들어가기 전
『자바의 신 3판』 을 읽고 내용 정리 및 공부한 내용을 정리한 글입니다.
서적: 자바의 신 3판 구입처
내용 정리
I/O 란
I/O는 프로그램에 있는 어떤 내용을
- 파일에 읽거나 저장할 일이 있을 때
- 다른 서버나 디바이스로 보낼 일이 있을 때
사용한다.
I는 Input, O는 Output의 약자로, 입출력을 통칭하는 용어이다. JVM을 기준으로, 읽을 때는 Input 파일로 쓰거나 외부로 전송할 때는 Ouput이라는 용어를 사용한다.
Stream 기반 클래스
초기의 자바에서는 java.io 패키지에 있는 클래스만을 제공했다. 이 패키지에서는 바이트 기반의 데이터를 처리하기 위해서 여러 종류의 Stream 이라는 클래스를 제공한다.
- 읽는 작업은 InputStream
- 쓰는 작업은 OutputStream
바이트가 아닌, char 기반의 문자열로만 되어 있는 파일은 Reader와 Writer라는 클래스로 처리한다.
- 읽는 작업은 Reader
- 쓰는 작업은 Writer
💡 Stream이란?
”개천, 줄기”라는 뜻으로, 끊기지 않고 연속적인 데이터를 말한다. 참고로, Java8에서 도입된 스트림과는 별개의 것이다.
검색 키워드: What is the difference between java streams and io streams?
NIO
JDK 1.4부터는 보다 빠른 I/O를 처리하기 위해서 NIO(New I/O)라는 것이 추가되었다. NIO는 스트림 기반이 아니라, Buffer와 Channel 기반으로 데이터를 처리한다.
이 책에서는 NIO에 대해서 간단하게 어떤 클래스가 있는지, 어떻게 동작하는 지에 대해 살펴본다.
Java 7에서는 NIO2라는 것이 추가되었다. 파일을 보다 효율적으로 처리하기 위해서 만들어졌으며, 기존에 있는 여러 단점들을 보완하고 있다. 이에 대한 자세한 내용은 31장에서 다룬다.
File과 Files 클래스
File 클래스
java.io 패키지에 있는 클래스로, 파일 및 경로 정보를 통제하기 위한 클래스다.
File 클래스는 아래와 같은 이유로, Java 7부터는 java.nio.file 패키지에 있는 Files 클래스에서 File 클래스에 있는 메소드들을 대체하여 제공한다.
- 정체가 불분명 하다.
- 심볼릭 링크와 같은 유닉스 계열의 파일에서 사용하는 몇몇 기능을 제대로 제공하지 못한다.
File 클래스의 기능
생성한 파일 객체가 가리키고 있는 것이
- 존재하는지
- 파일인지 경로인지
- 읽거나, 쓰거나, 실행할 수 있는지
- 언제 수정되었는지
를 확인하는 기능과 해당 파일의
- 이름을 바꾸고
- 삭제하고
- 생성하고
- 전체 경로를 확인
하는 등의 기능을 제공한다.
이 외에 File 객체가 가리키는 것이 파일이 아닌 경로일 경우에는 해당 경로에 있는
- 파일의 목록을 가져오거나
- 경로를 생성하고
- 경로를 삭제하는
등의 기능도 있다.
생성자
생성자 | 설명 |
|---|---|
| File(File parent, String child) | 이미 생성되어 있는 File 객체(parent)와 그 경로의 하위 경로 이름으로 새로운 File 객체를 생성한다. |
| File(String pathname) | 지정한 경로 이름으로 File 객체를 생성한다. |
| File(String parent, String child) | 상위 경로(parent)와 하위 경로(child)로 File 객체를 생성한다. |
| File(URI uri) | URI에 따른 File 객체를 생성한다. |
- child는 경로 혹은 파일 이름이다.
- pathname에 전체 경로와 파일이름이 지정되어 있을 경우, 파일을 가리키는 File 객체가 된다.
- URI는 Uniform Resource Identifier의 약자로, 어떠한 리소스를 가리키기 위한 경로를 뜻한다.
- 자세한 설명은 java.net.URI 클래스의 API를 참고할 것
파일의 경로
OS 별로 각 디렉터리를 구분하는 기호는 다르다.
- 유닉스 계열: 슬래시(/)로 구분
- 윈도우 : 역슬래시()로 구분
이렇게 OS에 따라 구분 기호가 달라지는 모호함을 없애기 위해 File 클래스에서는 separator 라는 static 변수를 제공한다.
따라서, Java 에서는 아래와 같이 경로를 지정한다.
// 유닉스 계열
String pathName = "/godOfJava/test";
// 윈도우
String pathName = "C:\\godOfJava\\test";
// File 클래스에서 제공하는 변수 사용
Strign pathname = File.separator + "godOfJava" + File.separator + "test";자바에서는 역슬래시는 그 뒤에 있는 단어에 따라 미리 약속한 특수한 기호로 인식하기 때문에, 역슬래시를 나타내기 위해서는 두 개의 역슬래시를 연달아 사용해야 한다.
💡 Escape Character
보통 역슬래시()로 시작하는 특수한 목적을 가진 문자이다. 역슬래시 뒤에 나오는 문자와 함께 사용되어, 특별한 의미를 부여하거나 특정 동작을 수행한다.
ex) 줄바꿈 문자인 \n 혹은 탭을 뜻하는 \t
파일의 정보 확인
파일을 생성하기에 앞서 해당 디렉터리와 파일이 존재하는지 확인해야 한다.
