들어가기 전
『자바의 신 3판』 을 읽고 내용 정리 및 공부한 내용을 정리한 글입니다.
서적: 자바의 신 3판 구입처
내용 정리
Map이란?
자바에서의 Map은 키(key)와 값(value)으로 이루어져 있다. Map에서의 키는 다른 데이터와 구분하기 위한 값의 이름을 말한다.
예를 들어, 핸드폰 번호와 핸드폰 주인과의 관계를 살펴보자.
- 하나의 핸드폰 번호를 사용하는 사람은 한 사람뿐이다.
- 한 사람이 여러 대의 핸드폰을 보유하기도 한다.
자바의 Map에서는 핸드폰 번호가 키에 해당하고, 핸드폰 주인이 값에 해당한다. 즉, 자바의 Map은 키와 값이 1:1로 저장된다.
Key는 해당 Map에서 중복되지 않는다. 만약 키가 다르고, 값이 동일하다면 Map에서는 다른 것으로 간주한다.
Map의 특징
- 모든 데이터는 키와 값이 존재한다.
- 키가 없이 값만 저장될 수는 없다.
- 값 없이 키만 저장할 수도 없다.
- 키는 해당 Map에서 고유해야만 한다.
- 값은 Map에서 중복되어도 전혀 상관 없다.
Map 인터페이스
java.util 패키지의 Map이라는 이름의 인터페이스로 선언되어 있다.

Map 인터페이스의 메소드
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| V | put(K key, V value) | 첫 번째 매개 변수인 키를 갖는, 두 번째 매개변수인 값을 갖는 데이터를 저장한다. |
| void | putAll(Map<? extends k, ? extends V> m) | 매개 변수로 넘어온 Map의 모든 데이터를 저장한다. |
| V | get(Object key) | 매개 변수로 넘어온 키에 해당하는 값을 넘겨준다. |
| V | remove(Object key) | 매개 변수로 넘어온 키에 해당하는 값을 넘겨주며, 해당 키와 값은 Map에서 삭제한다. |
| Set<K> | keySet() | 키의 목록을 Set 타입으로 리턴한다. |
| Collection<V> | values() | 값의 목록을 Collection 타입으로 리턴한다 |
| Set<Map.Entry<K, V>> | entrySet() | Map 안에 Entry라는 타입의 Set을 리턴한다. |
| int | size() | Map의 크기를 리턴한다. |
| void | clear() | Map의 내용을 지운다. |
Map을 사용할 때 아래 메소드들은 꼭 기억해야 한다.
- Map에 데이터를 넣는 put()
- 데이터를 확인하는 get()
- 데이터를 삭제하는 remove()
Map을 구현한 주요 클래스
Map 인터페이스를 구현한 클래스들은 매우 다양하고 많다.
- HashMap, TreeMap, LinkedHashMap 등이 가장 유명하고, 개발자들이 애용하는 클래스다.
- Hashtable 클래스
Hashtable 클래스와 Map 인터페이스의 차이
Hashtable 클래스는 일반적인 Map 인터페이스를 구현한 클래스들과는 다르다.
| 기능 | Map | Hashtable |
|---|---|---|
| 데이터 처리 | 컬렉션 뷰(Collection view) | Enumeration 객체 |
| 데이터 순환 | 키, 값, 키-값 쌍 | 키-값 쌍 |
| 이터레이션을 처리하는 도중 안전한 데이터 삭제 | O | X |
Hashtable 클래스와 HashMap 클래스의 차이
| 기능 | HashMap | Hashtable |
|---|---|---|
| 키나 값에 null 저장 가능 여부 | 가능 | 불가능 |
| 여러 쓰레드 안전 여부 | 불가능 | 가능 |
이러한 차이가 발생한 이유는 Map 인터페이스보다 Hashtable이 먼저 나왔기 때문이다.
- Collection 인터페이스는 JDK 1.2부터 추가
- HashMap과 TreeMap이라는 클래스도 이 때 만들어졌다.
- Hashtable 클래스는 JDK 1.0부터 추가
- JDK 1.2 에서 Map 인터페이스의 기능 구현 (만들어진 Map에 맞추어 보완)
- LinkedHashMap 클래스는 JDK 1.4에서 추가
그런데, 이와 같이 버전에 따라서 언제 어떤 클래스가 만들어졌는가 보다는 각 클래스의 특징이 중요하다. 어떤 작업을 할 때 어떤 클래스가 더 유리한지를 알고 사용해야 한다.
Thread Safe하게 사용하기
Hashtable을 제외한 Map으로 끝나는 클래스들을 여러 쓰레드에서 동시에 접근하여 처리할 필요가 있을 때에는 다음과 같이 선언하여 사용해야만 한다.
Map m = Collections.synchronizedMap(new HashMap(...));- JDK 1.0부터 제공되는 Hashtable, Vector 클래스는 Thread Safe
- JDK 1.2부터 제공되는 대부분의 Collection 관련 클래스는 따로 위와 같은 처리를 해야 함
- 이름에 Concurrent가 포함되어 있으면 Thread Safe하게 사용할 수 있다.
