데이터 전처리
- 전체 데이터 전처리 과정 요약
- 전처리 코드가 너무 긴 경우 첨부하지 않았음.
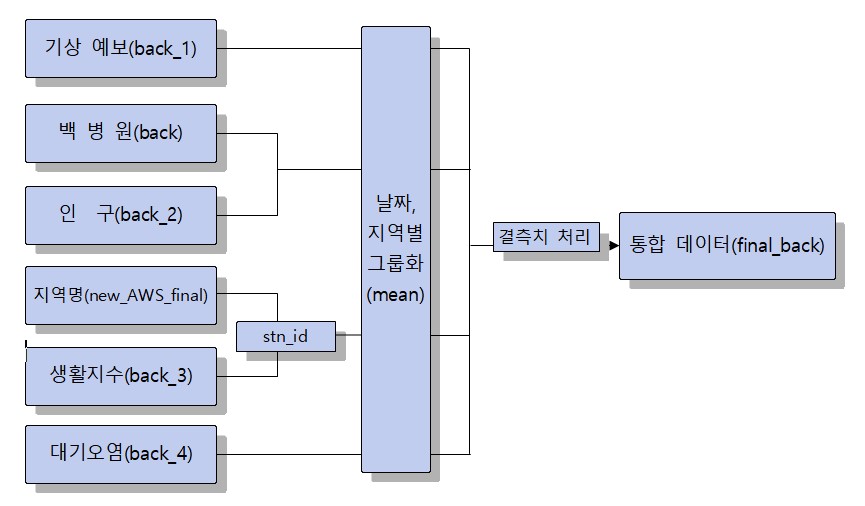
1. 제공 데이터
1) 지역별 심뇌혈관 질환 빈도
-
기간: 2012 ~ 2015 + 2016(검증용)
-
제공처: 백병원&(주)렉스소프트
대회 측에서 제공하는 데이터는 학습을 위한 primary key(날짜, 지역, 성별)와 예측 대상인 심뇌혈관질환 발생건수(frequency)만을 제공한다. 예측을 위한 데이터는 오로지 참가자들의 몫이지만 조건에 반드시 기상예보데이터가 들어가야한다.
yyyymmdd area sex frequency
1 20120101 강원 1 3.0
2 20120101 강원 2 3.0
3 20120101 경기 1 4.0
4 20120101 경기 2 5.0
5 20120101 경남 1 2.0
... ... ... ... ...
12441 20161231 제주 2 NaN
12425 20161231 충남 1 NaN
12442 20161231 충남 2 NaN
12426 20161231 충북 1 NaN
12443 20161231 충북 2 NaN
62118 rows × 4 columns2) 기상 예보
-
기간: 2012 ~ 2016
-
활용 데이터: 3시간기온, 습도, 일최고기온, 일최저기온, 풍속, 12시간강수량, 12시간신적설
-
제공처: 날씨 빅데이터 콘테스트
날씨마루 데이터베이스 상의 오류와 데이터 크기가 매우 커 참가자들이 데이터를 받지 못하자 대회측에서 제공해준 데이터이다. 당일 9시, 15시 21시 기상상황을 예보한 데이터이고 결측치는 interpolate 함수로 날짜를 기준으로 보간하였다.
