라는 객체를 lock 객체로 사용하여 대기 중인 쓰레드가 2개라면 다음과 같이 2번 호출해줘야 한다.
// 전체 코드는 책의 예제 코드 참고 (176P~)
public class StateThread extends Thread {
private Object monitor;
public StateThread(Object monitor) {
this.monitor=monitor;
}
public void run() {
try {
synchronized(monitor) {
monitor.wait();
}
System.out.println(getName()+" is notified.");
Thread.sleep(1000);
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}
public class RunObjectThreads {
public static void main(String args[]) {
Object monitor =new Object();
StateThread thread=new StateThread(monitor);
StateThread thread2=new StateThread(monitor);
try {
thread.start();
thread2.start();
synchronized(monitor) {
monitor.notify();
monitor.notify();
}
thread.join();
thread2.join();
} catch (InterruptedException ie) {
ie.printStackTrace();
}
}
}그런데, monitor 객체를 통해 wait() 상태가 몇 개인지 모르는 상태에서 이렇게 구현하는 것은 별로 좋은 방법이 아니다.
이럴 때는 다음과 같이 notifyAll() 메소드를 사용하는 것이 좋다.
synchronized(monitor) {
monitor.notifyAll();
}ThreadGroup 클래스
ThreadGroup은 쓰레드의 관리를 용이하게 하기 위한 클래스다. 하나의 애플리케이션에서는 여러 종류의 쓰레드가 있을 수 있으며, 만약 ThreadGroup 클래스가 없으면 용도가 다른 여러 쓰레드를 관리하기 어려울 것이다.
쓰레드 그룹은 기본적으로 운영체제의 폴더처럼 뻗어나가는 트리(Tree) 구조를 가진다. 즉, 하나의 그룹이 다른 그룹에 속할 수도 있고, 그 아래에 또 다른 그룹을 포함할 수도 있다.
// 쓰레드 그룹 지정 예제
SleepThread sleep1=new SleepThread(5000);
SleepThread sleep2=new SleepThread(5000);
ThreadGroup group=new ThreadGroup("Group1");
Thread thread1=new Thread(group,sleep1);
Thread thread2=new Thread(group,sleep2);주요 메소드
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| int | activeCount() | 실행중인 쓰레드의 개수를 리턴한다. |
| int | activeGroupCount() | 실행중인 쓰레드 그룹의 개수를 리턴한다. |
| int | enumerate(Thread[] list) | 현재 쓰레드 그룹에 있는 모든 쓰레드를 매개 변수로 넘어온 쓰레드 배열에 담는다. |
| int | enumerate(ThreadGroup[] list) | 현재 쓰레드 그룹에 있는 모든 쓰레드 그룹을 매개 변수로 넘어온 쓰레드 그룹 배열에 담는다. |
| String | getName() | 쓰레드 그룹의 이름을 리턴한다. |
| ThreadGroup | getParent() | 부모 쓰레드 그룹을 리턴한다. |
| void | list() | 쓰레드 그룹의 상세 정보를 출력한다. |
| void | setDaemon(boolean daemon) | 지금 쓰레드 그룹에 속한 쓰레드들을 데몬으로 지정한다. |
enumerate()
이 메소드는 해당 쓰레드 그룹에 포함된 쓰레드나 쓰레드 그룹의 목록을 매개 변수로 넘어온 배열에 담는다. 이 메소드의 리턴값은 배열에 저장된 쓰레드의 개수다.
따라서, 쓰레드 그룹에 있는 모든 쓰레드의 객체를 제대로 담으려면 activeCount() 메소드를 통해서 현재 실행중인 쓰레드의 개수를 정확히 파악한 후, 그 개수만큼의 배열을 생성하면 된다.
int activeCount=group.activeCount();
Thread[] tempThreadList=new Thread[activeCount];
int result=group.enumerate(tempThreadList);
for(Thread thread:tempThreadList) {
System.out.println(thread);
}이렇게 쓰레드 그룹을 사용하면 쓰레드를 보다 체계적으로 관리할 수 있다.