- 예를 들어, java.util.concurrent 패키지의 ConcurrentHashMap, CopyOnWriteArrayList 등이 있다.
이러한 처리가 필요한 클래스의 API에는 반드시 관련된 설명이 제공되므로 API를 참고하는 습관을 들이도록 하자.
순서는 중요하지 않다.
자바의 자료 구조 중에서 저장 순서가 중요한 것은 List와 Queue 뿐이다.
Set과 Map은 데이터 추가 순서는 중요치 않다. Set은 데이터가 중복되지 않는 것이 중요하고, Map은 키가 중복되지 않는 것이 중요하다.
따라서, Set과 Map을 출력해보면 데이터를 저장한 순서대로 저장되지 않는 것을 확인할 수 있다.
HashMap 클래스
상속 관계

AbstractMap 이라는 추상 클래스를 확장했으며, 대부분의 주요 메소드는 AbstractMap 클래스가 구현해 놓았다.
구현한 인터페이스
| 인터페이스 | 용도 |
|---|---|
| Serializable | 원격으로 객체를 전송하거나, 파일에 저장할 수 있음을 지정 |
| Cloneable | Object 클래스의 clone() 메소드가 제대로 수행될 수 있음을 지정. 즉, 복제가 가능한 객체임을 의미한다. |
| Map<K,V> | 맵의 기본 메소드 지정 |
생성자
| 생성자 | 설명 |
|---|---|
| HashMap() | 16개의 저장 공간을 갖는 HashMap 객체를 생성한다. |
| HashMap(int initialCapacity) | 매개 변수만큼의 저장 공간을 갖는 HashMap 객체를 생성한다. |
| HashMap(int initialCapacity, float loadFactor) | 첫 매개 변수의 저장 공간을 갖고, 두 번째 매개 변수의 로드 팩터를 갖는 HashMap 객체를 생성한다. |
HashMap(Map<? extends K,? extends V> m) | 매개 변수로 넘어온 Map을 구현한 객체에 있는 데이터를 갖는 HashMap 객체를 생성한다. |
대부분 HashMap 객체를 생성할 때에는 매개 변수가 없는 생성자를 사용한다. 하지만, HashMap에 담을 데이터의 개수가 많은 경우에는 초기 크기를 지정해 주는 것을 권장한다.
HashMap의 키로 사용될 객체를 직접 만들 경우
HashMap의 키는 기본 자료형과 참조 자료형 모두 될 수 있다. 그래서 보통은 int나 long과 같은 숫자나 String 클래스를 키로 많이 사용한다.
하지만 직접 키로 사용할 클래스를 만들 경우, Object 클래스의 hashCode() 메소드와 equals() 메소드를 잘 구현해 놓아야만 한다.
HashMap에 객체가 들어가면, hashCode() 메소드의 결과 값에 따른 버켓(bucket)이라는 목록(list) 형태의 바구니가 만들어진다.
만약 서로 다른 키가 저장되었는데, hashCode() 메소드의 결과가 동일하다면, 이 버켓에 여러 개의 값이 들어갈 수 있다.
get() 메소드 호출 시, 아래와 같이 동작한다.
- hashCode()의 결과를 확인
- 버켓에 들어간 목록에 데이터가 하나일 경우: 반환
- 버켓에 들어간 목록에 데이터가 여러 개일 경우: equals() 메소드를 호출하여 동일한 값 탐색
따라서, 키가 되는 객체를 직접 작성할 때에는 hashCode()와 equals() 메소드를 꼭 구현해야 한다.
💡 참고 키워드: java map buckets
HashMap 의 주요 메소드
HashMap에 있는 주요 메소드는 대부분 Map 인터페이스에 정의되어 있다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| V | put(K key, V value) | 첫 번째 매개 변수인 키를 갖는, 두 번째 매개변수인 값을 갖는 데이터를 저장한다. 이미 존재하는 키로 값을 넣으면 기존의 값을 새로운 값으로 대치한다. |
| void | putAll(Map<? extends k, ? extends V> m) | 매개 변수로 넘어온 Map의 모든 데이터를 저장한다. |
| V | get(Object key) | 매개 변수로 넘어온 키에 해당하는 값을 넘겨준다. 존재하지 않는 키일 시 null을 리턴한다. |
키 목록과 값 목록을 얻는 메소드
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| Set<K> | keySet() | 키의 목록을 Set 타입으로 리턴한다. |
| Collection<V> | values() | 값의 목록을 Collection 타입으로 리턴한다 |
| Set<Map.Entry<K, V>> | entrySet() | Map 안에 Entry라는 타입의 Set을 리턴한다. |
entrySet() 메소드는 Map에 선언된 Entry라는 타입의 객체를 리턴한다.
- Entry에는 단 하나의 키와 값만이 저장된다.
getKey()와getValues()메소드로 키와 값을 간단하게 가져올 수 있다.
public void checkHashMapEntry() {
HashMap<String,String> map=new HashMap<String,String>();
map.put("A", "a");
// ...