yyyymmdd area sex frequency 3시간기온_mean_9 3시간기온_mean_15 3시간기온_mean_21 습도_mean_9 습도_mean_15 습도_mean_21 ... 일최저기온_mean_21 풍속_mean_9 풍속_mean_15 풍속_mean_21 강수량_mean_9 강수량_mean_15 강수량_mean_21 적설_mean_9 적설_mean_15 적설_mean_21
0 20120101 강원 1 3.0 -1.657143 -5.650000 -8.032143 50.642857 78.982143 83.250000 ... -9.000000 286.714286 288.285714 163.976190 2.5 2.142857 0.267857 2.5 1.875 0.267857
1 20120101 강원 2 3.0 -1.657143 -5.650000 -8.032143 50.642857 78.982143 83.250000 ... -9.000000 286.714286 288.285714 163.976190 2.5 2.142857 0.267857 2.5 1.875 0.267857
2 20120101 경기 1 4.0 -2.520000 -6.440000 -9.756667 44.400000 64.100000 79.533333 ... -9.530000 319.600000 318.800000 289.666667 0.0 0.000000 0.000000 0.0 0.000 0.000000
3 20120101 경기 2 5.0 -2.520000 -6.440000 -9.756667 44.400000 64.100000 79.533333 ... -9.530000 319.600000 318.800000 289.666667 0.0 0.000000 0.000000 0.0 0.000 0.000000
4 20120101 경남 1 2.0 2.492857 -2.101786 -4.680952 40.071429 59.803571 68.476190 ... -4.339286 313.571429 312.785714 284.380952 0.0 0.000000 0.000000 0.0 0.000 0.000000
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
62113 20161231 제주 2 NaN 8.600000 6.275000 5.650000 56.500000 64.375000 66.333333 ... 6.883333 4.850000 2.847917 2.027778 3.0 5.000000 1.000000 5.0 1.000 1.000000
62114 20161231 충남 1 NaN 3.216667 -0.970833 -1.831111 76.000000 88.750000 88.155556 ... -0.035000 1.266667 0.662500 0.950000 3.0 5.000000 1.000000 5.0 1.000 1.000000
62115 20161231 충남 2 NaN 3.216667 -0.970833 -1.831111 76.000000 88.750000 88.155556 ... -0.035000 1.266667 0.662500 0.950000 3.0 5.000000 1.000000 5.0 1.000 1.000000
62116 20161231 충북 1 NaN 1.516667 -0.616667 -2.432222 79.250000 82.300000 86.972222 ... -0.866667 1.800000 0.900000 0.816667 3.0 5.000000 1.000000 5.0 1.000 1.000000
62117 20161231 충북 2 NaN 1.516667 -0.616667 -2.432222 79.250000 82.300000 86.972222 ... -0.866667 1.800000 0.900000 0.816667 3.0 5.000000 1.000000 5.0 1.000 1.0000002. 외부 데이터
1) 관측지점정보
-
기간: 2012 ~ 2016
-
출처 : 기상자료개방포털 > 데이터 > 메타데이터 > 지점정보 >
관측지점정보 ( https://data.kma.go.kr/tmeta/stn/selectStnList.do )관측지점정보인 stn_id는 primary key로 데이터베이스에서 받아온 데이터들을 합칠때 사용할 기준이 된다. 예측 key인 지역이 서울,경기,인천과 같은 지역명이므로 적절히 매핑하였다.
area_names = pd.read_csv('/content/drive/MyDrive/2022_WeatherContest_Data/DataSet/mapping_data/META_관측지점정보_20220701105117.csv', index_col=0)
AWS = pd.read_csv('/content/drive/MyDrive/2022_WeatherContest_Data/DataSet/mapping_data/AWS.csv', encoding='cp949', index_col=0)
new_AWS = pd.merge(AWS, area_names, left_on='지점번호', right_on='지점', how='left')
new_AWS.drop(['지점', '지점명'], axis=1, inplace=True)
idxs = new_AWS['지점주소'].fillna('non fault')
new_AWS['area'] = [idx.split()[0] for idx in idxs]
def area_words(word):
if word in ['경상북도', '충청북도', '충청남도', '경상남도', '전라북도', '전라남도']:
word = list(word)[0] + list(word)[2]
elif word == '서귀포시':
word = '제주'
elif word == 'non':
word = word
else:
word = list(word)[0] + list(word)[1]
return word
new_AWS['area'] = [area_words(i) for i in new_AWS['area']]
## 남은 100여개는 직접 매핑한다.
new_AWS_final = pd.read_csv('/content/drive/MyDrive/2022_WeatherContest_Data/DataSet/mapping_data/new_AWS_after.csv', encoding='cp949').drop(['관리관서', '지점주소'], axis=1)
new_AWS_final.drop_duplicates(subset = ['지점번호', '지점명(한글)'],ignore_index=True, inplace=True)
new_AWS_final.drop('지점명(한글)', axis=1, inplace=True)
new_AWS_final.rename(columns={'지점번호' : 'stn_id'}, inplace=True)
new_AWS_final.to_csv('/content/drive/MyDrive/2022_WeatherContest_Data/DataSet/mapping_data//new_AWS_final.csv', index=False, encoding='cp949')
new_AWS_finalstn_id area
0 90 강원
1 92 강원
2 95 강원
3 96 경북
4 98 경기
... ... ...
