모델링
1. 데이터 분리

전체 final 데이터를 8:2비율로 train과 valid셋으로 분리한다.
# train, test split
train = final[final['year'] != 2016].drop('yyyymmdd', axis=1)
test = final[final['year'] == 2016].drop(['frequency','yyyymmdd'], axis=1)
X = train.drop(['frequency'], axis=1)
y = train['frequency']2. 각 모델 하이퍼파라미터 튜닝
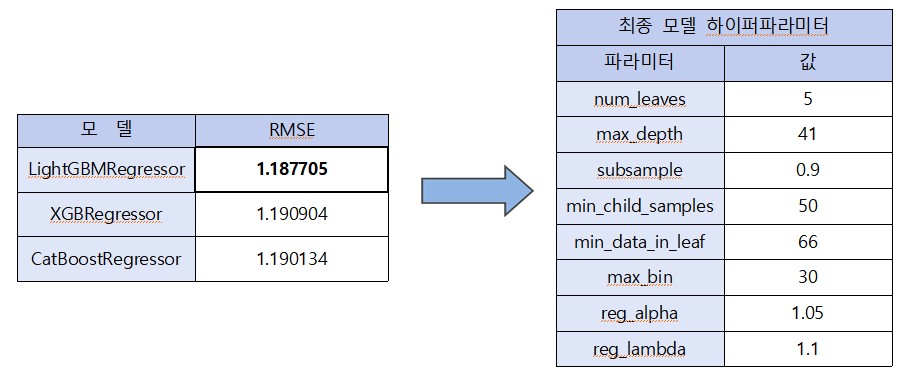
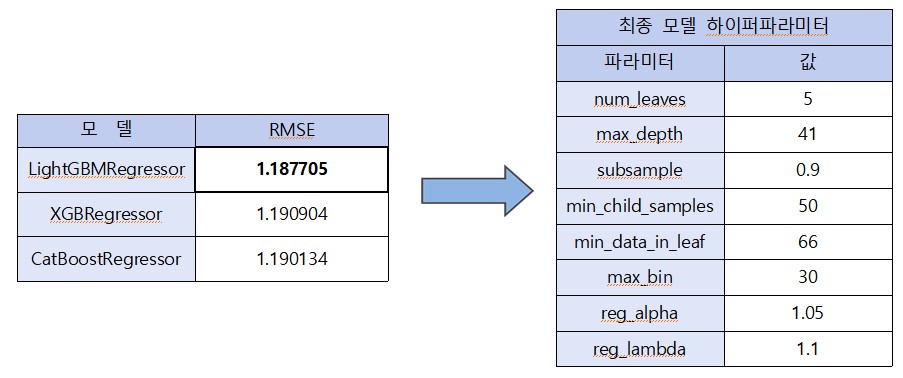
총 3개의 모델(CatBoostRegressor, XGBRegressor, LGBMRegressor)을 사용하여 각각 하이퍼파라미터 튜닝을 진행하고 가장 좋은 점수를 보인 LGBM 모델을 최종 결과로 제출하였다. Voting이나 Stacking과 같은 앙상블 기법 역시 활용하여 제출해 보았으나 LGBM 단일 모델보다 성능이 나쁜 모습을 보여 최종적으론 선택하지 않았다.
파라미터 튜닝은 Optuna 패키지의 TPESampler를 활용하여 Bayesian Optimization 방식으로 진행하였다.
