
1. 서론
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Hadoop의 경우 하둡 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Hive 란?

하이브는 하둡 기반의 데이터 웨어하우징 프레임워크 입니다. 페이스북에서 매일 같이 생산되는 대량의 데이터를 관리하고 학습하기 위해 개발했습니다.
아래는 Apache Hive Document 에서 말하는 한 줄 설명입니다.
" The Apache Hive ™ is a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale and facilitates reading, writing, and managing petabytes of data residing in distributed storage using SQL. "
Hadoop 의 HDFS 의 데이터를 관리하기 위해서는 Java를 활용하여 코드를 구현해야 합니다. 그러나 MapReduce를 직접 구현하기에는 많은 어려움이 있으므로 SQL 로 데이터를 관리하고 분석할 수 있는 툴이 필요했는데, 이 것이 바로 Hive 입니다.
하이브의 Document는 Jira로 이어지도록 구성이 돼 있습니다.
저는 Hive 자체에서 Query를 거의 활용하지는 않지만 Spark 에서 spark.sql 을 사용할 때 Hive 호출을 많이 합니다.
Hive는 0.13 버전 부터 ACID 를 지원하고, 0.14 버전 부터 ORC 파일 포맷에 한 해서 Update, Delete를 지원합니다.
그러나 Spark 의 경우 Hive update 가 불가능합니다. 그러므로 다른 방안을 찾아야 합니다 ...
3. Hive 구성
하이브는 아래와 같은 구조를 가지고 있습니다.
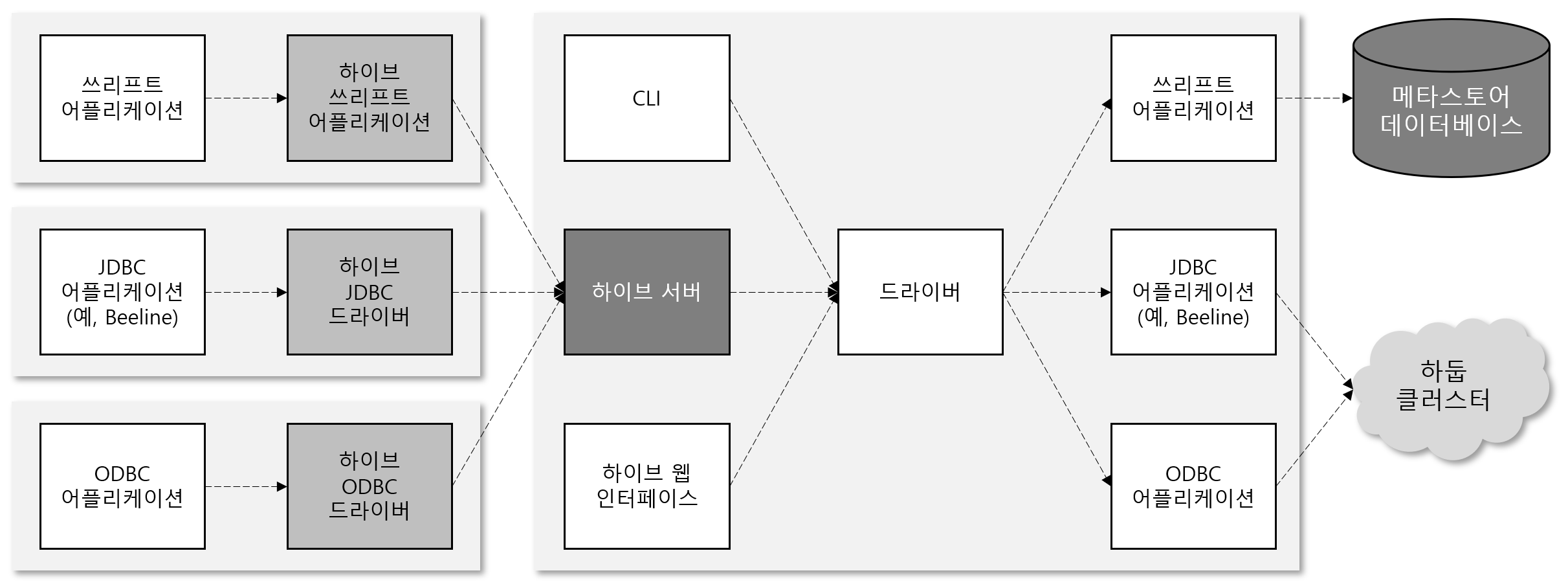
처음 Hive 를 설치하고 서비스를 실행하면 드라이브와 Thrfit, JDBC, ODBC 어플리케이션이 동작하게 됩니다. 그리고 CLI로 Hive 를 조작할 수 있게 됩니다.