687 963 울산
688 966 인천
689 967 인천
690 968 부산
691 969 부산
692 rows × 2 columns2) 행정구역(시군구)별, 성별 인구수
-
기간: 2012 ~ 2016
-
출처: KOSIS > 행정구역(시군구)별, 성별 인구수
( https://kosis.kr/statHtml/statHtml.do?orgId=101&tblId=DT_1B040A3)단순 기상 데이터로만 심뇌혈관 발생을 예측하기엔 무리가 있을 것 같아 해당 기간의 지역별 성별 및 인구 수 데이터를 추가하였다. 원천 데이터의 형태가 통계데이터 형식이라 처리하는데 많은 시간이 소요되었다.
세종 시의 경우 2012년 7월에 출범한 특별자치시이기에 그 이전 데이터는 존재하지 않아 시간 순으로 정렬 후 선형 비례하도록 결측치를 보간해주었다.
yyyymmdd area sex frequency tot_person num_risk_age
0 20120101 강원 1 3.0 772718 322636.0
1 20120101 강원 2 3.0 762617 229447.0
2 20120101 경기 1 4.0 6020446 2054584.0
3 20120101 경기 2 5.0 5928150 1182747.0
4 20120101 경남 1 2.0 1665308 622268.0
... ... ... ... ... ... ...
62113 20161231 제주 2 NaN 319052 94654.0
62114 20161231 충남 1 NaN 1064765 471322.0
62115 20161231 충남 2 NaN 1031962 348117.0
62116 20161231 충북 1 NaN 803240 358361.0
62117 20161231 충북 2 NaN 788385 258676.0
62118 rows × 6 columns3) 생활지수 예보
-
기간: 2012 ~ 2016
-
활용 데이터: A03(체감온도), A04(동상가능지수), A05(열지수), A06(불쾌지수)
-
출처: 날씨마루
오전 6시 기준으로 3시간 뒤, 6시간 뒤, 9시간 뒤의 예보 데이터 사용하였다. 지역명, 발표시간 기준으로 그룹화하여 평균값을 구하였다.
yyyymmdd area sex frequency A03_t1 A03_t2 A03_t3 A04_t1 A04_t2 A04_t3 A05_t1 A05_t2 A05_t3 A06_t1 A06_t2 A06_t3
0 20120101 강원 1 3.0 -3.006250 -1.112500 -1.112500 -2.677778 -0.455556 0.600000 0.181250 1.050000 1.425000 33.268750 39.906250 42.375000
1 20120101 강원 2 3.0 -3.006250 -1.112500 -1.112500 -2.677778 -0.455556 0.600000 0.181250 1.050000 1.425000 33.268750 39.906250 42.375000
2 20120101 경기 1 4.0 -4.521429 -3.050000 -3.367857 -2.566667 -0.300000 0.666667 0.000000 0.067857 0.342857 32.271429 38.539285 39.732143
3 20120101 경기 2 5.0 -4.521429 -3.050000 -3.367857 -2.566667 -0.300000 0.666667 0.000000 0.067857 0.342857 32.271429 38.539285 39.732143
4 20120101 경남 1 2.0 -0.660000 3.120000 3.275000 0.133333 4.833333 5.766667 0.870000 4.690000 5.830000 36.465000 45.705000 47.840000
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
62113 20161231 제주 2 NaN 2.659574 6.234043 6.787234 4.787234 8.212766 8.723404 4.787234 8.127660 8.702128 NaN NaN NaN
62114 20161231 충남 1 NaN -0.017857 3.593750 5.500000 0.080357 3.892857 6.035714 0.558036 3.848214 6.026786 NaN NaN NaN
62115 20161231 충남 2 NaN -0.017857 3.593750 5.500000 0.080357 3.892857 6.035714 0.558036 3.848214 6.026786 NaN NaN NaN
62116 20161231 충북 1 NaN -2.166667 0.285714 2.226190 -2.166667 1.922619 3.964286 0.000000 1.916667 3.922619 NaN NaN NaN
62117 20161231 충북 2 NaN -2.166667 0.285714 2.226190 -2.166667 1.922619 3.964286 0.000000 1.916667 3.922619 NaN NaN NaN
62118 rows × 16 columns4) 대기오염
-
기간: 2012 ~ 2016
-
활용 데이터 : NO2, CO, SO2, O3, PM10
-
출처: 에어코리아 > 통계정보 > 확정자료 다운로드
(https://www.airkorea.or.kr/web/last_amb_hour_data)사전 조사에서 심혈관질환 발생에 유의미한 영향을 미치는 요인으로 대기오염물질이 있었기에 분석 데이터로 활용하였다.