1) CatBoostRegressor
# 학습함수 정의
X_train, X_val, y_train, y_val = train_test_split(X,y, test_size=0.2, random_state=42, stratify=X['month'])
def objective(trial: Trial):
param = {
'max_depth': trial.suggest_int('max_depth', 3, 5),
'reg_lambda': trial.suggest_float('reg_lambda', 1, 1.5, step=0.05),
'max_bin': trial.suggest_int('max_bin', 200, 500, step=20),
'min_data_in_leaf': trial.suggest_int('min_data_in_leaf', 5, 100, step=5),
'leaf_estimation_iterations': trial.suggest_int('leaf_estimation_iterations',1,15),
"colsample_bylevel":trial.suggest_float("colsample_bylevel", 0.4, 1.0, step=0.1),
'od_type': trial.suggest_categorical('od_type', ['IncToDec', 'Iter'])
}
model = CatBoostRegressor(**param, one_hot_max_size = 17, loss_function = 'RMSE', random_state=42)
model.fit(X_train, y_train, eval_set=[(X_val,y_val)], early_stopping_rounds=50, verbose=False)
rmse = RMSE(y_val, model.predict(X_val))
return rmse
# create study
study = optuna.create_study(
direction='minimize',
sampler=optuna.samplers.TPESampler(seed=42),
pruner=optuna.pruners.HyperbandPruner(),
study_name='CatBoostRegressor-Hyperparameter-Tuning'
)
# 학습
study.optimize(lambda trial: objective(trial), n_trials=300)
print('Best trial : score {}, \nparams {}'.format(study.best_trial.value, study.best_trial.params))[I 2022-08-07 12:18:52,408] Trial 281 finished with value: 1.214827544996846 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 220, 'min_data_in_leaf': 30, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:18:57,109] Trial 282 finished with value: 1.214827544996846 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 220, 'min_data_in_leaf': 35, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:02,375] Trial 283 finished with value: 1.2151356893544427 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 220, 'min_data_in_leaf': 35, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:07,911] Trial 284 finished with value: 1.2152719642591685 and parameters: {'max_depth': 5, 'reg_lambda': 1.15, 'max_bin': 240, 'min_data_in_leaf': 35, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:12,644] Trial 285 finished with value: 1.2180466809961152 and parameters: {'max_depth': 3, 'reg_lambda': 1.2, 'max_bin': 200, 'min_data_in_leaf': 45, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:17,390] Trial 286 finished with value: 1.214827544996846 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 220, 'min_data_in_leaf': 40, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:22,726] Trial 287 finished with value: 1.2151356893544427 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 220, 'min_data_in_leaf': 30, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:27,486] Trial 288 finished with value: 1.214827544996846 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 220, 'min_data_in_leaf': 30, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:33,586] Trial 289 finished with value: 1.2154125779361387 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 35, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:39,330] Trial 290 finished with value: 1.214989707752569 and parameters: {'max_depth': 5, 'reg_lambda': 1.15, 'max_bin': 220, 'min_data_in_leaf': 35, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:44,383] Trial 291 finished with value: 1.2153717999496112 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 200, 'min_data_in_leaf': 30, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:49,104] Trial 292 finished with value: 1.214827544996846 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 220, 'min_data_in_leaf': 40, 'leaf_estimation_iterations': 6, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 97 with value: 1.214827544996846.
[I 2022-08-07 12:19:55,400] Trial 293 finished with value: 1.214590819570159 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 40, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 293 with value: 1.214590819570159.
[I 2022-08-07 12:20:01,696] Trial 294 finished with value: 1.214590819570159 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 40, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 293 with value: 1.214590819570159.
[I 2022-08-07 12:20:07,963] Trial 295 finished with value: 1.214590819570159 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 25, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 293 with value: 1.214590819570159.
[I 2022-08-07 12:20:14,263] Trial 296 finished with value: 1.214590819570159 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 45, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 293 with value: 1.214590819570159.
[I 2022-08-07 12:20:18,258] Trial 297 finished with value: 1.2163331867088623 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 45, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.4, 'od_type': 'IncToDec'}. Best is trial 293 with value: 1.214590819570159.
[I 2022-08-07 12:20:24,591] Trial 298 finished with value: 1.214590819570159 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 35, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}. Best is trial 293 with value: 1.214590819570159.
[I 2022-08-07 12:20:29,582] Trial 299 finished with value: 1.2156572142137656 and parameters: {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 45, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.7000000000000001, 'od_type': 'IncToDec'}. Best is trial 293 with value: 1.214590819570159.
