
1. 서론
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Hadoop의 경우 하둡 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Tez 란?

Apache Tez 는 기존의 Mapreduce 에서 데이터를 처리하는 방식에서 Disk 에 저장하는 다시 불러오는 과정을 없앤 연산 방식입니다.
Hive 에서는 Mapreduce, Tez, Spark 이 3가지 중에서 연산 엔진을 고를 수 있습니다.
그리고 Hive 에서는 Tez 엔진을 기본 엔진으로 권장하고 있으므로 다른 선택지를 따로 생각하기 보다는 Tez를 자연스럽게 사용하게 됩니다.
아래는 Apache Tez 에 대한 공식 설명 입니다.
[Empowering end users by]:
- Expressive dataflow definition APIs
- Flexible Input-Processor-Output runtime model
- Data type agnostic
- Simplifying deployment
[Execution Performance]
- Performance gains over Map Reduce
- Optimal resource management
- Plan reconfiguration at runtime
- Dynamic physical data flow decisions
링크텍스트Apache Tez Document
3. Tez 구조
Tez는 MapReduce 연산 모델의 구조가 개선된 모델 입니다.
공식 문서에서 아래 그림으로 상세하게 표현해뒀습니다.
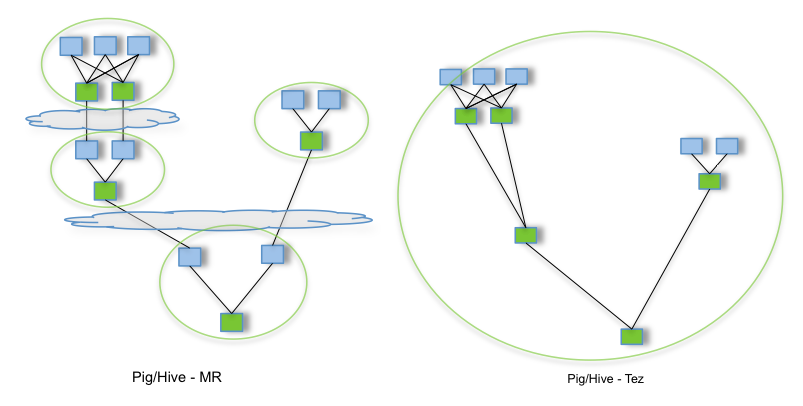
해당 그림에서 기호들은 아래와 같이 의미하고 있습니다.
- 파란 박스 : Map
- 초록 박스 : Reduce
- 구름 : HDFS
2개의 그림은 모두 같은 연산을 하고 있는 것을 가정으로 예시를 들고 있습니다.
Pig/Hive - MR 의 도식을 살펴 보게 되면 중간 연산 과정에 HDFS ( or DISK) 에 데이터를 쓰고, 읽어오는 작업들이 빈번하게 일어나고 있습니다.
그러나 Pig/Hive - Tez 의 그림을 보게 되면 그런 중간 과정에서 Reduce 과정만 존재하는 것을 알 수 있습니다.
그렇기 때문에 Tez 가 기존의 MapReduce 보다 연산 속도가 더 빠르게 나올 수 밖에 없습니다.
그러나 중간 과정에서 Disk 로 저장하는 과정이 없어진다면 메모리에 데이터가 저장이 돼 있는 모델일 것이고 해당 데이터가 유실 될 경우 어떻게 대처할 수 있는가에 대해서 고민해 볼 수 있습니다.
그렇기에 Tez 에서는 DAG 그래프를 작성해서 해당 작업을 먼저 스케줄링 합니다.
DAG(Direct acyclic graphs)는 방향 비순환 그래프로 방향성은 존재하지만 순환이 되지 않는 그래프로 처음과 끝이 존재하는 무한 반복이 없는 그래프를 말합니다.
작업 전 해당 그래프가 만들어 진 후 데이터 처리가 이루어 지기 때문에 어떤 edge에서 어떤 문제가 발생했는지 다시 실행 계획을 잡을 수 있습니다.
아래는 Cloudera 에서 정의하고 있는 DAG 설명이 포함 된 TEZ 설명 입니다.
4. Tez Releases
업무를 수행하며 지인과 대화 중 Tez 의 Releases 에 대한 불안성에 대하여 이야기가 오간 적이 있었습니다.