ThreadLocal 클래스와 volatile 예약어
이 둘은 어려운 개념이므로 부록에서 다룬다.
정리해 봅시다.
Q. 쓰레드와 프로세스의 차이를 이야기 해 보세요.
Me: JVM은 기본적으로 아무 옵션 없이 실행하면 OS 마다 다르지만, 적어도 32MB~64MB의 물리 메모리를 점유한다. 그에 반해서, 쓰레드를 하나 추가하면 1MB 이내의 메모리를 점유한다. 그래서 쓰레드를 “경량 프로세스-lightweight process”라고도 부른다.
Q. 쓰레드 클래스를 만들기 위해서는 어떤 인터페이스를 구현하면 될까요?
Me: Runnable 인터페이스
Q. 위의 문제에서 이야기한 인터페이스에 선언되어 있는 유일한 메소드는 무엇인가요?
Me: run() 메소드
Q. 쓰레드 클래스를 만들기 위해서 어떤 클래스를 확장하면 되나요?
Me: Thread 클래스
Q. 쓰레드가 시작되는 메소드의 이름은 무엇인가요?
Me: run() 메소드
Q. 쓰레드를 시작하는 메소드의 이름은 무엇인가요?
Me: start() 메소드
Q. 쓰레드에 선언되어 있는 sleep() 메소드의 역할은 무엇인가요?
Me: 일정 시간동안 쓰레드를 대기시킨다.
Q. sleep() 메소드를 사용할 때 try-catch 로 감싸 주어야 하는 이유는 무엇인가요?
Me: 대기 중에 interrupt() 메소드가 호출되면 InterruptedException을 던질 수도 있다고 선언되어 있으므로 try-catch로 묶어 주어야만 한다.
Q. 데몬(Daemon) 쓰레드와 일반 쓰레드의 차이는 무엇인가요?
Me: 일반 쓰레드가 종료되어야 프로세스가 종료할 수 있다. 그러나, 데몬 쓰레드는 해당 쓰레드가 종료되지 않아도 다른 실행 중인 일반 쓰레드가 없다면 멈춰 버린다.
Q. synchronized 구문은 왜 써 주며, 어디에 사용해야 하나요?
Me: 여러 쓰레드가 한 객체에 선언된 메소드에 접근하여 데이터를 처리하려고 할 때 동시에 연산을 수행하여 값이 꼬이는 경우 사용해야 한다.
Q. synchronized 를 사용하는 두 가지 방법은 어떤 것 인가요?
Me: 메소드 자체를 synchronized로 선언하거나, 메소드 내의 특정 문장만 Synchronized로 감싸는 방법이 있다.
Q. 쓰레드의 상태에는 어떤 것들이 있나요?
Me: NEW, RUNNABLE, BLOCKED, WAITING, TIMED_WAITING, TERMINATED
Q. 쓰레드에 선언되어 있는 join() 메소드의 용도는 무엇인가요?
Me: 해당 쓰레드가 종료될 때까지 기다린다.
Q. 쓰레드에 선언되어 있는 interrupt() 메소드의 용도는 무엇인가요?
Me: 예외를 발생시키며 해당 쓰레드를 중지시킨다.
Q. interrupt() 메소드를 호출하면 해당 쓰레드는 어떤 상태에 있을 때 interrupt() 메소드가 호출된 효과가 발생 되나요?
Me: sleep()과 join() 메소드와 같이 대기 상태를 만드는 메소드가 호출되었을 때
Q. Object 클래스에 선언된 wait() 메소드의 용도는 무엇인가요?
Me: notify() 메소드가 호출될 때까지 해당 쓰레드를 대기 상태로 만든다.
Q. Object 클래스에 선언된 notify() 메소드의 용도는 무엇인가요?
Me: 대기하고 있는(waiting) 쓰레드를 깨운다.