Best trial : score 1.214590819570159,
params {'max_depth': 5, 'reg_lambda': 1.2, 'max_bin': 240, 'min_data_in_leaf': 40, 'leaf_estimation_iterations': 5, 'colsample_bylevel': 0.8, 'od_type': 'IncToDec'}2) XGBRegressor
# 학습함수 정의
X_train, X_val, y_train, y_val = train_test_split(X,y, test_size=0.2, random_state=42, stratify=X['month'])
def objective(trial: Trial):
param = {
'max_depth' : trial.suggest_int('max_depth', 2, 12),
'subsample' : trial.suggest_float('subsample', 0.8, 1, step=0.05),
'max_leaves' : trial.suggest_int('max_leaves', 200, 1000, 10),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 5),
'lambda': trial.suggest_float("lambda", 0, 1, step=0.05),
'alpha': trial.suggest_float('alpha', 0, 1, step=0.05),
'gamma' : trial.suggest_float('gamma', 0, 1, step=0.05),
"boosting_type": trial.suggest_categorical('boosting_type', ['gbdt', 'dart']),
"subsample_freq": trial.suggest_int("subsample_freq", 1, 10),
"min_child_samples": trial.suggest_int("min_child_samples", 50, 200),
"max_bin": trial.suggest_int("max_bin", 600, 1200),
}
model = XGBRegressor(**param, random_seed=42, objective = 'reg:squarederror', eval_metric = 'rmse', verbose=-1,
metric = 'rmse', n_jobs=-1, tree_method='gpu_hist')
model.fit(X_train, y_train, eval_set=[(X_val,y_val)], verbose=False, early_stopping_rounds=50)
rmse = RMSE(y_val, model.predict(X_val))
return rmse
# create study
study = optuna.create_study(
direction='minimize',
sampler=optuna.samplers.TPESampler(seed=42),
pruner=optuna.pruners.HyperbandPruner(),
study_name='XGBRegressor-Hyperparameter-Tuning'
)
# 학습
study.optimize(lambda trial: objective(trial), n_trials=500)
print('Best trial : score {}, \nparams {}'.format(study.best_trial.value, study.best_trial.params))[I 2022-08-07 09:43:50,520] Trial 482 finished with value: 1.1922941570571013 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 330, 'min_child_weight': 2, 'lambda': 0.65, 'alpha': 0.9, 'gamma': 0.0, 'boosting_type': 'gbdt', 'subsample_freq': 7, 'min_child_samples': 184, 'max_bin': 940}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:50,997] Trial 483 finished with value: 1.1938413013780478 and parameters: {'max_depth': 3, 'subsample': 0.8, 'max_leaves': 680, 'min_child_weight': 4, 'lambda': 0.65, 'alpha': 0.9, 'gamma': 0.05, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 189, 'max_bin': 929}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:51,575] Trial 484 finished with value: 1.1942547634483083 and parameters: {'max_depth': 5, 'subsample': 0.9500000000000001, 'max_leaves': 610, 'min_child_weight': 2, 'lambda': 0.6000000000000001, 'alpha': 0.9, 'gamma': 0.2, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 190, 'max_bin': 958}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:52,116] Trial 485 finished with value: 1.192963499196168 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 670, 'min_child_weight': 2, 'lambda': 0.9, 'alpha': 0.9, 'gamma': 0.2, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 186, 'max_bin': 895}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:52,648] Trial 486 finished with value: 1.1937139244786092 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 370, 'min_child_weight': 2, 'lambda': 0.65, 'alpha': 0.9, 'gamma': 0.1, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 134, 'max_bin': 944}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:53,105] Trial 487 finished with value: 1.1974930371580679 and parameters: {'max_depth': 2, 'subsample': 0.8, 'max_leaves': 630, 'min_child_weight': 2, 'lambda': 0.6000000000000001, 'alpha': 0.45, 'gamma': 0.30000000000000004, 'boosting_type': 'gbdt', 'subsample_freq': 7, 'min_child_samples': 187, 'max_bin': 857}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:53,614] Trial 488 finished with value: 1.1938721943606663 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 650, 'min_child_weight': 2, 'lambda': 1.0, 'alpha': 0.9500000000000001, 'gamma': 0.30000000000000004, 