File 객체의 정보를 확인할 수 있는 메소드들은 아래와 같다.
| 반환값 | 메소드 | 설명 |
|---|---|---|
| boolean | exists() | 파일의 경로가 존재하면 true, 존재하지 않으면 false를 반환한다. |
| boolean | isFile() | File 객체가 파일을 나타내는지 알 수 있다. |
| boolean | isDerectory() | File 객체가 디렉터리를 나타내는지 알 수 있다. |
| boolean | isHidden() | 숨겨진 파일인지 여부를 반환한다. |
다음과 같이 현재 수행하고 있는 자바 프로그램이 현재 File 객체의 권한이 있는지도 확인할 수 있다.
| 반환값 | 메소드 | 설명 |
|---|---|---|
| boolean | canRead() | 해당 File 객체에 읽을 수 있는 권한이 있는지 확인 |
| boolean | canWrite() | 해당 File 객체에 쓸 수 있는 권한이 있는지 확인 |
| boolean | canExeute() | 해당 File 객체에 실행 수 있는 권한이 있는지 확인 (Java6부터 추가) |
파일이나 경로가 언제 생성되었는지 확인하는 메소드는 lastModified() 다. long 타입의 현재 시간을 리턴해주기 때문에, [java.util.Date](http://java.util.Date) 클래스를 사용하여 시간을 확인해야 한다.
| 반환값 | 메소드 | 설명 |
|---|---|---|
| Long | lastModified() | 파일이나 경로가 언제 생성되었는지 확인 후, Long 타입의 현재 시간을 리턴한다. |
파일의 경로 출력
| 반환값 | 메소드 | 설명 |
|---|---|---|
| String | getAbsolutePath() | 절대 경로를 반환한다. |
| File | getAbsoluteFile() | 절대 경로를 반환한다. |
| String | getCanonicalPath() | 절대적이고 유일한 경로를 반환한다. |
| File | getCanonicalFile() | 절대적이고 유일한 경로를 반환한다. |
| String | getParent() | 파일 이름을 제외한 경로만을 반환한다. |
Absolute와 Canonical는 File 객체의 경로가 상대 경로일 경우 결과가 달라진다.
- “C:\godOfJava\a” 에서 자바를 실행 후, “..\b” 로 “C:\godOfJava\b” 디렉터리로 이동했을 경우
- Absolute: “C:\godOfJava\a..\b”
- Canonical: “C:\godOfJava\b”
파일의 삭제
| 반환값 | 메소드 | 설명 |
|---|---|---|
| boolean | delete() | 파일을 삭제한다. |
디렉터리 생성
이 메소드들을 사용하기 전에, 해당 경로가 존재하는지 여부를 먼저 검사해야 한다.
| 반환값 | 메소드 | 설명 |
|---|---|---|
| boolean | mkdir() | 파일의 경로에서 존재하지 않는 하나의 디렉터리를 생성한다. |
| boolean | mkdirs() | 파일의 경로에서 존재하지 않는 여러 개의 하위 디렉터리를 생성한다. |
파일의 생성
| 반환값 | 메소드 | 설명 |
|---|---|---|
| boolean | createNewFile() | 파일을 생성한다. 경로에 동일한 이름의 파일이 있을 경우 false를 반환한다. |
이 메소드는 IOException을 던지기 때문에, 아래와 같이 try-catch 문으로 묶어주어야 한다.
public void newFile() {
String pathName = File.separator + "godOfJava" + File.separator + "test";
String fileName = "test.txt";
File file = new File(pathName, fileName);
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace()
}
}디렉터리의 목록 확인
반환값 | 메소드 | 설명 |
|---|---|---|
| static File[] | listRoots() | JVM이 수행되는 OS에서 사용중인 파일 시스템의 Root 디렉터리 목록을 File 배열로 리턴한다. |
| String[] | list() | 현재 디렉터리의 하위에 있는 목록을 String 배열로 리턴한다. |
| String[] | list(FilenameFileter filter) | 현재 디렉터리의 하위에 있는 목록 중, 매개 변수로 넘어온 filter의 조건에 맞는 목록을 String 배열로 리턴한다. |
| File[] | listFiles() | 현재 디렉터리의 하위에 있는 목록을 File 배열로 리턴한다. |
| File[] | listFiles(FileFilter filter) | 현재 디렉터리의 하위에 있는 목록 중, 매개 변수로 넘어온 filter의 조건에 맞는 목록을 File 배열로 리턴한다. |
| File[] | listFiles(FilenameFilter filter) | 현재 디렉터리의 하위에 있는 목록 중, 매개 변수로 넘어온 filter의 조건에 맞는 목록을 File 배열로 리턴한다. |
FileFilter 와 FilenameFilter는 목록을 가져올 때 필요한 파일만 선택할 수 있다.
예를 들어, 텍스트 파일(.txt)과 이미지 파일(.jpg)이 섞여 있을 때, 이미지 파일만 가져오고 싶은 경우가 있을 것이다.
- FileFilter 와 FilenameFilter는 인터페이스므로 구현 후 사용해야 한다.
- 두 인터페이스에는
accept()메소드가 있다. - 구현한 클래스의 객체를 list로 시작하는 메소드(위의 6가지)의 매개변수로 넘겨주면, 메소드에서 파일이나 경로를 만날 때마다
accept()메소드가 자동 수행된다.
FileFilter 인터페이스
| 반환값 | 메소드 | 설명 |
|---|---|---|
| boolean | accpet(File pathname) | 매개 변수로 넘어온 File 객체가 조건에 맞는지 확인한다. |
public class JPGFileFilter implements FileFilter {
@Override
public boolean accept(File file) {
// 파일인지 확인 후,
if(file.isFile()) {
// 파일이 ".jpg"로 끝나면 true를 리턴한다.
String fileName=file.getName();
if(fileName.endsWith(".jpg")) return true;
}
return false;
}
}FilenameFilter 인터페이스
| 반환값 | 메소드 | 설명 |
|---|---|---|
| boolean | accpet(File dir, String name) | 매개 변수로 넘어온 디렉터리(dir)에 있는 경로나 파일 이름(name)이 조건에 맞는지 확인한다. |
💡 디렉터리와 파일을 구분하지 못하기 때문에, 만약 “.jpg”로 끝나는 디렉터리가 있으면 필터로 걸러낼 수가 없다.
public class JPGFilenameFilter implements FilenameFilter {
@Override
public boolean accept(File file, String fileName) {
// 파일이 ".jpg"로 끝나면 true를 리턴한다.
if(fileName.endsWith(".jpg")) return true;
return false;
}
}InputStream과 OutputStream
💡 InputStream과 OutputStream은 자바 스트림의 부모들이다.