Q. ThreadGroup 클래스에 선언된 enumerate() 메소드의 용도는 무엇인가요?
Me: 해당 쓰레드 그룹에 포함된 쓰레드나 쓰레드 그룹의 목록을 매개 변수로 넘어온 배열에 담는다.
질문
💡 책에 있는 내용이 아닙니다.
책을 읽으며 설명이 더 필요하거나, 추가로 궁금한 점에 대해 질문 형식으로 작성 후, 답을 구해보고 있습니다.
참고한 사이트나 영상은 [출처]로 달아두었으며, 오류 지적은 언제나 환영합니다.
Q. 프로세스와 스레드의 차이
프로그램이란
먼저, 참고한 사이트에 따르면 프로그램의 정의는 다음과 같다.
프로그램이란, 파일이 저장 장치에 저장되어 있지만 메모리에는 올라가 있지 않은 정적인 상태를 말한다.
다시 말해, 아직 실행하기 전의 코드 덩어리를 말한다.
Process란
프로그램을 실행하면 운영 체제가 자원을 할당해주고, 프로그램은 컴퓨터 메모리에 올라간다.
이 때, 이 실행 중인 상태의 프로그램을 프로세스(Process)라고 한다. 위키피디아에 따르면 스케줄링의 대상이 되는 “작업(Task)”이라는 용어와 거의 같은 의미로 쓰인다.
프로세스는 운영체제로부터 아래와 같이 각각 독립된 메모리 영역을 할당해준다.
- Code
- Data
- Stack
- Heap
Thread란
프로그램이 복잡해지면서, 프로세스 하나로는 실행하기 벅차게 되었다. 안전성을 위해 자신에게 할당된 메모리 내의 정보에만 접근할 수 있는 프로세스를 늘리는 것은 불가능한 일이었고, 따라서 그보다 더 작은 실행 단위인 스레드가 나왔다.
스레드(Thread)는 프로세스가 할당받은 메모리 영역 내에서, Stack 메모리 영역은 따로 할당받고, 나머지 메모리 영역은 공유한다.
따라서, 각 스레드는 별도의 Stack 영역을 가지고 있고 힙 메모리는 서로 공유하여 읽고 쓸 수 있다.
- 스레드별 할당: Stack
- 공유 자원: Code, Data, Heap
Multi Process와 Multi Thread
멀티 프로세스는 여러 개의 프로세스가 동시에 실행되는 것이다. 각 프로세스는 독립적인 메모리 공간을 가지므로, 서로 영향을 주지 않는다.
멀티 스레드는 하나의 프로세스가 여러 작업을 여러 스레드를 사용해 동시에 처리하는 것을 의미한다.
- 프로세스 간의 Context-Switching은 많은 자원 손실이 발생한다.
- 스레드는 Context-Switching할 때 공유하고 있는 메모리만큼의 메모리 자원을 아낄 수 있다.
- 스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신의 부담이 적어서 응답 시간이 빠르다.
- 스레드 하나가 프로세스 내 자원을 망쳤을 때 모든 프로세스가 종료될 수 있다.
- 자원을 공유하기 때문에 필연적으로 동기화 문제가 발생한다.
💡 유사한 단어들
1. 멀티 프로세서(Multi-Processor): 하나의 시스템이 여러 개의 CPU 코어를 포함하는 구성을 의미한다. 프로세스가 프로그램의 실행 상태라면, 프로세서는 CPU 코어를 말한다고 보면 된다.
2. 멀티 프로세싱 (Multi-Processing): 한 컴퓨터 내에 2개 이상의 프로세서(CPU)들이 동시에 병렬로 작업을 수행하는 것을 말한다. 일반적으로는 멀티 프로세서와 유사한 의미로 사용되고 있다.
3. 멀티 프로그래밍(multi-programming): 한 CPU는 한 시점에 하나의 프로그램만 수행한다. CPU의 효율성을 높이기 위해 메인 메모리에 여러 프로그램을 유지한다.