import math
from tqdm import tqdm
from sklearn.linear_model import LinearRegression
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
lr = LinearRegression()
imp = IterativeImputer(estimator=lr,missing_values=np.nan, verbose=0, min_value = 0, imputation_order='roman',random_state=42)
path = '/content/drive/MyDrive/2022_WeatherContest_Data/DataSet/atmosphere/'
file_list = os.listdir(path)
func_list = ['mean']
data_list = []
for i in tqdm(file_list):
res = pd.read_csv(path + i)
data_list.append(res)
res_data = pd.concat(data_list, axis=0, ignore_index = True)
atmo = res_data.iloc[:, [0,3,4,5,6,7,8]]
df = atmo.copy() # SettingWithCopyWarning 회피용도
df.loc[:, 'area'] = [i.split()[0] for i in df['지역']]
df.loc[:, 'yyyymmdd'] = [math.floor(i / 100) for i in df['측정일시']]
df.drop(['지역', '측정일시'], axis=1, inplace=True)
# 이상치 -999를 평균으로 대체
col_list = ['SO2', 'CO', 'O3', 'NO2', 'PM10']
for i in col_list:
df.loc[df[i] == -999, i] = df[df[i] != -999][i].mean()
# 결측치 대체
df_1 = df.drop(['area', 'yyyymmdd'], axis=1)
df_2 = df[['area', 'yyyymmdd']]
X = pd.DataFrame(imp.fit_transform(df_1), columns = df.columns[0:-2])
df = pd.concat([X, df_2], axis=1)
# 날짜, 지역별 그룹화
# 세종 시의 경우 16년도 이후의 데이터만 존재.
df = df.groupby(['yyyymmdd', 'area'])[['SO2','CO','O3','NO2','PM10']].agg(func_list).reset_index()
df.columns = list(map('_'.join, df.columns.values))
df.rename(columns = {'yyyymmdd_' : 'yyyymmdd', 'area_' : 'area'}, inplace=True)
# 데이터 병합
back_4 = pd.read_csv('/content/drive/MyDrive/2022_WeatherContest_Data/DataSet/hospital_data/back.csv',encoding='cp949')
back_4 = pd.merge(back_4, df, on=['yyyymmdd','area'],how='outer')
# 세종시 NaN 데이터 처리 - 날짜별 평균
fill_mean_func = lambda g: g.fillna(g.mean())
for i in back_4.columns[4:]:
back_4[i] = back_4.groupby('yyyymmdd')[i].apply(fill_mean_func)
back_4 = back_4.astype({'yyyymmdd':'int64'})
back_4 = back_4.sort_values(['yyyymmdd', 'sex', 'area']).reset_index(drop=True)
back_4yyyymmdd area sex frequency SO2_mean CO_mean O3_mean NO2_mean PM10_mean
0 20120101 강원 1 3.0 0.010033 1.012879 0.019098 0.020873 81.004920
1 20120101 경기 1 4.0 0.009029 0.957298 0.012696 0.030727 85.095743
2 20120101 경남 1 2.0 0.008975 0.653175 0.021270 0.017499 61.997379
3 20120101 경북 1 6.0 0.009128 0.753123 0.022520 0.015224 71.985180
4 20120101 광주 1 0.0 0.005657 0.742130 0.014366 0.024338 50.203704
... ... ... ... ... ... ... ... ... ...