자바의 I/O는 기본적으로 InputStream과 OutputStream이라는 abstract 클래스를 통해서 제공된다.
- 어떤 대상의 데이터를 읽을 때: InputStream
- 어떤 대상의 데이터를 쓸 때: OutputStream
InputStream 추상 클래스
클래스 선언문

Closeable
Closeable 인터페이스에는 close() 라는 메소드만 선언되어 있다. 어떤 리소스를 열었던 간에 이 인터페이스를 구현하면 해당 리소스는 close() 메소드를 이용하여 닫으라는 것을 의미한다.
java.io 패키지에 있는 클래스를 사용할 때에는, 해당 리소스를 다른 클래스에서도 작업할 수 있도록 하던 작업이 종료되면 close() 메소드를 “항상” 닫아 주어야 한다.
여기서 리소스라는 것은 파일, 네트워크 연결 등 스트림을 통해 작업할 수 있는 모든 것을 말한다.
메소드
꼭 기억해야 할 메소드로 지정된 것만 정리했다.
💡 스트림을 다룰 때 close() 메소드는 반드시 호출해야 한다. 그렇지 않으면 예상치도 못한 심각한 오류가 발생한다.
리턴 타입 | 메소드 | 설명 |
|---|---|---|
| abstract int | read() | 스트림에서 다음 바이트를 읽는다. 이 클래스에 선언된 유일한 abstract 메소드다. |
| void | close() | 스트림에서 작업 중인 대상을 해제한다. 이 메소드를 수행한 이후에는 다른 메소드를 사용하여 데이터를 처리할 수 없다. |
주로 사용하는 스트림
클래스 | 설명 |
|---|---|
| FileInputStream | 파일을 읽는 데 사용한다. 이미지와 같이 바이트 코드로 된 데이터를 읽을 때 사용한다. |
| FilterInputStream | 다른 입력 스트림을 포괄하며, 단순히 InputStream 클래스가 Override 되어 있다. |
| ObjectInputStream | ObjectOutputStream으로 저장한 데이터를 읽는 데 사용한다. |
FileInputStream과ObjectInputStream은 객체를 생성해서 데이터를 처리하면 된다.FilterInputStream클래스의 생성자는 protected로 선언되어 있기 때문에, 상속 받은 클래스에서만 객체를 생성할 수 있다.
FilterInputStream 클래스를 확장한 클래스 목록

OutputStream 추상 클래스
클래스 선언문
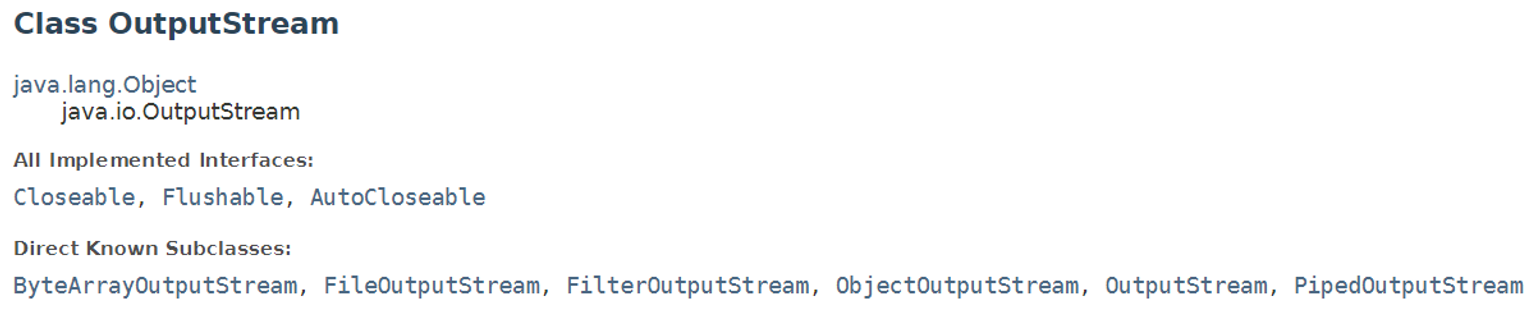
Flushable 인터페이스
flush() 메소드 하나만 선언되어 있다. 일반적으로 어떤 리소스에 데이터를 쓸 때, 매번 쓰기 작업을 “요청할 때마다 저장”하면 효율이 안좋아진다.
대부분 저장을 할 때 버퍼(buffer)를 가지고 데이터를 차곡차곡 쌓아 두었다가, 어느 정도 차게 되면 한 번에 쓰는 것이 좋다.
flush() 메소드는 그러한 버퍼를 사용할 때, 현재 버퍼에 있는 내용을 기다리지 말고 무조건 저장하도록 하는 것이다.
메소드
리턴 타입 | 메소드 | 설명 |
|---|---|---|
| void | write(byte[] b) | 매개 변수로 받은 바이트 배열(b)을 저장한다. |
| void | write(byte[] b, int off, int len) | 매개 변수로 받은 바이트 배열(b)의 특정 위치(off)부터 지정한 길이(len)만큼 저장한다. |
| abstract void | write(int b) | 매개 변수로 받은 바이트를 저장한다. 타입은 int 지만, 실제 저장되는 것은 바이트로 저장된다. |
| void | flush() | 버퍼에 쓰려고 대기하고 있는 데이터를 강제로 쓰도록 한다. |
| void | close() | 쓰기 위해 열은 스트림을 해제한다. |
사용 스트림
InputStream에서 살펴본 클래스들의 이름 뒤에 InputStream 대신 OutputStream 을 붙여 주면 된다.
Reader와 Writer
Reader와 Writer는 char 기반의 문자열을 처리하기 위한 클래스다.
