
1. 서론
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Hadoop의 경우 하둡 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. 읽기 스키마와 쓰기 스키마
데이터베이스에서는 스키마를 검증하는 시점에 따라 읽기 스키마와 쓰기 스키마로 구분 합니다.
Hive 는 데이터를 로드하는 시점이 아닌 먼저 쿼리를 실행하는 시점에서 데이터 스키마를 검증하는데, 이 것을 읽기 스키마라고 합니다. 그러나 전통적인 데이터베이스에서는 테이블의 스키마는 데이터를 로드하는 시점에 검증을 하며, 이를 쓰기 스키마라고 합니다.
조금 더 간단하게 읽기 스키마와 쓰기 스키마를 구분하자면 아래와 같이 이해할 수 있습니다.
- 읽기 스키마 : 데이터를 읽을 때 스키마가 정의 되면 된다. (스키마 없이 데이터를 저장할 수 있다.)
- 쓰기 스키마 : 데이터를 처음 저장할 때 스키마를 정의하고 데이터를 저장해야 한다.
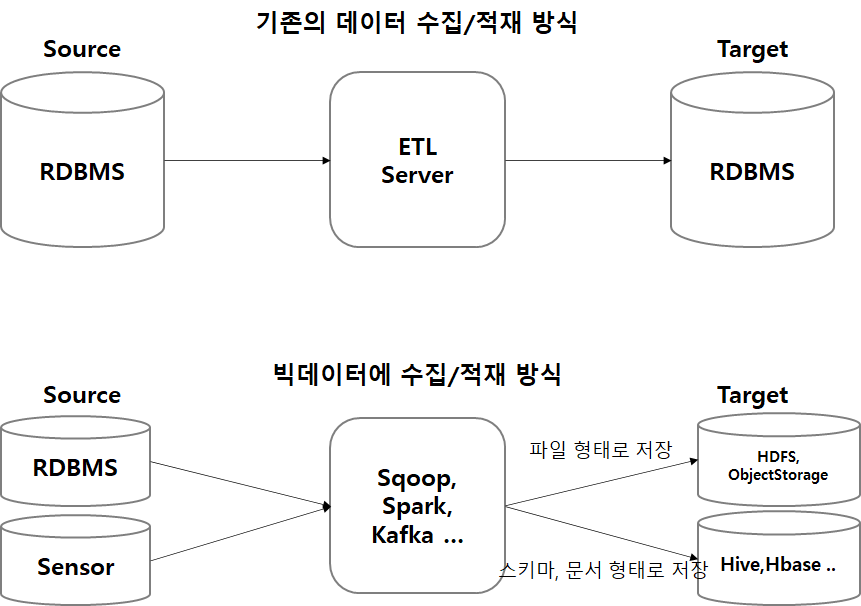
왜 이런 관점이 생기는 것인지를 알기 위해서는 빅데이터의 역할을 이해할 필요가 있습니다.
빅데이터 시스템은 주로 데이터 레이크 역할을 합니다. 이 때 데이터들은 보통 가공 되지 않은 원천 형태 그대로 데이터를 가져오게 되는데, 이러한 이유는 원천 형태에서 변형이 일어나게 되면 혹시 모르는 데이터 유실이 있을 수 있기 때문입니다.
원형 데이터를 형태 그대로 데이터를 적재한 후 변형을 일으키는데, 모든 데이터가 정형 데이터이지는 않기 때문에 스키마를 처음부터 정의하여 저장하기에는 다소 무리가 있습니다.
그렇기에 데이터 수집을 할 때 포맷을 지정한 파일 형태로 먼저 저장 되는 경우가 많습니다. (물론 도메인 IT 에 능숙한 인원과 함께 처리한다면 처음부터 스키마를 정의하여 데이터를 저장할 수도 있습니다.)
3. 갱신, 트랜잭션, 색인
데이터베이스에서 핵심적으로 제공하는 기능들은 갱신, 트랜잭션, 색인 입니다. 그러나 처음 Hive 는 이러한 특성을 전혀 고려하지 않았습니다. HDFS 에 담겨 있는 데이터들을 MapReduce를 활용하여 데이터를 조회했을 때 이미 full scan을 하게 된다는 것입니다.
그리고 테이블을 갱신할 때는 기존의 테이블을 지우고 새로운 테이블로 대체하는 방식으로 (truncate insert, insert overwrite) 동작합니다.
하지만 0.14.0 버전 부터 행 단위의 UPDATE, DELETE 도 지원하게 됐습니다.
HDFS는 기존의 파일 갱신을 지원하지 않기 때문에 삽입, 변경, 삭제로 인한 갱신 내역은 별도의 작은 델타 파일에 저장되었다가 메타스토어에서 백그라운드로 실행되는 맵리듀스 잡에 의해 기존 테이블과 주기적으로 병합됩니다.
Hive 에서 트랜잭션 테이블을 만들 때 파일 포맷은 orc 만 사용할 수 있고, 해당 테이블은 ACID가 가능한 세션만이 테이블을 접근할 수 있습니다. 그리고 테이블은 버켓팅 설정이 된 managed table 만 가능합니다.