4. 멀티 태스킹(multi-tasking): 멀티 프로그래밍의 확장된 개념이다. 여러 메인 메모리에 올라와 있는 여러 프로세스들을 번갈아 가며 수행하는데, 이 속도가 빨라서 동시에 수행되는 것처럼 보인다.
ex) 메모장과 엑셀, 크롬을 켜고 함께 이용하는 것5. 멀티 스레딩 (Multi-Threading): 한 프로세스 내에서 여러 스레드를 생성할 수 있는 프로그램을 의미한다. 여러 스레드는 독립적으로 수행되지만 프로세스의 자원을 공유하며 동시에 수행된다.
Context Switching란?
CPU는 여러 프로그램이 동시에 실행되는 것처럼 보이게 하기 위해 Task를 바꿔가며 실행한다.
이 때, 현재 진행 중인 Task(프로세스, 스레드)의 상태를 저장하고 다음 진행할 Task의 상태 값을 읽어 적용하는 과정을 Context-Switching이라고 한다.
CPU는 PCB(process control block)에 이전에 실행하던 Task의 정보를 담아서 스위칭이 일어났을 때 다시 이전 작업으로 돌아올 수 있도록 해준다.
이때, 독립적인 메모리 공간을 갖는 프로세스보다는 스택 영역만 따로 존재하고 모든 영역을 공유하는 스레드가 더 비용이 적다. 스택 영역만 변경하면 되기 때문이다.
정리
- 프로세스는 운영체제로부터 자원을 할당 받은 작업의 단위
- 운영체제 관점에서 최소 작업 단위
- 스레드는 프로세스 내에서 실행되는 흐름의 단위
- CPU 입장에서 최소 작업 단위
JVM은 하나의 프로세스라고 할 수 있다. 스레드는 스택 영역을 따로 가지며, 스태틱 영역과 힙 영역은 공유한다.
Q. JVM과 프로세스
JVM이란
Java Virtual Machine의 약자로, 자바 프로그램을 실행하기 위한 가상 컴퓨터 환경을 제공하는 소프트웨어다.
Java은 JVM을 사용해 모든 운영 환경에서 Java 프로그램을 실행할 수 있다. 즉, 가장 중요한 특징 중 하나인 “write once, run anywhere” 라는 원칙을 지원한다.
JVM은 두 가지의 주요 목적이 있다.
- JVM은 Java 프로그램이 어떤 환경에서도 실행될 수 있는 수단을 제공한다.
- JVM은 프로그램 메모리를 유지하고 최적화 한다.
JVM에서 프로세스와 스레드
Java 코드를 실행할 때마다 자체 JVM 프로세스가 시작된다. JVM은 독립된 자바 프로세스이다.
자바 스레드는 JVM에 의해 스케쥴링 되는 실행 단위 코드 블록이다.
출처: https://wooaoe.tistory.com/55 [개발개발 울었다:티스토리]
JVM에는 하나의 프로세스가 돌아가는가?
그렇다. 하나의 프로세스 내에서 하나의 JVM 인스턴스가 실행된다. 그리고 JVM은 Java 애플리케이션을 실행하는데 사용되는 가상 머신이다. 즉, 한 번에 여러 개의 프로세스를 동시에 실행할 수 없다.
JVM을 여러 개 실행할 수 있는가?
가능하다. 각 애플리케이션에 대해 별도의 JVM 프로세스를 시작할 수 있다. 이렇게 실행된 애플리케이션들은 서로 독립적으로 실행된다.
Q. JVM과 WAS
Web Server
웹 서버는 웹 브라우저와 같은 클라이언트로부터 HTTP 프로토콜을 기반으로 보내는 요청을 받아들이고, Image, CSS, JavaScript, HTML 문서와 같은 정적 콘텐츠를 반환하는 서버이다.