Reader 추상 클래스
클래스 선언부
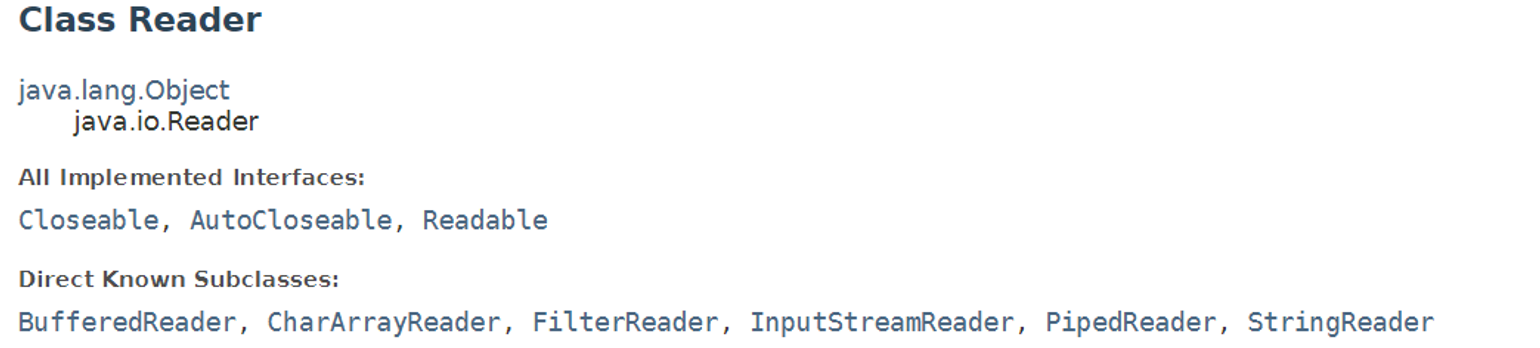
메소드
메소드의 목록을 보면 알겠지만, InputStream 클래스의 메소드와 많이 중복되는 것을 볼 수 있다.
💡 Reader 클래스도 모든 작업이 끝난 이후 close() 메소드를 호출해 주어야만 한다.
리턴 타입 | 메소드 | 설명 |
|---|---|---|
| int | read() | 하나의 Char를 읽는다. |
| int | read(char[] cbuf) | 매개 변수로 넘어온 char 배열에 데이터를 담는다. 리턴값은 데이터를 담은 개수다. |
| abstract int | read(char[] cbuf, int off, int len) | 매개 변수로 넘어온 char 배열에 특정 위치(off)부터 지정한 길이(len)만큼의 데이터를 담는다. 리턴값은 데이터를 담은 개수다. |
| int | read(CharBuffer target) | 매개 변수로 넘어온 CharBuffer 클래스의 객체에 데이터를 담는다. 리턴값은 데이터를 담은 개수다. |
| void | close() | Reader에서 작업 중인 대상을 해제한다. 이 메소드를 수행한 이후에는 다른 메소드를 사용하여 데이터를 처리할 수 없다. |
주로 사용하는 클래스
- BufferedReader
- InputStreamReader
Writer 추상 클래스
클래스 선언부
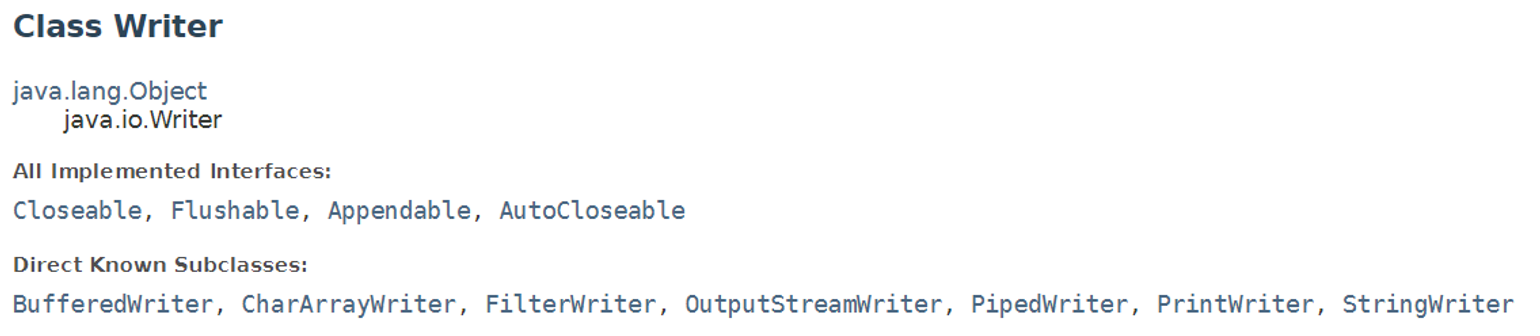
Appendable 인터페이스
Writer 클래스에는 다른 클래스에는 없는 Appendable 인터페이스가 구현되어 있다. 이 인터페이스는 Java5부터 추가되었으며, 각종 문자열을 추가하기 위해서 선언되었다.
메소드
OutputStream 클래스에 선언된 메소드와 대부분 동일하지만, append() 메소드가 존재한다는 점이 다르다.
리턴 타입 | 메소드 | 설명 |
|---|---|---|
| Writer | append(char c) | 매개 변수로 넘어온 char를 추가한다. |
| Writer | append(CharSequence csq) | 매개 변수로 넘어온 CharSequence를 추가한다. |
| Writer | append(CharSequence csq, int start, int end) | 매개 변수로 넘어온 CharSequence을 시작 위치(start)부터 끝 위치(end)까지 추가한다. |
| void | write(char[] buf) | 매개 변수로 넘어온 char의 배열을 추가한다. |
| abstract void | write(char[] cbuf, int off, int len) | 매개 변수로 넘어온 char의 배열을 특정 위치(off)부터 특정 길이(len) 만큼을 추가한다. |
| void | write(int c) | 매개 변수로 넘어온 int 값에 해당하는 char를 추가한다. |
| void | write(String str) | 매개 변수로 넘어온 문자열을 쓴다. |
| void | write(String str, int off, int len) | 매개 변수로 넘어온 문자열을 추가하며, 쓰여지는 해당 문자열의 시작 위치(start)와 끝 위치(end)를 지정하면 된다. |
| abstract void | flush() | 버퍼에 있는 데이터를 강제로 대상 리소스에 쓰도록 한다. |
| abstract void | close() | 쓰기 위해 열을 스트림을 해제한다. |
- CharSequence를 매개 변수로 받는다는 것은 대부분의 문자열을 다 받아서 처리한다는 말이다.