Set<Map.Entry<String,String>> entries = map.entrySet();
for(Map.Entry<String,String> tempEntry : entries) {
System.out.println(tempEntry.getKey() + "=" + tempEntry.getValue());
}
}Map에 어떤 키나 값이 존재하는지 확인
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| boolean | containsKey() | 매개 변수로 넘긴 키가 존재하는지 여부를 반환한다. |
| boolean | containsValue() | 매개 변수로 넘긴 값이 존재하는지 여부를 반환한다. |
데이터를 삭제하는 메소드
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| V | remove(Object key) | 매개 변수로 넘어온 키에 해당하는 값을 넘겨주며, 해당 키와 값은 Map에서 삭제한다. |
TreeMap 이란
HashMap 객체의 키를 정렬하는 방법
가장 간단한 방법 중 하나가 부록 13에서 살펴볼 Arrays라는 클래스를 사용하는 것이다.
하지만, 불필요한 객체가 생긴다는 단점이 있다.
단점을 보완한 TreeMap 클래스
이러한 단점을 보완하는 TreeMap이라는 클래스가 있다. TreeMap은 키를 정렬하여 저장한다.
- 정렬되는 기본적인 순서: “숫자 > 알파벳 대문자 > 알파벳 소문자 > 한글” 순
- 이 순서는 String과 같은 문자열이 저장되는 순서를 말한다.
- 객체가 저장되거나, 숫자가 저장될 때에는 그 순서가 달라진다.
SortedMap 인터페이스
SortedMap을 구현한 클래스들은 모두 키가 정렬되어 있어야만 한다. 그리고 TreeMap은 SortedMap 인터페이스를 구현했다.
키를 정렬하는 것의 장단점
장점
- 가장 앞에 있는 키(firstKey())
- 가장 뒤에 있는 키(lastKey())
- 특정 키 뒤에 있는 키(higherKey())
위 키들을 알 수 있는 메소드를 제공해 준다. 이러한 기능들은 키를 검색하는 프로그램을 작성할 때 매우 도움이 된다.
단점
키가 정렬되기 때문에, 매우 많은 데이터를 보관하여 처리할 때 속도가 느려진다.
- TreeMap에 매우 많은 데이터를 삽입하면 HashMap보다는 느릴 것이다.
- 100건, 1000건 정도의 데이터를 처리하고, 정렬을 해야 할 필요가 있다면 HashMap보다는 TreeMap을 사용하는 것이 더 유리하다.
Map을 구현한 Properties 클래스
Properties 클래스는 Hashtable을 확장(extends)했으므로, Map 인터페이스에서 제공하는 모든 메소드를 사용할 수 있다.
자바에서는 기본적으로 시스템의 속성을 이 클래스를 사용하여 제공한다.
시스템의 속성값을 확인하는 방법
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| static Properties | getProperties() | 시스템의 속성값들을 Properties 타입의 객체로 리턴한다. |
시스템에서 제공하는 여러 속성
시스템에서 제공하는 여러 속성 중에서 자주 사용할 속성은 다음과 같다.
| 속성 | 설명 |
|---|---|
| user.language | 사용자의 사용 언어 |
| user.dir | 현재 사용중인 기본 디렉터리 |
| user.home | 사용자 계정의 홈 티렉터리 |
| java.io.tmpdir | 자바에서 사용하는 임시 디렉터리 |
| file.encoding | 파일의 기본 인코딩 |
| sun.io.unicode.encoding | 유니코드 인코딩 |
| path.separator | 경로 구분자 |
| file.separator | 파일 구분자 |
| line.separator | 줄(line) 구분자 |
디렉터리나 파일과 관련된 값들은 대부분 IO 관련 클래스의 상수로 정해져 있다.
가장 좋은 방법은 그 상수들을 사용하는 것이지만, 위 메소드를 사용하면 간단하고 빠르게 시스템의 속성을 확인할 수 있다.
Properties 클래스를 사용하는 이유
Properties 클래스를 이용하는 주된 이유는 클래스가 제공하는 메소드들 때문이다.
여기서 comment라고 되어 있는 매개 변수들은 저장되는 속성 파일에 주석으로 저장된다.
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| void | load(InputStream inStream) | 파일에서 속성을 읽는다. |
| void | load(Reader reader) | |
| void | loadFromXML(InputStream in) | XML로 되어 있는 속성을 읽는다. |
| void | store(OutputStream out, String comments) | 파일에 속성을 저장한다. |
| void | store(Writer writer, String comments) | |
| void | storeToXML(OutputStream os, String comment) | XML로 구성되는 속성 파일을 생성한다. |
| void | storeToXML(OutputStream os, String comment, String encoding) |
💡 XML이란
eXtensible Markup Language에서 XML을 따온 약어다.
태그로 구성되어 있는 텍스트 문서를 의미한다. 이러한 XML은 서로 데이터를 주고 받을 때 표준을 정하기가 쉽다.
Properties 객체에 속성값 넣기
Properties 객체에는 아래 속성들이 들어갈 수 있다.