'boosting_type': 'gbdt', 'subsample_freq': 9, 'min_child_samples': 182, 'max_bin': 931}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:54,234] Trial 489 finished with value: 1.19382177192224 and parameters: {'max_depth': 4, 'subsample': 0.8500000000000001, 'max_leaves': 670, 'min_child_weight': 2, 'lambda': 0.25, 'alpha': 0.8500000000000001, 'gamma': 0.15000000000000002, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 193, 'max_bin': 885}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:54,762] Trial 490 finished with value: 1.1925017417480457 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 610, 'min_child_weight': 2, 'lambda': 0.8500000000000001, 'alpha': 0.75, 'gamma': 0.0, 'boosting_type': 'gbdt', 'subsample_freq': 7, 'min_child_samples': 179, 'max_bin': 871}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:55,249] Trial 491 finished with value: 1.1943344258826543 and parameters: {'max_depth': 3, 'subsample': 0.8, 'max_leaves': 690, 'min_child_weight': 2, 'lambda': 0.35000000000000003, 'alpha': 0.8, 'gamma': 0.30000000000000004, 'boosting_type': 'gbdt', 'subsample_freq': 6, 'min_child_samples': 200, 'max_bin': 912}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:55,772] Trial 492 finished with value: 1.1927380632045224 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 640, 'min_child_weight': 2, 'lambda': 0.65, 'alpha': 0.30000000000000004, 'gamma': 0.30000000000000004, 'boosting_type': 'gbdt', 'subsample_freq': 9, 'min_child_samples': 188, 'max_bin': 898}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:56,658] Trial 493 finished with value: 1.2040083320327528 and parameters: {'max_depth': 7, 'subsample': 0.8, 'max_leaves': 620, 'min_child_weight': 2, 'lambda': 0.30000000000000004, 'alpha': 0.9, 'gamma': 0.25, 'boosting_type': 'gbdt', 'subsample_freq': 7, 'min_child_samples': 185, 'max_bin': 926}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:57,193] Trial 494 finished with value: 1.1929598401810617 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 650, 'min_child_weight': 2, 'lambda': 0.7000000000000001, 'alpha': 0.35000000000000003, 'gamma': 0.2, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 190, 'max_bin': 908}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:57,749] Trial 495 finished with value: 1.1973698523750549 and parameters: {'max_depth': 5, 'subsample': 0.8, 'max_leaves': 710, 'min_child_weight': 2, 'lambda': 0.7000000000000001, 'alpha': 0.5, 'gamma': 0.2, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 192, 'max_bin': 839}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:58,272] Trial 496 finished with value: 1.1919626664626506 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 680, 'min_child_weight': 5, 'lambda': 0.65, 'alpha': 0.55, 'gamma': 0.2, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 197, 'max_bin': 883}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:58,811] Trial 497 finished with value: 1.1931101456624946 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 650, 'min_child_weight': 2, 'lambda': 0.6000000000000001, 'alpha': 0.8, 'gamma': 0.4, 'boosting_type': 'gbdt', 'subsample_freq': 7, 'min_child_samples': 174, 'max_bin': 975}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:59,355] Trial 498 finished with value: 1.1929986336044254 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 660, 'min_child_weight': 2, 'lambda': 0.75, 'alpha': 0.8500000000000001, 'gamma': 0.15000000000000002, 'boosting_type': 'gbdt', 'subsample_freq': 8, 'min_child_samples': 182, 'max_bin': 946}. Best is trial 148 with value: 1.1909040640847843.
[I 2022-08-07 09:43:59,874] Trial 499 finished with value: 1.1924734669270964 and parameters: {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 630, 'min_child_weight': 2, 'lambda': 0.45, 'alpha': 0.9, 'gamma': 0.25, 'boosting_type': 'gbdt', 'subsample_freq': 9, 'min_child_samples': 186, 'max_bin': 923}. Best is trial 148 with value: 1.1909040640847843.