이 때, 웹 서버에게 동적 콘텐츠를 요청하면 WAS에게 해당 요청을 넘겨주고, WAS에서 처리한 결과를 클라이언트에게 전달하는 역할도 한다.
Apache Web Server, NginX 등이 있다.
WAS (Web Application Server)
웹 서버가 할 수 있는 기능 대부분을 처리할 수 있으며, 비즈니스 로직(서버 사이드 코드)을 처리할 수 있어 동적인 콘텐츠를 제공할 수 있다.
주로 데이터베이스 서버와 같이 수행되며, 동적인 데이터를 위주로 처리하는 서버이다.
JVM과 WAS
JVM은 Java 애플리케이션을 실행을 담당하는 가상 머신이다. 그러므로 자바 애플리케이션을 실행하기 위한 WAS에는 내부적으로 JVM이 내장되어 있다.
대표적인 예로는 Tomcat이 있다.
Q. Thread 클래스의 run() 메소드
runnable 인터페이스를 구현하고 있으므로, 속이 빈 run() 메소드를 구현해뒀다.
Q. Synchronized(this)의 의미
현재 객체(this)에 대한 잠금을 의미한다. synchronized method와 별반 다를 바가 없다고 한다.
Q. Thread.Stop() 메소드가 deprecated된 이유
Thread.Stop() 메소드는 스레드를 강제로 종료하는 메소드로, 스레드를 즉시 중단시킨다.
그런데, 이 메소드는 본질적으로 안전하지 않기 때문에 지원 중단되었다.
오라클 공식 문서에 따르면, 스레드를 중지하면서 해당 스레드가 잠근 모든 모니터를 잠금 해제한다. 이 때, 잠금되어 보호되던 객체 중 어떤 것이 일관성 없는 상태에 있다면 다른 스레드들은 앞으로 이 객체를 일관성 없는 상태로 보게 된다.
이러한 객체를 손상되었다고 표현한다.
이렇게 손상된 건 세밀하게 감지하기 어려울 수 있고, 손상이 발생한 후 한참 시간이 흘러 발견할 수도 있다.
즉, 갑작스럽게 작업을 중단하면서 작업이 완료되지 않는 상태에서 종료되어 데이터의 일관성이 깨지거나 손상될 수 있다는 말인 듯 하다.
Q. 멀티쓰레드 환경에서 어떤 map을 사용해야 하는가?
ConcurrentHashMap 을 사용하면 안전하게 사용할 수 있다고 한다.
- 동기화 매커니즘을 사용하여 Thread Safe한 HashMap
Map 중 Thread Safe한 것은 HashTable과 SynchronizedMap도 있는데, 이 둘은 map 전체에 lock을 걸기 때문에 성능 오버헤드를 발생시킨다.
따라서, map의 일부에만 lock을 거는 ConcurrentHashMap을 사용하는 것이 좋다.
SynchronizedMap의 문제
- 성능 이슈 모든 메소드에 대해 동기화를 제공하기 때문에, 여러 스레드가 동시에 맵에 접근하는 경우에도 한 번에 하나의 스레드만이 해당 메소드를 호출할 수 있다.
- 커스텀 동시성 제어의 어려움 내부에서 동기화를 수행하기 때문에 사용자가 세밀한 동시성 제어를 구현하기 어렵다.
참고 사이트
Java Virtual Machine: The Basics
What does "JVM processes" mean?
멀티 프로세싱(Multi-Processing)과 멀티 스레딩(Multi-Threading)
[운영체제] 컨텍스트 스위치(Context Switch)란?
Java Multi-Processing? (Java in General forum at Coderanch)
웹 서버와 WAS(Web Application Server) | 요즘IT
Java Thread Primitive Deprecation
[기술면접준비] 멀티스레드 상황에서 어떤 Map 구현체를 사용해야할까?
Collections.synchronizedMap vs. ConcurrentHashMap | Baeldung