- 시스템 속성
- 애플리케이션에서 사용할 여러 속성 값 (개발자가 삽입)
파일을 읽고 쓸 때 Properties 클래스를 사용하면 저장과 읽기가 한 줄에 끝난다. 만약 이 클래스가 없다면, 직접 파일을 읽고 쓰는 메소드를 만들어야만 한다.
저장한 파일은 시스템 속성 중 “user.dir”에 지정되어 있는 경로에 저장된다
| 리턴 타입 | 메소드 이름 및 매개 변수 | 설명 |
|---|---|---|
| Object | setProperty(String key, String value) | Hashtable의 put() 메소드 호출 |
| void | store(OutputStream out, String comments) | 파일로 저장 |
| void | storeToXML(OutputStream os, String comment) | XML 형식 파일로 저장 |
| void | load(InputStream inStream) | 파일을 읽어오기 |
| void | loadFromXML(InputStream in) | XML 형식 파일을 읽어오기 |
.properties 파일로 저장
- 가장 왼쪽에 #으로 시작하는 줄은 주석으로 간주된다.
- stroe() 메소드를 사용할 때 지정한 주석이 여기(가장 첫 줄)에 저장된다.
- 그 다음 줄에는 해당 파일이 생성된 날짜가 자동으로 찍힌다.
- 키는 왼쪽에, 값은 오른쪽에 표시하고 그 사이에 등호(=)를 넣어 키와 값을 분리한다.
- key=value
XML 파일로 저장
- <properties> 태그 내부를 보면 된다.
- 저장할 때 사용한 주석은 <comments>라는 태그 내에 저장된다.
- 각 키와 값으로 선언되어 있는 값들은 <entry>라는 태그 내에 선언되어 있다.
자료 구조 요약 정리
자료 구조
- Collection을 구현한 List
- 배열처럼 목록을 처리하기 위한 자료구조
- 대표 클래스: ArrayList, LinkedList
- 보통 ArrayList를 많이 사용
- Collection을 구현한 Set
- List와 같은 목록형 자료구조
- 데이터의 중복이 없고 순서가 필요 없음
- 대표 클래스: HashSet, TreeSet, LinkedHashSet
- Collection을 구현한 Queue
- 데이터를 들어온 순서대로 처리하기 위해 사용
- 대표 클래스: LinkedList, PriorityQueue
- 별도의 인터페이스인 Map
- 대표 클래스: HashMap, TreeMap, LinkedHashMap
- 대부분 HashMap을 많이 사용.
자료 구조의 데이터 처리
- Collection의 데이터를 처리 시 방법
- for 루프
- iterator() 메소드로 Iterator 객체를 얻어 각 데이터를 처리
- Map의 데이터 얻기
- “키” 목록은 keySet() 메소드 사용
- “값” 목록은 values() 메소드 사용
정리해 봅시다.
Q. Map 형태의 자료구조는 무엇과 무엇으로 구성되어 있나요?
Me: 키와 값
Q. Map에서 데이터를 저장하는 메소드는 무엇인가요?
Me: put() 메소드
Q. Map에서 특정 키에 할당된 값을 가져오는 메소드는 무엇인가요?
Me: get() 메소드
Q. Map에서 특정 키와 관련된 키와 데이터를 지우는 메소드는 무엇인가요?
Me: remove() 메소드
Q. Map에서 키의 목록을 가져오는 메소드는 무엇인가요?
Me: keySet()
Q. Map에 저장되어 있는 데이터의 크기를 가져오는 메소드는 무엇인가요?
Me: size()
Q. HashMap과 Hashtable 중에서 키나 값에 null을 저장할 수 있는 것은 무엇인가요?
Me: HashMap
Q. HashMap과 Hashtable 중에서 여러 쓰레드에서 동시에 접근해도 문제가 없는 것은 무엇인가요?
Me: Hashtable
Q. HashMap에서 특정 키가 존재하는지 확인하는 메소드는 무엇인가요?
Me: containsKey()
Q. 이 장에서 살펴본 클래스 중, 키가 저장되면서 정렬되는 Map에는 어떤 것이 있나요?
Me: TreeMap
Q. Properties 클래스는 어떤 클래스를 확장한 것인가요?
Me: Hashtable 클래스
Q. Properties 클래스의 객체에 있는 데이터를 파일로 저장할 때에는 어떤 메소드들을 사용하면 되나요?
Me: setProperties() 메소드로 키-값을 넣고, store() 메소드로 저장한다.
질문
💡 책에 있는 내용이 아닙니다.
책을 읽으며 설명이 더 필요하거나, 추가로 궁금한 점에 대해 질문 형식으로 작성 후, 답을 구해보고 있습니다.
참고한 사이트나 영상은 [출처]로 달아두었으며, 오류 지적은 언제나 환영합니다.
Q. Entry 타입은 무엇인가?
Map 인터페이스에서 사용되는 키-값 쌍을 나타내는 Entry 인터페이스가 있다. 이는 Map 인터페이스의 구현체들이 내부에서 키와 값을 묶어서 관리할 때 사용된다.