- CharSequence 인터페이스를 구현한 대표 클래스: String, StringBuilder, StringBuffer
- Writer 클래스가 제공된 JDK 1.1에는 데이터를 저장하기 위한 메소드는 write() 뿐이었다.
- 그래서 append()와 write() 메소드가 비슷해 보인다.
- 만들어진 문자열이 String 타입: write() 메소드를 사용해도 상관 없다.
- 만들어진 문자열이 StringBuilder, StringBuffer 타입: append() 메소드를 사용하는 것이 훨씬 편하다.
텍스트 파일 쓰기
사용 클래스
책에서 사용한 클래스에 대해 정리한다.
- FileWriter 클래스
- write()나 append() 메소드를 호출할 때마다 파일에 쓴다는 단점이 있다.
- BufferedWriter 클래스
- FileWriter 클래스의 단점을 보완하는 클래스이다.
- 버퍼라는 공간에 저장할 데이터를 보관해 두었다가, 버퍼가 차게되면 데이터를 저장하도록 도와주므로 효율적인 저장이 가능하다.
생성자
| 생성자 | 설명 |
|---|---|
| FileWriter(File file) | File 객체를 매개 변수로 받아 객체를 생성한다. |
| FileWriter(File file, boolean append) | File 객체를 매개 변수로 받아 객체를 생성한다. append 가 true면 해당 파일에 뒤에 붙이고, false면 해당 파일을 덮어 쓴다. |
| FileWriter(FileDescriptor fd) | FileDescriptor 객체를 매개 변수로 받아 객체를 생성한다. |
| FileWriter(String fileName) | 지정한 문자열의 경로와 파일 이름에 해당하는 객체를 생성한다. |
| FileWriter(String fileName, boolean append) | 지정한 문자열의 경로와 파일 이름에 해당하는 객체를 생성한다. append 값에 따라 데이터를 추가할지 덮어쓸지를 정한다. |
| BufferedWriter(Writer out) | Writer 객체를 매개 변수로 받아 객체를 생성한다. |
| BufferedWriter (writer out, int size) | Writer 객체를 매개 변수로 받아 객체를 생성한다. 그리고 두 번째 매개 변수인 size를 사용해 버퍼의 크기를 정한다. |
- FileWriter 객체를 생성할 때 IOException이 발생할 수 있다.
- 매개 변수로 넘어온 파일 이름이 파일이 아닌 경로를 의미할 경우
- 해당 파일이 존재하지는 않지만, 권한 등의 문제로 생성할 수 없는 경우
- 파일이 존재하지만, 여러 가지 이유로 파일을 열 수 없는 경우
사용 예제
// static import로 가져와 상수처럼 사용 가능
import static java.io.File.separator;
public static void main(Stringp[] args) {
String fileName = separator + "godOfJava" + separator + "numbers.txt"
FileWriter fileWriter = null;
BufferedWriter bufferedWriter = null;
try {
// 객체 생성
fileWriter = new FileWriter(fileName);
bufferedWriter = new BufferedWriter(fileWriter);
// 1~10까지 파일에 쓰기
for(int loop=0; loop<=10; loop++) {
// write() 메소드로 데이터 입력
bufferedWriter.write(Integer.toString(loop);
// 줄바꿈을 해준다.
bufferedWriter.newLine();
}
} catch(IOException ioe) {
...
} catch(Exception e) {
...
} finally {
// bufferedWriter를 닫는다.
if (bufferedWriter != null) {
try {
bufferedWriter.close();
} catch (IOException ioe) {
...
}
}
// fileWriter를 닫는다.
if (fileWriter != null) {
try {
fileWriter.close();
} catch (IOException ioe) {
...
}
}
}
}- 가장 마지막에 연(open) 객체부터 닫아주어야 정상적인 처리가 가능하다.
- 예제에서는 fileWriter → bufferedWriter 순으로 객체를 생성했으므로 bufferedWriter 부터 닫았다.
텍스트 파일 읽기
사용 클래스
책에서 사용한 클래스에 대해 정리한다.
- FileReader 클래스
- BufferedReader 클래스
- Scanner 클래스
사용 예제
public static void main(Stringp[] args) {
String fileName = separator + "godOfJava" + separator + "numbers.txt"
FileReader fileReader = null;
BufferedReader bufferedReader = null;
try {
// 객체 생성
fileReader = new FileReader(fileName);
bufferedReader = new BufferedReader(fileReader);
// readLine() 메소드의 수행 결과를 data에 담는다.
String data;
While( (data = bufferedReader.readLine()) != null ) {
System.out.println(data);
}
} catch(IOException ioe) {
...
} catch(Exception e) {
...
} finally {
// bufferedReader를 닫는다.
if (bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException ioe) {
...
}
}
// fileReader를 닫는다.
if (fileReader != null) {
try {
fileReader.close();
} catch (IOException ioe) {
...
}
}
}
}Scanner 클래스
java.util 패키지의 Scanner 클래스는 텍스트 기반의 기본 자료형이나 문자열 데이터를 처리하기 위한 클래스다.
- 정규 표현식(Regular Expression)을 사용하여 데이터를 잘라 처리할 수 있다.
💡 정규 표현식(Regular Expression)
문자열을 처리하기 위해 많이 사용된다. JDK 1.4부터 사용할 수 있도록 관련 API가 제공되었다.
참고: java.util.regex.Pattern 클래스의 API
| 리턴 타입 | 메소드 | 설명 |
|---|---|---|
| boolean | hasNextLine | 다음 줄이 있는지 확인한다. |
| String | nextLine | 다음 줄의 내용으로 문자열로 한 줄씩 리턴한다. |
위의 예제는 코드의 길이도 길고 가독성도 떨어지는데, Scanner 클래스를 사용하면 매우 쉽게 파일을 읽을 수 있다.
public static void main(Stringp[] args) {
String fileName = separator + "godOfJava" + separator + "numbers.txt"
File file = new File(fileName);
Scanner scanner = null;
try {
scanner = new Scanner(file);
While(scanner.hasNextLine()) {
System.out.println(scanner.nextLine());
}
} catch(FileNotFoundException fnfe) {
...