Best trial : score 1.1909040640847843,
params {'max_depth': 4, 'subsample': 0.8, 'max_leaves': 610, 'min_child_weight': 3, 'lambda': 0.4, 'alpha': 0.9, 'gamma': 0.55, 'boosting_type': 'dart', 'subsample_freq': 3, 'min_child_samples': 175, 'max_bin': 863}3) LGBMRegressor
# 단일 LGBM
X_train, X_val, y_train, y_val = train_test_split(X,y, test_size=0.2, random_state=42, stratify=X['month'])
def objective(trial: Trial):
param = {
'num_leaves' : trial.suggest_int('num_leaves', 2, 10),
'max_depth' : trial.suggest_int('max_depth', 2, 50),
'subsample' : trial.suggest_float('subsample', 0.8, 1.0, step=0.05),
'min_child_samples' : trial.suggest_int('min_child_samples', 2, 100, 2),
'min_data_in_leaf' : trial.suggest_int('min_data_in_leaf', 10, 100, 2),
'max_bin' : trial.suggest_int('max_bin', 10, 100, 2),
'reg_alpha' : trial.suggest_float('reg_alpha', 1, 1.5, step = 0.05),
'reg_lambda' : trial.suggest_float('reg_lambda', 1, 1.5, step = 0.05)
}
model = LGBMRegressor(**param, random_seed=42, verbose=-1, metric = 'rmse', n_jobs=-1, n_estimators=500)
model.fit(X_train, y_train, eval_set=[(X_val,y_val)], categorical_feature = ['area'], verbose=False, early_stopping_rounds=50)
rmse = RMSE(y_val, model.predict(X_val))
return rmse
# create study
study = optuna.create_study(
direction='minimize',
sampler=optuna.samplers.TPESampler(seed=42),
pruner=optuna.pruners.HyperbandPruner(),
study_name='LGBMRegressor-Hyperparameter-Tuning'
)
# 학습
study.optimize(lambda trial: objective(trial), n_trials=500)
print('Best trial : score {}, \nparams {}'.format(study.best_trial.value, study.best_trial.params))[I 2022-08-07 11:47:24,553] Trial 494 finished with value: 1.211914315621302 and parameters: {'num_leaves': 5, 'max_depth': 15, 'subsample': 0.8500000000000001, 'min_child_samples': 56, 'min_data_in_leaf': 70, 'max_bin': 26, 'reg_alpha': 1.4, 'reg_lambda': 1.2}. Best is trial 148 with value: 1.2106750811877303.
/usr/local/lib/python3.7/dist-packages/lightgbm/basic.py:1209: UserWarning: categorical_feature in Dataset is overridden.
New categorical_feature is ['area']
'New categorical_feature is {}'.format(sorted(list(categorical_feature))))
[I 2022-08-07 11:47:25,553] Trial 495 finished with value: 1.212877046903649 and parameters: {'num_leaves': 6, 'max_depth': 16, 'subsample': 1.0, 'min_child_samples': 56, 'min_data_in_leaf': 70, 'max_bin': 28, 'reg_alpha': 1.4, 'reg_lambda': 1.3}. Best is trial 148 with value: 1.2106750811877303.
/usr/local/lib/python3.7/dist-packages/lightgbm/basic.py:1209: UserWarning: categorical_feature in Dataset is overridden.
New categorical_feature is ['area']
'New categorical_feature is {}'.format(sorted(list(categorical_feature))))
[I 2022-08-07 11:47:26,301] Trial 496 finished with value: 1.2141426787561342 and parameters: {'num_leaves': 6, 'max_depth': 15, 'subsample': 0.9, 'min_child_samples': 54, 'min_data_in_leaf': 64, 'max_bin': 24, 'reg_alpha': 1.4, 'reg_lambda': 1.35}. Best is trial 148 with value: 1.2106750811877303.
/usr/local/lib/python3.7/dist-packages/lightgbm/basic.py:1209: UserWarning: categorical_feature in Dataset is overridden.
New categorical_feature is ['area']
'New categorical_feature is {}'.format(sorted(list(categorical_feature))))
[I 2022-08-07 11:47:27,178] Trial 497 finished with value: 1.211030924311994 and parameters: {'num_leaves': 6, 'max_depth': 17, 'subsample': 1.0, 'min_child_samples': 52, 'min_data_in_leaf': 66, 'max_bin': 26, 'reg_alpha': 1.4, 'reg_lambda': 1.35}. Best is trial 148 with value: 1.2106750811877303.