Map.Entry 인터페이스
다음과 같이 정의되어 있다.
public interface Map.Entry<K, V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object obj);
int hashCode();
}getKey(): 현재 엔트리의 키를 반환getValue(): 현재 엔트리의 값을 반환setValue(V value): 현재 엔트리의 값을 주어진 값으로 설정하고, 이전 값을 반환equals(Object obj): 지정된 객체와 현재 엔트리를 비교하여 동등한지 여부를 반환hashCode(): 현재 엔트리의 해시 코드를 반환
HashMap의 Entry
HashMap에서 키-값 쌍의 데이터를 저장하면, 이 키-값 쌍은 Entry 클래스의 객체에 저장된다.
Entry 클래스는 HashMap의 static nested 클래스이며, 아래와 같이 정의된다.
static class Entry<K,V> implements Map.Entry<K,V>
{
final K key;
V value;
Entry<K,V> next;
int hash;
//Some methods are defined here
}- Key: 요소의 키를 저장한다. 그리고 이 값은 불변이다.
- value: 요소의 값을 저장한다.
- next: 다음 키-값 쌍에 대한 포인터를 저장한다. 이 속성은 키-값 쌍을 연결 리스트로 저장한다.
- hash: 키의 해시코드를 저장한다.
HashMap에서 저장 시 동작
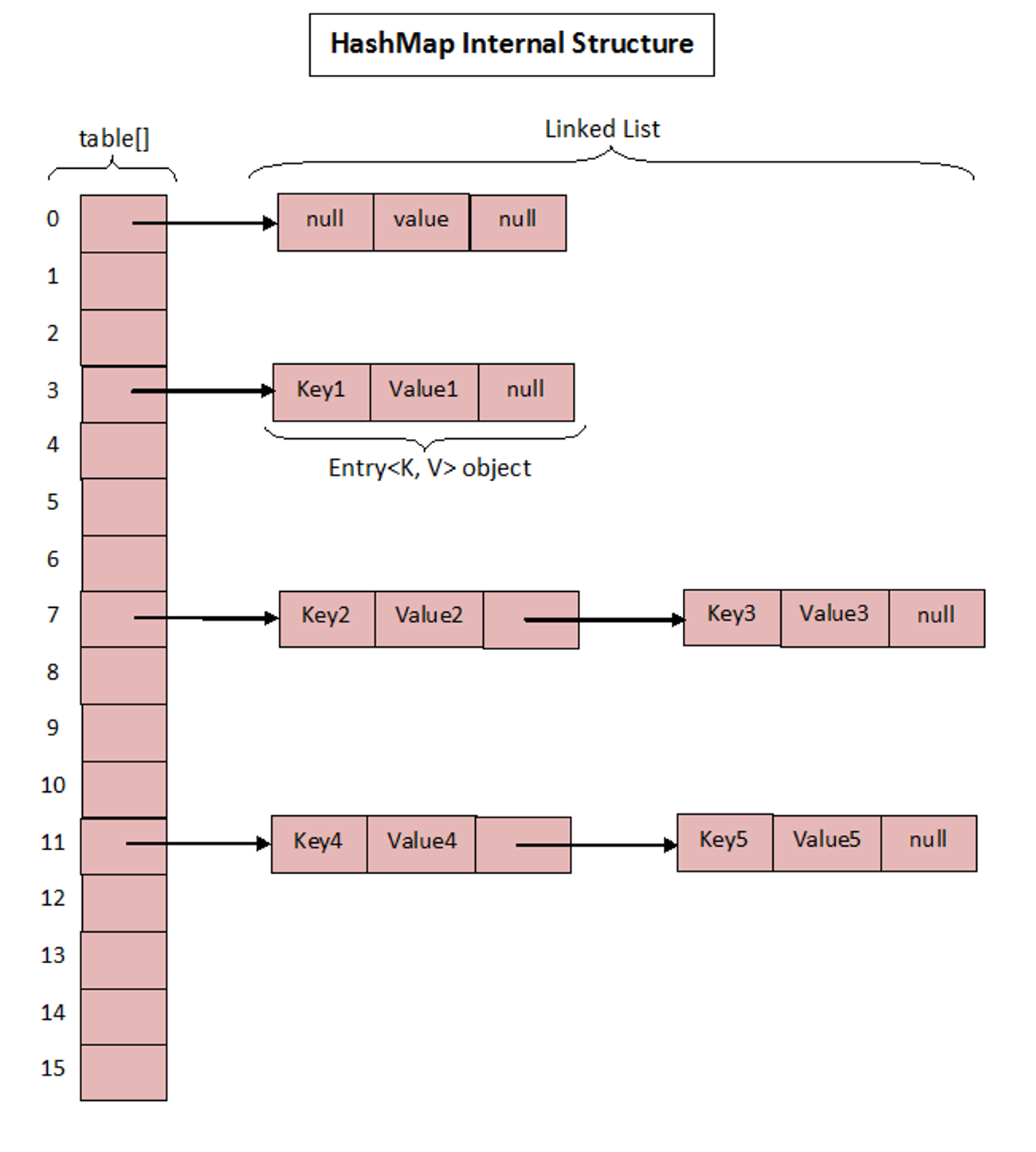
즉, HashMap에 키-값 쌍의 데이터를 저장하면 Entry 클래스의 객체로 저장된다. 이 클래스에는 다음 키-값 쌍에 대한 포인터를 보유한 next라는 속성이 있으므로, 키-값 쌍은 연결 리스트로 저장된다.