} catch(Exception e) {
...
} finally {
if (scanner != null) {
scanner.close()
}
}
}Files 클래스
Java 7에서 제공하는 클래스로, 더 간단하게 파일을 읽을 수 있다.
String data = new String(Files.readAllBytes(Paths.get(fileName)));정리해 봅시다.
Q. I/O는 각각 무엇의 약자인가요?
Me: Input/Output
Q. java.io.File 클래스는 파일만 지정할 수 있나요?
Me: X
Q. OS 마다 다른 경로 구분자를 처리하기 위해서는 File 클래스의 어떤 상수를 사용해야 하나요?
Me: separator
Q. File 클래스에서 디렉터리를 만드는 mkdir()과 mkdirs() 메소드의 차이는 무엇인가요?
Me: mkdir()은 디렉토리를 하나 생성하고, mkdirs()는 하위 디렉토리까지 모두 생성한다.
Q. File 클래스의 list() 메소드와 listFiles() 메소드의 차이는 무엇인가요?
Me: list() 는 현재 디렉터리의 하위에 있는 목록을 String 배열로 리턴하고, listFiles()는 현재 디렉터리 하위에 있는 목록을 File 배열로 리턴한다.
Q. FileFilter와 FilenameFilter의 차이는 무엇인가요?
Me: FileFilter는 매개 변수로 넘어온 File 객체가 조건에 맞는지 확인하고, FilenameFiler는 매개 변수로 디렉터리에 있는 경로나 파일 이름을 받는다. FilenameFilter는 디렉터리와 파일을 구분하지 못하기 때문에, 만약 .jpg로 끝나는 디렉터리가 있으면 필터로 걸러낼 수가 없다.
Q. InputStream 이라는 abstract 클래스는 어떤 작업을 하기 위해서 만들어 진 것인가요?
Me: Stream 기반의 클래스로 byte 파일을 읽을 때 사용한다.
Q. OutputStream 이라는 abstract 클래스는 어떤 작업을 하기 위해서 만들어 진 것인가요?
Me: Stream 기반의 클래스로 byte 파일을 쓸 때 사용한다.
Q. Reader 라는 abstract 클래스는 어떤 작업을 하기 위해서 만들어 진 것인가요?
Me: char 기반의 문자열 파일을 읽기 위해 만들어 졌다.
Q. Writer 라는 abstract 클래스는 어떤 작업을 하기 위해서 만들어 진 것인가요?
Me: char 기반의 문자열 파일을 쓰기 위해 만들어 졌다.
Q. BufferedReader나 BufferedWriter를 사용하는 이유는 무엇인가요?
Me: 파일을 읽고 쓰기 위해 메소드를 호출할 때마다 반영하는 건 효율이 나쁘다. 버퍼라는 공간에 한 번에 모았다가 읽고 쓰는 방식으로 더 효율적인 사용이 가능하다.
Q. 파일을 읽고, 문자열을 처리하기 위해서 필요한 Scanner 클래스가 속해있는 패키지는 무엇인가요?
Me: java.util
질문
💡 책에 있는 내용이 아닙니다.
책을 읽으며 설명이 더 필요하거나, 추가로 궁금한 점에 대해 질문 형식으로 작성 후, 답을 구해보고 있습니다.
참고한 사이트나 영상은 [출처]로 달아두었으며, 오류 지적은 언제나 환영합니다.
Q. 바이너리 파일과 바이트 파일
Byte
바이트(Byte)는 데이터의 기본 단위 중 하나로, 8비트를 말한다.
- 컴퓨터에서 정보를 저장하고 전송하는 데 기본적으로 사용하는 단위
- 텍스트, 이미지, 음악 파일 등 모든 종류의 데이터는 바이트로 표현
Binary
바이너리(Binary)는 “이진” 혹은 “이진 코드”를 의미하며, 0과 1로 이루어진 코드를 말한다.
- 컴퓨터에서 데이터를 표현하는 데 사용되는 모든 종류의 코드
- 텍스트 이외의 데이터(이미지, 동영상, 음악 등)를 나타낼 때 사용
- 텍스트 파일도 내부적으로는 이진 데이터지만, 사람이 읽을 수 있는 문자열로 구성되어 있으므로 제외한다.
바이트와 바이너리
바이트는 데이터의 크기 단위를 의미하고, 바이너리는 0과 1로 이루어진 데이터를 의미한다.
바이트 파일과 바이너리 파일
일반적으로 바이너리 파일은 텍스트 파일이 아닌 모든 종류의 파일을 의미한다. 바이너리 파일은 사람이 읽을 수 없는 이진 데이터로 구성되어 있다.
바이트 파일은 바이트 단위로 저장하거나 처리하는 파일을 의미한다.
즉, 바이트 파일은 파일 내용을 바이트로 표현하는 데 중점을 두고 있고, 바이너리 파일은 텍스트 파일이 아닌 모든 종류의 이진 파일을 포함하는 데 사용한다.
두 용어는 대부분의 상황에서 같은 의미로 사용된다.
바이트 코드와 바이너리 코드
바이트 코드(Bytecode)는 특정 프로그래밍 언어의 중간 단계의 코드를 말한다. 보통 가상 머신에서 실행되는 이진 형식의 코드를 의미하며, 가상 머신이 이해할 수 있는 언어라고 표현한다.
바이너리 코드(Binary Code)는 CPU가 직접 해석하여 실행할 수 있는 0과 1로 이루어진 코드를 말한다. 즉, 컴퓨터가 직접 실행할 수 있는 이진 형식의 코드를 의미한다.
Q. Stream이란 뭘까?
I/O Stream
스트림(Stream)이란 데이터를 읽고 쓰기 위한 일련의 연속된 데이터 흐름을 말한다.
출발지에서 도착지로 데이터를 운반하는 연결 통로로, 오라클 문서에서는 “A stream is a sequence of data”라고 표현했다.
데이터 시퀀스는 데이터가 특정한 순서로 나열된 구조를 말하는데, 스트림은 데이터를 순차적으로 읽거나 쓰는 데이터 흐름이므로 이렇게 표현한 것 같다.
일반적으로 입출력 스트림은 단방향이다.