/usr/local/lib/python3.7/dist-packages/lightgbm/basic.py:1209: UserWarning: categorical_feature in Dataset is overridden.
New categorical_feature is ['area']
'New categorical_feature is {}'.format(sorted(list(categorical_feature))))
[I 2022-08-07 11:47:27,932] Trial 498 finished with value: 1.2136544143750698 and parameters: {'num_leaves': 6, 'max_depth': 37, 'subsample': 0.9, 'min_child_samples': 2, 'min_data_in_leaf': 70, 'max_bin': 30, 'reg_alpha': 1.4, 'reg_lambda': 1.35}. Best is trial 148 with value: 1.2106750811877303.
/usr/local/lib/python3.7/dist-packages/lightgbm/basic.py:1209: UserWarning: categorical_feature in Dataset is overridden.
New categorical_feature is ['area']
'New categorical_feature is {}'.format(sorted(list(categorical_feature))))
[I 2022-08-07 11:47:28,827] Trial 499 finished with value: 1.2149271471729535 and parameters: {'num_leaves': 6, 'max_depth': 14, 'subsample': 0.9, 'min_child_samples': 4, 'min_data_in_leaf': 68, 'max_bin': 22, 'reg_alpha': 1.45, 'reg_lambda': 1.35}. Best is trial 148 with value: 1.2106750811877303.
Best trial : score 1.2106750811877303,
params {'num_leaves': 6, 'max_depth': 16, 'subsample': 0.8, 'min_child_samples': 46, 'min_data_in_leaf': 70, 'max_bin': 26, 'reg_alpha': 1.35, 'reg_lambda': 1.3}3. 최종 예측 및 feature importance
최종 선정된 LGBMRegressor의 feature importance를 보면 지역, 요일, 매월 1일 구분, 수도권 지역, 위험인구 비율 등이 중요한 것으로 나타났다. 사실상 기상예보 데이터는 새로 만들어낸 파생변수 만이 데이터 예측에 사용되었고 원본 예보 데이터는 거의 사용되지 않았음을 알 수 있다.