62113 20161231 전남 2 NaN 0.005292 0.577451 0.016422 0.020574 32.326121
62114 20161231 전북 2 NaN 0.003716 0.592187 0.012385 0.023351 47.750308
62115 20161231 제주 2 NaN 0.001338 0.191411 0.029063 0.012552 24.784515
62116 20161231 충남 2 NaN 0.002730 0.631250 0.014071 0.022291 42.137500
62117 20161231 충북 2 NaN 0.004405 0.905903 0.005111 0.026913 51.430227
62118 rows × 9 columns3. 데이터 통합
모든 데이터를 합친다. 결측치는 IterativeImputer를 활용하여 처리해주었다.
yyyymmdd area sex frequency 3시간기온_mean_9 3시간기온_mean_15 3시간기온_mean_21 습도_mean_9 습도_mean_15 습도_mean_21 ... A05_t2 A05_t3 A06_t1 A06_t2 A06_t3 SO2_mean CO_mean O3_mean NO2_mean PM10_mean
0 20120101 강원 1 3.0 -1.657143 -5.650000 -8.032143 50.642857 78.982143 83.250000 ... 1.050000 1.425000 33.268750 39.906250 42.375000 0.010033 1.012879 0.019098 0.020873 81.004920
1 20120101 강원 2 3.0 -1.657143 -5.650000 -8.032143 50.642857 78.982143 83.250000 ... 1.050000 1.425000 33.268750 39.906250 42.375000 0.010033 1.012879 0.019098 0.020873 81.004920
2 20120101 경기 1 4.0 -2.520000 -6.440000 -9.756667 44.400000 64.100000 79.533333 ... 0.067857 0.342857 32.271429 38.539285 39.732143 0.009029 0.957298 0.012696 0.030727 85.095743
3 20120101 경기 2 5.0 -2.520000 -6.440000 -9.756667 44.400000 64.100000 79.533333 ... 0.067857 0.342857 32.271429 38.539285 39.732143 0.009029 0.957298 0.012696 0.030727 85.095743
4 20120101 경남 1 2.0 2.492857 -2.101786 -4.680952 40.071429 59.803571 68.476190 ... 4.690000 5.830000 36.465000 45.705000 47.840000 0.008975 0.653175 0.021270 0.017499 61.997379
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
62113 20161231 제주 2 NaN 8.600000 6.275000 5.650000 56.500000 64.375000 66.333333 ... 8.127660 8.702128 49.033759 54.473095 54.774890 0.001338 0.191411 0.029063 0.012552 24.784515
62114 20161231 충남 1 NaN 3.216667 -0.970833 -1.831111 76.000000 88.750000 88.155556 ... 3.848214 6.026786 41.715959 49.925919 52.637506 0.002730 0.631250 0.014071 0.022291 42.137500
62115 20161231 충남 2 NaN 3.216667 -0.970833 -1.831111 76.000000 88.750000 88.155556 ... 3.848214 6.026786 41.728893 49.932534 52.644211 0.002730 0.631250 0.014071 0.022291 42.137500
62116 20161231 충북 1 NaN 1.516667 -0.616667 -2.432222 79.250000 82.300000 86.972222 ... 1.916667 3.922619 39.067558 48.120423 50.939535 0.004405 0.905903 0.005111 0.026913 51.430227
62117 20161231 충북 2 NaN 1.516667 -0.616667 -2.432222 79.250000 82.300000 86.972222 ... 1.916667 3.922619 39.079351 48.126974 50.946090 0.004405 0.905903 0.005111 0.026913 51.430227
62118 rows × 44 columns4. 파생변수 생성 및 변수 제거
다음의 파생변수를 생성하였다. 데이터의 분포 상으로 지역마다 발생건수에 다른 상관성을 보이는 변수가 존재하지 않아 지역별, 변수별 다른 가중치를 주는 변수를 새로 생성하였다.