그리고 각 Entry 객체는 table[] 이라는 배열에 저장된다.
💡 아래는 참고 사이트에서 가져온 그림이다.
참고로, null의 해시 코드는 0이므로 table[0]은 항상 key가 null일 경우 저장된다.
Q. HashMap과 HashSet
물론 Map과 Set의 차이가 있지만, 둘 다 해시 알고리즘을 사용하므로 비교해 봤다.
아래 표는 아래 ‘참고 사이트’에 기재한 사이트에서 참고했다.
| 구분 | HashMap | HashSet |
|---|---|---|
| 정의 | Map 인터페이스의 해시 테이블 기반 구현체 | Set 인터페이스의 구현체 |
| 데이터 | 키-값 쌍을 저장 | 객체를 저장 |
| 저장 방식 | 내부적으로 해싱 사용 | 내부적으로 해시 테이블을 사용하는 컬렉션(HashMap) 사용 |
| 중복값 허용 | 중복 키는 불가능, 중복 값은 허용 | 중복 값 불가능 |
| Null 허용 | Null인 키 혹은 값 허용 | Null 값 허용 |
| 요소 삽입 메소드 | put() 메소드 | add() 메소드 |
| 성능 | 키로 값을 매핑하기 때문에, HashSet보다 빠르다. | 중복 검사를 해야 하기 때문에 HashMap보다 느리다. |
Q. Hashtable에서 null인 키와 값을 허용하지 않는 이유는 무엇인가?
Hashtable은 키-값에 null을 허용하지 않지만, HashMap은 null을 허용하고 있다. 그러나, ConcurrentHashMap도 키-값에 null을 허용하지 않는다.
이러한 이유에 대해서는 아래와 같은 이유가 있는 것 같다.
- Hashtable은 Java 1.0에 추가된 클래스이다. 즉, 처음에는 키가 null일 경우의 유용성을 알지 못해 그렇게 설계한 걸 수 있다.
- 많은 해시 함수는 입력이 null이 아니라고 가정하기 때문에, 키를 null로 넣으면 해시 함수에 따라 예측할 수 없는 동작이 일어날 수 있다.
- 멀티스레드 환경에서 사용될 경우, null을 허용할 경우 문제가 발생할 수 있다.
- map에 null인 키나 값을 넣고 get() 메소드로 조회할 때, 다른 스레드가 접근해 해당 키를 제거하면, 제거된 것인지 원래 null인 것인지 구별할 수 없다.
이러한 관점에서, HashMap에서 키-값에 null을 허용하는 건 아래 이유에서 이다.
- 키가 null일 경우가 필요해서 추가되었다.
- HashMap은 단일 스레드에 의해 호출 될 것이므로, 검색 도중 키가 제거될 가능성은 없다. 따라서 null을 허용할 수 있다.
- 일반적으로 null의 해시 코드는 0으로 정의된다.
Q. Collection View란?
컬렉션 뷰(Collection View)는 컬렉션 프레임워크에서 사용되는 개념으로, 컬렉션의 일부 요소나 전체 요소에 접근하고 조작할 수 있도록 제공하는 것을 말한다.
즉, 각 컬렉션에 접근해서 조회하고 수정할 수 있도록 제공하는 클래스나 인터페이스를 말하는 것 같다.
컬렉션 뷰의 종류는 다음과 같다.
- Set View
- Set 인터페이스를 구현한 컬렉션은 Set의 메소드를 사용해 뷰를 생성할 수 있다.
- List View
- List 인터페이스를 구현한 컬렉션은 List의 메소드를 사용해 뷰를 생성할 수 있다.
- Map View
- Map 인터페이스를 구현한 컬렉션은 Map의 메소드를 사용해 뷰를 생성할 수 있다.
- 예를 들어, Map의 entrySet() 메서드로 Map의 모든 엔트리에 접근할 수 있다.
Q. Enumeration에 대한 설명
23장의 ‘Iterator와 Enumeration의 차이’ 를 참고.
Q. HashMap과 Bucket
HashMap은 해시 테이블 기반 구현체이다. 다시 말해, 해시 테이블을 사용해 데이터를 저장하고 관리한다.
해시 테이블은 해시 함수를 통해 각 키를 특정 위치(bucket)에 매핑하여, 데이터를 저장하고 검색하는 자료 구조이다.
Bucket과 Slot
동작을 설명하기 앞서, 먼저 개념을 짚고 가자.
- 버킷(Bucket): 해시 테이블의 각 위치를 가리키는 용어다.
- 해시 테이블은 여러 버킷으로 나뉘어져 있다.
- 각 버킷에는 특정 해시 코드에 해당하는 데이터가 저장된다.
- 이 위치에는 하나 이상의 항목이 저장될 수 있다.
- 슬롯(Slot): 주로 충돌이 발생했을 때 사용되는 용어다.