아래 설정을 통해 트랜잭션이 가능한 테이블을 만들 수 있습니다.
CREATE TABLE table1 (
) SOTRED AS ORC
TBLPROPERTIES ("transactional"="true")이 때 Spark 이 해당 테이블을 조회하면 에러가 발생합니다.
여러 경우가 있겠지만 앞서 말했던 메타스토어에서 백그라운드로 실행 되면 기존 테이블과 주기적으로 병합시키는 프로세스인 Compactor 를 지정해줘야 합니다.
Compaction 의 종류는 아래 두가지 입니다.
- 마이너 컴팩션(minor compaction) : 델타 파일을 모아서 버켓당 하나의 델타 파일로 다시 생성
- 메이저 컴팩션(major compaction) : 베이스 파일과 델타 파일을 새로운 베이스 파일로 생성
Spark 은 Major compaction 을 통해서 ACID 테이블을 조회할 수 있다고 합니다.
how to read orc transaction hive table in spark? - stackoverflow
물론 Spark 자체 만으로 Update, Delete 를 대응하기가 힘들기 때문에 그다지 큰 기대는 없습니다. (기본적으로 Update 가 필요한 데이터는 원천에서는 잘 없을 테니 깔끔하게 JDBC로 RDBMS 에서 Update, Delete 를 합니다.)
Hive 는 파티션 수준의 잠금 또한 지원합니다. 예를 들어 잠금은 특정 프로세스가 테이블을 읽는 도중에 다른 프로세스가 테이블을 삭제하는 것을 방지할 수 있습니다.
잠금은 주키퍼에 의해 투명하게 관리되므로 사용자가 직접 주키퍼를 조작하여 잠금을 적용하거나 해제할 수는 없습니다.
하이브는 특정한 경우에 쿼리의 속도를 높일 수 있는 색인을 지원합니다. compact, bitmap 색인을 지원하고, 플러그인 방식으로 다른 방식의 색인을 추가할 수도 있다고 합니다.
4. 관리 테이블, 외부 테이블
Hive 는 기본적으로 테이블을 생성할 때 데이터를 직접 관리하게 되는데, 이는 하이브가 데이터를 자신이 관리하는 웨어하우스 디렉터리로 이동시킨다는 의미 입니다.
외부 테이블의 경우 다른 디렉터리에 있는 데이터를 스키마만 만들어 읽는 테이블 입니다.
- Managed Table
CREATE TABLE managed_table (id string);- External Table
CREATE EXTERNAL TABLE external_table (id string)
LOCATION '/external/path';관리 테이블의 경우 DROP 했을 경우 테이블 & 데이터 모두 삭제되지만, 외부 테이블의 경우 스키마만 삭제 되고 데이터의 경우 삭제가 되지 않습니다.
애초에 외부 테이블은 스키마를 만들 때 해당 경로에 데이터가 존재하는지 조차 검사를 하지 않기 때문에 Hive 데이터를 직접 관리를 하지 않는 것을 알 수 있습니다.
저희의 경우 관리 테이블에 넣어서 관리를 하지만, 하나의 데이터에 다양한 스키마를 입힐 필요가 있다면 외부 테이블도 고민을 해볼만 하다고 생각합니다.
5. 파티션, 버킷
파티션은 전통적인 데이터베이스에서 자주 사용하는 기능입니다.
Hive에서의 파티셔닝은 아래와 같이 적용할 수 있습니다.
CREATE TABLE table1 (id STRING, passwd STRING)
PARTITIONED BY (BASE_DT STRING);Hive 에서는 dynamic partition 을 지원하기 때문에 별도의 키를 지정해서 파티셔닝을 할 필요 없이 자동으로 Hive 에서 파티션 별로 데이터를 분배합니다.
그러나 동적 파티션은 아래와 같이 파티션 키 제한이 있으므로 유념해서 데이터를 저장하도록 합니다.
Hive 에서 파티션 구조는 아래와 같이 디렉터리가 생성 됩니다.
/table
- base_dt='202305'
- file1
- file2
- base_dt='202306'
- file1
- file2버킷은 테이블에 대한 추가 구조를 부여하는 것을 말합니다.
추가 구조는 지정된 컬럼의 값을 hash 처리해서 지정한 수의 파일로 나누어 저장하는 방식입니다.
데이터셋의 일부에만 쿼리를 실행하여 조회 속도를 증가 시키는 용도로 사용 됩니다.
CREATE TABLE table1 (id STRING, passwd STRING)
CLUSTERD BY (id) INTO 4 BUCKETS;6. 결론
Hive 에서도 생각보다 많은 기능들을 제공하고 있습니다.
아직까지 Hive 에 트랜잭션 테이블을 활용하거나 버킷을 활용해 보지는 않았지만, 필요할 때 이런 기능들을 이용해보는 것도 괜찮을 듯 합니다. 물론 다른 Application 들을 사용할 수 없는 경우에 한정이겠지만요.