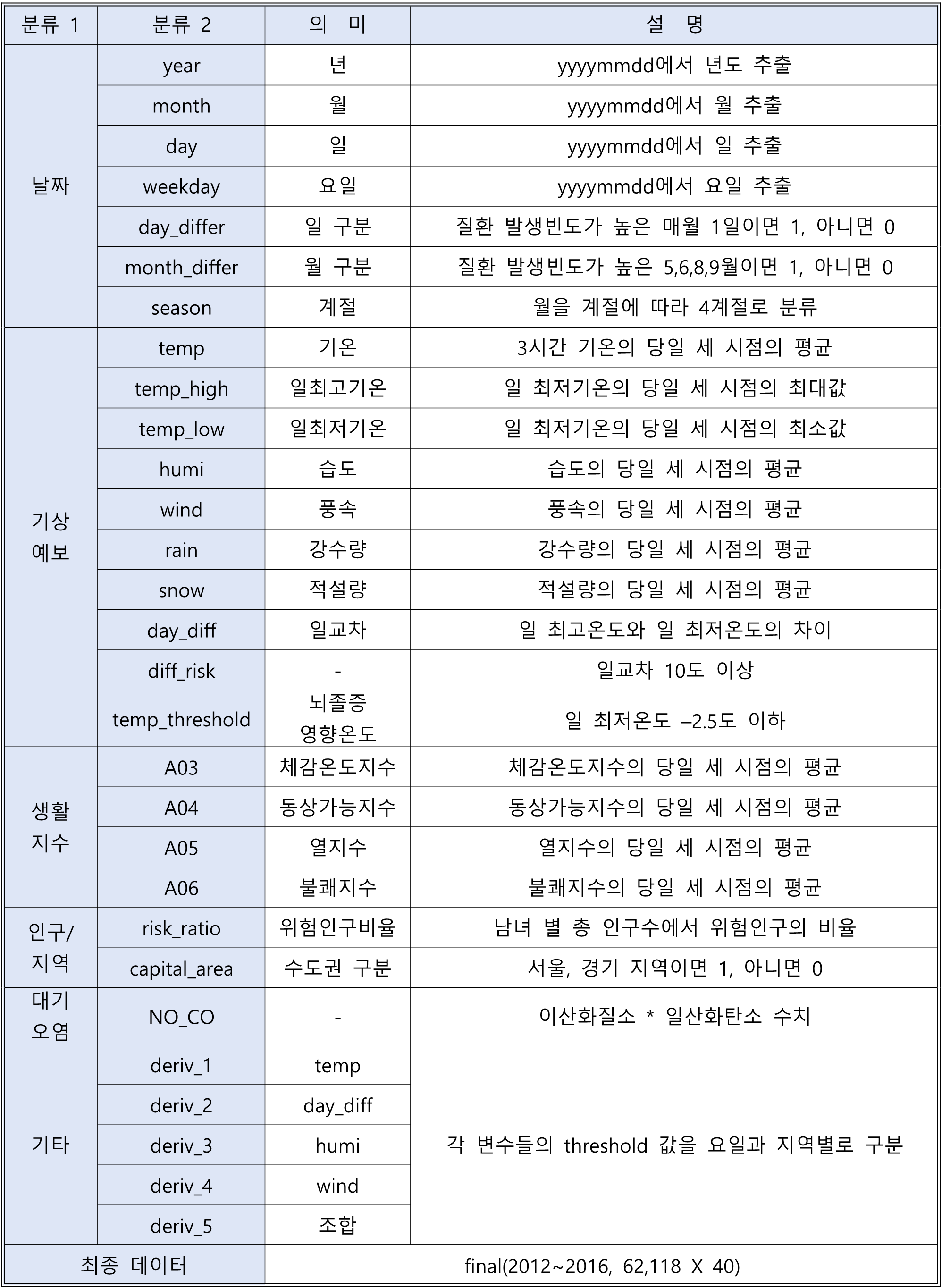
final = final_back.copy()
# 새로운 변수 생성
dates = pd.to_datetime(final.yyyymmdd, format='%Y%m%d').dt
final['year'] = dates.year
final['month'] = dates.month
final['day'] = dates.day
final['day_differ'] = [1 if i == 1 else 0 for i in final['day']]
final['month_differ'] = [1 if i in [5,6,8,9] else 0 for i in final['month']]
final['temp'] = final[['3시간기온_mean_9', '3시간기온_mean_15', '3시간기온_mean_21']].mean(axis=1)
final['humi'] = final[['습도_mean_9', '습도_mean_15', '습도_mean_21']].mean(axis=1)
final['temp_high'] = final[['일최고기온_mean_9', '일최고기온_mean_15', '일최고기온_mean_21']].max(axis=1)
final['temp_low'] = final[['일최저기온_mean_9', '일최저기온_mean_15', '일최저기온_mean_21']].min(axis=1)
final['wind'] = final[['풍속_mean_9','풍속_mean_15', '풍속_mean_21']].mean(axis=1)
final['rain'] = final[['강수량_mean_9','강수량_mean_15', '강수량_mean_21']].mean(axis=1)
final['snow'] = final[['적설_mean_9', '적설_mean_15', '적설_mean_21']].mean(axis=1)
final['A03'] = (final['A03_t1'] + final['A03_t2'] + final['A03_t3']) / 3
final['A04'] = (final['A04_t1'] + final['A04_t2'] + final['A04_t3']) / 3
final['A05'] = (final['A05_t1'] + final['A05_t2'] + final['A05_t3']) / 3
final['A06'] = (final['A06_t1'] + final['A06_t2'] + final['A06_t3']) / 3
final['weekday']= dates.weekday # 'weekday' : 요일
final['risk_ratio'] = final['num_risk_age'] / final['tot_person'] # 'risk_ratio': 위험인구 비율
final['day_diff'] = final['temp_high'] - final['temp_low'] # 'day_diff' : 일교차
final['temp_threshold'] = np.where((final['temp_low'] < -2.5), 1, 0) # 'temp_threshold' : 뇌졸중 영향 온도 threshhold
# https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0094070
conditionlist = [
(final['month'].isin([3,4,5])),
(final['month'].isin([6,7,8])),
(final['month'].isin([9,10,11])),
(final['month'].isin([12,1,2]))]
choicelist = [1,2,3,4]
final['season'] = np.select(conditionlist, choicelist, default='Not Specified').astype('int64') # 'season' : 계절