# feature importance
def plotImp(model, X , num = 10, fig_size = (20, 10)):
feature_imp = pd.DataFrame({'Value':model.feature_importances_,'Feature':X.columns})
plt.figure(figsize=fig_size)
sns.set(font_scale = 2)
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value",
ascending=False)[0:num])
plt.title('LightGBM Features')
plt.tight_layout()
plt.show()
LGBM = LGBMRegressor(**study.best_trial.params, random_state=42, verbose=-1, metric = 'rmse', n_jobs=-1, learning_rate=0.03)
LGBM.fit(X, y, categorical_feature = ['area'], verbose=False)
plotImp(LGBM, X)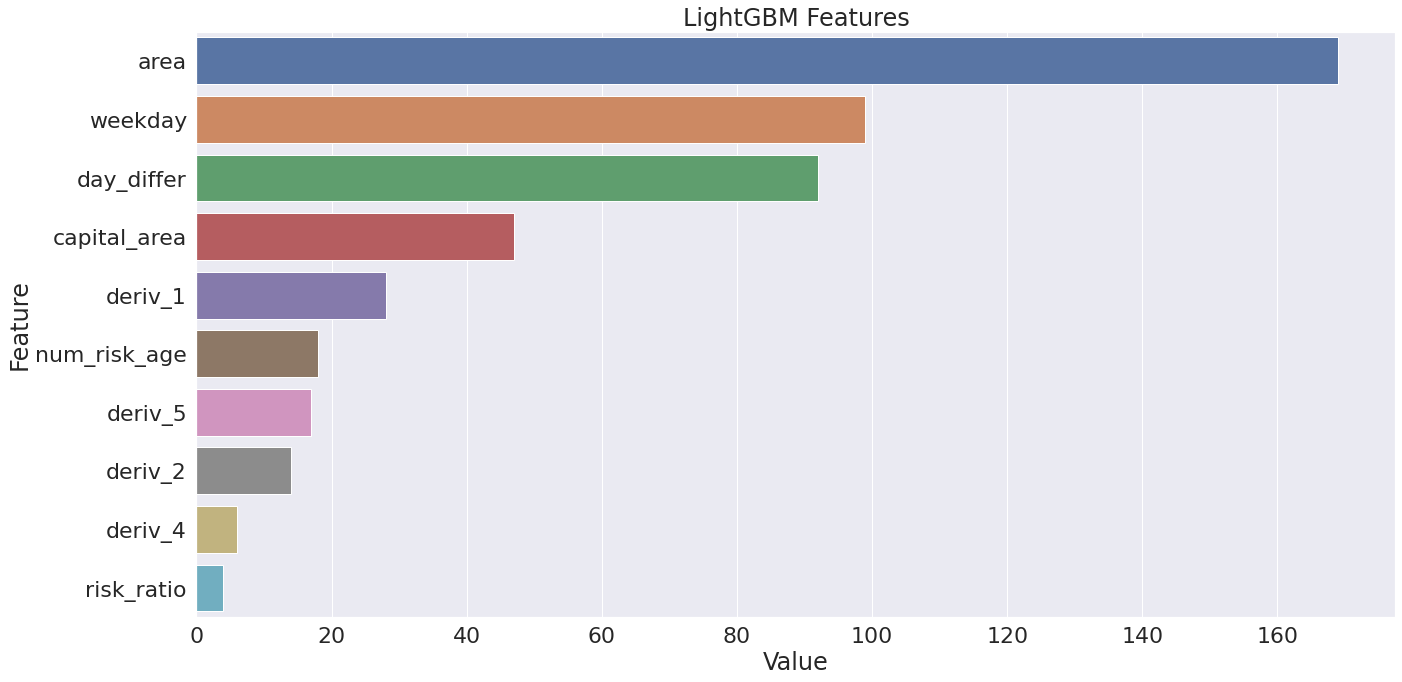
LGBM_pred = LGBM.predict(test)
submit['frequency'] = LGBM_pred * 1.052012년에서 2016년으로 갈수록 증가하는 환자발생수의 년도 별 증가분 예상치(1.05)를 곱해주어 최종 예측치의 성능을 높여주었다.
4. 결론
개인적으로는 탈이 많은 대회였다고 생각한다. 우선적으로,
-
대부분의 데이터를 수급해야 하는 기상청의 ‘날씨마루’ 플랫폼의 서버가 불안정하고 자체 SQL 쿼리로 직접 데이터베이스에서 데이터를 불러와 가공해야 했다. 이 과정이 데이터도 크고 시간도 오래걸려 많은 노력이 필요했다. 가공이 어느정도 잘 되어있는 데이터임에도 불구하고 대회 데이터 포맷에 맞게 만드는 전처리 과정이 길어 힘들었던 것 같다.
-
열심히 예보 데이터를 가공해서 쓰던 중 대회 중간쯤에 운영 측에서 다 제공해주었다…… -
대회의 목적이 ‘심뇌혈관계 질환발생에 영향을 미치는 기상정보’를 파악하여 발생을 미리 예측하는 것인데 결론적으로 모델의 정확도에 큰 영향을 주었던 변수는 인구와 지역 변수였다. 데이터 가공을 제대로 하지 못했을 가능성도 있지만 1차적으로 기상과 질환발생이 데이터적으로 유의미한 상관관계가 존재하는 것인지에 대한 의문 역시 들었다. 역시 데이터에 정답은 없는 것 같다.
-
대회 이후에 안 사실이지만 여러 모델을 앙상블하는 기법은 다른 방식을 가지는 모델들을 합쳐서 예측값에 서로 부족한 부분을 보완해주길 기대하는 것이라고 한다. 대회 중에는 XGB, LGBM, CatBoost를 앙상블 시도해보았는데 같은 boosting기법 모델을 앙상블 할 것이 아니라 다른 방식의 모델들(ex) DNN, tree구조 등)을 시도해야했다.
-
모델링보다 전처리에 전체 자원의 80% 정도를 쏟았보며 실무자 분들이 항상 말하던 ‘전처리가 가장 시간이 오래 걸린다’를 직접 맛보았던 의미 있는 대회였던 것 같다.