먼저 2023-06-11 기준 Tez 의 Releases 는 아래와 같습니다.
- Apache TEZ® 0.10.2 (Jul 15, 2022)
- Apache TEZ® 0.10.1 (Jul 01, 2021)
- Apache TEZ® 0.10.0 (Oct 15, 2020)
- Apache TEZ® 0.9.2 (Mar 29, 2019)
- Apache TEZ® 0.9.1 (Jan 04, 2018)
- Apache TEZ® 0.9.0 (Jul 27, 2017)
- Apache TEZ® 0.8.5 (Mar 13, 2017)
- Apache TEZ® 0.8.4 (Jul 08, 2016)
- Apache TEZ® 0.8.3 (Apr 15, 2016)
- Apache TEZ® 0.8.2 (Jan 19, 2016)
- Apache TEZ® 0.8.1-alpha (Oct 12, 2015)
- Apache TEZ® 0.8.0-alpha (Sep 01, 2015)
- Apache TEZ® 0.7.1 (May 10, 2016)
- Apache TEZ® 0.7.0 (May 18, 2015)
- Apache TEZ® 0.6.2 (Aug 07, 2015)
- Apache TEZ® 0.6.1 (May 18, 2015)
- Apache TEZ® 0.6.0 (Jan 23, 2015)
- Apache TEZ® 0.5.4 (Jun 26, 2015)
- Apache TEZ® 0.5.3 (Dec 10, 2014)
- Apache TEZ® 0.5.2 (Nov 07, 2014)
- Apache TEZ® 0.5.1 (Oct 08, 2014)
- Apache TEZ® 0.5.0 (Sep 04, 2014)
활발하게 버전 배포를 해오다가 2018년 부터 7월에 한 번씩만 배포를 하고 있는 것을 알 수가 있습니다.
물론 배포가 몇 년째 중단이 된 경우가 아니기 때문에 올해도 새로운 개선 모델이 있지 않을까 해서 github repository를 살펴봤습니다.
확실히 Pull request 도 적어서 뭔가 더 개선할 여지는 따로 보이지는 않습니다.
그렇기에 엔진을 활발하게 발전 중인 Spark로 변경하는 부분도 고민 해 볼만한 거리라고 생각이 됩니다.
5. Tez 구성
아래는 저희가 사용하고 있는 Tez Config을 공유 드립니다.
더 좋은 설정 값이 있다면 공유 해주시면 참고할 수 있도록 하겠습니다.
<configuration>
<property>
<name>tez.lib.uris</name>
<value>{HDFS 경로}/tez-0.10.2-build-hadoop-3.2.1.tar.gz</value>
</property>
<property>
<name>tez.tez-ui.history-url.base</name>
<value>http://{TEZ UI 가 뜰 서버 IP}:8686/tez/</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>tez.am.java.opts</name>
<value>-Xmx4096m</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>16384</value>
</property>
<property>
<name>tez.runtime.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>tez.am.grouping.min-size</name>
<value>16777216</value>
</property>
<property>
<name>tez.am.grouping.max-size</name>
<value>1073741824</value>
</property>
<property>
<name>tez.am.container.reuse.locality.delay-allocation-millis</name>
<value>250</value>
</property>
<property>
<name>tez.am.container.reuse.non-local-fallback.enabled</name>
<value>false</value>
</property>
<property>
<name>tez.am.container.reuse.rack-fallback.enabled</name>
<value>true</value>
</property>
<property>
<name>tez.session.client.timeout.secs</name>
<value>-1</value>
</property>
<property>
<name>tez.staging-dir</name>
<value>/tmp/${user.name}/staging</value>
</property>
<property>
<name>tez.session.am.dag.submit.timeout.secs</name>
<value>60</value>
</property>
<property>
<name>tez.queue.name</name>
<value>{tez job 이 수행될 YARN Queue 이름}</value>
</property>
</configuration>6. 결론
손쉽게 Hive on Tez 를 구성할 수 있었습니다만 Spark 를 활용한 Hive 또한 고민을 해볼만한 거리라고 생각이 듭니다.
이번에 새로 생긴 개발 서버를 활용하여 Hive on Spark 테스트를 진행해보는 것도 좋을 듯 합니다.