final['diff_risk'] = np.where(final['day_diff'] >= 10, 1, 0) # 'diff_risk' : 일교차 10도 이상
final['capital_area'] = np.where((final['area'].isin(['서울', '경기'])), 1, 0) # 'capital_area' : 서울, 경기 여부
final['NO_CO']=final['NO2_mean'] * final['CO_mean'] # 'NO_CO' : 이산화질소 * 일산화탄소
# area 변수 라벨 인코딩
cat_features = ['area']
for i in enumerate(cat_features):
ca = i[1]
encoder = LabelEncoder()
encoder.fit(final[ca])
final[ca] = encoder.transform(final[ca])
final['deriv_1'] = 1
final.loc[final['temp'] <= -10, 'deriv_1'] = 2
final['deriv_1'] = final['deriv_1'] + (final['weekday']*10) + (final['area'] * 100) # 'deriv_1' : 요일,지역 별 기온 threshhold 구분
final['deriv_2'] = 1
final.loc[final['day_diff'] >= 10, 'deriv_2'] = 2
final['deriv_2'] = final['deriv_2'] + (final['weekday']*10) + (final['area'] * 100) # 'deriv_2' : 요일,지역 별 일교차 threshhold 구분
final['deriv_3'] = 1
final.loc[final['humi'] >= 50, 'deriv_3'] = 2
final['deriv_3'] = final['deriv_3'] + (final['weekday']*10) + (final['area'] * 100) # 'deriv_3' : 요일,지역 별 습도 threshhold 구분
final['deriv_4'] = 1
final.loc[final['wind'] >= 18, 'deriv_4'] = 2
final['deriv_4'] = final['deriv_4'] + (final['weekday']*10) + (final['area'] * 100) # 'deriv_4' : 요일,지역 별 풍속 threshhold 구분
final['deriv_5'] = final['deriv_1'] + final['deriv_2']*10 + final['deriv_3']*100 + final['deriv_4']+1000 # 'deriv_5' : 'deriv_1' ~ 'deriv_4' 통합
final = final.drop([
'3시간기온_mean_9', '3시간기온_mean_15', '3시간기온_mean_21',
'습도_mean_9', '습도_mean_15', '습도_mean_21',
'일최고기온_mean_9','일최고기온_mean_15', '일최고기온_mean_21',
'일최저기온_mean_9','일최저기온_mean_15', '일최저기온_mean_21',
'풍속_mean_9','풍속_mean_15', '풍속_mean_21',
'강수량_mean_9','강수량_mean_15', '강수량_mean_21',
'적설_mean_9', '적설_mean_15', '적설_mean_21',
'A03_t1', 'A03_t2', 'A03_t3',
'A04_t1', 'A04_t2', 'A04_t3',
'A05_t1', 'A05_t2', 'A05_t3',
'A06_t1', 'A06_t2', 'A06_t3',
], axis=1)