- 충돌이 발생했을 때, 동일한 해시 코드를 갖는 여러 키들은 동일한 버킷에 매핑된다.
- 각각의 데이터는 해당 버킷 내에서 별도의 위치(슬롯)에 저장된다.
- 즉, 슬롯은 버킷 내에서의 상대적인 위치를 나타낸다.
- 슬롯에는 하나의 데이터가 저장된다.
저장 시 동작
- 키-값 쌍의 데이터를 put() 메소드로 넣으면, 먼저 해시 함수를 사용해 키의 해시 코드를 얻는다.
- 키의 해시 코드를 위치로 갖는 Bucket에 키-값 쌍의 데이터(Entry)를 저장한다.
- 이 때, 해시 충돌이 발생하면 동일한 Bucket에 데이터를 이어 삽입한다.
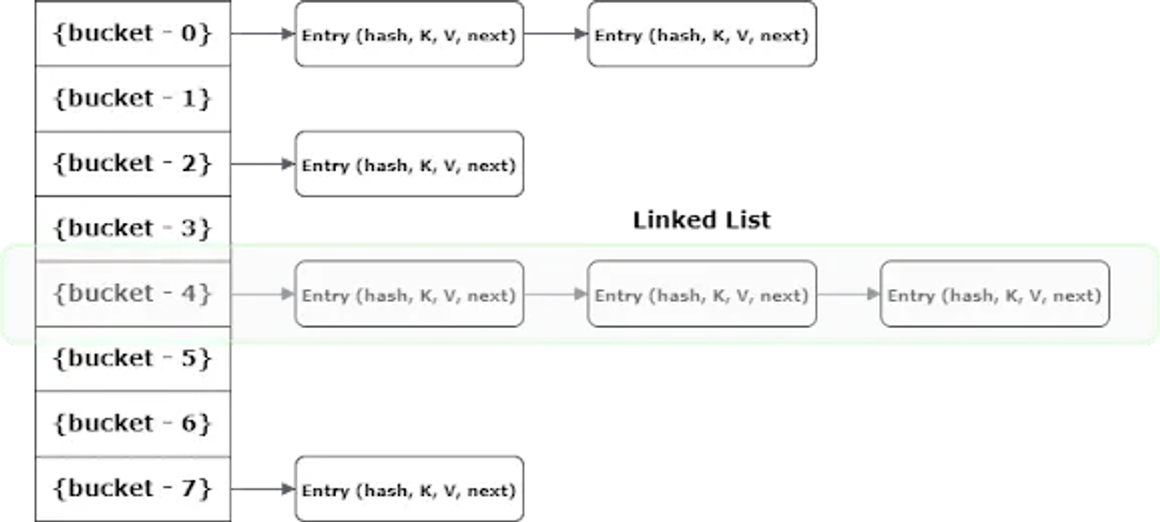
Bucket은 연결 리스트로 되어 있기 때문에, 아래 그림처럼 들어가게 된다.
💡 참고 사이트에서 가져온 그림
내부 구조 변경
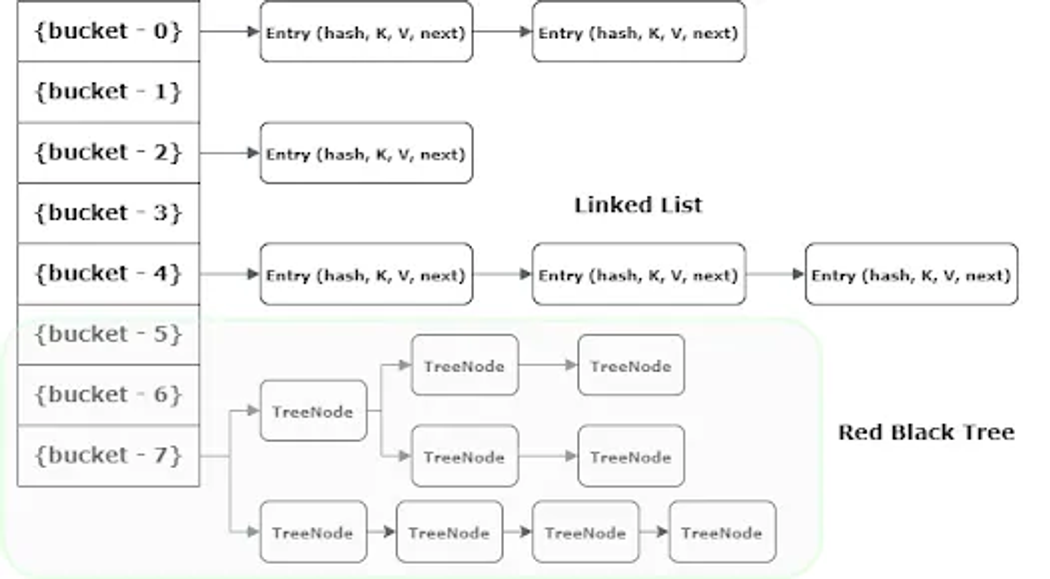
Java 8 이상에서는 단일 Bucket의 Entry가 임계값(TREEIFY_THRESHOLD, 기본값 8)을 넘어서면 연결 리스트에서 Red-Black 트리로 내부 구조를 변환한다고 한다.