- 입력 스트림: 데이터를 읽기 위한 통로.
- 출력 스트림: 데이터를 쓰기 위한 통로.
입출력 스트림을 조합하여 양방향 통신을 구현할 수 있다고 한다.
- 소켓 통신에서는 InputStream과 OutputStream을 조합하여 양방향 통신을 구현
Byte Streams와 Character Streams
입출력 스트림은 바이트 기반 스트림과 문자 기반 스트림으로 나뉜다.
- 바이트 기반 스트림
- InputStream/OutputStream 클래스
- FileInputStream/FileOutputStream 클래스
- 문자 기반 스트림
- Reader/Writer 클래스
- FileReader/FileWriter 클래스
- BufferedReader/BufferedWriter 클래스
Stream API
Java 8에서 추가된 함수형 프로그래밍 스타일의 API으로, java.util.stream 패키지의 Stream 인터페이스를 말한다.
- 함수형 프로그래밍의 특징을 지원한다.
- 함수를 인자로 전달하거나 반환하며, 람다 표현식과 같은 기능을 활용할 수 있다.
- 스트림은 원본 데이터를 변경하지 않는다.
- 스트림은 재사용이 가능한 컬렉션과는 달리 단 한 번만 사용할 수 있다.
- 컬렉션을 명시적으로 반복하지 않고 내부에서 자동으로 처리한다.
- 이는 코드를 간결하게 만들어준다.
- 지연 연산(Lazy Evaluation)을 지원한다.
- 데이터 처리 연산이 필요할 때만 수행하여 성능을 최적화한다.
- 중간 연산과 최종 연산으로 구성된다.
- 중간 연산: 데이터를 변환하거나 필터링하는 등의 작업 수행
- 최종 연산: 최종 결과를 생성하거나 반환
- 내부적으로 병렬 처리를 지원한다.
- parallelStream() 메소드 제공
Q. NIO의 버퍼와 채널이란?
NIO(New I/O)는 기존의 I/O보다 빠르고 효율적인 입출력 작업을 수행할 수 있도록 설계되어 있으며, 핵심 개념으로 버퍼와 채널이 있다.
Buffer
데이터를 임시로 저장하는 메모리 영역이다. 입출력 작업에서 데이터는 버퍼를 통해 이동한다.
버퍼가 사용하는 메모리의 위치에 따라 두 가지로 분류된다.
- Direct Buffer
- 운영체제의 네이티브 메모리를 사용하는 버퍼
- 주로 입출력 작업에서 사용되며, 네이티브 코드와의 상호 작용에서 효율적이다.
- 네이티브 메모리로 직접 데이터를 할당하므로 입출력 성능이 향상될 수 있다.
- 대용량 데이터를 다루거나 네이티브 코드와 데이터를 공유하려는 경우 사용한다. (성능 향상)
- Non-Direct Buffer
- JVM의 힙 메모리를 사용하는 버퍼
- 입출력 작업이나 일반적인 데이터 처리에서 사용한다.
- Direct Buffer보다는 속도가 느리지만, 메모리 관리 등에서 더 유연하게 동작할 수 있다.
- 상대적으로 작은 크기의 데이터를 다루거나, 데이터를 자주 생성하고 해제하는 경우 등에 사용한다.
Channel
입출력 작업을 수행하는 연결 통로이다. 기존의 스트림 기반 I/O와는 다르게 양방향 통신을 하며, 비동기/non-blocking 방식을 지원한다.
아래와 같은 채널들을 제공한다.
- FileChannel: 파일에 대한 입출력을 담당하는 채널
- 이 채널은 양방향 통신은 지원하지 않는다.
- SocketChannel: TCP 네트워크 소켓에 대한 입출력을 담당하는 채널
- DatagramChannel: UDP 네트워크 소켓에 대한 입출력을 담당하는 채널
동기/비동기와 블로킹/넌블로킹
-
동기 (Synchronous) vs. 비동기 (Asynchronous)
동기는 호출된 작업이 완료될 때까지 대기하는 방식으로, 작업이 끝났는지 여부를 확인한다.
비동기는 호출된 작업이 완료되지 않아도 다음 코드를 실행할 수 있는 방식으로, 콜백 메소드로 반환 여부를 알림 받는다. -
블로킹 (Blocking) vs. 넌블로킹 (Non-blocking)
블로킹은 호출된 쪽이 제어권을 가지고 가서, 작업이 완료될 때까지 호출한 쪽은 다른 작업을 하지 못하고 대기시킨다.
넌블로킹은 호출된 쪽이 제어권을 돌려줘서, 호출한 쪽은 다른 작업을 할 수 있다.
이 개념들은 헷갈리는 경우가 많다.
동기/비동기는 호출한 함수의 수행 결과 및 종료를 확인하느냐 마느냐이고, 블로킹/넌블로킹은 제어권을 호출된 함수가 가지고 갔느냐 아니냐의 차이이다.
예를 들어, 동기-넌블로킹이라면 호출한 함수 쪽에서 다른 작업을 진행할 수 있지만 지속적으로 작업이 끝났는지를 확인한다.
Q. File 클래스의 정체가 불분명하다는 것은 무슨 뜻인가?
기존의 File 클래스는 파일과 파일 경로 정보를 함께 가지고 있다. 즉, 파일 및 경로를 함께 다루기 때문에 이것이 파일인지 경로인지 구분하기 어려울 수 있다.
반면 NIO에서 추가된 file 패키지는 파일 정보와 경로 정보를 별도의 클래스로 분리하여 다루고 있다.
위와 같은 이유로 불분명하다고 한 게 아닐까?
Q. 심볼릭 링크란?
심볼릭 링크(Symbolic Link)는 리눅스의 파일 시스템에서 다른 파일이나 디렉터리를 가리키는 특별한 종류의 파일이다. 윈도우의 ‘바로가기’와 유사하다고 한다.
심볼릭 링크는 소프트 링크라고도 불리며, 하드 링크라는 개념과는 반대된다.
소프트 링크 (Symbolic Link)
- 다른 파일 시스템이나 디렉터리 간 링크가 가능하다.