물론 여기서 멈추면 다른 어플리케이션들(JDBC, Spark(Thrift))이 하이브로 접근할 수 있는 방법이 없으므로 hiveserver2 라고 부르는 하이브 서버를 띄웁니다. 이 hive 서버에 beeline 이나 JDBC 를 통해 SQL 질의가 가능해집니다.
아래는 용어에 대해서 정리를 해보겠습니다.
1. 하이브 서버(hive server 2)
다른 언어로 개발된 클라이언트와 연동할 수 있도록 하이브를 쓰리프트 서비스로 실행합니다. 하이브서버2는 기존 하이브서버를 개선하여 인증과 다중 사용자 동시성을 지원합니다. Thrift, JDBC, ODBC 연결자를 사용하는 어플리케이션은 하이브와 통신하기 위해 먼저 하이브 서버를 실행해야 합니다.
2. 메타스토어
HDFS 에 저장된 데이터를 하이브는 보여주는 역할을 합니다. 그러나 HDFS 어디에 데이터가 저장 돼 있는지에 대한 메타 정보와 그 데이터를 표현하는 테이블 정보가 필요하게 됩니다. 그렇기에 Hive는 메타스토어라는 기존의 RDBMS 를 두고 해당 메타데이터를 저장하여 SQL 질의 시 사용할 수 있도록 구성 됩니다. 이 때 메타스토어는 MariaDB, PostgreSQL, MySQL 을 주로 활용하며 이중화 하여 관리합니다.
3. Apache Thrift
페이스북에서 서로 다른 언어간의 통신을 위해 개발 기증 된 프로젝트 입니다. 원격 프로시저 호출(Remote Procedure Call)로 언어에 상관 없이 서로 통신할 수 있도록 도와줍니다.
4. Hive Metastore 구성
Hive 메타 스토어 구성은 아래와 같이 3가지 방식으로 메타스토어로 구성할 수 있습니다.

보통의 큰 환경에서는 드라이버와 메타스토어를 분리 시킨 원격 메타스토어를 활용할 것입니다.
저희 또한 Postgres 를 이중화 하여 원격 메타스토어 구조를 취하고 있는데, 노드 개수 제약으로 각각 분리 돼 운영되고 있지는 않습니다.
5. Hive Config
저는 운영중인 Hive Config 을 아래와 같이 설정하고 있습니다.
더 효율적인 방법을 찾아가는 중이며, 만약 더 좋은 제안이 있다면 꼭 공유가 됐으면 합니다.
1. hive-site.xml
<configuration>
<property>
<name>hive.exec.parallel.thread.number</name>
<value>8</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>16384</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>{RDBMS DRIVER}</value>
</property>
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnctionPassword</name>
<value>password</value>
</property>
<property>
<name>hive.exec.parallel</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://{HIVE SERVER1 IP}:9083,thrift://{HIVE SERVER2 IP}:9083</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:{DB}://{DB IP}:{PORT}/hive</value>
</property>
<property>
<name>hive.strict.managed.tables</name>
<value>false</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.user.install.directory</name>
<value>/user/</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>{Zookeeper 1}:2181,{Zookeeper 2}:2181,{Zookeeper 3}:2181</value>
</property>
<property>
<name>hive.security.authorization.sqlstd.confwhitelist.append</name>
<value>mapreduce.*|mapred.*|{Hadoop 계정}.*|user*|password*|{hive 계정}.*</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/{Managed Table}</value>
</property>
<property>
<name>hive.metastore.warehouse.external.dir</name>
<value>/hive/{External Table}</value>
</property>
<property>
<name>hive.zookeeper.session.timeout</name>
<value>10</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.stats.autogather</name>
<value>false</value>
</property>
<!-- Atlas - Hive Config -->
<property>
<name>hive.exec.failure.hooks</name>
<value>org.apache.hadoop.hive.ql.hooks.ATSHook,org.apache.atlas.hive.hook.HiveHook</value>
</property>
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.hadoop.hive.ql.hooks.ATSHook,org.apache.atlas.hive.hook.HiveHook</value>
</property>
<property>
<name>tez.queue.name</name>
<value>{TEZ 가 동작할 Queue 이름}</value>
</property>
<!-- ranger plugin config -->
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory</value>
</property>
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.conf.restricted.list</name>
<value>hive.security.authorization.enabled,hive.security.authorization.manager,hive.security.authenticator.manager</value>
</property>
</configuration>6. 결론
사실 빅데이터 분석에서 Hive라는 존재는 엄청 큰 역할을 하고 있다고 생각합니다.
SQL로 데이터를 조회하고 테이블로 데이터를 관리할 수 있다는 것은 상당히 많은 들여야 할 노력들을 줄여주지 않았나 생각이 듭니다.
Trino 나 Impala 또한 Hive 의 메타스토어를 공유하며 발전해나가므로 Hadoop 의 기초적이고 대표적인 RDBMS 이지 않나 라고 생각합니다.