이 때, Entry는 TreeNode로 변환된다.
이는 검색 성능을 향상 시키기 위해, O(n)의 시간 복잡도를 갖는 선형 검색을 하는 연결 리스트 대신 O(log n)의 시간 복잡도를 갖는 Red-Black 트리로 변환하는 것이다.
다만 TreeNode는 Entry보다 더 많은 메모릴 사용하므로, Bucket의 TreeNode가 임계값 미만으로 줄어들면 연결 리스트로 다시 변환된다.
💡 참고 사이트에서 가져온 그림
Q. HTML과 XML
책에서는 HTMK이 XML의 일종이라고 설명했다. 하지만, 둘은 마크업 언어라는 프로그래밍 언어 계열에 속할 뿐 다른 언어이다.
HTML은 주로 애플리케이션의 UI를 개발하는데 사용되고, XML은 주로 데이터 교환 및 전송에 사용된다.
마크업 언어
위키백과에 적힌 설명에 따르면,
태그 등을 이용해 문서나 데이터의 구조를 명기하는 언어의 한 가지이다.
HTML과 XML 외에도 LaTeX, SVG, Markdown, SGML 등이 있다.
Q. HashMap vs DTO
HashMap과 DTO 중 어떤 것을 사용하면 좋을 지에 대한 이야기는 항상 나온다. 상황에 따라 다르겠지만, 특히 API와 같이 데이터를 전송할 경우에는 DTO를 사용하는 것이 좋다.
Map을 사용하는 이유
그럼에도 Map을 선호하는 사람들은 있다. 그 이유는 아래 이유에서 기인한다고 생각한다.
- Map은 매번 클래스를 생성하지 않아도 되므로 생산성이 좋다.
- 특히 요구사항을 빠르게 처리해줘야 하는 경우, DTO 클래스를 만드는 시간을 줄이고 바로 Map으로 데이터 처리하는 게 속도가 빠르다.
- 동적으로 필드를 추가하거나 제거할 수 있어서 유연하다.
Map의 단점
하지만, Map에는 아래 문제들이 있다.
- (컴파일 시) 타입 안전성을 보장하지 않는다.
- 컴파일 시 없는 Key로 조회했을 경우를 잡지 못한다. 즉, key를 잘못 쳐서 오타를 내면 런타임에 오류가 발생한다.
- 값을 가져올 때 형 변환을 해줘야 한다. 이 때, 잘못 형 변환을 했을 경우 런타임에 오류가 발생한다.
- 값을 가져올 때 형 변환을 하면서 추가적인 오버헤드가 발생한다.
- 가독성이 좋지 않다.
- 키와 값만으로 데이터를 표현하므로 의미 파악이 어렵다.
- 어떤 Key에 어떤 Value가 들어갔는 지를 한 눈에 확인하기 어렵다. 특히 여러 클래스에서 같은 Map 변수를 사용한다면, 그 모든 클래스를 전부 확인해야 하는 것이다.
- 유지보수성이 좋지 않다.
- 가독성이 좋지 않기 때문이다.
DTO를 사용하는 이유
DTO는 객체지향적이며, 컴파일 시 오류 체크가 가능하다.
- 타입 안전성을 보장한다.
- DTO 클래스에서 필드에 대한 유효성 검증 로직을 추가하여, 잘못된 데이터의 전송을 방지할 수 있다.
- 가독성이 좋다.
- DTO는 데이터의 의미와 타입이 명확하게 정의되어 있다.
- 명시적인 인터페이스 제공
- DTO는 특정 데이터 구조와 인터페이스를 명시적으로 정의한다. 따라서, 필요한 데이터만을 제공할 수 있다.
- JSON 또는 XML 변환
- DTO는 일반적으로 JSON이나 XML과 같은 형식으로 변환하기 쉽다.
- 따라서, 웹 API 같은 환경에서 데이터를 주고받을 때 유용하다.
DTO의 단점
- 초기에 필드를 정의하고 값을 할당하는 등의 작업이 필요하므로 번거롭다.
- 모든 요청/응답마다 클래스를 생성하면 수가 너무 많아지므로 고민이 필요하다.
- 비즈니스 로직이 변경되면 DTO도 함께 수정해야 한다.
결론
Map은 생산성이빠르고 편리하다는 이유로 많이 사용하지만, 런타입 오류 발생 가능성과 유지보수성을 생각하면 DTO를 선택하는 것이 좋다.
참고 사이트
Hashing and its Use Cases in Java - Scaler Topics
What exactly is bucket in hashmap?
How does a Java HashMap handle different objects with the same hash code?
Why Hashtable does not allow null keys or values?
How HashMap Works Internally In Java?
How HashMap internally works in Java 8?
XML과 HTML 비교 - 마크업 언어 간의 차이점 - AWS
스프링 api 메세지 수신시 map dto 뭐가 좋을까요? 어떤상황에 map , dto 를 선택해서 사용해야 할까요? - 인프런