- 원본 파일의 경로를 가리키며, 심볼릭 링크 파일 자체는 단순한 텍스트 파일로 이루어져 있다.
- 원본 파일이 삭제되면 유효하지 않은 참조가 되어 동작하지 않는다.
- 상대 경로로 가리킬 대상을 지정할 수 있다.
하드 링크(Hard Link)
- 동일한 파일 시스템 내의 파일만 링크가 가능하다.
- 원본 파일과 동일한 inode 번호를 공유하는 파일이다.
- inode: ndex node number의 약자로 리눅스/유닉스 시스템에서 모든 파일들에 할당되는 고유의 번호
- 파일의 내용, 소유자, 권한 등 모든 속성이 일치
- 원본 파일이나 하드 링크 중 어느 하나를 삭제해도 다른 것은 그대로 유지된다.
Q. URI란?
- URI (Uniform Resource Identifier)
- 인터넷에 있는 자원을 나타내는 유일한 주소 (자원의 식별자)
- URL과 URN의 상위 개념이다.
- URL (Uniform Resource Locator)
- 네트워크 상에서 자원이 어디 있는지를 알려주기 위한 규약 (위치)
- 쉽게 말해, 웹 페이지를 찾기 위한 주소
- URN (Uniform Resource Name)
- urn:scheme을 사용하는 URI를 위한 역사적인 이름 (이름)
- 자원에 이름을 부여하는 방법인데, 이름으로 부여하면 거의 찾기가 힘들어서 대부분 URL만 사용한다고 한다.
Q. Scanner VS BufferedReader
Scanner 클래스
Scanner 클래스는 표준 입력(키보드) 또는 텍스트를 읽기 위해 사용되는 클래스 중 하나이다. 간단하게 사용할 수 있어서 입출력 작업이나 콘솔 입력을 처리하는 데 많이 활용된다.
- 공백 및 개행을 기준으로 읽는다.
- 사용자가 직접 구분자를 지정할 수도 있다.
- 다양한 데이터 타입을 편리하게 읽어올 수 있도록 메소드를 제공한다.
- 동기화되지 않는다.
- 정규식을 사용할 수 있다.
BufferedReader
데이터를 한 번에
- 데이터를 적절한 크기의 버퍼에 일부분씩 읽어와 저장하고, 프로그램이 실제로 데이터를 요청하면 버퍼에서 읽어온다.
- 입출력 성능 향상
- 동기화된다. (Thread safe)
- 명시적으로 버퍼 크기를 지정할 수 있다.
결론
스택오버플로우의 답변에 따르면, 아래와 같은 차이가 있다고 한다.
- BufferedReader is synchronized but Scanner is not synchronized.
- BufferedReader is thread-safe but Scanner is not thread-safe.
- BufferedReader has larger buffer memory but Scanner has smaller buffer memory.
- BufferedReader is faster but Scanner is slower in execution.
다양한 데이터 타입을 읽어야 하거나 간편하게 사용하고 싶다면 Scanner 클래스를 사용하면 되지만, 대용량의 텍스트 데이터를 읽어야 하거나 더 빠른 입출력을 제공하고 싶다면 BufferedReader 클래스를 사용하면 된다.
Q. Char 기반의 문자열은 왜 사용할까?
String 기반일 경우 발생하는 문제
String은 불변(immutable)하기 때문에, 문자열을 다룰 때 새로운 문자열이 생성된다. 즉, 문자열 변경이 자주 발생한다면 메모리가 낭비되고, 성능 저하가 발생할 수 있다.
반면, Char는 유니코드 문자 하나를 표현하므로, 문자열 파일을 읽어올 때 유니코드 문자를 하나씩 처리하는데 더 적합하다.
Reader와 Writer 클래스도 문자(Char) 단위의 입출력을 위해 설계되었다.
패스워드는 Char[]을 써야 한다는 글을 봤다.
사용자의 패스워드와 같은 중요한 정보를 다룰 때, 일반적으로 char[]를 사용하는 것이 String을 사용하는 것보다 안전성 면에서 더 좋은 선택일 수 있다.
String은 불변(immutable)하며, 메모리 내에서 재사용될 수 있다. 즉, 비밀번호를 String으로 저장한다면 가비지 컬렉션이 일어나 메모리에서 사용되지 않는 객체를 지우기 전까지는 메모리 상에 그대로 남아있다.
char[]를 사용한다면, 데이터를 비우거나 다른 값으로 덮어쓰기 하는 등의 처리가 가능하지만, String은 기존 값은 변경되지 않으므로 보안에 민감한 정보가 메모리에 계속 남아있을 가능성이 있다.
또한, 로그로 출력했을 경우 String은 그대로 출력되지만 배열은 배열의 위치(해시코드가 출력되었던 거 같은데)가 출력되므로 실수로 로그로 출력했을 경우에도 보호된다.
char[] 를 사용한 패스워드 처리
import java.util.Arrays;
public class PasswordExample {
public static void main(String[] args) {
char[] password = {'s', 'e', 'c', 'r', 'e', 't'};
// 패스워드 사용
// 패스워드 사용이 끝나면 char 배열을 클리어하여 데이터를 안전하게 지움
Arrays.fill(password, '0');
}
}Q. FileDescriptor
사용할 일은 거의 없다지만, 아주 간략하게 검색해봤다.
운영체제에서 열린 파일 또는 소켓과 같은 I/O 리소스를 식별하는 데 사용된다. 주로 네이티브 메소드와 함께 사용된다.
보통 하위 수준의 I/O 작업에 사용되며, 보다 안정적이고 편리한 고수준의 API가 있기 때문에 개발자가 직접 다루는 경우는 드물다.
참고 사이트
Java: Difference between Streams and I/O stream explained
Difference Between Bytecode and Binary Code
I/O Streams (The Java™ Tutorials >
Essential Java Classes > Basic I/O)
자바 NIO의 동작원리 및 IO 모델
리눅스 Symlink 튜토리얼 - 심볼릭 링크(Symbolic Link)를 생성하고 삭제하는 방법
🌐 URL / URI / URN 차이점 - 한방 이해하기
Why is a char[] Preferred Over a String for Passwords?
